
בינה מלאכותית
InstructIR: שחזור תמונה באיכות גבוהה בעקבות הוראות אנושיות

תמונה יכולה להעביר הרבה מאוד, אך היא עשויה גם להיות פגומה על ידי נושאים שונים כגון טשטוש תנועה, אובך, רעש וטווח דינמי נמוך. בעיות אלו, המכונה בדרך כלל השפלות בראייה ממוחשבת ברמה נמוכה, יכולות לנבוע מתנאים סביבתיים קשים כמו חום או גשם או ממגבלות של המצלמה עצמה. שחזור תמונה מייצג אתגר מרכזי בראייה ממוחשבת, השאיפה לשחזר תמונה איכותית ונקייה מאלה שמציגה השפלות כאלה. שחזור תמונה הוא מורכב מכיוון שעשויים להיות מספר פתרונות לשחזור כל תמונה נתונה. חלק מהגישות מכוונות להדרדרות ספציפיות, כגון הפחתת רעש או הסרת טשטוש או אובך.
בעוד ששיטות אלה יכולות להניב תוצאות טובות עבור בעיות מסוימות, הן לרוב מתקשות להכליל על פני סוגים שונים של השפלה. מסגרות רבות משתמשות ברשת עצבית גנרית עבור מגוון רחב של משימות שחזור תמונה, אך כל רשתות אלו מאומנות בנפרד. הצורך במודלים שונים עבור כל סוג של השפלה הופך גישה זו ליקרה וגוזלת זמן חישובית, מה שמוביל להתמקדות במודלים של שחזור All-In-One בהתפתחויות האחרונות. מודלים אלה משתמשים במודל שחזור יחיד ועיוור עמוק המתייחס לרמות וסוגים מרובים של השפלה, לעתים קרובות תוך שימוש בהנחיות או וקטורי הנחיה ספציפיים לשפלה כדי לשפר את הביצועים. למרות שדגמי All-In-One בדרך כלל מציגים תוצאות מבטיחות, הם עדיין מתמודדים עם אתגרים עם בעיות הפוכות.
InstructIR מייצגת גישה פורצת דרך בתחום, בהיותה הראשונה שחזור תמונה מסגרת שנועדה להנחות את מודל השיקום באמצעות הוראות שנכתבו על ידי אדם. הוא יכול לעבד הנחיות בשפה טבעית כדי לשחזר תמונות באיכות גבוהה מתמונות מושפלות, בהתחשב בסוגי השפלה שונים. InstructIR קובע סטנדרט חדש בביצועים עבור מגוון רחב של משימות שחזור תמונה, כולל ניקוי משקעים, שחרור רעלים, שחרור אובך, טשטוש ושיפור תמונות בתאורה נמוכה.
מאמר זה נועד לכסות את המסגרת של InstructIR לעומק, ואנו חוקרים את המנגנון, המתודולוגיה, הארכיטקטורה של המסגרת יחד עם ההשוואה שלה למסגרות ליצירת תמונות ווידאו מתקדמות. אז בואו נתחיל.
InstructIR: שחזור תמונה באיכות גבוהה
שחזור תמונה הוא בעיה מהותית בראייה ממוחשבת שכן מטרתו לשחזר תמונה נקייה באיכות גבוהה מתמונה המדגימה השפלות. בראייה ממוחשבת ברמה נמוכה, Degradations הוא מונח המשמש לייצג אפקטים לא נעימים שנצפו בתוך תמונה כמו טשטוש תנועה, אובך, רעש, טווח דינמי נמוך ועוד. הסיבה לכך ששחזור תמונה הוא אתגר הפוך מורכב היא מכיוון שיכולים להיות מספר פתרונות שונים לשחזור כל תמונה. מסגרות מסוימות מתמקדות בהשפלות ספציפיות כמו הפחתת רעש מופעים או הפחתת הרעש של התמונה, בעוד שאחרות עשויות להתמקד יותר בהסרת טשטוש או טשטוש, או ניקוי אובך או חוסר ערוב.
שיטות למידה עמוקה לאחרונה הציגו ביצועים חזקים ועקביים יותר בהשוואה לשיטות שחזור תמונה מסורתיות. מודלים אלה של שחזור תמונה של למידה עמוקה מציעים להשתמש ברשתות עצביות המבוססות על רובוטריקים ורשתות עצביות קונבולוציוניות. ניתן לאמן מודלים אלה באופן עצמאי למשימות מגוונות של שחזור תמונה, ויש להם גם את היכולת ללכוד אינטראקציות מקומיות וגלובליות, ולשפר אותן, וכתוצאה מכך ביצועים משביעי רצון ועקביים. למרות שחלק מהשיטות הללו עשויות לעבוד בצורה נאותה עבור סוגים ספציפיים של השפלה, הן בדרך כלל אינן מבצעות אקסטרפולציה טובה לסוגים שונים של השפלה. יתר על כן, בעוד מסגרות קיימות רבות משתמשות באותה רשת עצבית עבור מספר רב של משימות שחזור תמונה, כל ניסוח רשת עצבית מאומן בנפרד. מכאן, ברור ששימוש במודל עצבי נפרד לכל השפלה אפשרית אינה מעשית וגוזלת זמן, וזו הסיבה שמסגרות שחזור תמונות האחרונות התרכזו בפרוקסי שחזור All-In-One.
מודלים של שחזור תמונות All-In-One או Multi-Degradation או Multi-Task צוברים פופולריות בתחום הראייה הממוחשבת מאחר והם מסוגלים לשחזר מספר סוגים ורמות של השפלות בתמונה ללא צורך באימון הדגמים באופן עצמאי עבור כל השפלה. . מודלים של שחזור תמונה של All-In-One משתמשים במודל שחזור תמונה עיוור עמוק אחד כדי להתמודד עם סוגים ורמות שונות של השחתת תמונה. מודלים שונים של All-In-One מיישמים גישות שונות כדי להנחות את המודל העיוור לשחזר את התמונה השפלה, למשל, מודל עזר לסיווג השפלה או וקטורי הנחיה רב-ממדיים או הנחיות שיעזרו למודל לשחזר סוגים שונים של השפלה בתוך תמונה.
עם זאת, אנו מגיעים למניפולציית תמונה מבוססת טקסט מכיוון שהיא יושמה על ידי מספר מסגרות בשנים האחרונות ליצירת טקסט לתמונה, ומשימות עריכת תמונות מבוססות טקסט. מודלים אלה משתמשים לעתים קרובות בהנחיות טקסט כדי לתאר פעולות או תמונות יחד עם מודלים מבוססי דיפוזיה כדי ליצור את התמונות המתאימות. ההשראה העיקרית למסגרת InstructIR היא המסגרת InstructPix2Pix המאפשרת למודל לערוך את התמונה באמצעות הוראות משתמש שמורות לדגם איזו פעולה לבצע במקום תוויות טקסט, תיאורים או כיתובים של תמונת הקלט. כתוצאה מכך, משתמשים יכולים להשתמש בטקסטים כתובים טבעיים כדי להנחות את המודל איזו פעולה לבצע ללא צורך במתן תמונות לדוגמה או תיאורי תמונה נוספים.
בהתבסס על יסודות אלה, מסגרת InstructIR היא מודל הראייה הממוחשבת הראשון אי פעם שמשתמש בהוראות שנכתבו על ידי אדם כדי להשיג שחזור תמונה ולפתור בעיות הפוכות. עבור הנחיות בשפה טבעית, מודל InstructIR יכול לשחזר תמונות באיכות גבוהה מעמיתיהם המושפלים וגם לוקח בחשבון מספר סוגי השפלה. המסגרת של InstructIR מסוגלת לספק ביצועים מתקדמים במגוון רחב של משימות שחזור תמונה, לרבות ריקון תמונה, שחרור רעלים, שחרור אובך, טשטוש ושיפור תמונה בתאורה נמוכה. בניגוד לעבודות קיימות המשיגות שחזור תמונה באמצעות וקטורי הדרכה נלמדים או הטמעות הנחיות, המסגרת של InstructIR משתמשת בהנחיות משתמש גולמיות בצורת טקסט. המסגרת של InstructIR מסוגלת להכליל לשחזור תמונות באמצעות הוראות כתובות אנושיות, והמודל ה-All-in-One היחיד המיושם על ידי InstructIR מכסה יותר משימות שחזור מאשר דגמים קודמים. האיור הבא מדגים את דוגמאות השחזור המגוונות של מסגרת InstructIR.

InstructIR: שיטה ואדריכלות
בבסיסה, מסגרת InstructIR מורכבת מקודד טקסט ומודל תמונה. המודל משתמש במסגרת NAFNet, מודל שחזור תמונה יעיל העוקב אחר ארכיטקטורת U-Net כמודל התמונה. יתר על כן, המודל מיישם טכניקות ניתוב משימות כדי ללמוד משימות מרובות באמצעות מודל אחד בהצלחה. האיור הבא ממחיש את גישת ההדרכה וההערכה עבור מסגרת InstructIR.

שואבת השראה ממודל InstructPix2Pix, מסגרת InstructIR מאמצת הוראות כתובות אנושיות כמנגנון הבקרה מאחר ואין צורך של המשתמש לספק מידע נוסף. הוראות אלו מציעות דרך אקספרסיבית וברורה לאינטראקציה המאפשרת למשתמשים להצביע על המיקום המדויק וסוג ההשפלה בתמונה. יתרה מזאת, שימוש בהנחיות משתמש במקום בהנחיות ספציפיות לפגיעה קבועה משפר את השימושיות והיישומים של המודל שכן ניתן להשתמש בו גם על ידי משתמשים חסרי המומחיות הנדרשת בתחום. כדי לצייד את המסגרת של InstructIR עם יכולת להבין הנחיות מגוונות, המודל משתמש ב-GPT-4, מודל שפה גדול ליצירת בקשות מגוונות, עם הנחיות מעורפלות ולא ברורות שהוסרו לאחר תהליך סינון.
מקודד טקסט
מקודד טקסט משמש על ידי מודלים של שפות כדי למפות את הנחיות המשתמש להטמעת טקסט או לייצוג וקטור בגודל קבוע. באופן מסורתי, מקודד הטקסט של a דגם CLIP הוא מרכיב חיוני ליצירת תמונות מבוססות טקסט, ומודלים של מניפולציה של תמונות מבוססות טקסט כדי לקודד הנחיות משתמש מכיוון שמסגרת CLIP מצטיינת בהנחיות ויזואליות. עם זאת, רוב הפעמים, הנחיות משתמשים להשפלה מכילות מעט תוכן ויזואלי, ולכן, מה שהופך את מקודדי ה-CLIP הגדולים לחסרי תועלת עבור משימות כאלה, שכן זה יפגע משמעותית ביעילות. כדי להתמודד עם בעיה זו, המסגרת של InstructIR בוחרת במקודד משפטים מבוסס טקסט שמאומן לקודד משפטים במרחב הטמעה משמעותי. מקודדי משפטים הוכשרו מראש על מיליוני דוגמאות ועם זאת, הם קומפקטיים ויעילים בהשוואה למקודדי טקסט מסורתיים מבוססי CLIP תוך שהם בעלי יכולת לקודד את הסמנטיקה של הנחיות משתמש מגוונות.
הנחיות טקסט
היבט מרכזי של מסגרת InstructIR הוא יישום ההוראה המקודדת כמנגנון בקרה עבור מודל התמונה. בהתבסס על כך, ובהשראת ניתוב משימות עבור למידת משימות רבות, המסגרת של InstructIR מציעה בלוק בנייה של הוראה או ICB כדי לאפשר טרנספורמציות ספציפיות למשימה בתוך המודל. ניתוב משימות קונבנציונלי מחיל מסכות בינאריות ספציפיות למשימה על תכונות ערוץ. עם זאת, מכיוון שמסגרת InstructIR אינה יודעת את השפלה, טכניקה זו אינה מיושמת ישירות. יתרה מזאת, עבור תכונות תמונה וההוראות המקודדות, מסגרת InstructIR מיישמת ניתוב משימות, ומייצרת את המסכה באמצעות שכבה ליניארית המופעלת באמצעות פונקציית Sigmoid כדי לייצר קבוצה של משקלים בהתאם להטמעות הטקסט, ובכך לקבל ממד C לפי מסכה בינארית ערוץ. המודל משפר עוד יותר את התכונות המותנות באמצעות NAFBlock, ומשתמש ב-NAFBlock ו-Instruction Conditioned Block כדי להתנות את התכונות הן בבלוק המקודד והן בבלוק המפענח.
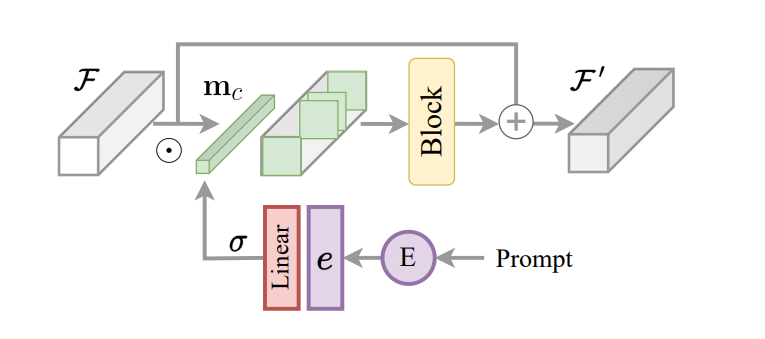
למרות שמסגרת InstructIR אינה מתנתה במפורש את מסנני הרשת העצבית, המסכה מאפשרת למודל לבחור את הערוצים הרלוונטיים ביותר על בסיס הוראת התמונה והמידע.
InstructIR: יישום ותוצאות
מודל ה-InstructIR ניתן לאימון מקצה לקצה, ומודל התמונה אינו דורש הדרכה מוקדמת. יש לאמן רק את תחזיות הטמעת הטקסט וראש הסיווג. מקודד הטקסט מאותחל באמצעות מקודד BGE, מקודד דמוי BERT שהוכשר מראש על כמות עצומה של נתונים מפוקחים ובלתי מפוקחים עבור קידוד משפטי מטרה גנרי. המסגרת של InstructIR משתמשת במודל NAFNet כמודל תמונה, והארכיטקטורה של NAFNet מורכבת ממפענח מקודד בן 4 רמות עם מספר משתנה של בלוקים בכל רמה. הדגם מוסיף גם 4 בלוקים אמצעיים בין המקודד למפענח כדי לשפר עוד יותר את התכונות. יתר על כן, במקום לשרשר עבור חיבורי הדילוג, המפענח מיישם הוספה, ומודל ה-InstructIR מיישם רק את ICB או Instruction Conditioned Block עבור ניתוב משימות רק במקודד ובמפענח. בהמשך, מודל ה-InstructIR עובר אופטימיזציה באמצעות האובדן בין התמונה המשוחזרת לבין התמונה הנקייה של האמת, ואובדן האנטרופיה הצולבת משמש לראש סיווג הכוונות של מקודד הטקסט. מודל ה-InstructIR משתמש בממטב AdamW עם גודל אצווה של 32, וקצב למידה של 5e-4 במשך כמעט 500 עידנים, וכן מיישם את דעיכת קצב הלמידה של חישול הקוסינוס. מכיוון שמודל התמונה במסגרת InstructIR כולל רק 16 מיליון פרמטרים, ויש רק 100 אלף פרמטרים של הקרנת טקסט נלמדים, ניתן לאמן את המסגרת של InstructIR בקלות על GPUs סטנדרטיים, ובכך להפחית את עלויות החישוב ולהגדיל את הישימות.
תוצאות השפלה מרובות
עבור השפלות מרובות ושחזורים מרובי משימות, מסגרת InstructIR מגדירה שתי הגדרות ראשוניות:
- תלת מימד עבור מודלים של שלוש השפלות להתמודדות עם בעיות השפלה כמו שחרור אובך, שחרור רעלים וניקוי ריקנות.
- 5D עבור חמישה מודלים של השפלה להתמודדות עם בעיות השפלה כמו הפחתה של תמונה, שיפורי תאורה חלשה, דה-ערב, שחרור רעלים וריקון.
הביצועים של דגמי 5D מודגמים בטבלה הבאה, ומשווים אותם עם שחזור תמונה מתקדם ודגמי All-in-One.

כפי שניתן לראות, המסגרת של InstructIR עם מודל תמונה פשוט ורק 16 מיליון פרמטרים יכולה להתמודד בהצלחה עם חמש משימות שונות של שחזור תמונה הודות להנחיה מבוססת הוראות, ומספקת תוצאות תחרותיות. הטבלה הבאה מדגימה את הביצועים של המסגרת במודלים תלת מימדיים, והתוצאות דומות לתוצאות לעיל.

גולת הכותרת העיקרית של מסגרת InstructIR היא שחזור תמונה מבוסס הוראות, והאיור הבא מדגים את היכולות המדהימות של מודל InstructIR להבין מגוון רחב של הוראות עבור משימה נתונה. כמו כן, עבור הוראה יריבות, מודל InstructIR מבצע זהות שאינה מאולצת.

מחשבות סופיות
שחזור תמונה הוא בעיה מהותית בראייה ממוחשבת שכן מטרתו לשחזר תמונה נקייה באיכות גבוהה מתמונה המדגימה השפלות. בראייה ממוחשבת ברמה נמוכה, Degradations הוא מונח המשמש לייצג אפקטים לא נעימים שנצפו בתוך תמונה כמו טשטוש תנועה, אובך, רעש, טווח דינמי נמוך ועוד. במאמר זה, דיברנו על InstructIR, המסגרת הראשונה בעולם לשחזור תמונות שמטרתה להנחות את מודל שחזור התמונה באמצעות הוראות שנכתבו על ידי אדם. עבור הנחיות בשפה טבעית, מודל InstructIR יכול לשחזר תמונות באיכות גבוהה מעמיתיהם המושפלים וגם לוקח בחשבון מספר סוגי השפלה. המסגרת של InstructIR מסוגלת לספק ביצועים מתקדמים במגוון רחב של משימות שחזור תמונה, לרבות ריקון תמונה, שחרור רעלים, שחרור אובך, טשטוש ושיפור תמונה בתאורה נמוכה.















