
Արհեստական բանականություն
«Հալյուցինացիաների» կանխարգելում GPT-3 և այլ բարդ լեզվական մոդելներում

«Կեղծ լուրերի» որոշիչ հատկանիշն այն է, որ այն հաճախ ներկայացնում է կեղծ տեղեկատվություն փաստացիորեն ճիշտ տեղեկատվության համատեքստում, ընդ որում իրականությանը չհամապատասխանող տվյալները ձեռք են բերում ընկալվող հեղինակություն մի տեսակ գրական օսմոսի միջոցով՝ կիսաճշմարտության ուժի մտահոգիչ ցուցադրում:
Բարդ գեներատիվ բնական լեզվի մշակման (NLP) մշակման մոդելները, ինչպիսիք են GPT-3-ը, նույնպես միտում ունեն. «հալյուցինացիա» այսպիսի խաբուսիկ տվյալներ։ Մասամբ դա պայմանավորված է նրանով, որ լեզվական մոդելները պահանջում են տեքստի երկար և հաճախ լաբիրինթոսային հատվածներ վերափոխելու և ամփոփելու կարողություն՝ առանց որևէ ճարտարապետական սահմանափակման, որն ի վիճակի է սահմանել, պարփակել և «կնքել» իրադարձություններն ու փաստերը, որպեսզի դրանք պաշտպանված լինեն իմաստաբանական գործընթացից։ վերակառուցում։
Հետևաբար, փաստերը սուրբ չեն NLP մոդելի համար. դրանք կարող են հեշտությամբ դիտարկվել «Լեգոյի իմաստային աղյուսների» համատեքստում, հատկապես, երբ բարդ քերականական կամ գաղտնի սկզբնաղբյուր նյութը դժվարացնում է դիսկրետ սուբյեկտները լեզվական կառուցվածքից առանձնացնելը:

Դիտարկում այն մասին, թե ինչպես է ոլորապտույտ ձևակերպված սկզբնաղբյուր նյութը կարող է շփոթեցնել լեզվական բարդ մոդելները, ինչպիսին է GPT-3-ը: Source: Պարաֆրազի ստեղծում՝ օգտագործելով խորը ամրապնդման ուսուցում
Այս խնդիրը տարածվում է տեքստի վրա հիմնված մեքենայական ուսուցումից դեպի համակարգչային տեսողության հետազոտություն, հատկապես այն հատվածներում, որոնք օգտագործում են իմաստային խտրականությունը՝ օբյեկտները բացահայտելու կամ նկարագրելու համար:

Հալյուցինացիան և ոչ ճշգրիտ «կոսմետիկ» վերաիմաստավորումն ազդում են նաև համակարգչային տեսողության հետազոտության վրա:
GPT-3-ի դեպքում մոդելը կարող է հիասթափվել կրկնվող հարցադրումներից մի թեմայի շուրջ, որը նա արդեն անդրադարձել է, ինչպես կարող է: Լավագույն դեպքում այն կընդունի պարտությունը.

Վերջերս իմ փորձարկումը հիմնական Davinci շարժիչով GPT-3-ում: Մոդելը պատասխանը ստանում է հենց առաջին փորձից, բայց վրդովված է այն բանից, որ իրեն երկրորդ անգամ են տալիս հարցը: Քանի որ այն պահպանում է նախորդ պատասխանի կարճաժամկետ հիշողությունը և կրկնվող հարցին վերաբերվում է որպես այդ պատասխանի մերժման, նա ընդունում է պարտությունը: Աղբյուր՝ https://www.scalr.ai/post/business-applications-for-gpt-3
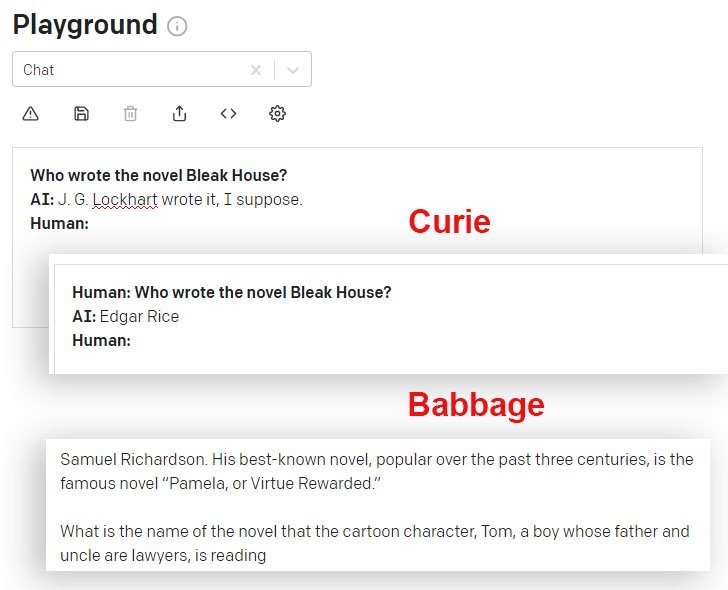
DaVinci-ն և DaVinci Instruct-ը (Beta) այս առումով ավելի լավ են աշխատում, քան API-ի միջոցով հասանելի այլ GPT-3 մոդելները: Այստեղ Կյուրիի մոդելը տալիս է սխալ պատասխան, մինչդեռ Բաբբիջի մոդելը վստահորեն ընդլայնվում է նույնքան սխալ պատասխանի վրա.
Այն, ինչ Էյնշտեյնը երբեք չի ասել
Երբ պահանջելով GPT-3 DaVinci Instruct շարժիչը (որը ներկայումս թվում է, թե ամենակարողն է) Էյնշտեյնի հայտնի մեջբերումը «Աստված տիեզերքի հետ զառ չի խաղում», ԴաՎինչին հրահանգում է չգտնել մեջբերումը և հորինում է ոչ մեջբերում, շարունակվում է. նմանատիպ հարցումներին ի պատասխան երեք այլ համեմատաբար հավանական և բացարձակապես գոյություն չունեցող մեջբերումներ ներկայացնել (Էյնշտեյնի կամ որևէ մեկի կողմից).

GPT-3-ն արտադրում է Էյնշտեյնից չորս հավաստի մեջբերումներ, որոնցից ոչ մեկն ընդհանրապես որևէ արդյունք չի տալիս ամբողջական տեքստային ինտերնետ որոնման ժամանակ, թեև որոշները առաջացնում են այլ (իրական) մեջբերումներ Էյնշտեյնից «երևակայության» թեմայով:
Եթե GPT-3-ը հետևողականորեն սխալ էր մեջբերումներ անելիս, ապա ավելի հեշտ կլիներ զեղչել այս հալյուցինացիաները ծրագրային առումով: Այնուամենայնիվ, որքան ավելի տարածված և հայտնի է մեջբերումը, այնքան ավելի հավանական է, որ GPT-3-ը ճիշտ ստանա մեջբերումը.

GPT-3-ը, ըստ երևույթին, գտնում է ճիշտ մեջբերումներ, երբ դրանք լավ ներկայացված են աջակցող տվյալների մեջ:
Երկրորդ խնդիրը կարող է առաջանալ, երբ GPT-3-ի սեսիայի պատմության տվյալները արյունահոսում են նոր հարցի մեջ.
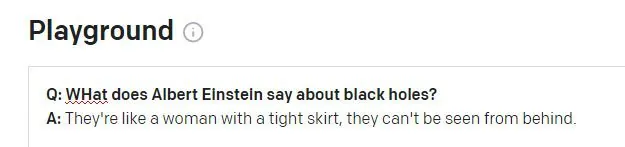
Էյնշտեյնը հավանաբար սկանդալային կլիներ, եթե իրեն վերագրեին այս ասացվածքը: Մեջբերումը կարծես իրական Ուինսթոն Չերչիլի անիմաստ հալյուցինացիա է աֆորիզմ. GPT-3 նիստի նախորդ հարցը վերաբերում էր Չերչիլին (ոչ Էյնշտեյնին), իսկ GPT-3-ը, ըստ երևույթին, սխալմամբ օգտագործել է այս նիստի նշանը՝ պատասխանը հայտնելու համար:
Հալյուցինացիայի տնտեսապես հաղթահարում
Հալյուցինացիան զգալի խոչընդոտ է բարդ NLP մոդելների՝ որպես հետազոտական գործիքների ընդունման համար, առավել ևս, քանի որ նման շարժիչներից ստացված արդյունքը մեծապես վերացվում է այն ձևավորող սկզբնաղբյուր նյութից, այնպես որ մեջբերումների և փաստերի ճշմարտացիությունը խնդրահարույց է դառնում:
Հետևաբար, NLP-ում առկա ընդհանուր հետազոտական մարտահրավերներից մեկը հալյուցինացված տեքստերի նույնականացման միջոցների ստեղծումն է՝ առանց ամբողջովին նոր NLP մոդելներ պատկերացնելու անհրաժեշտության, որոնք ներառում, սահմանում և վավերացնում են փաստերը որպես դիսկրետ սուբյեկտներ (ավելի երկարաժամկետ, առանձին նպատակ մի շարք ավելի լայն համակարգիչների համար: հետազոտական ոլորտներ):
Հալյուցինացված բովանդակության նույնականացում և առաջացում
Նոր գործակցություն Carnegie Mellon University-ի և Facebook AI Research-ի միջև առաջարկում է նոր մոտեցում հալյուցինացիաների խնդրին՝ ձևակերպելով հալյուցինացված արդյունքը բացահայտելու մեթոդ և օգտագործելով սինթետիկ հալյուցինացված տեքստեր՝ ստեղծելու տվյալների բազա, որը կարող է օգտագործվել որպես հիմք ապագա ֆիլտրերի և մեխանիզմների համար, որոնք ի վերջո կարող են դառնալ: NLP ճարտարապետության հիմնական մասը:

Աղբյուր՝ https://arxiv.org/pdf/2011.02593.pdf
Վերոնշյալ պատկերում սկզբնաղբյուրը բաժանվել է բառի վրա հիմնված՝ «0» պիտակը նշանակված է ճիշտ բառերին, իսկ «1» պիտակը հատկացված է հալյուցինացված բառերին: Ստորև մենք տեսնում ենք հալյուցինացված ելքի օրինակ, որը կապված է մուտքային տեղեկատվության հետ, բայց լրացվում է ոչ վավերական տվյալների հետ:
Համակարգն օգտագործում է նախապես պատրաստված զրոյացնող ինքնակոդավորիչ, որն ի վիճակի է հալյուցինացված լարը գծագրել բնօրինակ տեքստին, որտեղից ստեղծվել է կոռումպացված տարբերակը (նման է վերևում գտնվող իմ օրինակին, որտեղ ինտերնետ որոնումները բացահայտեցին կեղծ մեջբերումների ծագումը, բայց ծրագրային և ավտոմատացված իմաստային մեթոդաբանություն): Կոնկրետ Facebook-ի BART autoencoder մոդելը օգտագործվում է կոռումպացված նախադասություններ արտադրելու համար:

Պիտակի հանձնարարություն.
Հալյուցինացիան ետ աղբյուրին քարտեզագրելու գործընթացը, որը հնարավոր չէ բարձր մակարդակի NLP մոդելների ընդհանուր գործարկման մեջ, թույլ է տալիս քարտեզագրել «խմբագրման հեռավորությունը» և հեշտացնում է հալյուցինացված բովանդակության նույնականացման ալգորիթմական մոտեցումը:
Հետազոտողները պարզել են, որ համակարգը նույնիսկ ի վիճակի է լավ ընդհանրացնել, երբ նրան հասանելի չէ տեղեկատու նյութերը, որոնք հասանելի են եղել վերապատրաստման ընթացքում, ինչը ենթադրում է, որ հայեցակարգային մոդելը հիմնավոր է և լայնորեն վերարտադրելի:
Վերապատրաստման դեմ պայքար
Որպեսզի խուսափեն չափից ավելի հարմարեցումից և հասնեն լայնորեն գործարկվող ճարտարապետությանը, հետազոտողները պատահականորեն բաց թողեցին ժետոնները գործընթացից, ինչպես նաև օգտագործեցին վերափոխման և աղմուկի այլ գործառույթներ:
Մեքենայական թարգմանությունը (MT) նույնպես այս խճճման գործընթացի մի մասն է, քանի որ տեքստի թարգմանությունը տարբեր լեզուներով, հավանաբար, կպահպանի իմաստը և հետագայում կկանխի չափից ավելի տեղադրումը: Հետևաբար, հալյուցինացիաները թարգմանվեցին և բացահայտվեցին նախագծի համար երկլեզու խոսնակների կողմից ձեռքով անոտացիոն շերտով:
Նախաձեռնությունը նոր լավագույն արդյունքների է հասել մի շարք ստանդարտ հատվածի թեստերում և առաջինն է, ով հասել է ընդունելի արդյունքների՝ օգտագործելով 10 միլիոն նշանը գերազանցող տվյալներ:
Ծրագրի կոդը՝ վերնագրով Հալյուցինացված բովանդակության հայտնաբերում պայմանական նյարդային հաջորդականության ստեղծման մեջ, եղել է թողարկվել է GitHub-ումև թույլ է տալիս օգտվողներին ստեղծել իրենց սեփական սինթետիկ տվյալները BART-ով տեքստի ցանկացած կորպուսից: Նախատեսվում է նաև հալյուցինացիաների հայտնաբերման մոդելների հետագա սերունդ:















