Intelligenza Artificiale
Adobe Research estende l'editing facciale GAN districato

Non è difficile capire perché aggrovigliamento è un problema nella sintesi delle immagini, perché spesso è un problema in altri ambiti della vita; ad esempio, è molto più difficile rimuovere la curcuma da un curry che eliminare i cetriolini sottaceto da un hamburger, ed è praticamente impossibile dezuccherare una tazza di caffè. Alcune cose sono semplicemente incluse.
Allo stesso modo l’entanglement è un ostacolo per le architetture di sintesi delle immagini che idealmente vorrebbero separare caratteristiche e concetti diversi quando si utilizza l’apprendimento automatico per creare o modificare volti (o cani, barcheo qualsiasi altro dominio).
Se potessi separare fili come , genere, colore dei capelli, tono della pelle, emozionee così via, si otterrebbe l'inizio di una vera strumentalità e flessibilità in un framework in grado di creare e modificare le immagini dei volti a un livello veramente granulare, senza trascinare "passeggeri" indesiderati in queste conversioni.

Al massimo entanglement (in alto a sinistra), tutto ciò che puoi fare è cambiare l'immagine di una rete GAN appresa con l'immagine di un'altra persona.
Si tratta di utilizzare in modo efficace la più recente tecnologia di visione artificiale basata sull’intelligenza artificiale per ottenere qualcosa che è stato risolto con altri mezzi più di trent'anni fa.
Con un certo grado di separazione ("Separazione media" nell'immagine precedente), è possibile apportare modifiche basate sullo stile, come il colore dei capelli, l'espressione, l'applicazione di cosmetici e una rotazione limitata della testa, tra le altre cose.

Fonte: FEAT: modifica del volto con attenzione, febbraio 2022, https://arxiv.org/pdf/2202.02713.pdf
Negli ultimi due anni ci sono stati numerosi tentativi di creare ambienti interattivi di modifica del volto che consentano a un utente di modificare le caratteristiche del viso con cursori e altre interazioni tradizionali dell'interfaccia utente, mantenendo intatte le caratteristiche principali del volto di destinazione quando si apportano aggiunte o modifiche. Tuttavia, ciò si è rivelato una sfida a causa dell'entanglement sottostante di caratteristiche/stile nello spazio latente del GAN.
Per esempio, la occhiali tratto è spesso invischiato con il anni tratto, il che significa che aggiungere occhiali potrebbe anche "invecchiare" il viso, mentre invecchiare il viso potrebbe comportare l'aggiunta di occhiali, a seconda del grado di separazione applicato delle caratteristiche di alto livello (vedere "Test" di seguito per alcuni esempi).
In particolare, è diventato quasi impossibile modificare il colore dei capelli e altre sfaccettature senza ricalcolarle, ovvero ciocche e disposizione, il che conferisce un effetto di transizione "frizzante".

Fonte: InterFaceGAN Demo (CVPR 2020), https://www.youtube.com/watch?v=uoftpl3Bj6w
Attraversamento GAN da latente a latente
Un nuovo documento guidato da Adobe inserito per WACV 2022 offre un nuovo approccio a questi problemi sottostanti in a carta dal titolo Da latente a latente: un mappatore appreso per la modifica dell'identità che preserva gli attributi di più volti nelle immagini generate da StyleGAN.

Materiale supplementare dalla carta Da latente a latente: un mappatore appreso per la modifica dell'identità che preserva gli attributi di più volti nelle immagini generate da StyleGAN. Qui vediamo che le caratteristiche di base nella faccia appresa non vengono trascinate in cambiamenti non correlati. Guarda l'incorporamento del video completo alla fine dell'articolo per dettagli e risoluzione migliori. Fonte: https://www.youtube.com/watch?v=rf_61llRH0Q
Il documento è guidato da Adobe Applied Scientist Siavash Khodadadeh, insieme ad altri quattro ricercatori Adobe e un ricercatore del Dipartimento di Informatica dell'Università della Florida centrale.
L'articolo è interessante in parte perché Adobe opera in questo ambito da un po' di tempo ed è allettante immaginare che questa funzionalità possa entrare a far parte di un progetto Creative Suite nei prossimi anni; ma soprattutto perché l'architettura creata per il progetto adotta un approccio diverso per mantenere l'integrità visiva in un editor di volti GAN durante l'applicazione delle modifiche.
Gli autori dichiarano:
'[Noi] addestriamo una rete neurale per eseguire una trasformazione da latente a latente che trova la codifica latente corrispondente all'immagine con l'attributo modificato. Poiché la tecnica è one-shot, non si basa su una traiettoria lineare o non lineare del cambiamento graduale degli attributi.
“Addestrando la rete end-to-end sull'intera pipeline di generazione, il sistema può adattarsi agli spazi latenti delle architetture dei generatori standard. Le proprietà di conservazione, come il mantenimento dell'identità della persona, possono essere codificate sotto forma di perdite di addestramento.
"Una volta addestrata la rete latente-latente, può essere riutilizzata per immagini arbitrarie senza bisogno di un nuovo addestramento."
Quest'ultima parte significa che l'architettura proposta arriva all'utente finale in uno stato completo. Deve ancora eseguire una rete neurale su risorse locali, ma le nuove immagini possono essere "inserite" ed essere pronte per la modifica quasi immediatamente, poiché il framework è sufficientemente disaccoppiato da non richiedere ulteriore addestramento specifico per ogni immagine.
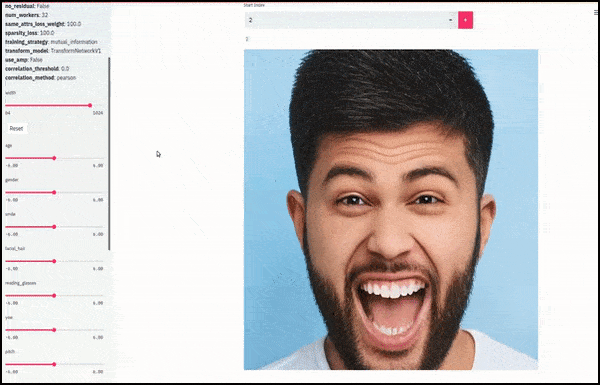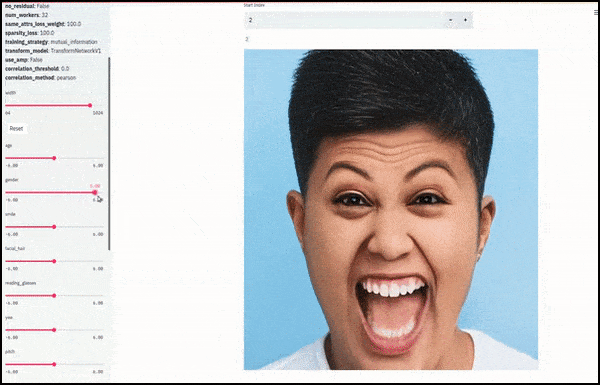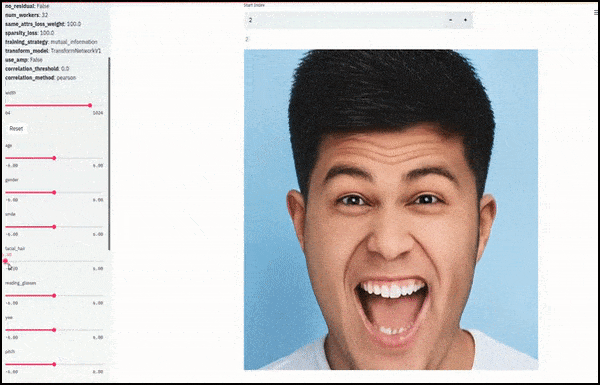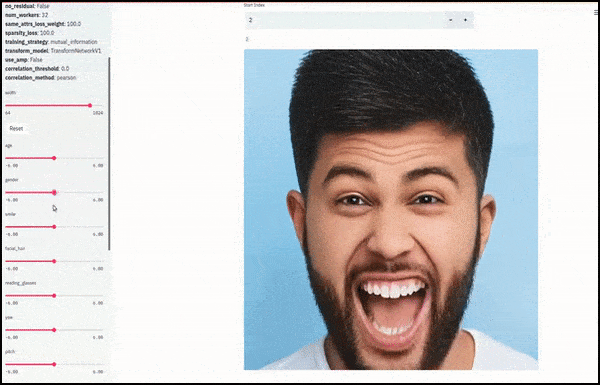
Genere e barba sono cambiati mentre i cursori tracciano percorsi casuali e arbitrari nello spazio latente, non solo "scorrendo tra i punti finali". Guarda il video incorporato alla fine dell'articolo per ulteriori trasformazioni a una risoluzione migliore.
Tra i principali risultati ottenuti nel lavoro c'è la capacità della rete di "congelare" le identità nello spazio latente modificando solo l'attributo in un vettore target e fornendo "termini di correzione" che conservano le identità in fase di trasformazione.
In sostanza, la rete proposta è incorporata in un'architettura più ampia che orchestra tutti gli elementi elaborati, che passano attraverso componenti pre-addestrati con pesi congelati che non produrranno effetti collaterali indesiderati sulle trasformazioni.
Dal momento che il processo di formazione si basa su terzine che può essere generato sia da un'immagine seme (sotto Inversione GAN) o una codifica latente iniziale esistente, l'intero processo di formazione non è supervisionato, con le azioni tacite della consueta gamma di sistemi di etichettatura e cura in tali sistemi effettivamente incorporati nell'architettura. Infatti, il nuovo sistema utilizza regressori di attributi standard:
"[Il] numero di attributi che la nostra rete può controllare in modo indipendente è limitato solo dalle capacità del/i riconoscitore/i: se si dispone di un riconoscitore per un attributo, possiamo aggiungerlo a volti arbitrari. Nei nostri esperimenti, abbiamo addestrato la rete latente-latente per consentire la regolazione di 35 diversi attributi facciali, più di qualsiasi approccio precedente."
Il sistema incorpora un'ulteriore salvaguardia contro le trasformazioni indesiderate di "effetti collaterali": in assenza di una richiesta di modifica di un attributo, la rete latente-latente mapperà un vettore latente su se stessa, aumentando ulteriormente la persistenza stabile dell'identità di destinazione.
Riconoscimento facciale
Un problema ricorrente con GAN e gli editor di volti basati su encoder/decoder degli ultimi anni è stato che le trasformazioni applicate tendono a degradare la somiglianza. Per combattere questo, il progetto Adobe utilizza una rete di riconoscimento facciale incorporata chiamata Face Net come discriminante.

Architettura del progetto, vedere in basso a metà sinistra per l'inclusione di FaceNet. Fonte: Da latente a latente: un mappatore appreso per la modifica dell'identità che preserva gli attributi di più volti nelle immagini generate da StyleGAN, Accesso libero.
(A livello personale, questo sembra un passo incoraggiante verso l'integrazione dell'identificazione facciale standard e persino dei sistemi di riconoscimento dell'espressione nelle reti generative, probabilmente il modo migliore per superare il pixel cieco> mappatura dei pixel che domina le attuali architetture deepfake a scapito della fedeltà delle espressioni e di altri importanti domini nel settore della generazione dei volti.)
Accesso a tutte le aree nello Spazio Latente
Un'altra caratteristica impressionante del framework è la sua capacità di spostarsi arbitrariamente tra potenziali trasformazioni nello spazio latente, a piacimento dell'utente. Diversi sistemi precedenti che fornivano interfacce esplorative spesso lasciavano l'utente sostanzialmente a "spulciare" tra timeline di trasformazione delle funzionalità fisse: un'esperienza impressionante, ma spesso piuttosto lineare o prescrittiva.

Da Migliorare l'equilibrio GAN aumentando la consapevolezza spaziale: qui l'utente passa attraverso una gamma di potenziali punti di transizione tra due posizioni dello spazio latente, ma entro i confini di posizioni pre-addestrate nello spazio latente. Per applicare altri tipi di trasformazione basati sullo stesso materiale, è necessaria la riconfigurazione e/o la riqualificazione. Fonte: https://genforce.github.io/eqgan/
Oltre a essere aperto a immagini utente completamente nuove, l'utente può anche "congelare" manualmente gli elementi che desidera conservare durante il processo di trasformazione. In questo modo, l'utente può garantire che (ad esempio) gli sfondi non si spostino o che gli occhi rimangano aperti o chiusi.
Dati
La rete di regressione degli attributi è stata addestrata su tre reti: FFHQ, CelebAMask-HQ, e una rete locale generata da GAN ottenuta campionando 400,000 vettori dallo spazio Z di StileGAN-V2.
Le immagini fuori distribuzione (OOD) sono state filtrate e gli attributi estratti utilizzando Microsoft API viso, con il set di immagini risultante diviso 90/10, lasciando 721,218 immagini di addestramento e 72,172 immagini di test con cui confrontare.
Collaudo
Sebbene la rete sperimentale fosse inizialmente configurata per accogliere 35 potenziali trasformazioni, queste sono state ridotte a otto per poter effettuare test analoghi rispetto a framework comparabili InterfacciaGAN, GANSspacee StyleFlow.
Gli otto attributi selezionati erano Età, Calvizie, Barba, Espressione, Genere, Bicchieri, Intonazionee Imbardata. È stato necessario riorganizzare i framework concorrenti per alcuni degli otto attributi che non erano stati forniti nella distribuzione originale, come l'aggiunta calvizie e barba a InterFaceGAN.
Come previsto, si è verificato un maggiore livello di entanglement nelle architetture rivali. Ad esempio, in un test, InterFaceGAN e StyleFlow hanno entrambi cambiato il genere del soggetto quando è stato chiesto di candidarsi :

Due dei framework concorrenti hanno integrato il cambio di genere nella trasformazione "età", cambiando anche il colore dei capelli senza l'intervento diretto dell'utente.
Inoltre, due dei rivali hanno scoperto che gli occhiali e l'età sono sfaccettature inseparabili:

Occhiali e cambio di colore dei capelli senza costi aggiuntivi!
Non si tratta di una vittoria uniforme per la ricerca: come si può vedere nel video di accompagnamento incorporato alla fine dell'articolo, il framework è il meno efficace quando si cerca di estrapolare angoli diversi (imbardata), mentre GANSpace ha un risultato generale migliore per e l'imposizione di occhiali. Il framework da latente a latente legato a GANSpace e StyleFlow per quanto riguarda l'aggiunta del tono (angolo della testa).

Risultati calcolati sulla base di una calibrazione del Rilevatore facciale MTCNN. I risultati inferiori sono migliori.
Per maggiori dettagli e una migliore risoluzione degli esempi, guarda il video allegato al documento qui sotto.
Pubblicato per la prima volta il 16 febbraio 2022.












