
Արհեստական բանականություն
Նյարդային լյումիգրաֆի մատուցմամբ իրական ժամանակի AI մարդկանց նկատմամբ

Չնայած նյարդային ճառագայթման դաշտերի նկատմամբ հետաքրքրության ներկա ալիքին (Ներֆ), տեխնոլոգիա, որը կարող է ստեղծել AI-ի ստեղծած 3D միջավայրեր և օբյեկտներ, պատկերների սինթեզի տեխնոլոգիայի այս նոր մոտեցումը դեռևս պահանջում է մեծ ուսուցման ժամանակ և չունի իրական ժամանակում, բարձր արձագանքող ինտերֆեյսներ թույլ տվող իրագործում:
Այնուամենայնիվ, արդյունաբերության և ակադեմիայի որոշ տպավորիչ անունների համագործակցությունը նոր մոտեցում է առաջարկում այս մարտահրավերին (ընդհանուր առմամբ հայտնի է որպես Novel View Synthesis կամ NVS):
Հետազոտությունը թուղթ, իրավունք Նյարդային լյումիգրաֆի մատուցում, պնդում է մոտ երկու կարգի մեծության նորագույն մակարդակի բարելավում, որը ներկայացնում է մի քանի քայլ դեպի իրական ժամանակում CG-ի մատուցում մեքենայական ուսուցման խողովակաշարերի միջոցով:

Նյարդային Lumigraph Rendering-ը (աջից) առաջարկում է միախառնվող արտեֆակտների ավելի լավ լուծում և խցանման բարելավված կառավարում նախորդ մեթոդների համեմատ: Աղբյուրը՝ https://www.youtube.com/watch?v=maVF-7×9644
Թեև թերթի վարկերը վկայակոչում են միայն Սթենֆորդի համալսարանը և հոլոգրաֆիկ ցուցադրման տեխնոլոգիական ընկերությունը՝ Raxium (ներկայումս գործում է ք. գաղտագողի ռեժիմ), ներդրողները ներառում են հիմնական մեքենայական ուսուցում ճարտարապետ Google-ում՝ համակարգիչ գիտնական Adobe-ում և ԱՏՏ at StoryFile (որը պատրաստեց վերնագրերը վերջերս Ուիլյամ Շաթների AI տարբերակով):
Ինչ վերաբերում է Shatner-ի վերջին հրապարակային բլիցին, StoryFile-ը, կարծես, օգտագործում է NLR-ն իր նոր գործընթացում՝ ինտերակտիվ, AI-ի կողմից ստեղծված սուբյեկտների ստեղծման համար, որոնք հիմնված են առանձին մարդկանց բնութագրերի և պատմությունների վրա:

StoryFile-ը նախատեսում է այս տեխնոլոգիայի օգտագործումը թանգարանների ցուցադրություններում, առցանց ինտերակտիվ պատմվածքներում, հոլոգրաֆիկ ցուցադրություններում, հավելյալ իրականության (AR) և ժառանգության փաստաթղթերում, ինչպես նաև, թվում է, թե նայում է NLR-ի հնարավոր նոր կիրառություններին հավաքագրման հարցազրույցներում և վիրտուալ ժամադրության հավելվածներում:

Առաջարկվող օգտագործումը StoryFile-ի առցանց տեսանյութից: Աղբյուր՝ https://www.youtube.com/watch?v=2K9J6q5DqRc
Ծավալային նկարահանում վեպի դիտման սինթեզի միջերեսների և տեսանյութերի համար
Ծավալային նկարահանման սկզբունքը, թեմայի շուրջ կուտակվող թղթերի տիրույթում, առարկայի անշարժ պատկերներ կամ տեսանյութեր վերցնելու և մեքենայական ուսուցման կիրառման գաղափարն է՝ «լրացնելու» այն տեսակետները, որոնք չեն ընդգրկվել բնօրինակում: տեսախցիկների զանգված.
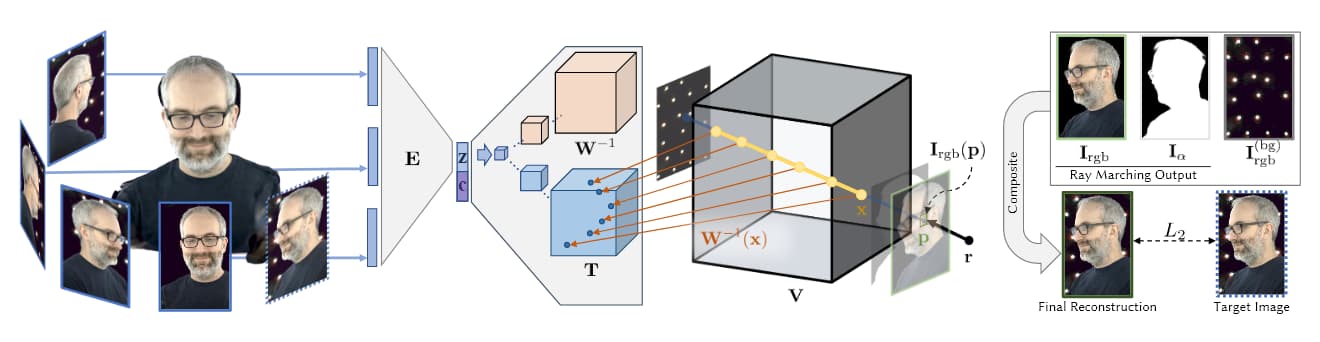
Աղբյուր՝ https://research.fb.com/wp-content/uploads/2019/06/Neural-Volumes-Learning-Dynamic-Renderable-Volumes-from-Images.pdf
Վերևի նկարում, որը վերցված է Facebook-ի AI 2019 AI հետազոտությունից (տես ստորև), մենք տեսնում ենք ծավալային նկարահանման չորս փուլերը. բազմաթիվ տեսախցիկներ ստանում են պատկերներ/կադրեր. կոդավորիչ/ապակոդավորիչ ճարտարապետություն (կամ այլ ճարտարապետություններ) հաշվարկում և միացնում են դիտումների հարաբերականությունը. ray-marching ալգորիթմները հաշվարկում են վոքսելներ (կամ այլ XYZ տարածական երկրաչափական միավորներ) յուրաքանչյուր կետի ծավալային տարածության մեջ. և (ամենավերջին աշխատություններում) ուսուցումը տեղի է ունենում ամբողջական էություն սինթեզելու համար, որը կարող է շահարկվել իրական ժամանակում:
Հենց այս հաճախ ընդարձակ և տվյալների համար ծանր ուսուցման փուլն է, որ մինչ օրս պահում է նոր հայացքների սինթեզը իրական ժամանակում կամ բարձր արձագանքող գրավման ոլորտից:
Այն փաստը, որ Novel View Synthesis-ը կազմում է ծավալային տարածության ամբողջական 3D քարտեզ, նշանակում է, որ համեմատաբար աննշան է այս կետերը միավորել համակարգչից ստեղծվող ավանդական ցանցի մեջ՝ արդյունավետորեն գրավելով և արտահայտելով CGI մարդու (կամ որևէ այլ համեմատաբար սահմանափակված առարկա) վրա: թռիչք.
Մոտեցումները, որոնք օգտագործում են NeRF-ը, հիմնվում են կետերի ամպերի և խորության քարտեզների վրա՝ նկարահանող սարքերի նոսր տեսադաշտերի միջև ինտերպոլացիաներ ստեղծելու համար.

NeRF-ը կարող է ծավալային խորություն առաջացնել խորության քարտեզների հաշվարկման միջոցով, այլ ոչ թե CG ցանցերի ստեղծման միջոցով: Աղբյուր՝ https://www.youtube.com/watch?v=JuH79E8rdKc
Չնայած NeRF-ն է ընդունակ ցանցերի հաշվարկման դեպքում իրականացումներից շատերը դա չեն օգտագործում ծավալային տեսարաններ ստեղծելու համար:
Ի հակադրություն, իմպլիցիտ տարբերվող արտապատկերիչը (IDR) մոտեցում, լույս Վայզմանի գիտության ինստիտուտի կողմից 2020 թվականի հոկտեմբերին, կախված է 3D ցանցի տեղեկատվության շահագործումից, որն ավտոմատ կերպով ստեղծվում է գրավման զանգվածներից.

IDR գրավումների օրինակները վերածվել են ինտերակտիվ CGI ցանցերի: Աղբյուր՝ https://www.youtube.com/watch?v=C55y7RhJ1fE
Թեև NeRF-ը չունի IDR-ի ձևը գնահատելու հնարավորությունը, IDR-ը չի կարող համապատասխանել NeRF-ի պատկերի որակին, և երկուսն էլ պահանջում են մեծ ռեսուրսներ մարզելու և համադրելու համար (չնայած NeRF-ի վերջին նորարարությունները. սկիզբ դեպի անդրադառնալ սրան).

NLR-ի հատուկ տեսախցիկի սարքը, որն ունի 16 GoPro HERO7 և 6 կենտրոնական Back-Bone H7PRO տեսախցիկներ: «Իրական ժամանակում» ցուցադրման համար դրանք աշխատում են նվազագույնը 60 կադր/վրկ արագությամբ: Աղբյուր՝ https://arxiv.org/pdf/2103.11571.pdf
Փոխարենը, Նյարդային Lumigraph Rendering-ը օգտագործում է ՍԻՐԵՆ (Sinusoidal Representation Networks) յուրաքանչյուր մոտեցման ուժեղ կողմերը ներառելու իր շրջանակում, որը նախատեսված է արտադրել արտադրանք, որն ուղղակիորեն օգտագործելի է գոյություն ունեցող իրական ժամանակի գրաֆիկական խողովակաշարերում:
SIREN-ը օգտագործվել է նմանատիպ իրականացումներ անցած տարվա ընթացքում, իսկ այժմ ներկայացնում է ա հայտնի API զանգ պատկերների սինթեզի համայնքներում հոբբիստ Կոլաբի համար; Այնուամենայնիվ, NLR-ի նորամուծությունն է SIREN-ների կիրառումը երկչափ բազմատեսակ պատկերի հսկողության համար, ինչը խնդրահարույց է, քանի որ SIREN-ը արտադրում է ոչ թե ընդհանրացված, այլ չափից ավելի հարմարեցված արդյունք:
Այն բանից հետո, երբ CG ցանցը հանվում է զանգվածի պատկերներից, ցանցը պատկերացվում է OpenGL-ի միջոցով, և ցանցի գագաթային դիրքերը քարտեզագրվում են համապատասխան պիքսելներին, որից հետո հաշվարկվում է տարբեր նպաստող քարտեզների միաձուլումը:
Ստացված ցանցն ավելի ընդհանրացված և ներկայացուցչական է, քան NeRF-ը (տես ստորև նկարը), պահանջում է ավելի քիչ հաշվարկ և չի կիրառում չափազանց մանրուք այն տարածքների վրա (օրինակ՝ հարթ դեմքի մաշկը), որոնք չեն կարող օգտվել դրանից.

Աղբյուր՝ https://arxiv.org/pdf/2103.11571.pdf
Բացասական կողմը, NLR-ը դեռ չունի դինամիկ լուսավորության հնարավորություն կամ վերալուսավորելով, և ելքը սահմանափակվում է ստվերային քարտեզներով և լուսային այլ նկատառումներով, որոնք ձեռք են բերվել նկարահանման պահին: Հետազոտողները մտադիր են դրան անդրադառնալ հետագա աշխատանքում:
Բացի այդ, թերթը խոստովանում է, որ NLR-ի կողմից ստեղծված ձևերն այնքան ճշգրիտ չեն, որքան որոշ այլընտրանքային մոտեցումներ, ինչպիսիք են. Pixelwise Դիտման ընտրություն չկառուցված բազմատեսակ ստերեոյի համար, կամ ավելի վաղ հիշատակված Վեյցմանի ինստիտուտի հետազոտությունը։
Ծավալային պատկերի սինթեզի բարձրացումը
Նյարդային ցանցերով սահմանափակ լուսանկարների շարքից 3D սուբյեկտներ ստեղծելու գաղափարը հնացել է NeRF-ի վաղեմության, տեսլական փաստաթղթերի հետ կապված 2007 թվականին կամ ավելի վաղ: 2019-ին Facebook-ի AI-ի հետազոտական բաժինը պատրաստեց հիմնական հետազոտական փաստաթուղթ, Նյարդային ծավալներ. Դինամիկ վերարտադրվող ծավալներ սովորել պատկերներից, որն առաջին անգամ հնարավորություն տվեց արձագանքող ինտերֆեյսներ սինթետիկ մարդկանց համար, որոնք ստեղծվել էին մեքենայական ուսուցման վրա հիմնված ծավալային գրավման միջոցով:

Facebook-ի 2019-ի հետազոտությունը հնարավորություն է տվել ստեղծել պատասխանող օգտատիրոջ ինտերֆեյս՝ ծավալային անձի համար: Աղբյուր՝ https://research.fb.com/publications/neural-volumes-learning-dynamic-renderable-volumes-from-images/















