
人工知能
ChatGPT XNUMX 周年: AI インタラクションの未来を再構築する

ChatGPT の最初の年を振り返ると、このツールが AI シーンを大きく変えたことは明らかです。 2022 年末に発表された ChatGPT は、AI との対話を機械というよりも人間とチャットしているように感じられるユーザーフレンドリーな会話スタイルで際立っていました。 この新しいアプローチはすぐに世間の注目を集めました。 リリース後わずか 2023 日以内に、ChatGPT はすでに 100 万人のユーザーを魅了しました。 1.7 年初頭までに、この数は月間ユーザー数約 XNUMX 億人にまで膨れ上がり、XNUMX 月までにプラットフォームは世界中で約 XNUMX 億人の訪問者を集めました。 これらの数字は、その人気と有用性を雄弁に物語っています。
過去 4 年間、ユーザーは電子メールの作成や履歴書の更新などの単純なタスクからビジネスの成功に至るまで、ChatGPT を使用するあらゆる種類の創造的な方法を見つけてきました。 しかし、人々がそれをどのように使用しているかだけが問題ではありません。 テクノロジー自体は成長し、改善されました。 当初、ChatGPT は詳細なテキスト応答を提供する無料のサービスでした。 現在、ChatGPT-XNUMX を含む ChatGPT Plus があります。 この更新されたバージョンは、より多くのデータでトレーニングされ、間違った答えが減り、複雑な指示をよりよく理解できるようになりました。
最大のアップデートの XNUMX つは、ChatGPT が複数の方法で対話できるようになったことであり、聞いたり、話したり、画像を処理したりすることもできます。 つまり、モバイルアプリを通じて話しかけたり、写真を見せたりして応答を得ることができます。 これらの変化は AI の新たな可能性を切り開き、私たちの生活における AI の役割に対する人々の見方や考え方を変えました。
技術デモとしての始まりから、技術界の主要企業としての現在の地位に至るまで、ChatGPT の歩みは非常に印象的です。 当初、これは一般からのフィードバックを得てテクノロジーをテストし、改善する方法とみなされていました。 しかし、それはすぐに AI 環境の重要な部分になりました。 この成功は、教師あり学習と人間からのフィードバックの両方を使用して大規模言語モデル (LLM) を微調整することがいかに効果的であるかを示しています。 その結果、ChatGPT は幅広い質問やタスクを処理できます。
最も有能で汎用性の高い AI システムの開発競争により、オープンソース モデルと ChatGPT のような独自モデルの両方が急増しました。 それらの一般的な機能を理解するには、幅広いタスクにわたる包括的なベンチマークが必要です。 このセクションでは、これらのベンチマークを検討し、ChatGPT を含むさまざまなモデルが相互にどのように積み重なるかを明らかにします。
LLM の評価: ベンチマーク
- MTベンチ: このベンチマークは、ライティング、ロールプレイ、情報抽出、推論、数学、コーディング、STEM 知識、人文科学/社会科学の 4 つの領域にわたって、マルチターン会話と指示に従う能力をテストします。 GPT-XNUMX などのより強力な LLM が評価器として使用されます。
- アルパカエヴァル: AlpacaFarm 評価セットに基づいて、この LLM ベースの自動評価器は、GPT-4 や Claude などの高度な LLM からの応答に対してモデルのベンチマークを行い、候補モデルの勝率を計算します。
- LLM リーダーボードを開く: このリーダーボードは、言語モデル評価ハーネスを利用して、ゼロショット設定と少数ショット設定の両方で、推論の課題や一般知識テストを含む XNUMX つの主要なベンチマークで LLM を評価します。
- ビッグベンチ: この共同ベンチマークは、さまざまなトピックや言語にわたる 200 を超える新しい言語タスクをカバーしています。 LLM を調査し、その将来の機能を予測することを目的としています。
- チャットエヴァル: 自由形式の質問や従来の自然言語生成タスクについて、チームが自律的に議論し、さまざまなモデルからの応答の質を評価できるようにするマルチエージェント ディベート フレームワーク。
比較性能
一般的なベンチマークの観点から見ると、オープンソース LLM は目覚ましい進歩を示しています。 ラマ-2-70Bたとえば、特に指示データで微調整された後は、印象的な結果を達成しました。 その亜種である Llama-2-chat-70B は、AlpacaEval で 92.66% の勝率で優れており、GPT-3.5-turbo を上回りました。 ただし、GPT-4 は 95.28% の勝率で依然として最有力候補です。
ゼファー7Bより小型のモデルは、特に AlpacaEval と MT-Bench において、大型の 70B LLM に匹敵する機能を実証しました。 一方、多様な命令データで微調整された WizardLM-70B は、MT-Bench でオープンソース LLM の中で最高のスコアを獲得しました。 しかし、それでも GPT-3.5-turbo や GPT-4 には遅れをとっていた。
興味深いエントリーである GodziLLa2-70B は、Open LLM Leaderboard で競争力のあるスコアを達成し、多様なデータセットを組み合わせた実験モデルの可能性を示しました。 同様に、ゼロから開発された Yi-34B は、GPT-3.5-turbo に匹敵するスコアで際立っていましたが、GPT-4 にはわずかに遅れていました。
UltraLlama は、多様で高品質のデータを微調整することで、提案されたベンチマークで GPT-3.5-turbo に匹敵し、世界および専門知識の分野で GPT-XNUMX-turbo を上回りました。
スケールアップ: 巨大 LLM の台頭
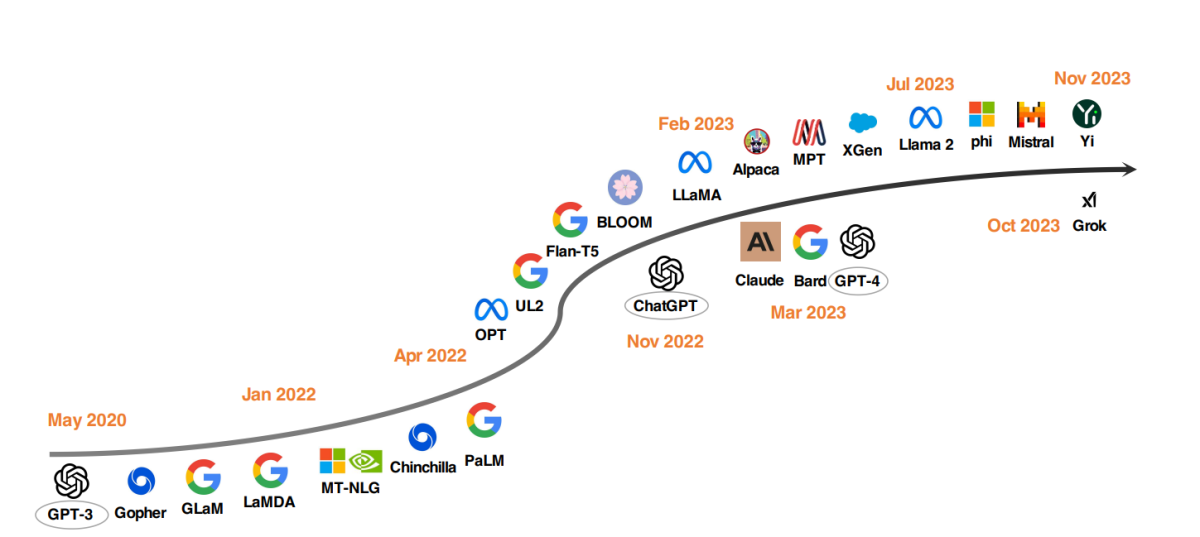
2020 年以降のトップ LLM モデル
LLM 開発における注目すべき傾向は、モデル パラメーターのスケールアップです。 Gopher、GLaM、LaMDA、MT-NLG、PaLM などのモデルは限界を押し広げ、最大 540 億のパラメーターを持つモデルに到達しました。 これらのモデルは優れた機能を示していますが、クローズドソースであるという性質により、より幅広い用途が制限されています。 この制限により、オープンソース LLM の開発への関心が高まり、この傾向は勢いを増しています。
モデルのサイズをスケールアップするのと並行して、研究者たちは別の戦略を模索してきました。 単にモデルを大きくするのではなく、より小さなモデルの事前トレーニングを改善することに重点を置いています。 例としては、チンチラや UL2 が挙げられますが、これらは多ければ多いほど良いとは限らないことを示しています。 賢い戦略を使えば効率的な結果も得られます。 さらに、言語モデルの命令チューニングにも大きな注目が集まっており、FLAN、T0、Flan-T5 などのプロジェクトがこの分野に大きく貢献しています。
ChatGPT カタリスト
OpenAIの導入 ChatGPT NLP 研究の転換点となりました。 OpenAI に対抗するために、Google や Anthropic などの企業は、それぞれ独自のモデル Bard と Claude を立ち上げました。 これらのモデルは多くのタスクで ChatGPT に匹敵するパフォーマンスを示しますが、OpenAI の最新モデルである GPT-4 には依然として遅れをとっています。 これらのモデルの成功は主に、ヒューマン フィードバックからの強化学習 (RLHF) によるものであり、この技術はさらなる改善を目指して研究の焦点が高まっています。
OpenAI の Q* (Q-Star) に関する噂と憶測
最近の報告 OpenAI の研究者らは、Q* (Q スターと発音) と呼ばれる新しいモデルの開発によって AI の大幅な進歩を達成した可能性があることを示唆しています。 Q* には小学校レベルの算数を実行する能力があると言われており、この偉業により、汎用人工知能 (AGI) へのマイルストーンとしての可能性について専門家の間で議論が巻き起こっています。 OpenAI はこれらのレポートについてコメントしていませんが、Q* の噂される能力はソーシャル メディアや AI 愛好家の間でかなりの興奮と憶測を引き起こしました。
ChatGPT や GPT-4 などの既存の言語モデルは、いくつかの数学的タスクは実行できますが、それらを確実に処理することに特に熟達していないため、Q* の開発は注目に値します。 課題は、AI モデルが現在ディープ ラーニングやトランスフォーマーを通じて行っているようにパターンを認識するだけでなく、抽象的な概念を推論して理解する必要があることにあります。 数学は推論のベンチマークであるため、AI が複数のステップを計画して実行する必要があり、抽象的な概念を深く理解していることを示します。 この能力は AI 能力の大幅な飛躍を示し、数学を超えて他の複雑なタスクにまで拡張される可能性があります。
しかし、専門家らはこの展開を誇張しすぎないよう警告している。 数学の問題を確実に解決する AI システムは素晴らしい成果ですが、必ずしも超インテリジェント AI や AGI の出現を示すものではありません。 OpenAI による取り組みを含む現在の AI 研究は、初歩的な問題に焦点を当てており、より複雑なタスクではさまざまな程度の成功を収めています。
Q* のようなアプリケーションの進歩の可能性は、個別指導から科学研究や工学の支援に至るまで、多岐にわたります。 ただし、期待を管理し、そのような進歩に伴う制限や安全性の懸念を認識することも重要です。 OpenAI の根本的な懸念である、AI が実存的リスクを引き起こすという懸念は、特に AI システムが現実世界とより連携し始めるにつれて、依然として重要です。
オープンソース LLM 運動
オープンソース LLM 研究を促進するために、Meta は Llama シリーズ モデルをリリースし、Llama に基づく新しい開発の波を引き起こしました。 これには、Alpaca、Vicuna、Lima、WizardLM などの命令データで微調整されたモデルが含まれます。 研究は、Llama ベースのフレームワーク内でのエージェント機能の強化、論理的推論、ロングコンテキスト モデリングにも分岐しています。
さらに、MPT、Falcon、XGen、Phi、Baichuan、 ミストラル, グロク、そしてイー。 これらの取り組みは、クローズドソース LLM の機能を民主化し、高度な AI ツールをよりアクセスしやすく効率的にするという取り組みを反映しています。
ヘルスケアにおける ChatGPT とオープンソース モデルの影響
私たちは、LLM が臨床メモの作成、償還のためのフォームの記入を支援し、医師の診断と治療計画をサポートする未来を見据えています。 これは、テクノロジー大手と医療機関の両方の注目を集めています。
Microsoftの エピックとの話し合い大手電子医療記録ソフトウェア プロバイダーである は、医療への LLM の統合を示唆しています。 カリフォルニア大学サンディエゴ校とスタンフォード大学医療センターではすでに取り組みが始まっています。 同様に、Googleの メイヨークリニックおよびアマゾンウェブサービスとのパートナーシップAI 臨床文書サービスである HealthScribe の開始は、この方向への大きな進歩を示しています。
しかし、こうした急速な展開により、医療の管理が企業の利益に譲渡されるのではないかという懸念が生じています。 これらの LLM は独自の性質を持っているため、評価が困難です。 収益性を理由に変更または中止される可能性があると、患者のケア、プライバシー、安全性が損なわれる可能性があります。
緊急に必要とされているのは、医療における LLM 開発に対するオープンで包括的なアプローチです。 医療機関、研究者、臨床医、患者は、世界中で協力して医療用のオープンソース LLM を構築する必要があります。 このアプローチは、Trillion Parameter Consortium と同様に、計算リソース、財政リソース、専門知識のプールを可能にします。













 |