
Արհեստական բանականություն
Մեկ հարցի համար GPT ոճի լեզվի մոդելի ստեղծում

Չինաստանից հետազոտողները մշակել են GPT-3 ոճի բնական լեզվի մշակման համակարգեր ստեղծելու տնտեսական մեթոդ՝ միաժամանակ խուսափելով ժամանակի և փողի հետզհետե արգելող ծախսերից, որոնք ներգրավված են տվյալների մեծ ծավալի ուսուցման մեջ. FAANG-ի խաղացողներին և բարձր մակարդակի ներդրողներին:
Առաջարկվող շրջանակը կոչվում է Առաջադրանքների վրա հիմնված լեզվի մոդելավորում (TLM): Միլիարդավոր բառերի և հազարավոր պիտակների ու դասերի հսկայական կորպուսի վրա հսկայական և բարդ մոդել պատրաստելու փոխարեն, TLM-ը պատրաստում է շատ ավելի փոքր մոդել, որն իրականում ներառում է հարցում անմիջապես մոդելի ներսում:

Ձախ, տիպիկ հիպերսանդղակի մոտեցում բարձր ծավալի լեզվական մոդելներին; ճիշտ է, TLM-ի բարակ մեթոդը՝ ուսումնասիրելու լեզվական մեծ կորպուսը յուրաքանչյուր թեմայի կամ յուրաքանչյուր հարցի հիման վրա: Աղբյուր՝ https://arxiv.org/pdf/2111.04130.pdf
Արդյունավետորեն, ստեղծվում է եզակի NLP ալգորիթմ կամ մոդել՝ մեկ հարցի պատասխանելու համար, փոխարենը ստեղծելու հսկայական և անգործունակ ընդհանուր լեզվական մոդել, որը կարող է պատասխանել ավելի լայն հարցերի:
TLM-ի փորձարկման ժամանակ հետազոտողները պարզել են, որ նոր մոտեցումը հասնում է այնպիսի արդյունքների, որոնք նման են կամ ավելի լավը, քան նախապես պատրաստված լեզվական մոդելները, ինչպիսիք են. RoBERTa-Largeև հիպերմաշտաբային NLP համակարգեր, ինչպիսիք են OpenAI-ի GPT-3-ը, Google-ի TRILLION պարամետրի փոխարկիչ տրանսֆորմատորը մոդել, Կորեա HyperClover, AI21 Labs' Jurassic 1և Microsoft-ի Megatron-Turing NLG 530B.
TLM-ի փորձարկումների ընթացքում ութ դասակարգման տվյալների հավաքածուներ չորս տիրույթներում, հեղինակները լրացուցիչ պարզել են, որ համակարգը նվազեցնում է ուսումնական FLOP-ները (լողացող կետով գործողություններ վայրկյանում) պահանջվում է մեծության երկու կարգով: Հետազոտողները հույս ունեն, որ TLM-ը կարող է «ժողովրդավարացնել» մի հատված, որը գնալով ավելի էլիտար է դառնում՝ NLP մոդելներով այնքան մեծ, որ դրանք իրականում չեն կարող տեղակայվել տեղական մակարդակում, և փոխարենը, GPT-3-ի դեպքում, նստել ետևում: թանկ և OpenAI-ի սահմանափակ հասանելիությամբ API-ներ և, այժմ, Microsoft Azure.
Հեղինակները նշում են, որ ուսուցման ժամանակը երկու աստիճանով կրճատելը նվազեցնում է վերապատրաստման ծախսերը մեկ օրվա համար ավելի քան 1,000 GPU-ով մինչև 8 ժամվա ընթացքում ընդամենը 48 GPU:
Նոր հաշվետվություն վերնագրված է NLP զրոյից առանց լայնածավալ նախնական վերապատրաստման. պարզ և արդյունավետ շրջանակ, և գալիս է Պեկինի Ցինհուա համալսարանի երեք հետազոտողներից և Չինաստանում գործող AI զարգացման ընկերության Recurrent AI, Inc.-ից:
Անհասանելի պատասխաններ
The արժենալ Արդյունավետ, համապարփակ լեզվական մոդելների ուսուցումը գնալով ավելի ու ավելի է բնութագրվում որպես պոտենցիալ «ջերմային սահման», որը ցույց է տալիս, թե որքանով արդյունավետ և ճշգրիտ NLP-ն իսկապես կարող է տարածվել մշակույթում:
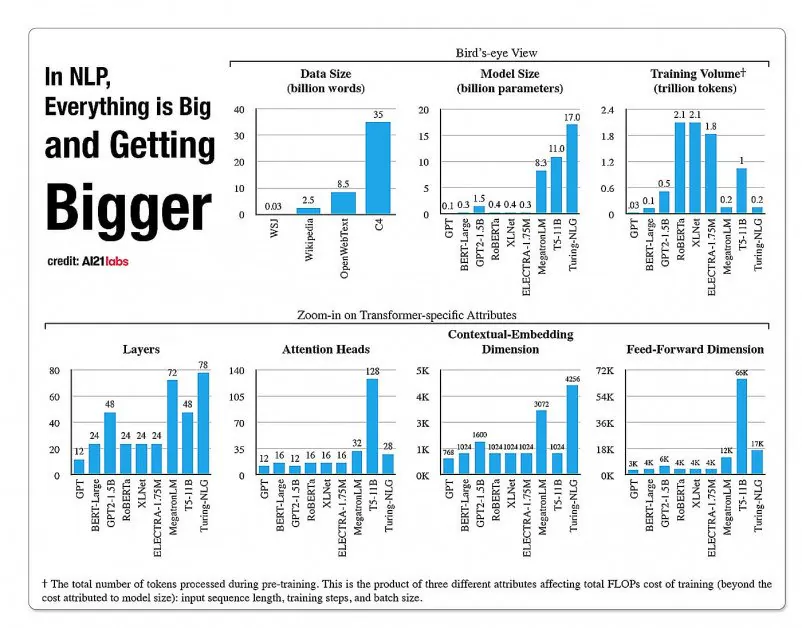
NLP մոդելային ճարտարապետություններում կողմերի աճի վիճակագրություն՝ A2020 Labs-ի 121 թվականի զեկույցից: Աղբյուր՝ https://arxiv.org/pdf/2004.08900.pdf
2019 թվականին գիտաշխատող հաշվարկված որ ուսուցման համար արժե $61,440 ԱՄՆ դոլար XLNet մոդելը (այդ ժամանակ հաղորդվում էր, որ հաղթել է BERT-ին NLP առաջադրանքներում) 2.5 օրվա ընթացքում 512 միջուկների վրա 64 սարքերում, մինչդեռ GPT-3-ը գնահատվում ուսուցման համար ծախսվել է 12 միլիոն դոլար, ինչը 200 անգամ գերազանցում է իր նախորդի՝ GPT-2-ի վերապատրաստման ծախսերը (չնայած վերջին վերահաշվարկները պնդում են, որ այն կարող է վերապատրաստվել հիմա: ընդամենը 4,600,000 դոլար ամենացածր գներով ամպային GPU-ների վրա):
Հարցման կարիքների վրա հիմնված տվյալների ենթաբազմություններ
Փոխարենը, նոր առաջարկվող ճարտարապետությունը ձգտում է ստանալ ճշգրիտ դասակարգումներ, պիտակներ և ընդհանրացում՝ օգտագործելով հարցումը որպես մի տեսակ զտիչ՝ սահմանելու տեղեկատվության ենթաբազմություն մեծ լեզվական տվյալների բազայից, որը կուսուցանվի հարցման հետ միասին՝ պատասխաններ տալու համար: սահմանափակ թեմայով:
Հեղինակները նշում են.
«TLM-ը դրդված է երկու հիմնական գաղափարներով. Նախ, մարդիկ յուրացնում են առաջադրանքը՝ օգտագործելով համաշխարհային գիտելիքի միայն մի փոքր մասը (օրինակ՝ ուսանողներին անհրաժեշտ է ընդամենը մի քանի գլուխ վերանայել՝ աշխարհի բոլոր գրքերից, որպեսզի հավաքեն քննություն):
«Մենք ենթադրում ենք, որ մեծ կորպուսում կա շատ ավելորդություն կոնկրետ առաջադրանքի համար: Երկրորդ, վերահսկվող պիտակավորված տվյալների վերաբերյալ ուսուցումը շատ ավելի արդյունավետ է տվյալների հոսքի կատարման համար, քան չպիտակավորված տվյալների վրա լեզվի մոդելավորման նպատակի օպտիմալացումը: Այս դրդապատճառների հիման վրա TLM-ն օգտագործում է առաջադրանքի տվյալները որպես հարցումներ՝ ընդհանուր կորպուսի մի փոքր ենթաբազմություն ստանալու համար: Դրան հաջորդում է վերահսկվող առաջադրանքի նպատակի և լեզվի մոդելավորման նպատակի համատեղ օպտիմիզացումը՝ օգտագործելով և՛ վերցված տվյալները, և՛ առաջադրանքի տվյալները:'
Բացի բարձր արդյունավետ NLP մոդելի ուսուցումը մատչելի դարձնելուց, հեղինակները տեսնում են առաջադրանքների վրա հիմնված NLP մոդելների օգտագործման մի շարք առավելություններ: Մեկի համար հետազոտողները կարող են վայելել ավելի մեծ ճկունություն՝ հաջորդականության երկարության, նշանաբանության, հիպերպարամետրային թյունինգի և տվյալների ներկայացման հատուկ ռազմավարություններով:
Հետազոտողները նաև կանխատեսում են հիբրիդային ապագա համակարգերի զարգացում, որոնք հակադրում են PLM-ի սահմանափակ նախնական վերապատրաստումը (որն այլ կերպ չի ակնկալվում ներկայիս ներդրման մեջ) ավելի մեծ բազմակողմանիության և վերապատրաստման ժամանակների ընդհանրացման դեմ: Նրանք համակարգը համարում են քայլ առաջ՝ տիրույթի զրոյական ընդհանրացման մեթոդների առաջխաղացման համար:
Փորձարկում եւ արդյունքներ
TLM-ը փորձարկվել է դասակարգման մարտահրավերների վրա ութ առաջադրանքներում չորս տիրույթներում՝ կենսաբժշկական գիտություն, նորություններ, ակնարկներ և համակարգչային գիտություն: Առաջադրանքները բաժանվեցին բարձր ռեսուրսների և ցածր ռեսուրսների կատեգորիաների: Բարձր ռեսուրսների առաջադրանքները ներառում էին ավելի քան 5,000 առաջադրանքների տվյալներ, ինչպիսիք են AGNews և RCT, ուրիշների մեջ; ներառված են ցածր ռեսուրսներով առաջադրանքներ Քիմպրոտ և ACL-ARC, Ինչպես նաեւ HyperPartisan նորությունների հայտնաբերման տվյալների հավաքածու:
Հետազոտողները մշակել են երկու ուսումնական հավաքածու Corpus-BERT և Corpus-RoBERTa վերնագրերով, որոնք տասը անգամ մեծ են առաջինից: Փորձերը համեմատեցին ընդհանուր նախնական պատրաստված լեզվի մոդելները ԲԵՐՏ (Google-ից) և ՌոԲԵՐՏԱ (Ֆեյսբուքից) դեպի նոր ճարտարապետություն։
Թերթը նշում է, որ թեև TLM-ը ընդհանուր մեթոդ է և պետք է լինի ավելի սահմանափակ իր շրջանակով և կիրառելիությամբ, քան ավելի լայն և ավելի մեծ ծավալի ժամանակակից մոդելները, այն ի վիճակի է կատարել տիրույթին հարմարվողական ճշգրտման մեթոդներին մոտ:

TLM-ի արդյունավետությունը BERT-ի և RoBERTa-ի վրա հիմնված հավաքածուների համեմատության արդյունքները: Արդյունքները ցույց են տալիս միջին F1 միավորը երեք տարբեր մարզումների սանդղակով և թվարկում են պարամետրերի քանակը, ընդհանուր ուսուցման հաշվարկը (FLOPs) և մարզման կորպուսի չափը:
Հեղինակները եզրակացնում են, որ TLM-ն ի վիճակի է հասնել արդյունքների, որոնք համեմատելի կամ ավելի լավ են, քան PLM-ները՝ անհրաժեշտ FLOP-ների էական կրճատմամբ և պահանջելով ուսումնական կորպուսի միայն 1/16-րդ մասը: Միջին և մեծ մասշտաբներով TLM-ն, ըստ երևույթին, կարող է բարելավել կատարումը միջինում 0.59 և 0.24 միավորներով՝ միաժամանակ նվազեցնելով վերապատրաստման տվյալների չափը երկու կարգով:
«Այս արդյունքները հաստատում են, որ TLM-ը շատ ճշգրիտ է և շատ ավելի արդյունավետ, քան PLM-ները: Ավելին, TLM-ն ավելի շատ առավելություններ է ստանում արդյունավետության առումով ավելի մեծ մասշտաբով: Սա ցույց է տալիս, որ ավելի լայնածավալ PLM-ները կարող էին վերապատրաստված լինել ավելի ընդհանուր գիտելիքներ պահելու համար, որոնք օգտակար չեն կոնկրետ առաջադրանքի համար:















