
בינה מלאכותית
LipSync3D של גוגל מציע סנכרון משופר של תנועת הפה 'Deepfaked'

A שיתוף פעולה בין חוקרי בינה מלאכותית של גוגל והמכון ההודי לטכנולוגיה Kharagpur מציעה מסגרת חדשה לסינתזה של ראשים מדברים מתוכן אודיו. מטרת הפרויקט היא לייצר דרכים אופטימליות ובעלות משאבים סבירים ליצירת תוכן וידאו 'ראש מדבר' מאודיו, למטרות סינכרון תנועות שפתיים לאודיו מדובב או מתורגם במכונה, ולשימוש באווטרים, ביישומים אינטראקטיביים ובשאר סביבות בזמן אמת.

מקור: https://www.youtube.com/watch?v=L1StbX9OznY
מודלים של למידת מכונה שהוכשרו בתהליך - הנקראים LipSync3D - דורשים רק סרטון בודד של זהות הפנים של המטרה כנתוני קלט. צינור הכנת הנתונים מפריד בין מיצוי גיאומטריית הפנים לבין הערכת תאורה והיבטים אחרים של סרטון קלט, ומאפשר אימון חסכוני וממוקד יותר.
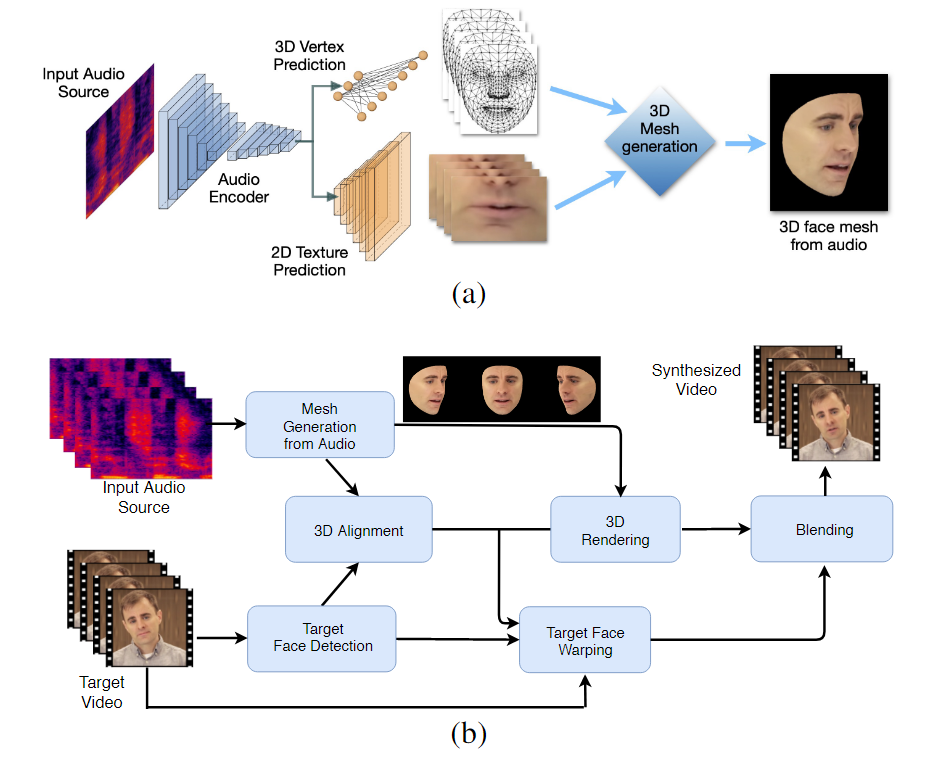
זרימת העבודה הדו-שלבית של LipSync3D. למעלה, יצירת פנים תלת-ממדיות בעל מרקם דינמי מאודיו 'המטרה'; להלן, הכנסת הרשת שנוצרה לסרטון יעד.
למעשה, התרומה הבולטת ביותר של LipSync3D לגוף המאמץ המחקרי בתחום זה עשויה להיות אלגוריתם נורמליזציה של התאורה שלו, המנתק אימון והארת מסקנות.

ניתוק נתוני התאורה מהגיאומטריה הכללית עוזר ל-LipSync3D לייצר פלט תנועתי שפתיים מציאותי יותר בתנאים מאתגרים. גישות אחרות של השנים האחרונות הגבילו את עצמן לתנאי תאורה 'קבועים' שלא יחשפו את יכולתם המוגבלת יותר מבחינה זו.
במהלך עיבוד מקדים של מסגרות נתוני הקלט, על המערכת לזהות ולהסיר נקודות ספקולריות, שכן אלו הן ספציפיות לתנאי התאורה שבהם צולם הסרטון, ובדרך אחרת יפריעו לתהליך ההדלקה מחדש.

LipSync3D, כפי ששמו מרמז, אינו מבצע ניתוח פיקסלים בלבד על הפנים שהוא מעריך, אלא משתמש באופן פעיל בנקודות ציון פנים מזוהות כדי ליצור רשתות תנועתיות בסגנון CGI, יחד עם המרקמים ה'פרוש' שעוטפים אותם ב-CGI מסורתי. צנרת.

נורמליזציה של תנוחה ב- LipSync3D. בצד שמאל מוצגות מסגרות הקלט והתכונות שזוהו; באמצע, הקודקודים המנורמלים של הערכת הרשת שנוצרה; ומימין, אטלס הטקסטורה המקביל, המספק את האמת הבסיסית לחיזוי המרקם. מקור: https://arxiv.org/pdf/2106.04185.pdf
מלבד שיטת ההדלקה מחדש החדשנית, החוקרים טוענים כי LipSync3D מציע שלושה חידושים עיקריים בעבודות קודמות: הפרדה של גיאומטריה, תאורה, תנוחה ומרקם לזרמי נתונים נפרדים במרחב מנורמל; מודל חיזוי מרקם אוטומטי שניתן לאמן בקלות, המייצר סינתזת וידאו עקבית זמנית; וריאליזם מוגבר, כפי שהוערך על ידי דירוגים אנושיים ומדדים אובייקטיביים.

פיצול ההיבטים השונים של תמונת הפנים בווידאו מאפשר שליטה רבה יותר בסינתזת וידאו.
LipSync3D יכול להפיק תנועת גיאומטריית שפתיים מתאימה ישירות מאודיו על ידי ניתוח פונמות והיבטים אחרים של דיבור, ותרגומם לתנוחות שרירים תואמות ידועות סביב אזור הפה.

תהליך זה משתמש בצינור חיזוי משותף, שבו לגיאומטריה והמרקם המסקנות יש מקודדים ייעודיים במערך מקודד אוטומטי, אך חולקים מקודד אודיו עם הדיבור שנועד להיות מוטל על הדגם:

סינתזת התנועה הלא-בילית של LipSync3D נועדה גם להפעיל אווטארים מסוג CGI, שהם למעשה רק אותו סוג של מידע רשת ומרקם כמו תמונות בעולם האמיתי:
לאוואטר 3D מסוגנן יש את תנועות השפתיים שלו מופעלות בזמן אמת על ידי סרטון רמקול מקור. בתרחיש כזה, התוצאות הטובות ביותר יתקבלו על ידי אימון מקדים מותאם אישית.
החוקרים גם צופים את השימוש באווטארים עם תחושה קצת יותר מציאותית:
![]()
זמני אימון לדוגמה עבור הסרטונים נעים בין 3-5 שעות לסרטון של 2-5 דקות, בצינור המשתמש ב-TensorFlow, Python ו-C++ על GeForce GTX 1080. ההדרכה השתמשה בגודל אצווה של 128 פריימים מעל 500-1000 עידנים, כאשר כל תקופה מייצגת הערכה מלאה של הסרטון.

לקראת סינכרון דינמי מחדש של תנועת שפתיים
תחום סינכרון השפתיים מחדש כדי להכיל רצועת אודיו חדשנית זכה לתשומת לב רבה במחקר ראיית מחשב בשנים האחרונות (ראה להלן), לא מעט מכיוון שהוא תוצר לוואי של שנוי במחלוקת טכנולוגיה עמוקה.
בשנת 2017 אוניברסיטת וושינגטון הציג מחקר מסוגל ללמוד סינכרון שפתיים מאודיו, תוך שימוש בו כדי לשנות את תנועות השפתיים של הנשיא דאז אובמה. בשנת 2018; מכון מקס פלנק לאינפורמטיקה הוביל יוזמת מחקר נוספת כדי לאפשר העברת וידאו זהות>זהות, עם lip synch a תוצר לוואי של התהליך; ובמאי 2021 סטארט-אפ AI FlawlessAI חשף את טכנולוגיית השפתון הקניינית שלו TrueSync, באופן נרחב קיבלו בעיתונות כמאפשרת של טכנולוגיות דיבוב משופרות להפצות סרטים מרכזיות בשפות שונות.
וכמובן, הפיתוח המתמשך של מאגרי קוד פתוח עמוק מזויפים מספק ענף נוסף של מחקר פעיל שתרמו משתמשים בתחום זה של סינתזת תמונות פנים.















