
בינה מלאכותית
EfficientViT: שנאי ראייה יעילה בזיכרון עבור ראייה ממוחשבת ברזולוציה גבוהה

בשל קיבולת הדגמים הגבוהה שלהם, דגמי Vision Transformer זכו להצלחה רבה בתקופה האחרונה. למרות הביצועים שלהם, לדגמי שנאי ראייה יש פגם מרכזי אחד: כושר החישוב המדהים שלהם מגיע בעלויות חישוב גבוהות, וזו הסיבה מדוע שנאי ראייה אינם הבחירה הראשונה ליישומים בזמן אמת. כדי להתמודד עם בעיה זו, קבוצת מפתחים השיקה את EfficientViT, משפחה של שנאי ראייה במהירות גבוהה.
כשעבדו על EfficientViT, המפתחים הבחינו כי המהירות של דגמי השנאים הנוכחיים מוגבלת לעתים קרובות על ידי פעולות זיכרון לא יעילות, במיוחד פונקציות אלמנטיות ועיצוב מחדש של טנזור ברשת MHSA או Multi-Head Self Attention. כדי להתמודד עם פעולות זיכרון לא יעילות אלו, מפתחי EfficientViT עבדו על אבן בניין חדשה באמצעות פריסת סנדוויץ', כלומר המודל של EfficientViT עושה שימוש ברשת תשומת לב עצמית מרובה ראשים אחת המחוברת לזיכרון בין שכבות FFN יעילות המסייעות בשיפור יעילות הזיכרון, ו גם שיפור התקשורת הכוללת בערוץ. יתר על כן, המודל גם מגלה שלמפות קשב יש לרוב קווי דמיון גבוהים בין ראשים שמובילים לעודפות חישובית. כדי להתמודד עם בעיית היתירות, מודל EfficientViT מציג מודול קשב קבוצתי מדורג שמזין את ראשי הקשב בפיצולים שונים של התכונה המלאה. השיטה לא רק מסייעת בחיסכון בעלויות חישוביות, אלא גם משפרת את גיוון הקשב של המודל.
ניסויים מקיפים שבוצעו על מודל EfficientViT על פני תרחישים שונים מצביעים על כך שה-EfficientViT מתעלה על מודלים יעילים קיימים עבור ראיית מחשב תוך התאמה טובה בין דיוק ומהירות. אז בואו נצלול לעומק, ונחקור את מודל EfficientViT קצת יותר לעומק.
מבוא ל-Vision Transformers ו-EfficientViT
Vision Transformers נותרה אחת המסגרות הפופולריות ביותר בתעשיית הראייה הממוחשבת מכיוון שהם מציעים ביצועים מעולים ויכולות חישוביות גבוהות. עם זאת, עם שיפור מתמיד של דיוק וביצועים של דגמי שנאי הראייה, העלויות התפעוליות והתקורה החישובית עולים גם כן. לדוגמה, מודלים נוכחיים הידועים כמספקים ביצועים מתקדמים על מערכי נתונים של ImageNet כמו SwinV2 ו-V-MoE משתמשים בפרמטרים של 3B ו-14.7B בהתאמה. הגודל העצום של דגמים אלה יחד עם העלויות והדרישות החישוביות הופכים אותם כמעט ללא מתאימים למכשירים ויישומים בזמן אמת.
מודל EfficientNet נועד לחקור כיצד להגביר את הביצועים של דגמי שנאי ראייה, ומציאת העקרונות הכרוכים מאחורי תכנון ארכיטקטורות מסגרת יעילות ואפקטיביות מבוססות שנאים. מודל EfficientViT מבוסס על מסגרות שנאי ראייה קיימות כמו Swim ו-DeiT, והוא מנתח שלושה גורמים חיוניים המשפיעים על מהירויות הפרעות במודלים כולל יתירות חישוב, גישה לזיכרון ושימוש בפרמטרים. יתר על כן, המודל מבחין כי מהירות דגמי שנאי הראייה ב-bound-זיכרון, כלומר ניצול מלא של כוח מחשוב במעבדים/GPUs אסור או מוגבל על ידי עיכוב גישה לזיכרון, מה שגורם להשפעה שלילית על מהירות זמן הריצה של השנאים . פונקציות של אלמנטים ועיצוב מחדש של טנזור ברשת MHSA או Multi-Head Self Attention הם הפעולות הכי לא יעילות בזיכרון. המודל מציין עוד כי התאמה אופטימלית של היחס בין FFN (רשת הזנה קדימה) ו-MHSA, יכולה לעזור בהפחתת זמן הגישה לזיכרון מבלי להשפיע על הביצועים. עם זאת, המודל גם צופה יתירות מסוימת במפות הקשב כתוצאה מהנטייה של ראש הקשב ללמוד תחזיות ליניאריות דומות.
המודל הוא טיפוח סופי של הממצאים במהלך עבודת המחקר עבור EfficientViT. הדגם כולל שחור חדש עם פריסת סנדוויץ' המחיל שכבת MHSA אחת המחוברת לזיכרון בין שכבות Feed Forward Network או FFN. הגישה לא רק מפחיתה את הזמן שלוקח לביצוע פעולות הקשורות לזיכרון ב-MHSA, אלא היא גם הופכת את התהליך כולו ליעיל יותר בזיכרון בכך שהיא מאפשרת ליותר שכבות FFN להקל על התקשורת בין ערוצים שונים. המודל גם עושה שימוש במודול CGA חדש או Cascaded Group Attention שמטרתו להפוך את החישובים ליעילים יותר על ידי הפחתת היתירות החישובית לא רק בראשי הקשב, אלא גם מגדילה את עומק הרשת וכתוצאה מכך קיבולת מודל מוגברת. לבסוף, המודל מרחיב את רוחב הערוץ של רכיבי רשת חיוניים כולל תחזיות ערך, תוך כיווץ רכיבי רשת בעלי ערך נמוך כמו ממדים נסתרים ברשתות ההזנה קדימה כדי להפיץ מחדש את הפרמטרים במסגרת.

כפי שניתן לראות בתמונה לעיל, המסגרת של EfficientViT מתפקדת טוב יותר מדגמי ה-CNN וה-ViT העדכניים ביותר מבחינת דיוק ומהירות. אבל איך המסגרת של EfficientViT הצליחה להתעלות על כמה מהמסגרות העדכניות של האמנות? בוא נגלה את זה.
EfficientViT: שיפור היעילות של שנאי ראייה
מודל EfficientViT שואף לשפר את היעילות של דגמי שנאי הראייה הקיימים באמצעות שלוש נקודות מבט,
- יתירות חישובית.
- גישה לזיכרון.
- שימוש בפרמטרים.
המודל נועד לגלות כיצד הפרמטרים הנ"ל משפיעים על היעילות של דגמי שנאי ראייה, וכיצד לפתור אותם כדי להשיג תוצאות טובות יותר ביעילות טובה יותר. בואו נדבר עליהם קצת יותר לעומק.
גישה ויעילות לזיכרון
אחד הגורמים החיוניים המשפיעים על המהירות של דגם הוא תקורה של גישה לזיכרון או MAO. כפי שניתן לראות בתמונה למטה, מספר מפעילים בשנאי כולל תוספת אלמנטית, נורמליזציה ועיצוב מחדש תכופים הן פעולות שאינן יעילות בזיכרון, מכיוון שהן דורשות גישה ליחידות זיכרון שונות שזה תהליך שלוקח זמן.
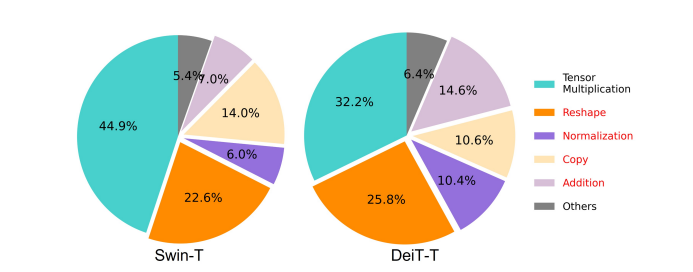
למרות שישנן כמה שיטות קיימות שיכולות לפשט את חישובי הקשב העצמי הסטנדרטיים של Softmax כמו קירוב בדרגה נמוכה ותשומת לב מועטה, לרוב הן מציעות תאוצה מוגבלת, ומפחיתות את הדיוק.
מצד שני, המסגרת של EfficientViT שואפת לצמצם את עלות הגישה לזיכרון על ידי הפחתת כמות השכבות הלא יעילות בזיכרון במסגרת. המודל מקטין את ה-DeiT-T וה-Swin-T לתת-רשתות קטנות עם תפוקת הפרעות גבוהה יותר של 1.25X ו-1.5X, ומשווה את הביצועים של תת-רשתות אלו עם פרופורציות של שכבות MHSA. כפי שניתן לראות בתמונה למטה, כאשר מיושמת, הגישה מגבירה את הדיוק של שכבות MHSA בכ-20 עד 40%.

יעילות חישוב
שכבות MHSA נוטות להטמיע את רצף הקלט במספר תת-מרחבים או ראשים, ומחשבות את מפות הקשב בנפרד, גישה שידועה כמשפרת את הביצועים. עם זאת, מפות קשב אינן זולות מבחינה חישובית, וכדי לחקור את העלויות החישוביות, מודל EfficientViT בוחן כיצד להפחית תשומת לב מיותרת במודלים קטנים יותר של ViT. המודל מודד את הדמיון הקוסינוס המקסימלי של כל ראש והראשים הנותרים בתוך כל בלוק על ידי אימון דגמי DeiT-T ו-Swim-T המוקטנים ברוחב עם מהירות הסקה של 1.25×. כפי שניתן לראות בתמונה למטה, יש מספר גבוה של דמיון בין ראשי קשב, מה שמצביע על כך שהמודל יוצר יתירות חישוב מכיוון שראשים רבים נוטים ללמוד תחזיות דומות של התכונה המלאה המדויקת.

כדי לעודד את הראשים ללמוד דפוסים שונים, המודל מיישם במפורש פתרון אינטואיטיבי שבו כל ראש מוזן רק חלק מהתכונה המלאה, טכניקה הדומה לרעיון של קונבולוציה קבוצתית. המודל מאמן היבטים שונים של הדגמים המוקטנים הכוללים שכבות MHSA מתוקנות.
פרמטר יעילות
דגמי ViT ממוצעים יורשים את אסטרטגיות העיצוב שלהם כמו שימוש ברוחב שווה ערך להקרנות, קביעת יחס התרחבות ל-4 ב-FFN והגדלת ראשים על שלבים משנאי NLP. יש לעצב מחדש את התצורות של רכיבים אלה בקפידה עבור מודולים קלים. מודל EfficientViT פורס גיזום מובנה של טיילור כדי למצוא את הרכיבים החיוניים בשכבות Swim-T ו-DeiT-T באופן אוטומטי, ובוחן עוד יותר את עקרונות הקצאת הפרמטרים הבסיסיים. תחת אילוצי משאבים מסוימים, שיטות הגיזום מסירות ערוצים לא חשובים, ושומרות על הקריטיים כדי להבטיח את הדיוק הגבוה ביותר האפשרי. האיור שלהלן משווה את היחס בין הערוצים להטמעות הקלט לפני ואחרי הגזם על המסגרת של Swin-T. נצפה כי: דיוק בסיס: 79.1%; דיוק גזם: 76.5%.

התמונה לעיל מצביעה על כך ששני השלבים הראשונים של המסגרת משמרים יותר ממדים, בעוד ששני השלבים האחרונים משמרים הרבה פחות ממדים. פירוש הדבר עשוי להיות שתצורת ערוץ טיפוסית המכפילה את הערוץ לאחר כל שלב או משתמשת בערוצים מקבילים עבור כל הבלוקים, עלולה לגרום לעודפות משמעותית בבלוקים האחרונים.
שנאי ראייה יעילה: אדריכלות
על בסיס הלמידה שהושגה במהלך הניתוח לעיל, מפתחים עבדו על יצירת מודל היררכי חדש המציע מהירויות הפרעות מהירות, EfficientViT דֶגֶם. בואו נסתכל מפורט על המבנה של מסגרת EfficientViT. האיור שלהלן נותן לך מושג כללי על מסגרת EfficientViT.
אבני הבניין של מסגרת EfficientViT
אבן הבניין עבור רשת שנאי הראייה היעילה יותר מומחשת באיור שלהלן.

המסגרת מורכבת ממודול קשב קבוצתי מדורג, פריסת סנדוויץ' חסכונית בזיכרון ואסטרטגיית חלוקה מחדש של פרמטרים המתמקדות בשיפור היעילות של המודל במונחים של חישוב, זיכרון ופרמטר, בהתאמה. בואו נדבר עליהם בפירוט רב יותר.
פריסת סנדוויץ'
המודל משתמש בפריסת סנדוויץ' חדשה כדי לבנות בלוק זיכרון יעיל ויעיל יותר עבור המסגרת. פריסת הסנדוויץ' משתמשת בפחות שכבות תשומת לב עצמית הקשורות לזיכרון, ועושה שימוש ברשתות הזנה קדימה יעילות יותר בזיכרון לתקשורת ערוצים. ליתר דיוק, המודל מיישם שכבת תשומת לב עצמית אחת לערבוב מרחבי, המשולבת בין שכבות ה-FFN. העיצוב לא רק עוזר בהפחתת צריכת זמן הזיכרון בגלל שכבות תשומת לב עצמית, אלא גם מאפשר תקשורת יעילה בין ערוצים שונים בתוך הרשת הודות לשימוש בשכבות FFN. המודל גם מחיל שכבת אסימון אינטראקציה נוספת לפני כל שכבת רשת הזנה קדימה באמצעות DWConv או Deceptive Convolution, ומשפר את קיבולת המודל על ידי הכנסת הטיה אינדוקטיבית של המידע המבני המקומי.
תשומת לב קבוצתית מדורגת
אחת הבעיות העיקריות בשכבות MHSA היא היתירות בראשי הקשב שהופכת את החישובים לבלתי יעילים יותר. כדי לפתור את הבעיה, המודל מציע CGA או Cascaded Group Attention עבור שנאי ראייה, מודול קשב חדש השואב השראה מהפיתולים הקבוצתיים ב-CNN יעילים. בגישה זו, המודל מזין ראשים בודדים עם פיצולים של התכונות המלאות, ולכן מפרק את חישוב הקשב באופן מפורש על פני ראשים. פיצול התכונות במקום הזנת תכונות מלאות לכל ראש חוסך חישוב, והופך את התהליך ליעיל יותר, והמודל ממשיך לעבוד על שיפור הדיוק והקיבולת שלו עוד יותר על ידי עידוד השכבות ללמוד תחזיות על תכונות בעלות מידע עשיר יותר.

הקצאת פרמטר מחדש
כדי לשפר את יעילות הפרמטרים, המודל מקצה מחדש את הפרמטרים ברשת על ידי הרחבת רוחב הערוץ של מודולים קריטיים תוך כיווץ רוחב הערוץ של מודולים לא כל כך חשובים. בהתבסס על ניתוח טיילור, המודל או מגדיר ממדי ערוץ קטנים עבור הקרנות בכל ראש במהלך כל שלב או שהמודל מאפשר לתחזיות לקבל את אותו מימד כמו הקלט. גם יחס ההתרחבות של רשת ההזנה קדימה מופחת ל-2 מ-4 כדי לעזור עם יתירות הפרמטרים שלה. אסטרטגיית ההקצאה מחדש המוצעת שמיישמת המסגרת של EfficientViT, מקצה יותר ערוצים למודולים חשובים כדי לאפשר להם ללמוד ייצוגים במרחב גבוה ממדי בצורה טובה יותר שממזערת את אובדן המידע על תכונה. יתר על כן, כדי להאיץ את תהליך ההפרעות ולשפר את היעילות של המודל עוד יותר, המודל מסיר אוטומטית את הפרמטרים המיותרים במודולים לא חשובים.

ניתן להסביר את הסקירה הכללית של מסגרת EfficientViT בתמונה לעיל שבה החלקים,
- ארכיטקטורה של EfficientViT,
- בלוק פריסת סנדוויץ',
- תשומת לב קבוצתית מדורגת.
EfficientViT: ארכיטקטורות רשת

התמונה לעיל מסכמת את ארכיטקטורת הרשת של מסגרת EfficientViT. המודל מציג הטמעת תיקון חופפת [20,80] שמטמיע טלאים של 16×16 באסימוני מימד C1 שמשפרת את יכולת המודל לבצע ביצועים טובים יותר בלימוד ייצוג חזותי ברמה נמוכה. הארכיטקטורה של המודל כוללת שלושה שלבים שבהם כל שלב מערם את אבני הבניין המוצעות של מסגרת EfficientViT, ומספר האסימונים בכל שכבת תת דגימה (2× תת דגימה של הרזולוציה) מצטמצם פי 4. כדי להפוך את תת הדגימה ליעילה יותר, המודל מציע בלוק תת-דגימה שיש לו גם את פריסת הסנדוויץ' המוצעת למעט העובדה שבלוק שיורי הפוך מחליף את שכבת הקשב כדי להפחית את אובדן המידע במהלך הדגימה. יתר על כן, במקום LayerNorm(LN) הרגיל, המודל עושה שימוש ב-BatchNorm(BN) מכיוון שניתן לקפל את BN לשכבות הליניאריות או הקונבולוציוניות הקודמות, מה שנותן לו יתרון בזמן ריצה על פני LN.
משפחת דגמי EfficientViT
משפחת הדגמים EfficientViT מורכבת מ-6 דגמים עם קשקשים שונים של עומק ורוחב, ומספר מוגדר של ראשים מוקצה לכל שלב. המודלים משתמשים בפחות בלוקים בשלבים ההתחלתיים בהשוואה לשלבים הסופיים, תהליך דומה לזה שאחריו המסגרת של MobileNetV3 מכיוון שתהליך העיבוד בשלב מוקדם עם רזולוציות גדולות יותר הוא זמן רב. הרוחב גדל על פני שלבים עם פקטור קטן כדי להפחית את היתירות בשלבים המאוחרים יותר. הטבלה המצורפת להלן מספקת את הפרטים הארכיטקטוניים של משפחת הדגמים EfficientViT כאשר C, L ו-H מתייחסים לרוחב, לעומק ולמספר הראשים בשלב המסוים.

EfficientViT: יישום מודל ותוצאות
לדגם EfficientViT יש גודל אצווה כולל של 2,048, נבנה עם Timm & PyTorch, מאומן מאפס במשך 300 עידנים באמצעות 8 Nvidia V100 GPUs, משתמש במתזמן קצב למידה של קוסינוס, ב-AdamW אופטימיזציה, ועורך את ניסוי סיווג התמונות שלו ב-ImageNet -1K. תמונות הקלט נחתכות באקראי וגודלן משתנה לרזולוציה של 224×224. עבור הניסויים הכוללים סיווג תמונה במורד הזרם, מסגרת EfficientViT מכוונת את המודל ל-300 עידנים, ומשתמשת ב- AdamW Optimizer בגודל אצווה של 256. המודל משתמש ב-RetineNet לזיהוי אובייקטים ב-COCO, וממשיך לאמן את המודלים ל-12 נוספים. תקופות עם הגדרות זהות.
תוצאות ב-ImageNet
כדי לנתח את הביצועים של EfficientViT, הוא מושווה למודלים הנוכחיים של ViT ו-CNN במערך הנתונים של ImageNet. התוצאות מההשוואה מדווחות באיור הבא. כפי שניתן לראות כי משפחת הדגמים EfficientViT עולה על המסגרת הנוכחית ברוב המקרים, ומצליחה להשיג פשרה אידיאלית בין מהירות ודיוק.

השוואה ל-CNN יעילים ו-ViTs יעילים
המודל משווה תחילה את הביצועים שלו מול יעילים CNN כמו EfficientNet ו-Vanilla CNN מסגרות כמו MobileNets. כפי שניתן לראות שבהשוואה למסגרות MobileNet, דגמי EfficientViT משיגים ציון דיוק טוב יותר מ-1, תוך שהם פועלים פי 3.0X ו-2.5X מהר יותר על Intel CPU ו-V100 GPU בהתאמה.
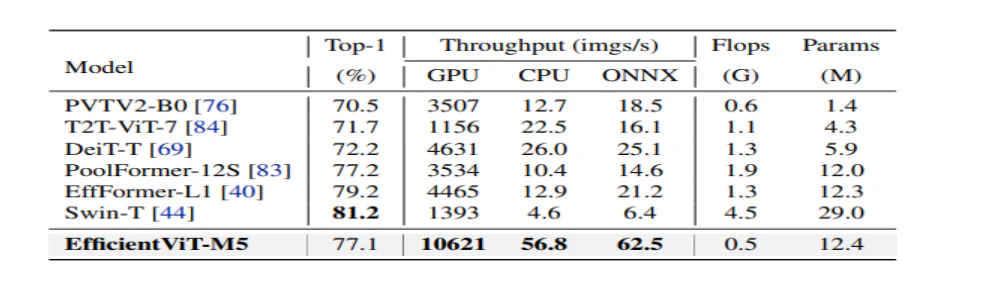
האיור שלמעלה משווה את ביצועי מודל EfficientViT עם מודלים מתקדמים של ViT בקנה מידה גדול הפועלים על מערך הנתונים ImageNet-1K.
סיווג תמונות במורד הזרם
מודל EfficientViT מיושם במשימות שונות במורד הזרם כדי ללמוד את יכולות הלמידה של המודל, והתמונה למטה מסכמת את תוצאות הניסוי. כפי שניתן לראות, מודל EfficientViT-M5 מצליח להשיג תוצאות טובות יותר או דומות בכל מערכי הנתונים תוך שמירה על תפוקה גבוהה בהרבה. היוצא מן הכלל היחיד הוא מערך הנתונים של Cars, שבו מודל EfficientViT לא מצליח לספק את הדיוק.

זיהוי אובייקט
כדי לנתח את היכולת של EfficientViT לזהות אובייקטים, הוא מושווה מול מודלים יעילים במשימת זיהוי האובייקטים של COCO, והתמונה למטה מסכמת את תוצאות ההשוואה.

מחשבות סופיות
במאמר זה, דיברנו על EfficientViT, משפחה של דגמי שנאי ראייה מהירה המשתמשים בתשומת לב קבוצתית מדורגת, ומספקים פעולות חסכוניות בזיכרון. ניסויים נרחבים שנערכו כדי לנתח את הביצועים של ה-EfficientViT הראו תוצאות מבטיחות שכן מודל ה-EfficientViT עולה על הדגמים הנוכחיים של CNN ושל שנאי ראייה ברוב המקרים. ניסינו גם לספק ניתוח של הגורמים שמשחקים תפקיד בהשפעה על מהירות ההפרעות של שנאי ראייה.















