
Արհեստական բանականություն
Առջևում երեք մարտահրավեր կայուն տարածման համար

The ազատ արձակել կայունության.ai's Stable Diffusion թաքնված դիֆուզիոն Պատկերի սինթեզի մոդելը մի քանի շաբաթ առաջ կարող է լինել ամենակարևոր տեխնոլոգիական բացահայտումներից մեկը DeCSS-ից սկսած 1999թ; դա, անշուշտ, 2017 թվականից ի վեր AI-ի կողմից ստեղծված պատկերների ամենամեծ իրադարձությունն է deepfakes կոդը պատճենվել է GitHub-ում և պատառաքաղվել այն, ինչ կդառնա Deepfacelab և դեմքի փոխանակում, ինչպես նաև իրական ժամանակի հոսքային deepfake ծրագրակազմը Deepfaceleive.
ինսուլտի ժամանակ, օգտագործողի հիասթափություն նկատմամբ բովանդակության սահմանափակումներ DALL-E 2-ի պատկերների սինթեզում API-ն մի կողմ է հանվել, քանի որ պարզվել է, որ Stable Diffusion-ի NSFW ֆիլտրը կարող է անջատվել՝ փոխելով կոդերի միակ տողը. Պոռնոկենտրոն Stable Diffusion Reddit-ները գրեթե անմիջապես առաջացան և նույնքան արագ կրճատվեցին, մինչդեռ մշակողների և օգտատերերի ճամբարը Discord-ում բաժանվեց պաշտոնական և NSFW համայնքների, և Twitter-ը սկսեց լցվել Stable Diffusion ֆանտաստիկ ստեղծագործություններով:
Այս պահին, թվում է, թե ամեն օր մի զարմանալի նորամուծություն է բերում այն մշակողների կողմից, ովքեր որդեգրել են համակարգը, փլագինների և երրորդ կողմի հավելվածների համար, որոնք հապճեպ գրվում են: կավիճ, Photoshop, Cinema4D, Blenderև շատ այլ հավելվածների հարթակներ:

Ընդ որում, արագագործություն – «AI շշուկի» այժմ պրոֆեսիոնալ արվեստը, որը կարող է դառնալ կարիերայի ամենակարճ տարբերակը «Filofax binder»-ից հետո. առևտրայնացված, մինչդեռ Stable Diffusion-ի վաղ դրամայնացումը տեղի է ունենում Ա Պատրեոնի մակարդակը, վստահ լինելով, որ ավելի բարդ առաջարկներ են սպասվում նրանց համար, ովքեր չեն ցանկանում նավարկել Կոնդայի վրա հիմնված սկզբնաղբյուրի տեղադրում կամ վեբ վրա հիմնված ներդրման NSFW զտիչներ:
Զարգացման տեմպերը և օգտատերերի կողմից հետազոտության ազատ զգացողությունն ընթանում են այնպիսի գլխապտույտ արագությամբ, որ դժվար է շատ հեռու տեսնել: Ըստ էության, մենք դեռ հստակ չգիտենք, թե ինչի հետ գործ ունենք, կամ որոնք կարող են լինել բոլոր սահմանափակումները կամ հնարավորությունները:
Այնուամենայնիվ, եկեք նայենք երեքին, որոնք կարող են լինել ամենահետաքրքիր և դժվարին խոչընդոտները արագ ձևավորվող և արագ զարգացող Stable Diffusion համայնքի համար, որոնք կարող են դիմակայել և, հուսանք, հաղթահարել:
1. Սալիկի վրա հիմնված խողովակաշարերի օպտիմալացում
Ներկայացված ապարատային սահմանափակ ռեսուրսներով և ուսուցման պատկերների լուծման կոշտ սահմանափակումներով, հավանական է թվում, որ մշակողները կգտնեն լուծումներ՝ բարելավելու կայուն դիֆուզիոն արտադրանքի որակը և լուծումը: Այս նախագծերից շատերը պետք է ներառեն համակարգի սահմանափակումների օգտագործումը, ինչպես օրինակ՝ 512×512 պիքսելների հիմնական լուծումը:
Ինչպես միշտ պատահում է համակարգչային տեսլականի և պատկերների սինթեզի նախաձեռնությունների դեպքում, Stable Diffusion-ը վերապատրաստվել է քառակուսի հարաբերակցությամբ պատկերների վրա, այս դեպքում նմուշառվել է մինչև 512×512, որպեսզի սկզբնաղբյուրի պատկերները կարողանան կանոնավորվել և տեղավորվել GPU-ների սահմանափակումների մեջ: վարժեցրել է մոդելին։
Հետևաբար, Stable Diffusion-ը «մտածում է» (եթե ընդհանրապես մտածում է) 512×512 տերմիններով և, իհարկե, քառակուսի տերմիններով: Շատ օգտատերեր, որոնք ներկայումս ուսումնասիրում են համակարգի սահմանները, հայտնում են, որ Stable Diffusion-ը տալիս է ամենահուսալի և ամենաքիչ շողոքորթ արդյունքները այս բավականին սահմանափակ չափերի հարաբերակցությամբ (տես ստորև «վերջույթների հասցեավորումը»:
Թեև տարբեր իրականացումներն առանձնանում են ընդլայնման միջոցով RealESRGAN (և կարող է շտկել վատ մատուցված դեմքերը միջոցով GFPGAN) Մի քանի օգտատերեր ներկայումս մշակում են նկարները 512x512px հատվածների բաժանելու և պատկերները միմյանց կարելու մեթոդներ՝ ավելի մեծ կոմպոզիտային աշխատանքներ ստեղծելու համար:

Այս 1024 × 576 ռենդերը, որը սովորաբար անհնար է լուծում մեկ Կայուն դիֆուզիոն ռենդերում, ստեղծվել է ուշադրություն.py Python ֆայլը պատճենելով և տեղադրելու միջոցով: Շառաչյուն Stable Diffusion-ի պատառաքաղը (տարբերակ, որն իրականացնում է սալիկների վրա հիմնված մասշտաբավորում) մեկ այլ պատառաքաղի մեջ: Աղբյուր՝ https://old.reddit.com/r/StableDiffusion/comments/x6yeam/1024x576_with_6gb_nice/
Թեև այս տեսակի որոշ նախաձեռնություններ օգտագործում են բնօրինակ կոդ կամ այլ գրադարաններ, txt2imghd նավահանգիստ GOBIG-ը (մի ռեժիմ VRAM-ի համար քաղցած ProgRockDiffusion-ում) շուտով կապահովի այս գործառույթը հիմնական մասնաճյուղին: Թեև txt2imghd-ը GOBIG-ի հատուկ նավահանգիստ է, համայնքի մշակողների այլ ջանքերը ներառում են GOBIG-ի տարբեր իրականացումներ:

Հարմար վերացական պատկեր բնօրինակ 512x512px ռենդերում (ձախից և ձախից երկրորդը); բարելավվել է ESGRAN-ի կողմից, որն այժմ քիչ թե շատ բնիկ է բոլոր Stable Diffusion բաշխումներում; և «հատուկ ուշադրություն» է տրվել GOBIG-ի իրականացման միջոցով՝ ստեղծելով մանրամասներ, որոնք, գոնե պատկերի հատվածի սահմաններում, ավելի լավ են թվում: Սմեր՝ https://old.reddit.com/r/StableDiffusion/comments/x72460/stable_diffusion_gobig_txt2imghd_easy_mode_colab/
Վերևում ներկայացված վերացական օրինակն ունի բազմաթիվ «փոքր թագավորություններ» դետալների, որոնք համապատասխանում են ընդլայնման այս սոլիպսիստական մոտեցմանը, բայց որը կարող է պահանջել ավելի դժվար կոդային լուծումներ՝ չկրկնվող, համահունչ ընդլայնում ստեղծելու համար, որը չի համապատասխանում: նայել կարծես այն հավաքված է շատ մասերից: Համենայն դեպս, մարդկային դեմքերի դեպքում, որտեղ մենք անսովոր կերպով ներդաշնակված ենք շեղումների կամ «կեղտոտ» արտեֆակտների հետ: Հետևաբար դեմքերը կարող են ի վերջո հատուկ լուծման կարիք ունենալ:
Stable Diffusion-ը ներկայումս չունի մեխանիզմ՝ ռենդերի ժամանակ դեմքի վրա ուշադրությունը կենտրոնացնելու այնպես, ինչպես մարդիկ առաջնահերթություն են տալիս դեմքի տեղեկատվությանը: Թեև Discord համայնքների որոշ ծրագրավորողներ դիտարկում են այս տեսակի «ուժեղացված ուշադրությունը» իրականացնելու մեթոդներ, ներկայումս շատ ավելի հեշտ է ձեռքով (և, ի վերջո, ինքնաբերաբար) կատարելագործել դեմքը սկզբնական ցուցադրումից հետո:
Մարդու դեմքն ունի ներքին և ամբողջական իմաստային տրամաբանություն, որը չի գտնվի (օրինակ) շենքի ստորին անկյունի «սալիկի» մեջ, և, հետևաբար, ներկայումս հնարավոր է շատ արդյունավետ «մեծացնել» և վերարտադրել «էսքիզային» դեմք կայուն դիֆուզիոն ելքում:

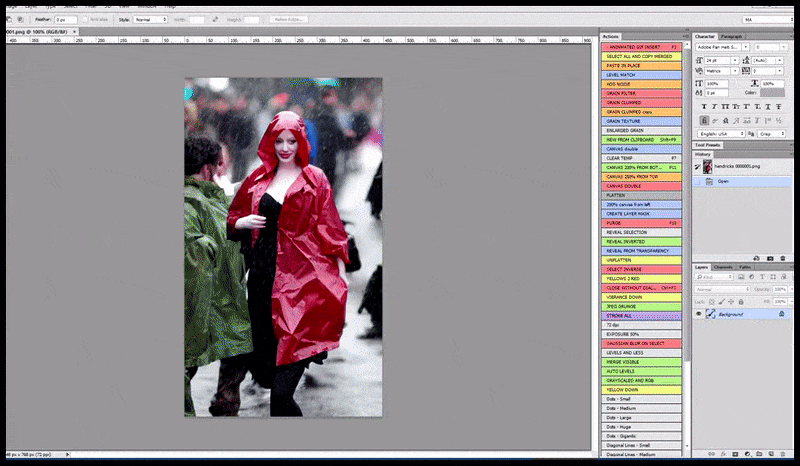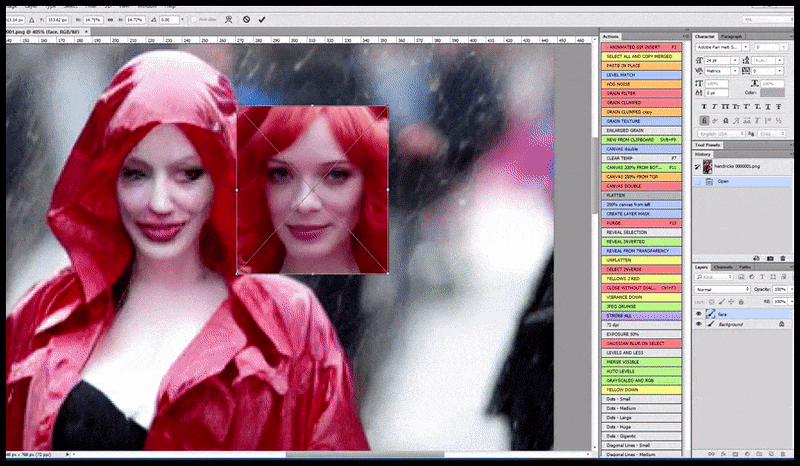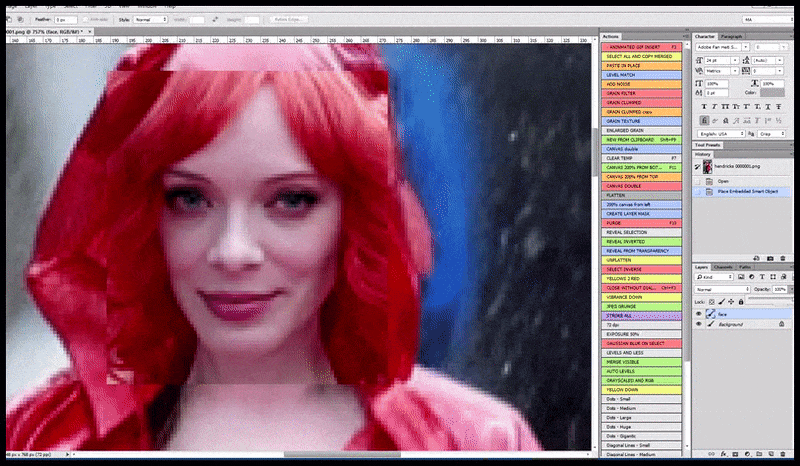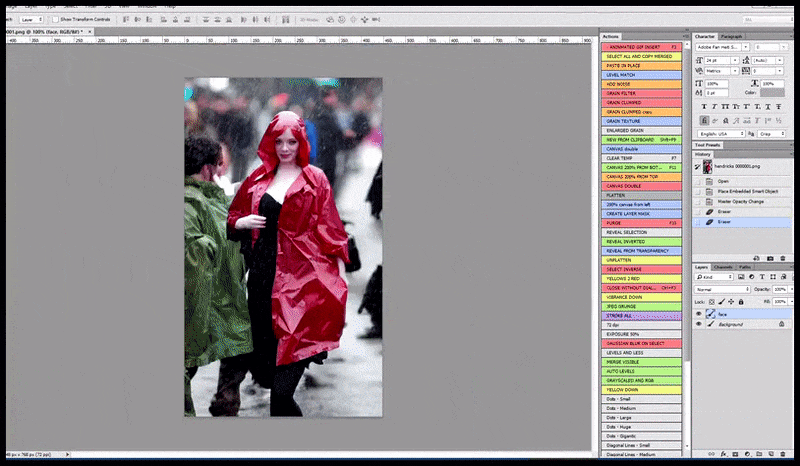
Ձախ, Stable Diffusion-ի սկզբնական ջանքերը՝ «Քրիստինա Հենդրիքսի ամբողջական գունավոր լուսանկարը, որը մտնում է մարդաշատ վայր՝ անձրեւանոցով; Canon50, աչքի կոնտակտ, բարձր դետալներ, դեմքի բարձր դետալներ։ Ճիշտ է, բարելավված դեմք, որը ստացվում է Img2Img-ի միջոցով մշուշված և ուրվագծային դեմքը վերադարձնելով ImgXNUMXImg-ի միջոցով (տե՛ս ստորև ներկայացված անիմացիոն պատկերները):
Տեքստային ինվերսիայի հատուկ լուծման բացակայության դեպքում (տես ստորև), սա կաշխատի միայն հայտնի մարդկանց պատկերների համար, որտեղ տվյալ անձը արդեն լավ ներկայացված է LAION տվյալների ենթաբազմություններում, որոնք վարժեցրել են Stable Diffusion-ը: Հետևաբար, այն կաշխատի այնպիսի մարդկանց վրա, ինչպիսիք են Թոմ Քրուզը, Բրեդ Փիթը, Ջենիֆեր Լոուրենսը և իրական մեդիա լուսատուների սահմանափակ շրջանակը, որոնք առկա են բազմաթիվ պատկերների մեջ աղբյուրի տվյալների մեջ:
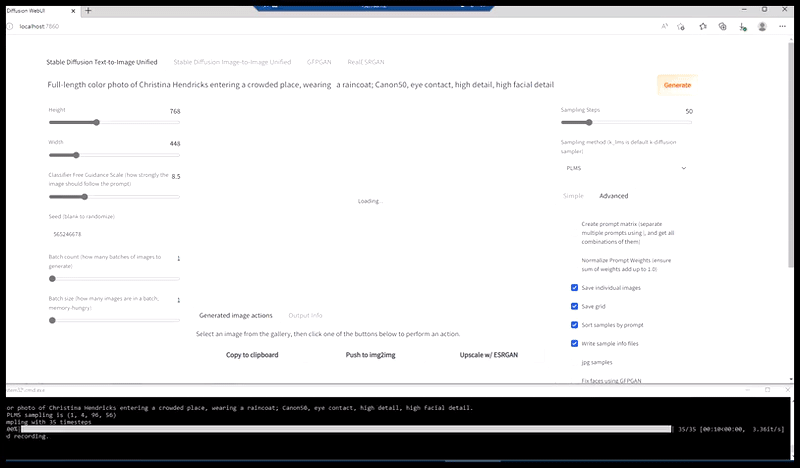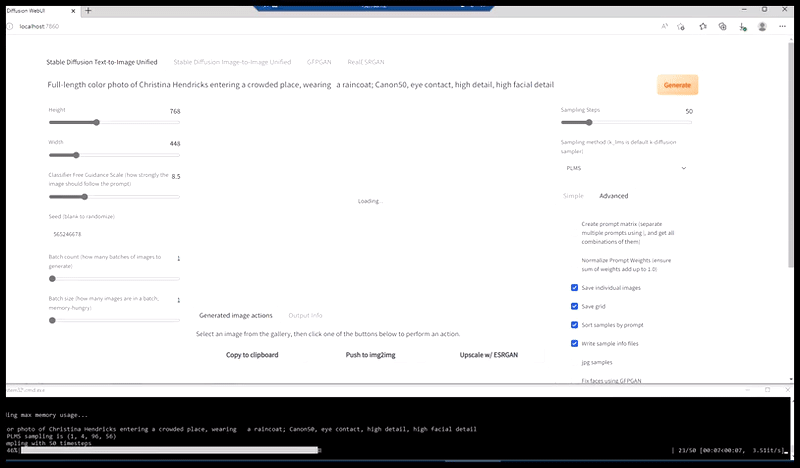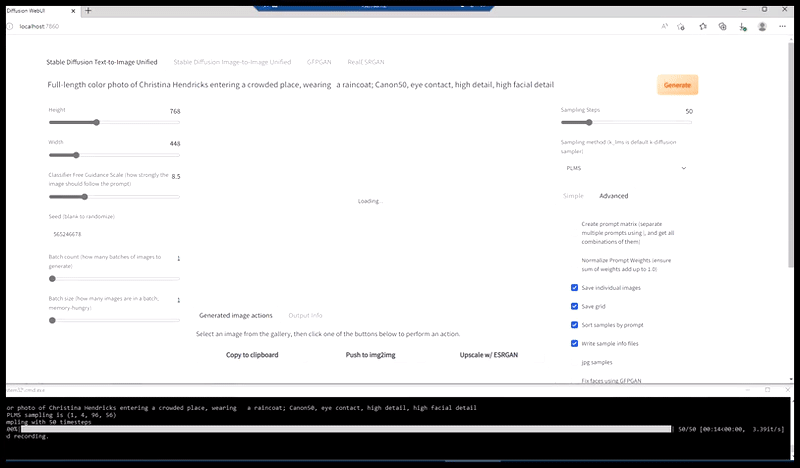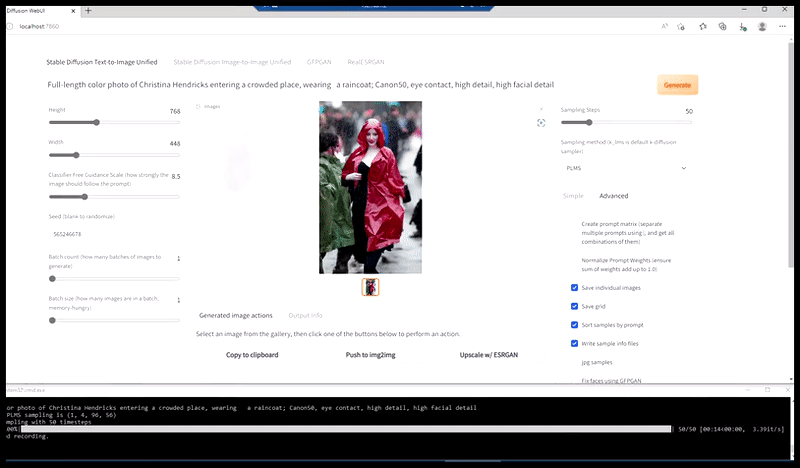
Ճշմարիտ մամուլի պատկերի ստեղծում՝ «Քրիստինա Հենդրիքսի ամբողջական գունավոր լուսանկարը, որը մտնում է մարդաշատ վայր՝ անձրեւանոցով, ակնարկով. Canon50, աչքի կոնտակտ, բարձր դետալներ, դեմքի բարձր դետալներ։
Երկար և երկարատև կարիերա ունեցող հայտնի մարդկանց համար Stable Diffusion-ը սովորաբար ստեղծում է մարդու պատկերը վերջին (այսինքն ավելի մեծ) տարիքում, և անհրաժեշտ կլինի ավելացնել արագ հավելումներ, ինչպիսիք են. «երիտասարդ» or «[ՏԱՐԻ] տարում» ավելի երիտասարդ տեսք ունեցող պատկերներ ստեղծելու համար:

Շուրջ 40 տարի տևող նշանավոր, շատ լուսանկարված և հետևողական կարիերայով դերասանուհի Ջենիֆեր Քոնելլին LAION-ի մի քանի հայտնի մարդկանցից մեկն է, որոնք Stable Diffusion-ին թույլ են տալիս ներկայացնել տարբեր տարիքներ: Աղբյուրը` prepack Stable Diffusion, տեղական, v1.4 անցակետ; տարիքի հետ կապված հուշումներ.
Սա հիմնականում պայմանավորված է 2000-ականների կեսերից թվային (այլ ոչ թե թանկարժեք, էմուլսիաների վրա հիմնված) մամուլի լուսանկարչության տարածմամբ, և ավելի ուշ պատկերի թողարկման ծավալի աճով՝ լայնաշերտ արագության բարձրացման պատճառով:
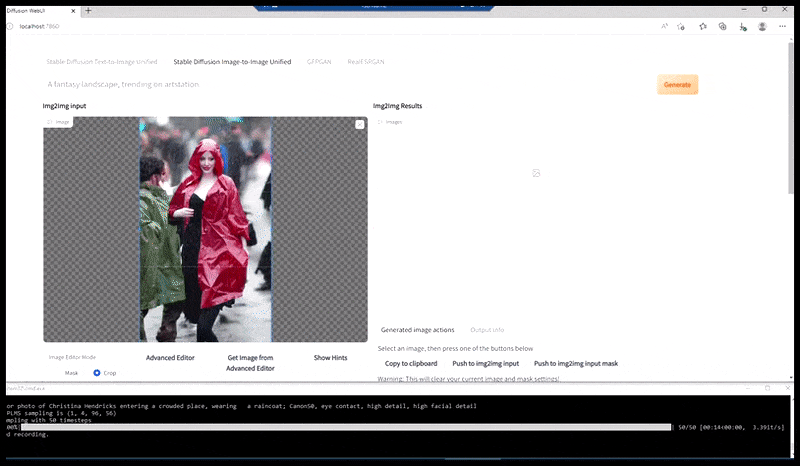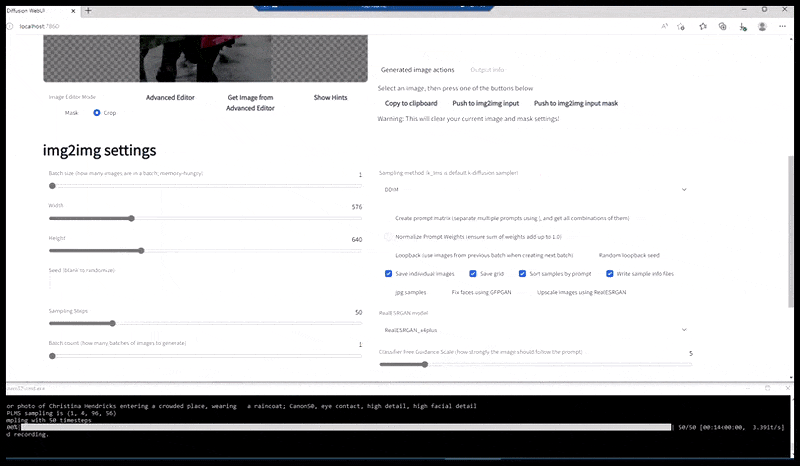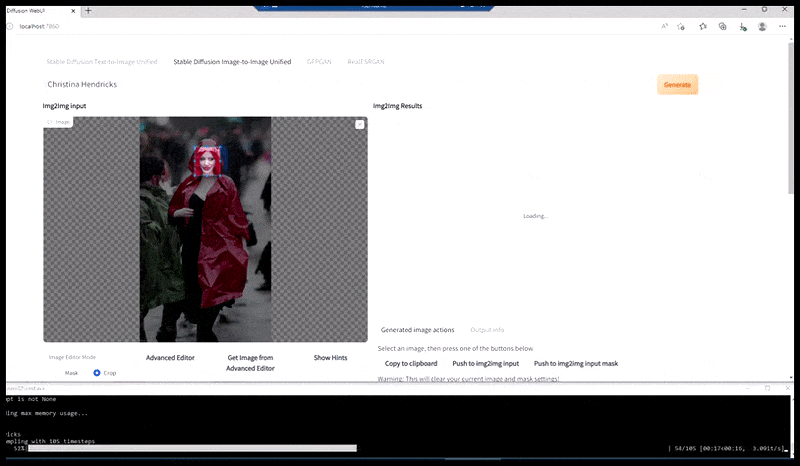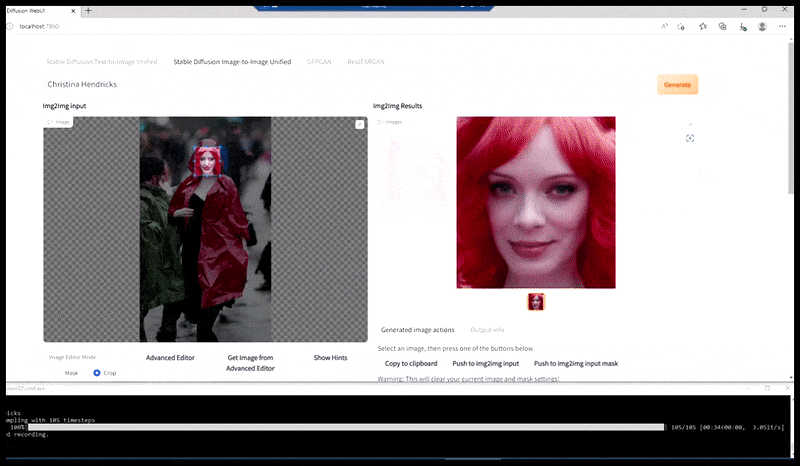
Արտադրված պատկերը փոխանցվում է Img2Img-ին Stable Diffusion-ում, որտեղ ընտրվում է «ֆոկուս տարածք», և նոր, առավելագույն չափի ռենդեր է արվում միայն այդ տարածքից, որը թույլ է տալիս Stable Diffusion-ին կենտրոնացնել բոլոր հասանելի ռեսուրսները դեմքը վերստեղծելու վրա:
«Բարձր ուշադրություն» դեմքի վերականգնում բնօրինակի մեջ: Բացի դեմքերից, այս գործընթացը կաշխատի միայն այն օբյեկտների հետ, որոնք ունեն պոտենցիալ հայտնի, համահունչ և ամբողջական տեսք, օրինակ՝ բնօրինակ լուսանկարի մի հատված, որն ունի հստակ առարկա, օրինակ՝ ժամացույց կամ մեքենա: Օրինակ, պատի մի հատվածի մեծացումը կհանգեցնի շատ տարօրինակ տեսք ունեցող վերակազմավորված պատի, քանի որ սալիկների ներկերը ավելի լայն ենթատեքստ չունեին այս «ոլորահատ սղոցի կտորի» համար, երբ նրանք արտապատկերում էին:
Տվյալների բազայի որոշ հայտնի մարդիկ ժամանակի ընթացքում «նախապես սառեցված» են, կամ այն պատճառով, որ նրանք վաղ են մահացել (օրինակ՝ Մերիլին Մոնրոն), կամ հասել են միայն անցողիկ հանրաճանաչության՝ սահմանափակ ժամանակահատվածում ստեղծելով պատկերների մեծ ծավալ: Polling Stable Diffusion-ը, անկասկած, ապահովում է մի տեսակ «ընթացիկ» ժողովրդականության ինդեքս ժամանակակից և ավելի մեծ աստղերի համար: Որոշ հին և ներկայիս հայտնիների համար աղբյուրի տվյալների մեջ բավականաչափ պատկերներ չկան՝ շատ լավ նմանություն ստանալու համար, մինչդեռ որոշակի վաղուց մեռած կամ այլ կերպ խունացած աստղերի հարատև ժողովրդականությունը երաշխավորում է, որ նրանց ողջամիտ նմանությունը կարելի է ստանալ համակարգից:

Stable Diffusion ռենդերներն արագորեն բացահայտում են, թե որ հայտնի դեմքերն են լավ ներկայացված մարզումների տվյալների մեջ: Չնայած գրելու պահին որպես մեծ դեռահասի իր հսկայական ժողովրդականությանը, Միլի Բոբի Բրաունն ավելի երիտասարդ էր և ավելի քիչ հայտնի, երբ LAION աղբյուրի տվյալների հավաքածուները ջնջվեցին համացանցից՝ այս պահին խնդրահարույց դարձնելով կայուն տարածման հետ բարձրորակ նմանությունը:
Այնտեղ, որտեղ առկա են տվյալներ, սալիկների վրա հիմնված բարձրորակ լուծումները Stable Diffusion-ում կարող են ավելի հեռուն գնալ, քան երեսին ներս մտնելը. դրանք կարող են պոտենցիալ հնարավորություն տալ ավելի ճշգրիտ և մանրամասն դեմքեր ունենալ՝ կոտրելով դեմքի հատկությունները և շրջելով տեղական GPU-ի ողջ ուժը: Առանձին-առանձին ակնառու հատկանիշների վերաբերյալ ռեսուրսներ, նախքան վերահավաքումը. գործընթաց, որը ներկայումս, կրկին, ձեռքով է:

Սա չի սահմանափակվում միայն դեմքերով, այլ սահմանափակվում է օբյեկտների մասերով, որոնք առնվազն նույնքան կանխատեսելիորեն տեղադրված են հյուրընկալող օբյեկտի ավելի լայն համատեքստում և որոնք համապատասխանում են բարձր մակարդակի ներկառուցումներին, որոնք կարելի է ողջամտորեն ակնկալել գտնել հիպերսանդղակի մեջ: տվյալների հավաքածու։
Իրական սահմանը տվյալների բազայում առկա հղման տվյալների քանակն է, քանի որ, ի վերջո, խորը կրկնվող մանրամասները կդառնան ամբողջովին «հալյուցինացված» (այսինքն՝ ֆիկտիվ) և ավելի քիչ վավերական:
Նման բարձր մակարդակի հատիկավոր ընդլայնումները գործում են Ջենիֆեր Քոնելիի դեպքում, քանի որ նա լավ ներկայացված է տարբեր տարիքի LAION-գեղագիտություն (առաջնային ենթաբազմություն LAION 5B որ Stable Diffusion-ը օգտագործում է), և ընդհանրապես LAION-ի ողջ տարածքում; Շատ այլ դեպքերում ճշգրտությունը կարող է տուժել տվյալների պակասից, ինչը կպահանջի կա՛մ ճշգրտում (լրացուցիչ ուսուցում, տե՛ս «Անհատականացում» ստորև) կամ տեքստային հակադարձում (տես ստորև):
Սալիկները հզոր և համեմատաբար էժան միջոց են Stable Diffusion-ի համար, որպեսզի հնարավորություն տրվի արտադրել բարձր որակի արդյունք, սակայն նման ալգորիթմական սալիկապատման ընդլայնումը, եթե այն չունի ավելի լայն, ավելի բարձր մակարդակի ուշադրության մեխանիզմ, կարող է չհամապատասխանել ակնկալվողին: ստանդարտների համար բովանդակության մի շարք տեսակների համար:
2. Մարդու վերջույթների հետ կապված խնդիրների լուծում
Stable Diffusion-ը չի համապատասխանում իր անվանը, երբ պատկերում է մարդու վերջույթների բարդությունը: Ձեռքերը կարող են պատահականորեն բազմապատկվել, մատները միաձուլվում են, երրորդ ոտքերը հայտնվում են անհարկի, իսկ գոյություն ունեցող վերջույթները անհետանում են առանց հետքի: Իր պաշտպանությունում Stable Diffusion-ը կիսում է խնդիրը իր կայուն ընկերների հետ, և, իհարկե, DALL-E 2-ի հետ:

DALL-E 2-ի և Stable Diffusion-ի (1.4) չխմբագրված արդյունքները 2022 թվականի օգոստոսի վերջին, երկուսն էլ ցույց են տալիս վերջույթների հետ կապված խնդիրներ: Հուշումն է՝ «Կինը գրկում է տղամարդուն»
Stable Diffusion երկրպագուները, ովքեր հուսով են, որ առաջիկա 1.5 անցակետը (մոդելի ավելի ինտենսիվ վարժեցված տարբերակը, բարելավված պարամետրերով) կլուծի վերջույթների շփոթությունը, ամենայն հավանականությամբ, հիասթափված կլինեն: Նոր մոդելը, որը կթողարկվի ք մոտ երկու շաբաթ, այժմ պրեմիերան է կայանում առևտրային stability.ai պորտալում երազանքի ստուդիա, որն օգտագործում է 1.5 լռելյայն, և որտեղ օգտվողները կարող են համեմատել նոր ելքը իրենց տեղական կամ այլ 1.4 համակարգերի արտապատկերումների հետ.

Աղբյուրը՝ Local 1.4 prepack և https://beta.dreamstudio.ai/

Աղբյուրը՝ Local 1.4 prepack և https://beta.dreamstudio.ai/

Աղբյուրը՝ Local 1.4 prepack և https://beta.dreamstudio.ai/
Ինչպես հաճախ է պատահում, տվյալների որակը կարող է լինել հիմնական նպաստող պատճառը:
Բաց կոդով տվյալների բազաները, որոնք սնուցում են պատկերների սինթեզի համակարգերը, ինչպիսիք են Stable Diffusion-ը և DALL-E 2-ը, կարող են բազմաթիվ պիտակներ տրամադրել ինչպես առանձին մարդկանց, այնպես էլ միջմարդկային գործողությունների համար: Այս պիտակները սիմբիոտիկ կերպով վերապատրաստվում են իրենց առնչվող պատկերների կամ պատկերների հատվածների հետ:

Stable Diffusion-ի օգտատերերը կարող են ուսումնասիրել մոդելի մեջ ուսուցանված հասկացությունները՝ հարցումներ կատարելով LAION-էսթետիկ տվյալների շտեմարանում՝ ավելի մեծ LAION 5B տվյալների բազայի ենթաբազմություն, որն ապահովում է համակարգը: Պատկերները դասավորված են ոչ թե իրենց այբբենական պիտակներով, այլ իրենց «գեղագիտական գնահատականով»: Աղբյուր՝ https://rom1504.github.io/clip-retrieval/
A լավ հիերարխիա Անհատական պիտակները և դասերը, որոնք նպաստում են մարդու ձեռքի պատկերմանը, նման կլինեն մարմին > ձեռք > ձեռք > մատներ > [ենթանշաններ + բթամատ] > [նիշի հատվածներ]> մատների եղունգներ.

Ձեռքի մասերի հատիկավոր իմաստային հատվածավորում: Նույնիսկ այս անսովոր մանրակրկիտ դեկոնստրուկցիան թողնում է յուրաքանչյուր «մատ» որպես միակ էություն՝ հաշվի չառնելով մատի երեք հատվածները և բութ մատի երկու հատվածները: Աղբյուր՝ https://athitsos.utasites.cloud/publications/rezaei_petra2021.pdf
Իրականում, սկզբնաղբյուրի պատկերները դժվար թե այդքան հետևողականորեն նշվեն ամբողջ տվյալների շտեմարանում, և չվերահսկվող պիտակավորման ալգորիթմները, հավանաբար, կդադարեն ավելի բարձր օրինակ՝ «ձեռքի» մակարդակը և թողնել ներքին պիքսելները (որոնք տեխնիկապես պարունակում են «մատի» տեղեկատվություն) որպես պիքսելների չպիտակավորված զանգված, որից կամայականորեն կբխեն հատկանիշները, և որոնք հետագայում կարող են դրսևորվել որպես ջղաձգվող տարր:

Ինչպես այն պետք է լինի (վերևի աջ, եթե ոչ վերևի կտրվածք), և ինչպես է այն հակված լինելու (ներքևի աջ կողմում), պիտակավորման համար սահմանափակ ռեսուրսների կամ այդպիսի պիտակների ճարտարապետական շահագործման պատճառով, եթե դրանք գոյություն ունեն տվյալների բազայում:
Այսպիսով, եթե թաքնված դիֆուզիոն մոդելը հասնում է այնքան, որքան ձեռք է տալիս ձեռքը, ապա գրեթե անկասկած, գոնե ձեռք կբերի այդ թևի վերջում, քանի որ arm> ձեռք նվազագույն անհրաժեշտ հիերարխիա է, որը բավականին բարձր է այն ամենի մեջ, ինչ ճարտարապետությունը գիտի «մարդու անատոմիայի» մասին:
Դրանից հետո «մատները» կարող են լինել ամենափոքր խմբավորումը, թեև կան ևս 14 ենթամասեր, որոնք պետք է հաշվի առնել մարդու ձեռքերը պատկերելիս:
Եթե այս տեսությունը հաստատվի, ապա իրական լուծում չկա՝ պայմանավորված ձեռքով ծանոթագրությունների համար նախատեսված բյուջեի բացակայությամբ և համարժեք արդյունավետ ալգորիթմների բացակայությամբ, որոնք կարող են ավտոմատացնել պիտակավորումը՝ միաժամանակ ստեղծելով սխալի ցածր մակարդակ: Փաստորեն, մոդելը ներկայումս կարող է հիմնվել թղթի վրա մարդու անատոմիական հետևողականության վրա՝ հաշվի առնելով այն տվյալների բազայի թերությունները, որոնց վրա վերապատրաստվել է:
Դրա հնարավոր պատճառներից մեկը չի կարող հենվել սրա վրա, վերջերս առաջարկեց Stable Diffusion Discord-ում այն է, որ մոդելը կարող է շփոթվել մատների ճիշտ քանակի հարցում, որը պետք է ունենա (իրատեսական) մարդու ձեռքը, քանի որ LAION-ից ստացված տվյալների բազան, որը սնուցում է այն, պարունակում է մուլտհերոսներ, որոնք կարող են ունենալ ավելի քիչ մատներ (ինչն ինքնին աշխատուժ խնայող դյուրանցում).

Կայուն դիֆուզիոն և նմանատիպ մոդելներում «բացակայող մատի» համախտանիշի հավանական մեղավորներից երկուսը: Ստորև բերված են մուլտֆիլմի ձեռքերի օրինակներ LAION-էսթետիկական տվյալների բազայից, որն ապահովում է Stable Diffusion-ը: Աղբյուր՝ https://www.youtube.com/watch?v=0QZFQ3gbd6I
Եթե դա ճիշտ է, ապա միակ ակնհայտ լուծումը մոդելի վերապատրաստումն է, բացառելով ոչ իրատեսական մարդու վրա հիմնված բովանդակությունը, ապահովելով, որ բացթողումների իրական դեպքերը (այսինքն անդամահատվածները) պատշաճ կերպով պիտակավորված լինեն որպես բացառություններ: Միայն տվյալների մշակման կետից սա բավականին մարտահրավեր կլինի, հատկապես ռեսուրսների կարիք ունեցող համայնքի ջանքերի համար:
Երկրորդ մոտեցումը կլինի ֆիլտրերի կիրառումը, որոնք բացառում են նման բովանդակության (այսինքն՝ «ձեռքը երեք/հինգ մատով») դրսևորումը ցուցադրման ժամանակ, մոտավորապես այնպես, ինչպես OpenAI-ն, որոշակի չափով, ֆիլտրացված GPT-3 և DALL-E2, որպեսզի դրանց արդյունքը կարգավորվի՝ առանց աղբյուրի մոդելների վերապատրաստման կարիքի:

Stable Diffusion-ի համար թվանշանների և նույնիսկ վերջույթների միջև իմաստային տարբերությունը կարող է սարսափելիորեն մշուշոտվել՝ հիշելով 1980-ականների «մարմնի սարսափ» ֆիլմերը, ինչպիսիք են Դեյվիդ Քրոնենբերգը: Աղբյուր՝ https://old.reddit.com/r/StableDiffusion/comments/x6htf6/a_study_of_stable_diffusions_strange_relationship/
Այնուամենայնիվ, կրկին, սա կպահանջի պիտակներ, որոնք կարող են գոյություն չունենալ բոլոր ազդակիր պատկերների վրա՝ թողնելով մեզ նույն նյութատեխնիկական և բյուջետային մարտահրավերի առաջ:
Կարելի է պնդել, որ դեռ երկու ճանապարհ կա՝ խնդրին ավելի շատ տվյալներ տրամադրելը և երրորդ կողմի մեկնաբանման համակարգերի կիրառումը, որոնք կարող են միջամտել, երբ վերջնական օգտագործողին ներկայացվում են այստեղ նկարագրված տիպի ֆիզիկական կեղծիքներ (առնվազն, վերջինս OpenAI-ին կտրամադրի «մարմնի սարսափով» ռենդերի համար փոխհատուցում տրամադրելու մեթոդ, եթե ընկերությունը դրդված լիներ դա անել):
3: Անհատականացում
Stable Diffusion-ի ապագայի համար ամենահուզիչ հնարավորություններից մեկը վերանայված համակարգեր մշակող օգտատերերի կամ կազմակերպությունների հեռանկարն է. փոփոխություններ, որոնք թույլ են տալիս նախապես պատրաստված LAION ոլորտից դուրս բովանդակությունը ինտեգրվել համակարգին, իդեալական՝ առանց ամբողջ մոդելի վերապատրաստման անկառավարելի ծախսերի, կամ ռիսկի, որը բխում է, երբ մեծ ծավալի նոր պատկերներ վերապատրաստվում են գոյություն ունեցող, հասուն և ունակ նկարների համար: մոդել.
Համեմատությամբ. եթե երկու պակաս օժտված ուսանողներ միանան երեսուն ուսանողներից բաղկացած առաջադեմ դասարանին, նրանք կամ կձուլվեն և կհասնեն, կամ կձախողվեն որպես արտասովոր: երկու դեպքում էլ, դասի միջին կատարողականը հավանաբար չի ազդի: Եթե միանան 15 պակաս շնորհալի ուսանողներ, այնուամենայնիվ, ամբողջ դասարանի գնահատականի կորը, ամենայն հավանականությամբ, կտուժի:
Նմանապես, փոխհարաբերությունների սիներգիկ և բավականին նուրբ ցանցը, որը ստեղծվել է մոդելի կայուն և թանկ ուսուցման վրա, կարող է վտանգվել, որոշ դեպքերում արդյունավետորեն ոչնչացվել չափազանց նոր տվյալների պատճառով՝ նվազեցնելով մոդելի արտադրանքի որակը ամբողջ պլանում:
Սա հիմնականում այն է, երբ ձեր հետաքրքրությունը կայանում է նրանում, որ մոդելի կողմից փոխհարաբերությունների և իրերի հայեցակարգային ըմբռնումն ամբողջությամբ թալանելն է և այն յուրացնելը բացառիկ բովանդակության արտադրության համար, որը նման է ձեր ավելացրած լրացուցիչ նյութին:
Այսպիսով, ուսուցում 500,000 Simpsons շրջանակները գոյություն ունեցող Stable Diffusion անցակետում, ամենայն հավանականությամբ, ի վերջո, ձեզ ավելի լավ կդարձնեն Simpsons սիմուլյատոր, քան կարող էր առաջարկել սկզբնական կառուցումը, ենթադրելով, որ բավականաչափ լայն իմաստային հարաբերություններ գոյատևում են գործընթացը (այսինքն. Հոմեր Սիմփսոնը հոթդոգ է ուտում, որը կարող է պահանջել հոթ-դոգի մասին նյութեր, որոնք չկար ձեր լրացուցիչ նյութում, բայց արդեն գոյություն ունեին անցակետում), և ենթադրելով, որ դուք չեք ցանկանում հանկարծակի անցնել։ Simpsons բովանդակություն ստեղծելու համար Գրեգ Ռուտկովսկու առասպելական բնապատկեր – որովհետև վերապատրաստված ձեր մոդելի ուշադրությունը զանգվածաբար շեղվել է, և նախկինի պես լավ չի լինի նման բան անելու մեջ:
Դրա ուշագրավ օրինակն է waifu-դիֆուզիոն, որը հաջողությամբ հետմարզված 56,000 անիմե պատկերներ ավարտված և պատրաստված կայուն դիֆուզիոն անցակետում: Հոբբիստի համար դա դժվար հեռանկար է, սակայն, քանի որ մոդելի համար պահանջվում է նվազագույնը 30 ԳԲ VRAM, ինչը շատ ավելին է, քան հնարավոր է հասանելի լինի սպառողների մակարդակում NVIDIA-ի առաջիկա 40XX սերիայի թողարկումներում:

Պատվերով բովանդակության վերապատրաստումը կայուն տարածման մեջ waifu-diffusion-ի միջոցով. մոդելը տևեց երկու շաբաթ հետմարզումներ՝ այս մակարդակի նկարազարդման համար: Ձախ կողմում գտնվող վեց պատկերները ցույց են տալիս մոդելի առաջընթացը, երբ ուսուցումն ընթանում էր, նոր ուսուցման տվյալների հիման վրա առարկայական համահունչ արդյունք ստեղծելու հարցում: Աղբյուր՝ https://gigazine.net/gsc_news/en/20220121-how-waifu-labs-create/
Կարելի է մեծ ջանք ծախսել Stable Diffusion անցակետերի նման «պատառաքաղների» վրա՝ միայն տեխնիկական պարտքի պատճառով: Պաշտոնական Discord-ի մշակողները արդեն նշել են, որ անցակետերի հետագա թողարկումները պարտադիր չէ, որ լինեն հետամնաց, նույնիսկ արագ տրամաբանությամբ, որը կարող է աշխատել նախորդ տարբերակի հետ, քանի որ նրանց հիմնական շահը հնարավոր լավագույն մոդելը ձեռք բերելն է, այլ ոչ թե աջակցելը: ժառանգական դիմումներ և գործընթացներ:
Հետևաբար, ընկերությունը կամ անհատը, որը որոշում է անցակետը բաժանել առևտրային ապրանքի, գործնականում հետդարձի ճանապարհ չունի. մոդելի նրանց տարբերակն այդ պահին «կոշտ պատառաքաղ» է և չի կարողանա օգուտներ քաղել stability.ai-ի հետագա թողարկումներից, ինչը բավականին պարտավորություն է:
Stable Diffusion-ի հարմարեցման ընթացիկ և ավելի մեծ հույսն է Տեքստային ինվերսիա, որտեղ օգտատերը մարզվում է փոքր բուռում CLIP- հավասարեցված պատկերներ:

Թել Ավիվի համալսարանի և NVIDIA-ի համագործակցությունը, տեքստային ինվերսիան թույլ է տալիս ուսուցանել դիսկրետ և նոր սուբյեկտներ՝ առանց սկզբնաղբյուրի մոդելի հնարավորությունները ոչնչացնելու: Աղբյուր՝ https://textual-inversion.github.io/
Տեքստային ինվերսիայի առաջնային ակնհայտ սահմանափակումն այն է, որ առաջարկվում է շատ քիչ թվով պատկերներ՝ ընդամենը հինգը: Սա արդյունավետորեն ստեղծում է սահմանափակ միավոր, որը կարող է ավելի օգտակար լինել ոճի փոխանցման առաջադրանքների համար, այլ ոչ թե ֆոտոռեալիստական օբյեկտների տեղադրման համար:
Այնուամենայնիվ, ներկայումս փորձեր են տեղի ունենում տարբեր Կայուն դիֆուզիոն տարաձայնությունների շրջանակներում, որոնք օգտագործում են շատ ավելի մեծ թվով ուսուցման պատկերներ, և դեռ պետք է պարզել, թե որքան արդյունավետ կարող է լինել մեթոդը: Կրկին, տեխնիկան պահանջում է մեծ VRAM, ժամանակ և համբերություն:
Այս սահմանափակող գործոնների պատճառով մենք կարող ենք որոշ ժամանակ սպասել՝ տեսնելու Stable Diffusion-ի սիրահարների տեքստային ինվերսիայի ավելի բարդ փորձերը, և արդյոք այս մոտեցումը կարող է ձեզ «ներկայացնել պատկերի մեջ» այնպես, որ ավելի լավ տեսք ունենա, քան Photoshop-ի կտրում և տեղադրում` պահպանելով պաշտոնական անցակետերի ապշեցուցիչ ֆունկցիոնալությունը:
Առաջին անգամ հրապարակվել է 6 թվականի սեպտեմբերի 2022-ին։















