
Արհեստական բանականություն
Google-ի LipSync3D-ն առաջարկում է «Deepfaked» բերանի շարժման բարելավված համաժամացում

A գործակցություն Google AI հետազոտողների և Հնդկական տեխնոլոգիական ինստիտուտի Խարագպուրը առաջարկում է նոր շրջանակ՝ ձայնային բովանդակությունից խոսող գլուխները սինթեզելու համար: Նախագիծը նպատակ ունի օպտիմիզացված և ողջամիտ ռեսուրսներով միջոցներ ստեղծել աուդիոյից «խոսող գլխի» վիդեո բովանդակություն ստեղծելու համար՝ շրթունքների շարժումները կրկնօրինակված կամ մեքենայացված ձայնի հետ համաժամեցնելու, ինչպես նաև ավատարներում, ինտերակտիվ հավելվածներում և այլ ծրագրերում օգտագործելու համար։ իրական ժամանակի միջավայրեր.

Աղբյուրը՝ https://www.youtube.com/watch?v=L1StbX9OznY
Գործընթացում վերապատրաստված մեքենայական ուսուցման մոդելները, որոնք կոչվում են LipSync3D, պահանջում են թիրախի դեմքի նույնականության միայն մեկ տեսանյութ՝ որպես մուտքային տվյալ: Տվյալների պատրաստման խողովակաշարը առանձնացնում է դեմքի երկրաչափության արդյունահանումը լուսավորության և մուտքային տեսանյութի այլ կողմերի գնահատումից՝ թույլ տալով ավելի խնայող և կենտրոնացված ուսուցում:
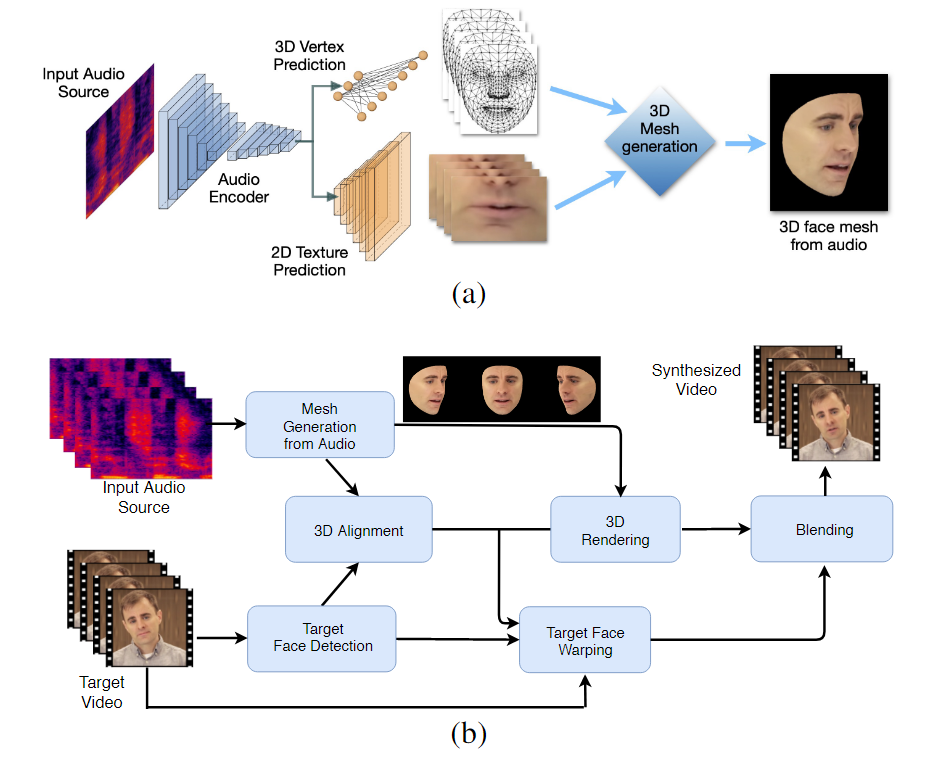
LipSync3D-ի երկփուլ աշխատանքային հոսքը: Վերևում՝ «թիրախային» աուդիոից դինամիկ տեքստուրավորված 3D դեմքի ձևավորում. ստորև՝ ստեղծված ցանցի ներդրումը թիրախային տեսանյութի մեջ:
Իրականում, LipSync3D-ի ամենաուշագրավ ներդրումը այս ոլորտում հետազոտական ջանքերի մեջ կարող է լինել նրա լուսավորության նորմալացման ալգորիթմը, որը բաժանում է ուսուցումն ու եզրակացության լուսավորությունը:

Լուսավորման տվյալների անջատումը ընդհանուր երկրաչափությունից օգնում է LipSync3D-ին դժվարին պայմաններում արտադրել շուրթերի շարժման ավելի իրատեսական արդյունք: Վերջին տարիների մյուս մոտեցումները սահմանափակվել են «ֆիքսված» լուսավորության պայմաններով, որոնք չեն բացահայտի դրանց ավելի սահմանափակ հնարավորություններն այս առումով:
Մուտքային տվյալների շրջանակների նախնական մշակման ժամանակ համակարգը պետք է հայտնաբերի և հեռացնի սպեկուլյար կետերը, քանի որ դրանք հատուկ են լուսային պայմաններին, որոնցում նկարահանվել է տեսանյութը, և հակառակ դեպքում կխանգարեն վերալուսավորման գործընթացին:

LipSync3D-ը, ինչպես ենթադրում է նրա անունը, չի կատարում զուտ պիքսելային վերլուծություն այն դեմքերի վրա, որոնք նա գնահատում է, այլ ակտիվորեն օգտագործում է դեմքի հայտնաբերված ուղենիշները՝ շարժական CGI ոճի ցանցեր ստեղծելու համար, ինչպես նաև «բացված» հյուսվածքները, որոնք փաթաթված են դրանց շուրջը ավանդական CGI-ով: խողովակաշար.

Պոզի նորմալացում LipSync3D-ում: Ձախ կողմում մուտքագրված շրջանակներն են և հայտնաբերված հատկանիշները. մեջտեղում, առաջացած ցանցի գնահատման նորմալացված գագաթները. իսկ աջ կողմում՝ համապատասխան հյուսվածքային ատլասը, որն ապահովում է հիմքի ճշմարտությունը հյուսվածքների կանխատեսման համար: Աղբյուր՝ https://arxiv.org/pdf/2106.04185.pdf
Բացի նոր լուսավորության մեթոդից, հետազոտողները պնդում են, որ LipSync3D-ն առաջարկում է երեք հիմնական նորամուծություն նախորդ աշխատանքի վերաբերյալ. հեշտությամբ վարժեցվող ավտոմատ ռեգրեսիվ հյուսվածքների կանխատեսման մոդել, որն արտադրում է ժամանակավորապես հետևողական տեսանյութերի սինթեզ; և ավելացել է իրատեսությունը, ինչպես գնահատվում է մարդկային վարկանիշներով և օբյեկտիվ չափանիշներով:

Տեսանյութի դեմքի պատկերների տարբեր կողմերը բաժանելը թույլ է տալիս ավելի մեծ վերահսկողություն վիդեո սինթեզում:
LipSync3D-ը կարող է համապատասխան շուրթերի երկրաչափական շարժումներ ստանալ անմիջապես աուդիոյից՝ վերլուծելով հնչյունները և խոսքի այլ կողմերը և դրանք թարգմանելով բերանի տարածքի շուրջ հայտնի համապատասխան մկանային դիրքերի:

Այս գործընթացը օգտագործում է համատեղ կանխատեսման խողովակաշար, որտեղ ենթադրվող երկրաչափությունը և հյուսվածքը ունեն հատուկ կոդավորիչներ՝ ավտոմատ կոդավորիչի կարգավորմամբ, բայց կիսում են աուդիո կոդավորիչը այն խոսքի հետ, որը նախատեսվում է պարտադրել մոդելին.

LipSync3D-ի անկայուն շարժման սինթեզը նաև նախատեսված է սնուցելու ոճավորված CGI ավատարները, որոնք, ըստ էության, ցանցի և հյուսվածքային տեղեկատվության նույն տեսակն են, ինչ իրական աշխարհի պատկերները.
Ոճավորված 3D ավատարի շուրթերի շարժումներն իրական ժամանակում ապահովվում են աղբյուրի բարձրախոսի տեսանյութի միջոցով: Նման սցենարի դեպքում լավագույն արդյունքները ձեռք կբերվեն անհատականացված նախնական վերապատրաստման միջոցով:
Հետազոտողները նաև ակնկալում են ավատարների օգտագործումը մի փոքր ավելի իրատեսական զգացողությամբ.
![]()
Տեսանյութերի ուսուցման օրինակելի ժամերը տատանվում են 3-5 ժամից 2-5 րոպեանոց տեսանյութի համար, խողովակաշարում, որն օգտագործում է TensorFlow, Python և C++ GeForce GTX 1080-ի վրա: Դասընթացների ընթացքում օգտագործվել է 128 կադրի խմբաքանակ՝ ավելի քան 500-1000: դարաշրջաններ, որոնցից յուրաքանչյուրը ներկայացնում է տեսանյութի ամբողջական գնահատականը:

Շուրթերի շարժման դինամիկ վերասինխավորման ուղղությամբ
Նոր աուդիո շրթունքներ տեղադրելու համար շուրթերի վերասինխավորման ոլորտը վերջին մի քանի տարիների ընթացքում մեծ ուշադրության է արժանացել համակարգչային տեսողության հետազոտության մեջ (տե՛ս ստորև), հատկապես, քանի որ դա հակասականների կողմնակի արդյունք է: խորքային տեխնոլոգիա.
Վաշինգտոնի համալսարանը 2017թ ներկայացրել է հետազոտություն ընդունակ է սովորել շուրթերի համաժամացումը աուդիոյից՝ օգտագործելով այն՝ փոխելու այն ժամանակվա նախագահ Օբամայի շուրթերի շարժումները: 2018 թվականին; ղեկավարել է Մաքս Պլանկի Ինֆորմատիկայի ինստիտուտը մեկ այլ հետազոտական նախաձեռնություն հնարավորություն ընձեռելու նույնականություն>ինքնության վիդեո փոխանցում, շրթունքների համաժամեցմամբ ա գործընթացի կողմնակի արտադրանք; և 2021 թվականի մայիսին AI ստարտափը FlawlessAI բացահայտեց իր սեփական շուրթերի համաժամացման TrueSync տեխնոլոգիան, լայնորեն: ստացել մամուլում՝ որպես տարբեր լեզուներով հիմնական ֆիլմերի թողարկումների բարելավված կրկնօրինակման տեխնոլոգիաների հնարավորություն:
Եվ, իհարկե, խորը կեղծ բաց կոդով պահեստների շարունակական զարգացումը ապահովում է օգտատերերի կողմից ներդրված ակտիվ հետազոտության ևս մեկ ճյուղ դեմքի պատկերների սինթեզի այս ոլորտում:















