
אבטחת סייבר
מדוע התקפות תדמית יריבות אינן בדיחה
תקיפת מערכות זיהוי תמונות עם תמונות יריבות מעוצבות בקפידה נחשבה להוכחה משעשעת אך טריוויאלית בחמש השנים האחרונות. עם זאת, מחקר חדש מאוסטרליה מצביע על כך ששימוש מזדמן במערכי נתונים פופולריים ביותר עבור פרויקטים מסחריים של AI עלול ליצור בעיית אבטחה חדשה מתמשכת.
כבר כמה שנים, קבוצה של אקדמאים באוניברסיטת אדלייד מנסה להסביר משהו חשוב באמת לגבי העתיד של מערכות זיהוי תמונות מבוססות בינה מלאכותית.
זה משהו שיהיה קשה (ויקר מאוד) לתקן ברגע זה, ואשר יהיה יקר באופן בלתי מכוון לתיקון ברגע שהמגמות הנוכחיות במחקר זיהוי תמונות יתפתחו במלואן לפריסות ממוסחרות ומתועשות תוך 5-10 שנים.
לפני שניכנס לזה, בואו נסתכל על פרח שמסווג כנשיא ברק אובמה, מתוך אחד מששת הסרטונים שהצוות פרסם באתר דף פרויקט:
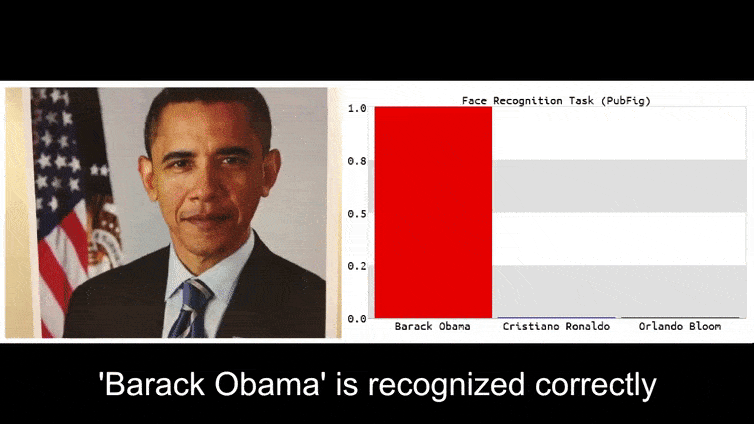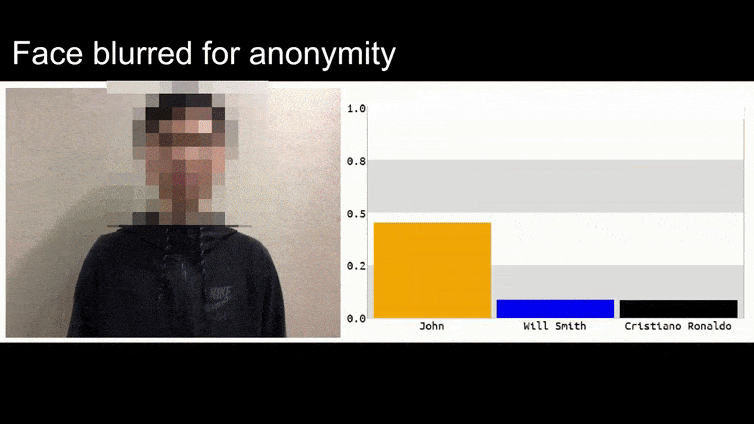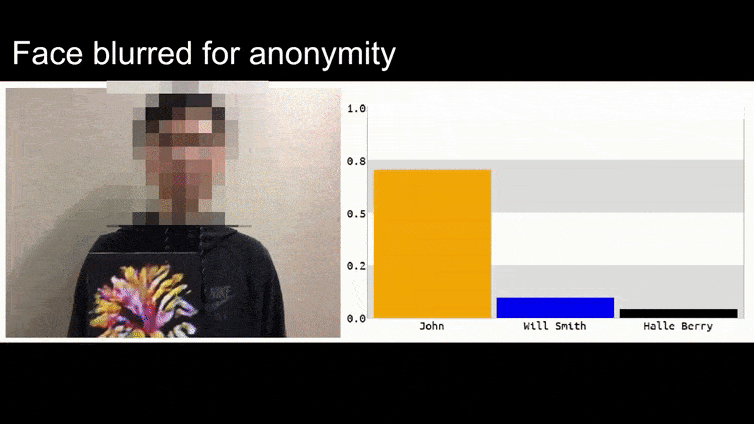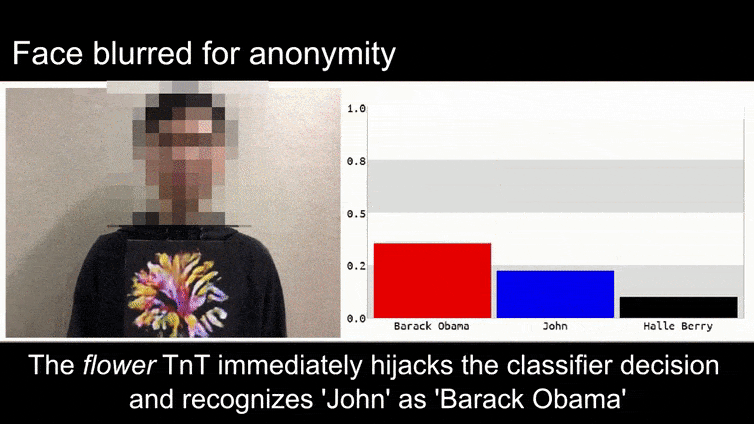
מקור: https://www.youtube.com/watch?v=Klepca1Ny3c
בתמונה שלמעלה, מערכת זיהוי פנים שיודעת בבירור לזהות את ברק אובמה מתעתעת בוודאות של 80% שאדם אנונימי שמחזיק תמונה יריב מעוצבת ומודפסת של פרח הוא גם ברק אובמה. למערכת אפילו לא אכפת ש'הפרצוף המזויף' נמצא על החזה של הנבדק, במקום על כתפיו.
למרות שזה מרשים שהחוקרים הצליחו להשיג סוג זה של לכידת זהות על ידי יצירת תמונה קוהרנטית (פרח) במקום רק הרעש האקראי הרגיל, נראה שמעללים מטופשים כמו זה צצים באופן די קבוע במחקרי אבטחה על ראיית מחשב . למשל, המשקפיים בדוגמאות מוזרות שהצליחו לשטות בזיהוי פנים שוב 2016, או תמונות יריבות שנוצרו במיוחד ניסיון לשכתב תמרורים.
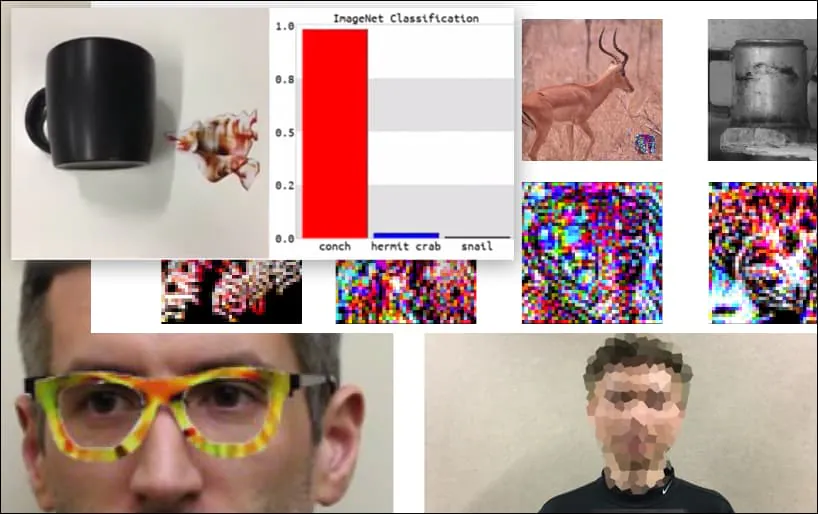
אם אתה מעוניין, המודל של Convolutional Neural Network (CNN) המותקף בדוגמה לעיל הוא VGGFace (VGG-16), הוכשר באוניברסיטת קולומביה מערך נתונים של PubFig. דגימות תקיפה אחרות שפותחו על ידי החוקרים השתמשו במשאבים שונים בשילובים שונים.

מקלדת מסווגת מחדש כקונכייה, בדגם WideResNet50 ב-ImageNet. החוקרים גם דאגו לכך שלמודל אין הטיה כלפי קונכיות. ראה את הסרטון המלא להדגמות מורחבות ונוספות בכתובת https://www.youtube.com/watch?v=dhTTjjrxIcU
זיהוי תמונה בתור וקטור התקפה עולה
ההתקפות המרשימות הרבות שהחוקרים מתארים וממחישים אינן ביקורת על מערכי נתונים בודדים או על ארכיטקטורות למידת מכונה ספציפיות המשתמשות בהן. אי אפשר להתגונן מפניהם בקלות על ידי החלפת מערכי נתונים או מודלים, הדרכה מחדש של מודלים או כל אחת מהתרופות ה"פשוטות" האחרות שגורמות למתרגלי ML ללגלג על הדגמות ספורדיות של תחבולות מסוג זה.
במקום זאת, מעלליו של צוות אדלייד מדגימים א חולשה מרכזית בכל הארכיטקטורה הנוכחית של פיתוח AI לזיהוי תמונה; חולשה שיכולה להיות מוגדרת לחשוף מערכות זיהוי תמונות עתידיות רבות למניפולציות קלות של תוקפים, ולהטיל כל אמצעי הגנה לאחר מכן על הרגל האחורית.
תארו לעצמכם את התמונות האחרונות של התקפות יריבות (כגון הפרח למעלה) מתווספות כ'ניצול של יום אפס' למערכות האבטחה של העתיד, בדיוק כפי שמסגרות אנטי-זדוניות ואנטי-וירוס הנוכחיות מעדכנות את הגדרות הווירוס שלהן מדי יום.
הפוטנציאל להתקפות תמונות יריבות חדשות יהיה בלתי נדלה, מכיוון שארכיטקטורת היסוד של המערכת לא צפתה בעיות במורד הזרם, כפי שהתרחשו עם האינטרנט, ה באג המילניום ו המגדל הנטוי של פיזה.
באיזה אופן, אם כן, אנחנו מכינים את הסצינה לכך?
קבלת הנתונים עבור התקפה
תמונות יריבות כגון הדוגמה של 'פרח' לעיל נוצרות על ידי גישה למערך הנתונים של התמונות שהכשירו את המודלים הממוחשבים. אינך זקוק לגישה 'פריבילגית' לנתוני אימון (או ארכיטקטורות מודל), שכן מערכי הנתונים הפופולריים ביותר (ודגמים מאומנים רבים) זמינים באופן נרחב בסצנת טורנטים חזקה ומתעדכנת כל הזמן.
לדוגמה, מערכי הנתונים המכובד של Goliath of Computer Vision, ImageNet זמין לטורנט על כל איטרציותיו הרבות, תוך עקיפת נהוג הגבלות, והפיכת אלמנטים משניים חיוניים לזמינים, כגון ערכות אימות.

מקור: https://academictorrents.com
אם יש לך את הנתונים, אתה יכול (כפי שמבחינים החוקרים של אדלייד) ביעילות 'להנדס לאחור' כל מערך נתונים פופולרי, כגון CityScapes, או CIFAR.
במקרה של PubFig, מערך הנתונים שאיפשר את 'פרח אובמה' בדוגמה הקודמת, אוניברסיטת קולומביה התייחסה למגמה הולכת וגוברת בנושאי זכויות יוצרים סביב הפצה מחדש של מערכי תמונות על ידי הדרכה לחוקרים כיצד להתרבות מערך הנתונים באמצעות קישורים אוצרים, במקום להפוך את האוסף לזמין ישירות, התבוננות "נראה שזו הדרך שבה נראה שמסדי נתונים גדולים מבוססי אינטרנט אחרים מתפתחים".
ברוב המקרים, זה לא הכרחי: Kaggle הערכות שעשרת מערכי התמונות הפופולריים ביותר בראייה ממוחשבת הם: CIFAR-10 ו-CIFAR-100 (שניהם להורדה ישירה); CALTECH-101 ו-256 (שניהם זמינים, ושניהם זמינים כעת כטורנטים); MNIST (זמין רשמית, גם בטורנטים); ImageNet (ראה למעלה); פסקל VOC (זמין, גם בטורנטים); MS COCO (זמין, ובטורנטים); Sports-1M (זמין); ו-YouTube-8M (זמין).
זמינות זו מייצגת גם את המגוון הרחב יותר של מערכי נתונים זמינים של תמונות של ראייה ממוחשבת, שכן ערפול הוא מוות בתרבות פיתוח קוד פתוח של 'פרסם או גסיסה'.
בכל מקרה, המחסור של ניתן לניהול מערכי נתונים חדשים, העלות הגבוהה של פיתוח ערכת תמונה, ההסתמכות על 'מועדפים ישנים' והנטייה פשוט התאם מערכי נתונים ישנים יותר כולם מחמירים את הבעיה המתוארת בנייר אדלייד החדש.
ביקורות אופייניות על שיטות התקפת תמונה יריבות
הביקורת השכיחה והעיקשת ביותר של מהנדסי למידת מכונה נגד היעילות של טכניקת התקפת התמונה האדוורסרית האחרונה היא שההתקפה היא ספציפי למערך נתונים מסוים, למודל מסוים או לשניהם; שהיא לא 'ניתנת להכללה' למערכות אחרות; וכתוצאה מכך, מייצג רק איום טריוויאלי.
התלונה השנייה בשכיחותה היא שהתקפת התדמית האדוורסרית היא 'קופסה לבנה', כלומר תזדקק לגישה ישירה לסביבת האימון או לנתונים. זה אכן תרחיש לא סביר, ברוב המקרים - למשל, אם אתה רוצה לנצל את תהליך האימון עבור מערכות זיהוי הפנים של משטרת המטרופולין של לונדון, תצטרך לפרוץ את דרכך NEC, או עם קונסולה או גרזן.
ה-'DNA' לטווח ארוך של מערכי נתונים פופולריים של ראיית מחשב
לגבי הביקורת הראשונה, עלינו לשקול לא רק שקומץ של מערכי נתונים של ראייה ממוחשבת שולטים בתעשייה לפי מגזר משנה לשנה (כלומר ImageNet עבור סוגים מרובים של אובייקטים, CityScapes עבור סצינות נהיגה, וכן FFHQ לזיהוי פנים); אלא גם שכנתוני תמונה מוערים פשוטים, הם 'אגנוסטיים לפלטפורמה' וניתנים להעברה גבוהה.
בהתאם ליכולות שלה, כל ארכיטקטורת אימון ראייה ממוחשבת תמצא כמה תכונות של אובייקטים ומחלקות במערך הנתונים של ImageNet. ארכיטקטורות מסוימות עשויות למצוא יותר תכונות מאחרות, או ליצור קשרים שימושיים יותר מאחרות, אבל את כל צריך למצוא לפחות את התכונות ברמה הגבוהה ביותר:

נתוני ImageNet, עם המספר המינימלי בר-קיימא של זיהויים נכונים - תכונות 'רמה גבוהה'.
אלו התכונות 'ברמה גבוהה' המייחדות ו'טביעת אצבע' של מערך נתונים, והן ה'ווים' האמינים שאפשר לתלות עליהם מתודולוגיית התקפת תמונות יריבות ארוכת טווח שיכולה לפוש בין מערכות שונות, ולצמוח במקביל ל-' מערך הנתונים הישן, שכן האחרון מונצח במחקר ובמוצרים חדשים.
ארכיטקטורה מתוחכמת יותר תייצר זיהויים, תכונות ומחלקות מדויקות יותר ומפורטות יותר:

עם זאת, ככל שמחולל התקפות יריב מסתמך על אלה להוריד תכונות (כלומר 'זכר קווקזי צעיר' במקום 'פנים'), כך זה יהיה פחות יעיל בארכיטקטורות מוצלבות או מאוחרות יותר המשתמשות גרסאות שונות של מערך הנתונים המקורי - כגון קבוצת משנה או קבוצה מסוננת, כאשר רבות מהתמונות המקוריות ממערך הנתונים המלא אינן קיימות:

התקפות יריבות על 'מאפס', דוגמניות שהוכשרו מראש
מה לגבי מקרים שבהם אתה פשוט מוריד מודל מאומן מראש שהוכשר במקור על מערך נתונים פופולרי מאוד, ונותן לו נתונים חדשים לחלוטין?
הדגם כבר עבר הכשרה (למשל) ב-ImageNet, וכל מה שנותר הוא משקולות, שאולי לקח שבועות או חודשים להתאמן, וכעת הם מוכנים לעזור לך לזהות אובייקטים דומים לאלו שהיו קיימים בנתונים המקוריים (שעכשיו נעדרים).

עם הסרת הנתונים המקוריים מארכיטקטורת ההכשרה, מה שנותר הוא ה"נטייה" של המודל לסווג אובייקטים כפי שהוא למד לעשות במקור, מה שבעצם יגרום לרבות מה"חתימות" המקוריות להשתנות ולהפוך לפגיעות פעם אחת. שוב לאותן שיטות התקפת תמונה היריב הישנות.
המשקולות האלה יקרות ערך. בלי הנתונים or המשקולות, בעצם יש לך ארכיטקטורה ריקה ללא נתונים. אתה תצטרך לאמן אותו מאפס, תוך הוצאות גדולות של זמן ומשאבי מחשוב, בדיוק כמו שעשו המחברים המקוריים (כנראה בחומרה חזקה יותר ועם תקציב גבוה יותר ממה שיש לך).
הצרה היא שהמשקולות כבר די מעוצבות וגמישות. למרות שהם יסתגלו במקצת באימונים, הם יתנהגו בדומה לנתונים החדשים שלך כפי שהתנהגו בנתונים המקוריים, וייצרו תכונות חתימה שמערכת תקיפה יריבה יכולה להזין בחזרה.
בטווח הארוך, גם זה משמר את ה'DNA' של מערכי נתונים של ראיית מחשב בן שתים עשרה או יותר, וייתכן שעברה אבולוציה בולטת ממאמצי קוד פתוח ועד לפריסות ממוסחרות - אפילו כאשר נתוני ההדרכה המקוריים הושמטו לחלוטין בתחילת הפרויקט. ייתכן שחלק מהפריסות המסחריות הללו לא יתרחשו במשך שנים עדיין.
אין צורך בקופסה לבנה
בנוגע לביקורת השכיחה השנייה על מערכות התקפת תמונות יריבות, מחברי המאמר החדש גילו שהיכולת שלהם לרמות מערכות זיהוי באמצעות תמונות של פרחים מעוצבות ניתנת להעברה על פני מספר ארכיטקטורות.
למרות שהבחינו כי שיטת 'התיקונים האוניברסליים היריביים האוניברסליים' (TnT) שלהם היא הראשונה שמשתמשת בתמונות ניתנות לזיהוי (ולא רעש הפרעות אקראי) כדי לשטות במערכות זיהוי תמונות, המחברים טוענים גם:
"[TnTs] יעילים נגד מספר מסווגים חדישים, החל משימוש נרחב WideResNet50 במשימת זיהוי חזותי בקנה מידה גדול של אימג'נט מערך נתונים למודלים של VGG-פנים במשימת זיהוי הפנים של PubFig מערך הנתונים בשניהם ממוקד ו לא ממוקד התקפות.
'TnTs יכולים להחזיק: i) הנטורליזם שניתן להשיג [עם] טריגרים המשמשים בשיטות התקפה טרויאניות; ו-ii) ההכללה וההעברה של דוגמאות ליריבות לרשתות אחרות.
"זה מעלה חששות בטיחות ואבטחה לגבי DNN שכבר נפרסו, כמו גם פריסות DNN עתידיות שבהן תוקפים יכולים להשתמש בתיקוני אובייקט בלתי בולטים למראה טבעי כדי להטעות מערכות רשתות עצביות מבלי להתעסק במודל ולהסתכן בגילוי."
המחברים מציעים כי אמצעי נגד קונבנציונליים, כגון השפלה של Clean Acc. של רשת, תיאורטית יכול לספק הגנה כלשהי מפני תיקוני TnT, אבל זה "TnTs עדיין יכולים לעקוף בהצלחה את שיטות ההגנה הניתנות להוכחה של SOTA כאשר רוב מערכות ההגנה משיגות 0% יציבות".
פתרונות אפשריים אחרים כוללים למידה מאוחדת, שבו מקור התמונות התורמות מוגן, וגישות חדשות שיכולות "להצפין" נתונים ישירות בזמן האימון, כמו אחת לאחרונה הציע על ידי אוניברסיטת נאנג'ינג לאווירונאוטיקה ואסטרונאוטיקה.
גם במקרים אלה, יהיה חשוב להתאמן על באמת חדש נתוני תמונה - עד עכשיו התמונות והביאורים הקשורים בקאדר הקטן של מערכי ה-CV הפופולריים ביותר מוטמעים במחזורי פיתוח ברחבי העולם עד כדי כך שהם דומים לתוכנה יותר מאשר נתונים; תוכנה שלעתים קרובות לא עודכנה בצורה ניכרת במשך שנים.
סיכום
התקפות תמונה יריבות מתאפשרות לא רק על ידי שיטות למידת מכונה בקוד פתוח, אלא גם על ידי תרבות פיתוח בינה מלאכותית ארגונית שמונעת לעשות שימוש חוזר במערכים מבוססים היטב של ראייה ממוחשבת מכמה סיבות: הם כבר הוכיחו יעילות; הם הרבה יותר זולים מ'להתחיל מאפס'; והם מתוחזקים ומתעדכנים על ידי מוחות וארגונים חלוציים ברחבי האקדמיה והתעשייה, ברמות מימון ואיוש שקשה יהיה לשכפל לחברה אחת.
בנוסף, במקרים רבים שבהם הנתונים אינם מקוריים (בניגוד ל-CityScapes), התמונות נאספו לפני מחלוקות אחרונות סביב פרטיות ואיסוף נתונים, והותירו את מערכי הנתונים הישנים הללו במעין צורף משפטי למחצה זה עשוי להיראות בצורה מנחמת כמו 'נמל בטוח', מנקודת מבט של חברה.
התקפות TnT! טלאים אוניברסליים טבעיים נגד מערכות רשת עצביות עמוקות נכתב בשיתוף באו ג'יה דואן, מינהוי שוה, אהסן אבסנג'אד, דמית סי רנאסינגה מאוניברסיטת אדלייד, יחד עם שיקינג מא מהמחלקה למדעי המחשב באוניברסיטת רוטגרס.
עודכן ב-1 בדצמבר 2021, 7:06 GMT+2 - שגיאת הקלדה תוקנה.















