
AI 101
რა არის Overfitting?
რა არის Overfitting?
როდესაც ავარჯიშებთ ნერვულ ქსელს, თავიდან უნდა აიცილოთ ზედმეტი მორგება. გადახურვა ეს არის მანქანათმცოდნეობისა და სტატისტიკის პრობლემა, სადაც მოდელი ძალიან კარგად სწავლობს ტრენინგის მონაცემთა ნაკრების ნიმუშებს, სრულყოფილად ხსნის ტრენინგის მონაცემთა ნაკრების, მაგრამ ვერ ახდენს მისი პროგნოზირების უნარის განზოგადებას სხვა მონაცემთა ნაკრებებზე.
სხვაგვარად რომ ვთქვათ, გადაჭარბებული მოდელის შემთხვევაში ის ხშირად აჩვენებს ძალიან მაღალ სიზუსტეს ტრენინგის მონაცემთა ბაზაში, მაგრამ დაბალი სიზუსტით შეგროვებულ და მოდელში მომავალში გაშვებულ მონაცემებზე. ეს არის ზედმეტად მორგების სწრაფი განმარტება, მაგრამ მოდით უფრო დეტალურად გადავხედოთ ზედმეტად მორგების კონცეფციას. მოდით შევხედოთ, თუ როგორ ხდება ზედმეტი მორგება და როგორ შეიძლება მისი თავიდან აცილება.
„ფიტის“ და „დაბალი ფიტინგის“ გაგება
სასარგებლოა გადახედოთ არასრულფასოვნების კონცეფციას და ”ჯდება” ზოგადად, როდესაც ვსაუბრობთ ზედმეტად მორგებაზე. როდესაც ჩვენ ვამზადებთ მოდელს, ჩვენ ვცდილობთ შევიმუშაოთ ჩარჩო, რომელსაც შეუძლია წინასწარ განსაზღვროს ელემენტების ბუნება, ან კლასი, მონაცემთა ბაზაში, იმ მახასიათებლების საფუძველზე, რომლებიც აღწერს ამ ერთეულებს. მოდელს უნდა შეეძლოს ახსნას ნიმუში მონაცემთა ნაკრების ფარგლებში და წინასწარ განსაზღვროს მომავალი მონაცემთა წერტილების კლასები ამ ნიმუშიდან გამომდინარე. რაც უფრო კარგად ხსნის მოდელი სასწავლო კომპლექტის მახასიათებლებს შორის ურთიერთობას, მით უფრო "შეესაბამება" ჩვენი მოდელი.
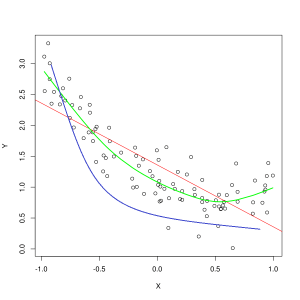
ცისფერი ხაზი წარმოადგენს პროგნოზებს მოდელის მიერ, რომელიც არ არის შესაფერისი, ხოლო მწვანე ხაზი წარმოადგენს უკეთეს მოდელს. ფოტო: პეპ როკა Wikimedia Commons-ით, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
მოდელი, რომელიც ცუდად ხსნის ურთიერთობას სასწავლო მონაცემების მახასიათებლებს შორის და, შესაბამისად, ვერ ახერხებს სამომავლო მონაცემთა მაგალითების ზუსტად კლასიფიკაციას, არის უხარისხო ტრენინგის მონაცემები. თუ თქვენ დასახავთ გრაფიკის მიხედვით არასრულფასოვანი მოდელის პროგნოზირებულ ურთიერთობას მახასიათებლებისა და ეტიკეტების რეალურ გადაკვეთაზე, პროგნოზები გადაუხვევს ნიშნულს. თუ ჩვენ გვქონდა გრაფიკი, რომელშიც მითითებულია სასწავლო ნაკრების რეალური მნიშვნელობები, სასტიკად დაუცველი მოდელი მკვეთრად გამოტოვებდა მონაცემთა პუნქტების უმეტესობას. უკეთესი მორგების მქონე მოდელმა შეიძლება გაჭრას ბილიკი მონაცემთა წერტილების ცენტრში, ცალკეული მონაცემების წერტილები პროგნოზირებულ მნიშვნელობებს მხოლოდ ოდნავ ჩამოშორდეს.
დაქვეითება ხშირად შეიძლება მოხდეს, როდესაც არ არის საკმარისი მონაცემები ზუსტი მოდელის შესაქმნელად, ან როდესაც ცდილობთ ხაზოვანი მოდელის შექმნას არაწრფივი მონაცემებით. მეტი ტრენინგის მონაცემები ან მეტი ფუნქციები ხშირად ხელს შეუწყობს არასრულფასოვნების შემცირებას.
მაშ, რატომ არ უნდა შევქმნათ მოდელი, რომელიც სრულყოფილად ხსნის ტრენინგის ყველა პუნქტს? რა თქმა უნდა, სასურველია სრულყოფილი სიზუსტე? მოდელის შექმნა, რომელმაც ზედმეტად კარგად ისწავლა ტრენინგის მონაცემების ნიმუშები, არის ის, რაც იწვევს გადაჭარბებულ მორგებას. ტრენინგის მონაცემთა ნაკრები და სხვა, სამომავლო მონაცემთა ნაკრები, რომელსაც თქვენ აწარმოებთ მოდელში, არ იქნება ზუსტად იგივე. ისინი, სავარაუდოდ, ძალიან ჰგვანან მრავალი თვალსაზრისით, მაგრამ ისინი ასევე განსხვავდებიან ძირითადი თვალსაზრისით. მაშასადამე, მოდელის შემუშავება, რომელიც სრულყოფილად ხსნის სასწავლო მონაცემთა ბაზას, ნიშნავს, რომ თქვენ მიიღებთ თეორიას მახასიათებლებს შორის ურთიერთობის შესახებ, რომელიც კარგად არ არის განზოგადებული სხვა მონაცემთა ნაკრებისთვის.
Overfitting-ის გაგება
ზედმეტად მორგება ხდება მაშინ, როდესაც მოდელი ზედმეტად კარგად სწავლობს დეტალებს სასწავლო მონაცემთა ნაკრების ფარგლებში, რაც იწვევს მოდელს ზარალს, როდესაც პროგნოზები კეთდება გარე მონაცემებზე. ეს შეიძლება მოხდეს მაშინ, როდესაც მოდელი არა მხოლოდ სწავლობს მონაცემთა ნაკრების მახასიათებლებს, ის ასევე სწავლობს შემთხვევით რყევებს ან ხმაური მონაცემთა ნაკრების ფარგლებში, რაც მნიშვნელობას ანიჭებს ამ შემთხვევით/არამნიშვნელოვან მოვლენებს.
ზედმეტად მორგება უფრო ხშირად ხდება არაწრფივი მოდელების გამოყენებისას, რადგან ისინი უფრო მოქნილები არიან მონაცემთა ფუნქციების შესწავლისას. არაპარამეტრული მანქანათმცოდნეობის ალგორითმებს ხშირად აქვთ სხვადასხვა პარამეტრი და ტექნიკა, რომლებიც შეიძლება გამოყენებულ იქნას მოდელის მგრძნობელობის შესაზღუდად მონაცემების მიმართ და ამით შემცირდეს გადაჭარბებული მორგება. Როგორც მაგალითი, გადაწყვეტილების ხის მოდელები ისინი ძალიან მგრძნობიარენი არიან ზედმეტად მორგების მიმართ, მაგრამ ტექნიკა, რომელსაც ეწოდება pruning, შეიძლება გამოყენებულ იქნას შემთხვევითი მოხსნისთვის ზოგიერთი დეტალი, რომელიც მოდელმა ისწავლა.
თუ მოდელის პროგნოზებს X და Y ღერძებზე გამოსახავთ, გექნებათ წინასწარმეტყველების ხაზი, რომელიც ზიგზაგდება წინ და უკან, რაც ასახავს იმ ფაქტს, რომ მოდელი ძალიან ცდილობდა მონაცემთა ნაკრების ყველა წერტილის მოთავსებას. მისი ახსნა.
ზედმეტად მორგების კონტროლი
როცა მოდელს ვავარჯიშებთ, იდეალურად გვსურს, რომ მოდელმა შეცდომები არ დაუშვას. როდესაც მოდელის ეფექტურობა უახლოვდება სწორი პროგნოზების გაკეთებას სავარჯიშო მონაცემთა ნაკრების ყველა მონაცემის წერტილზე, მორგება ხდება უკეთესი. კარგი მორგების მქონე მოდელს შეუძლია ახსნას ტრენინგის თითქმის მთელი მონაცემთა ნაკრები ზედმეტი მორგების გარეშე.
როგორც მოდელი ვარჯიშობს, მისი შესრულება დროთა განმავლობაში უმჯობესდება. მოდელის შეცდომის კოეფიციენტი შემცირდება ტრენინგის დროის გასვლისას, მაგრამ ის მხოლოდ გარკვეულ მომენტამდე მცირდება. წერტილი, როდესაც მოდელის ეფექტურობა სატესტო კომპლექტზე ხელახლა იწყებს აწევას, ჩვეულებრივ არის წერტილი, როდესაც ხდება გადაჭარბებული მორგება. იმისათვის, რომ მოდელს საუკეთესოდ მოერგოს, ჩვენ გვინდა შევწყვიტოთ მოდელის ვარჯიში სავარჯიშო კომპლექტში ყველაზე დაბალი დანაკარგის წერტილში, სანამ შეცდომა ხელახლა დაიწყებს ზრდას. ოპტიმალური გაჩერების წერტილი შეიძლება განისაზღვროს მოდელის მუშაობის გრაფიკის მიხედვით ვარჯიშის დროს და ვარჯიშის შეჩერებით, როდესაც დანაკარგი ყველაზე დაბალია. თუმცა, ზედმეტობის კონტროლის ამ მეთოდის ერთ-ერთი რისკია ის, რომ ტესტის შესრულების საფუძველზე ტრენინგის საბოლოო წერტილის დაზუსტება ნიშნავს, რომ ტესტის მონაცემები გარკვეულწილად შედის ტრენინგის პროცედურაში და ის კარგავს თავის წმინდა „ხელშეუხებელ“ მონაცემთა სტატუსს.
არსებობს რამდენიმე განსხვავებული გზა, რომლითაც შეიძლება ზედმეტად მორგებასთან ბრძოლა. გადაჭარბებული მორგების შემცირების ერთ-ერთი მეთოდია ხელახალი შერჩევის ტაქტიკის გამოყენება, რომელიც მოქმედებს მოდელის სიზუსტის შეფასებით. ასევე შეგიძლიათ გამოიყენოთ ა დადასტურება მონაცემთა ნაკრები ტესტური ნაკრების გარდა და დახაზეთ ტრენინგის სიზუსტე ვალიდაციის ნაკრების მიხედვით ტესტის მონაცემთა ნაკრების ნაცვლად. ეს ინახავს თქვენს სატესტო მონაცემთა ბაზას უხილავი. ხელახალი შერჩევის პოპულარული მეთოდია K-folds cross-validation. ეს ტექნიკა საშუალებას გაძლევთ დაყოთ თქვენი მონაცემები ქვეჯგუფებად, რომლებზეც მოდელი გაწვრთნილი იყო და შემდეგ გაანალიზებულია მოდელის მოქმედება ქვეჯგუფებზე, რათა შეფასდეს, თუ როგორ იმოქმედებს მოდელი გარე მონაცემებზე.
ჯვარედინი ვალიდაციის გამოყენება უხილავ მონაცემებზე მოდელის სიზუსტის შესაფასებლად ერთ-ერთი საუკეთესო გზაა და ვალიდაციის მონაცემთა ნაკრების შერწყმისას, ხშირად შეიძლება მინიმუმამდე იყოს დაყვანილი.










