
Mesterséges Intelligencia
YOLOv7: A legfejlettebb objektumészlelési algoritmus?

6. július 2022-a mérföldkőnek számít az AI történetében, mert ezen a napon jelent meg a YOLOv7. A YOLOv7 megjelenése óta a Computer Vision fejlesztői közösség legfelkapottabb témája, és ennek megfelelő okokból. A YOLOv7-et máris mérföldkőnek tekintik az objektumészlelési iparágban.
Röviddel a Megjelent a YOLOv7 tanulmány, a leggyorsabb és legpontosabb valós idejű kifogásérzékelő modellnek bizonyult. De hogyan veri felül a YOLOv7 elődeit? Mitől olyan hatékony a YOLOv7 a számítógépes látási feladatok végrehajtásában?
Ebben a cikkben megpróbáljuk elemezni a YOLOv7 modellt, és megpróbáljuk megtalálni a választ arra, hogy a YOLOv7 miért válik most ipari szabványtá? Mielőtt azonban erre választ adnánk, át kell tekintenünk az objektumészlelés rövid történetét.
Mi az objektumészlelés?
Az objektumészlelés a számítógépes látás egyik ága amely azonosítja és megkeresi az objektumokat egy képen vagy egy videofájlban. Az objektumészlelés számos alkalmazás építőköve, beleértve az önvezető autókat, a felügyelt felügyeletet és még a robotikát is.
A tárgyfelismerő modell két kategóriába sorolható: egylövetű detektorok, és a többlövésű detektorok.
Valós idejű objektumészlelés
Ahhoz, hogy valóban megértsük a YOLOv7 működését, elengedhetetlen, hogy megértsük a YOLOv7 fő célját, "Valós idejű objektumészlelés”. A valós idejű objektumészlelés a modern számítógépes látás kulcsfontosságú eleme. A valós idejű objektumészlelési modellek valós időben próbálják azonosítani és megtalálni az érdeklődésre számot tartó objektumokat. A valós idejű objektumészlelési modellek igazán hatékonyvá tették a fejlesztők számára az érdeklődésre számot tartó objektumok nyomon követését mozgó keretben, például videóban vagy élő felügyeleti bemeneten.

A valós idejű objektumészlelési modellek lényegében egy lépéssel előrébb járnak a hagyományos képfelismerő modellekhez képest. Míg az előbbi a videofájlokban lévő objektumok nyomon követésére szolgál, az utóbbi megkeresi és azonosítja az objektumokat egy álló keretben, például egy képen.
Ennek eredményeként a valós idejű objektumészlelési modellek valóban hatékonyak a videóelemzés, az autonóm járművek, az objektumok számlálása, a több objektum követése és még sok más területén.
Mi az a YOLO?
YOLO vagy "Csak egyszer nézel” valós idejű objektumészlelési modellek családja. A YOLO koncepciót először 2016-ban vezette be Joseph Redmon, és szinte azonnal szóba került a város, mert sokkal gyorsabb és sokkal pontosabb volt, mint a meglévő objektumészlelő algoritmusok. Nem sokkal később a YOLO algoritmus szabványossá vált a számítógépes látásiparban.

A YOLO algoritmus által javasolt alapvető koncepció egy végpontok közötti neurális hálózat használata határoló dobozok és osztályvalószínűség segítségével valós idejű előrejelzések készítéséhez. A YOLO abban az értelemben különbözött a korábbi objektumészlelési modelltől, hogy más megközelítést javasolt az objektumészlelés elvégzésére az osztályozók újrafelhasználásával.
A szemléletváltás működött, mivel a YOLO hamarosan iparági szabvánnyá vált, mivel a teljesítménykülönbség maga és más valós idejű objektumészlelési algoritmusok között jelentős volt. De mi volt az oka annak, hogy a YOLO olyan hatékony?
A YOLO-val összehasonlítva az objektumészlelési algoritmusok akkoriban Régiójavaslat-hálózatokat használtak a lehetséges érdeklődésre számot tartó régiók észlelésére. A felismerési folyamatot ezután minden régión külön-külön elvégezték. Ennek eredményeként ezek a modellek gyakran több iterációt hajtottak végre ugyanazon a képen, és ebből adódott a pontosság hiánya és a hosszabb végrehajtási idő. Másrészt a YOLO algoritmus egyetlen teljesen összekapcsolt réteget használ az előrejelzés egyidejű végrehajtásához.
Hogyan működik a YOLO?
Három lépésből áll a YOLO algoritmus működése.
Az objektumészlelés újrakeretezése egyszeri regressziós problémaként
A A YOLO algoritmus az objektumészlelést egyetlen regressziós problémaként próbálja átkeretezni, beleértve a képpontokat is, az osztályvalószínűségekhez és a határolókeret koordinátáihoz. Ezért az algoritmusnak csak egyszer kell megnéznie a képet, hogy megjósolja és megtalálja a képeken lévő célobjektumokat.
Indokolja az imázst globálisan
Továbbá, amikor a YOLO algoritmus előrejelzéseket készít, globálisan indokolja a képet. Ez különbözik a régiójavaslat-alapú és csúszó technikáktól, mivel a YOLO algoritmus a teljes képet látja a képzés és tesztelés során az adatkészleten, és képes kontextuális információkat kódolni az osztályokról és azok megjelenési módjáról.
A YOLO előtt a Fast R-CNN volt az egyik legnépszerűbb objektumészlelési algoritmus, amely nem látta a kép nagyobb kontextusát, mert összetévesztette a kép háttérfoltjait egy objektummal. A Fast R-CNN algoritmushoz képest a YOLO 50%-kal pontosabb ha a háttérhibákról van szó.
Általánosítja az objektumok ábrázolását
Végül a YOLO algoritmus célja az objektumok ábrázolásának általánosítása a képen. Ennek eredményeként, amikor egy YOLO algoritmust futtattak egy természetes képeket tartalmazó adatkészleten, és tesztelték az eredményeket, a YOLO nagy különbséggel felülmúlta a meglévő R-CNN modelleket. Ez azért van így, mert a YOLO nagyon általánosítható, így csekély az esélye annak, hogy összeomlik, ha váratlan bemeneteken vagy új tartományokon alkalmazzák.
YOLOv7: Újdonságok?
Most, hogy alapvető ismereteink vannak a valós idejű objektumészlelési modellekről és a YOLO algoritmusról, ideje megvitatni a YOLOv7 algoritmust.
A képzési folyamat optimalizálása
A YOLOv7 algoritmus nemcsak a modell architektúráját próbálja optimalizálni, hanem a képzési folyamat optimalizálását is célozza. Célja, hogy optimalizálási modulokat és módszereket használjon az objektumészlelés pontosságának javítására, növelve a képzés költségeit, miközben fenntartja az interferencia költségét. Ezeket az optimalizáló modulokat nevezhetjük a betanítható táska ajándékokkal.
Durva-finom ólom irányított címke hozzárendelés
A YOLOv7 algoritmus egy új durva-finom ólom irányított címke hozzárendelést tervez használni a hagyományos helyett. Dinamikus címke hozzárendelés. Ez azért van így, mert a dinamikus címke-hozzárendelésnél a több kimeneti réteggel rendelkező modell betanítása problémákat okoz, amelyek közül a leggyakoribb az, hogy hogyan lehet dinamikus célokat rendelni a különböző ágakhoz és kimeneteikhez.
Modell újraparaméterezés
A modell-újraparametrizálás fontos fogalom az objektumészlelésben, és használata általában bizonyos problémákkal követi a képzés során. A YOLOv7 algoritmus a koncepció használatát tervezi gradiens terjedési útvonalat a modell újraparaméterezési irányelveinek elemzéséhez a hálózat különböző rétegeire alkalmazható.
Extend and Compound Scaling
A YOLOv7 algoritmus bemutatja a kiterjesztett és összetett skálázási módszerek a paraméterek és számítások felhasználása és hatékony felhasználása a valós idejű objektumészleléshez.

YOLOv7 : Kapcsolódó munka
Valós idejű objektumészlelés
A YOLO jelenleg az ipari szabvány, és a valós idejű objektumdetektorok többsége YOLO algoritmusokat és FCOS-t (Fully Convolutional One-Stage Object-Detection) alkalmaz. A legkorszerűbb valós idejű tárgydetektor általában a következő jellemzőkkel rendelkezik
- Erősebb és gyorsabb hálózati architektúra.
- Hatékony funkcióintegrációs módszer.
- Pontos tárgyfelismerési módszer.
- Robusztus veszteségfüggvény.
- Hatékony címke-hozzárendelési módszer.
- Hatékony edzésmódszer.
A YOLOv7 algoritmus nem használ önfelügyelt tanulási és lepárlási módszereket, amelyek gyakran nagy mennyiségű adatot igényelnek. Ezzel szemben a YOLOv7 algoritmus egy betanítható bag-of-freebies módszert használ.
Modell újraparaméterezés
A modell-újraparaméterezési technikákat olyan együttes technikának tekintik, amely több számítási modult egyesít egy interferencia szakaszban. A technika további két csoportra osztható: modell szintű együttes, és a modulszintű együttes.
Most, hogy megkapjuk a végső interferencia-modellt, a modellszintű újraparaméterezési technika két gyakorlatot használ. Az első gyakorlat különböző képzési adatokat használ számos azonos modell betanításához, majd átlagolja a betanított modellek súlyát. Alternatív megoldásként a másik gyakorlat átlagolja a modellek súlyát a különböző iterációk során.
A modulszintű újraparaméterezés a közelmúltban hatalmas népszerűségnek örvend, mivel a képzési szakaszban feloszt egy modult különböző modulágakra, vagy különböző azonos ágakra, majd ezeket a különböző ágakat egy egyenértékű modulba integrálja az interferencia során.
Az újraparaméterezési technikák azonban nem alkalmazhatók mindenféle architektúrára. Ez az oka annak, hogy a A YOLOv7 algoritmus új modell-újraparaméterezési technikákat használ a kapcsolódó stratégiák tervezésére különböző architektúrákhoz alkalmas.
Modell méretezés
A modellméretezés egy meglévő modell fel- vagy leméretezésének folyamata, hogy az illeszkedjen a különböző számítástechnikai eszközökhöz. A modell méretezése általában számos tényezőt használ, például a rétegek számát (mélység), a bemeneti képek mérete (felbontás), jellemző piramisok száma(szakasz), és a csatornák száma (szélesség). Ezek a tényezők döntő szerepet játszanak a hálózati paraméterek, az interferenciasebesség, a számítás és a modell pontosságának kiegyensúlyozott kompromisszumának biztosításában.
Az egyik leggyakrabban használt skálázási módszer az NAS vagy Network Architecture Search amely minden bonyolult szabályok nélkül automatikusan megkeresi a megfelelő skálázási tényezőket a keresőmotorokból. A NAS használatának fő hátránya, hogy költséges megközelítés a megfelelő skálázási tényezők kereséséhez.
Szinte minden modell-újraparaméterezési modell önállóan elemzi az egyedi és egyedi skálázási tényezőket, sőt, függetlenül optimalizálja ezeket a tényezőket. Ez azért van, mert a NAS architektúra nem korrelált skálázási tényezőkkel működik.
Érdemes megjegyezni, hogy az összefűzés alapú modellek pl VoVNet or DenseNet módosítsa néhány réteg bemeneti szélességét a modellek mélységének méretezésekor. A YOLOv7 egy javasolt összefűzés-alapú architektúrán dolgozik, és ezért összetett skálázási módszert használ.

A fent említett ábra összehasonlítja a kiterjesztett hatékony réteg-aggregációs hálózatok (E-ELAN) különböző modellek. A javasolt E-ELAN módszer megtartja az eredeti architektúra gradiens átviteli útvonalát, de célja a hozzáadott tulajdonságok kardinalitása csoportkonvolúció segítségével. A folyamat javíthatja a különböző térképek által tanult jellemzőket, és tovább javíthatja a számítások és paraméterek használatát.
YOLOv7 architektúra
A YOLOv7 modell a YOLOv4, YOLO-R és a Scaled YOLOv4 modelleket használja alapként. A YOLOv7 az ezeken a modelleken végzett kísérletek eredménye az eredmények javítása és a modell pontosabbá tétele érdekében.
Extended Efficient Layer Aggregation Network vagy E-ELAN
Az E-ELAN a YOLOv7 modell alapvető építőköve, és a már meglévő hálózati hatékonysági modellekből származik, elsősorban a LENDÜLET.
A hatékony architektúra tervezésekor a fő szempontok a paraméterek száma, a számítási sűrűség és a számítás mennyisége. Más modellek olyan tényezőket is figyelembe vesznek, mint a bemeneti/kimeneti csatorna arányának hatása, az architektúra hálózat elágazásai, a hálózati interferencia sebessége, a konvolúciós hálózat tenzoraiban lévő elemek száma és még sok más.
A CSPVoNet A modell nem csak a fent említett paramétereket veszi figyelembe, hanem elemzi a gradiens útvonalát is, hogy a különböző rétegek súlyozását lehetővé tévő változatosabb jellemzőket tanulhasson meg. A megközelítés lehetővé teszi, hogy az interferenciák sokkal gyorsabbak és pontosak legyenek. A LENDÜLET Az architektúra célja egy hatékony hálózat tervezése a legrövidebb leghosszabb gradiensút szabályozására, hogy a hálózat hatékonyabb legyen a tanulásban és a konvergációban.
Az ELAN már elérte a stabil állapotot, függetlenül a számítási blokkok halmozási számától és a gradiens útvonal hosszától. A stabil állapot megsemmisülhet, ha a számítási blokkokat korlátlanul halmozzák fel, és a paraméterek kihasználtsága csökken. A a javasolt E-ELAN architektúra meg tudja oldani a problémát, mivel bővítést, keverést és egyesítési kardinalitást használ a hálózat tanulási képességének folyamatos javítása az eredeti gradiens útvonal megtartása mellett.
Továbbá, ha összehasonlítjuk az E-ELAN architektúráját az ELAN-nal, az egyetlen különbség a számítási blokkban van, míg az átmeneti réteg architektúrája változatlan.
Az E-ELAN a számítási blokkok számosságának bővítését, a csatorna bővítését javasolja csoportkonvolúció. A tereptárgytérkép ezután kiszámításra kerül, és a csoportparamétereknek megfelelően csoportokba keveredik, majd összefűződik. A csatornák száma az egyes csoportokban ugyanaz marad, mint az eredeti architektúrában. Végül a tereptérképek csoportjait hozzáadjuk a kardinalitás eléréséhez.
Modellskálázás összefűzés alapú modellekhez
A modell méretezése segít a modellek tulajdonságainak beállítása amely segít a követelményeknek megfelelő és különböző léptékű modellek generálásában, hogy megfeleljenek a különböző interferencia-sebességeknek.

Az ábra a különböző összefűzés alapú modellek modellskálázásáról beszél. Ahogy az (a) és (b) ábrán látható, a számítási blokk kimeneti szélessége növekszik a modellek mélységi skálázásának növekedésével. Ennek eredményeként az átviteli rétegek bemeneti szélessége megnő. Ha ezeket a módszereket összefűzés alapú architektúrán valósítják meg, a skálázási folyamat mélyreható, és ez a (c) ábrán látható.
Ebből az a következtetés vonható le, hogy a skálázási tényezőket nem lehet önállóan elemezni az összefűzés alapú modelleknél, hanem ezeket együtt kell figyelembe venni vagy elemezni. Ezért egy összefűzés alapú modell esetén alkalmas a megfelelő összetett modell skálázási módszer alkalmazása. Ezenkívül a mélységi tényező skálázásakor a blokk kimeneti csatornáját is skálázni kell.
Betanítható táska ingyenes ajándékokkal
A zsák ingyenes ajándék egy olyan kifejezés, amelyet a fejlesztők használnak a leírására olyan módszerek vagy technikák összessége, amelyek megváltoztathatják a képzési stratégiát vagy a költségeket a modell pontosságának növelése érdekében. Tehát mik ezek a betanítható ajándékcsomagok a YOLOv7-ben? Nézzük meg.
Tervezett újraparaméterezett konvolúció
A YOLOv7 algoritmus gradiens áramlási útvonalakat használ a meghatározásához hogyan lehet ideálisan kombinálni egy hálózatot az újraparaméterezett konvolúcióval. A YOLov7 ezzel a megközelítésével ellensúlyozási kísérlet RepConv algoritmus amely bár nyugodtan teljesített a VGG modellen, gyengén teljesít közvetlenül a DenseNet és ResNet modellekre alkalmazva.
A konvolúciós réteg összefüggéseinek azonosításához a A RepConv algoritmus 3×3 és 1×1 konvolúciót kombinál. Ha elemezzük az algoritmust, annak teljesítményét és az architektúrát, azt fogjuk látni, hogy a RepConv tönkreteszi a összefűzés a DenseNetben, és a maradék a ResNetben.

A fenti kép egy tervezett újraparaméterezett modellt ábrázol. Látható, hogy a YOLov7 algoritmus azt találta, hogy a hálózat összefűzött vagy maradék kapcsolatokkal rendelkező rétegének nem szabad identitáskapcsolattal rendelkeznie a RepConv algoritmusban. Ennek eredményeként elfogadható a RepConvN-nel történő váltás identitáskapcsolatok nélkül.
Durva a segédanyaghoz és finom az ólomveszteséghez
Mély felügyelet a számítástechnika olyan ága, amelyet gyakran alkalmaznak a mélyhálózatok képzési folyamatában. A mély felügyelet alapelve az, hogy egy további segédfejet ad a hálózat középső rétegeihez a sekély hálózati súlyokkal együtt, amelynek útmutatója az asszisztens veszteség. A YOLOv7 algoritmus a végső kimenetért felelős fejre utal vezető fejként, a segédfej pedig az edzést segítő fejre.
Tovább haladva a YOLOv7 más módszert használ a címke-hozzárendeléshez. Hagyományosan a címke-hozzárendelést használták a címkék előállítására, közvetlenül az alapigazságra hivatkozva, és egy adott szabályrendszer alapján. Az elmúlt években azonban az előrejelzési bemenet eloszlása és minősége fontos szerepet játszik a megbízható címke létrehozásában. A YOLOv7 lágy címkét hoz létre az objektumról a határoló doboz és az alapigazság előrejelzéseinek felhasználásával.
Ezenkívül a YOLOv7 algoritmus új címke-hozzárendelési módszere a vezetőfej előrejelzéseit használja a vezető és a segédfej irányításához. A címke-hozzárendelési módszernek két javasolt stratégiája van.
Vezető fej által irányított címkekiosztó
A stratégia számításokat végez a vezető fej előrejelzési eredményei és az alapigazság alapján, majd az optimalizálás segítségével lágy címkéket generál. Ezeket a puha címkéket ezután mind a vezetőfej, mind a segédfej képzési modelljeként használják.
A stratégia azon a feltételezésen alapul, hogy mivel a vezető fejnek nagyobb a tanulási képessége, az általa generált címkéknek reprezentatívabbnak kell lenniük, és korrelálniuk kell a forrás és a cél között.
Durva-finom ólomfej irányított címkekiosztó
Ez a stratégia számításokat is végez a vezető fej előrejelzési eredményei és az alapigazság alapján, majd az optimalizálás segítségével lágy címkéket generál. Van azonban egy lényeges különbség. Ebben a stratégiában két puha címkekészlet található, durva szint, és a finom címke.
A durva címkét a pozitív minta kényszereinek lazításával állítják elő
hozzárendelési folyamat, amely több rácsot kezel pozitív célként. Ezt azért teszik, hogy elkerüljék az információvesztést a segédfej gyengébb tanulási ereje miatt.

A fenti ábra a YOLOv7 algoritmusban betanítható ajándékcsomag használatát ismerteti. A segédfejnél durvát, az ólomfejnél finomat ábrázol. Ha összehasonlítunk egy segédfejjel (b) rendelkező modellt a normál modellel (a), akkor azt fogjuk látni, hogy a (b) sémának van segédfeje, míg az (a)-ban nincs.
A (c) ábra a közös független címke-hozzárendelőt mutatja, míg a (d) és (e) ábra a Lead Guided Assigner, illetve a Coarse-toFine Lead Guided Assigner, amelyet a YOLOv7 használ.
Egyéb betanítható táska ajándékokkal
A fent említetteken kívül a YOLOv7 algoritmus további ajándékcsomagokat is használ, bár eredetileg nem ők javasolták. Ők
- Kötegelt normalizálás a Conv-Bn-Activation technológiában: Ezt a stratégiát arra használják, hogy egy konvolúciós réteget közvetlenül a kötegelt normalizálási réteghez kapcsoljanak.
- Implicit tudás YOLOR nyelven: A YOLOv7 egyesíti a stratégiát a Convolutional szolgáltatástérképpel.
- EMA modell: Az EMA-modellt végső referenciamodellként használják a YOLOv7-ben, bár elsődlegesen az átlagos tanári módszerben kell használni.
YOLOv7: Kísérletek
Kísérleti elrendezés
A YOLOv7 algoritmus a Microsoft COCO adatkészlet képzéshez és érvényesítéshez tárgyészlelési modelljüket, és nem mindegyik kísérlet használ előre betanított modellt. A fejlesztők a 2017-es vonatadatkészletet használták a képzéshez, a 2017-es validációs adatkészletet pedig a hiperparaméterek kiválasztásához. Végül a YOLOv7 objektumészlelési eredmények teljesítményét összehasonlítjuk a legkorszerűbb objektumészlelési algoritmusokkal.
A fejlesztők egy alapmodellt készítettek hozzá edge GPU (YOLOv7-tiny), normál GPU (YOLOv7) és felhő GPU (YOLOv7-W6). Ezenkívül a YOLOv7 algoritmus egy alapmodellt is használ a különböző szolgáltatási követelményeknek megfelelő modellskálázáshoz, és különböző modelleket kap. A YOLOv7 algoritmus esetében a verem skálázása a nyakon történik, és a javasolt vegyületeket használják a modell mélységének és szélességének növelésére.
alaptervek
A YOLOv7 algoritmus a korábbi YOLO modelleket és a YOLOR objektumészlelési algoritmust használja kiindulási alapként.

A fenti ábra a YOLOv7 modell alapvonalát hasonlítja össze más objektumészlelési modellekkel, és az eredmények nyilvánvalóak. Ha összehasonlítjuk a A YOLOv4 algoritmus, a YOLOv7 nemcsak 75%-kal kevesebb paramétert használ, hanem 15%-kal kevesebb számítást is, és 0.4%-kal nagyobb a pontossága.
Összehasonlítás a legkorszerűbb tárgyérzékelő modellekkel

A fenti ábra azokat az eredményeket mutatja, amikor a YOLOv7-et összehasonlítjuk a mobil és általános GPU-k legkorszerűbb objektumészlelési modelljeivel. Megfigyelhető, hogy a YOLOv7 algoritmus által javasolt módszer rendelkezik a legjobb sebesség-pontosság kompromisszumos pontszámmal.
Ablációs vizsgálat: Javasolt vegyületskálázási módszer

A fenti ábra összehasonlítja a modell felskálázásához használt különböző stratégiák eredményeit. A YOLOv7 modell skálázási stratégiája 1.5-szeresére növeli a számítási blokk mélységét, és 1.25-szeresére növeli a szélességet.
Egy olyan modellel összehasonlítva, amely csak a mélységet növeli, a YOLOv7 modell 0.5%-kal jobban teljesít, miközben kevesebb paramétert és számítási teljesítményt használ. Másrészt a csak mélységet skálázó modellekkel összehasonlítva a YOLOv7 pontossága 0.2%-kal javult, de a paraméterek számát 2.9%-kal, a számítást pedig 1.2%-kal kell skálázni.
Javasolt tervezett újraparaméterezett modell
A javasolt újraparaméterezett modell általánosságának ellenőrzésére a A YOLOv7 algoritmus maradék alapú és összefűzés alapú modelleken használja az ellenőrzéshez. Az ellenőrzési folyamathoz a YOLOv7 algoritmus használja 3 halmozott ELAN az összefűzés alapú modellhez, a CSPDarknet pedig a maradék alapú modellhez.
Az összefűzés-alapú modellben az algoritmus a 3x3-as konvolúciós rétegeket a 3-halmozott ELAN-ban RepConv-val helyettesíti. Az alábbi ábra a Planned RepConv és a 3 halmozott ELAN részletes konfigurációját mutatja.
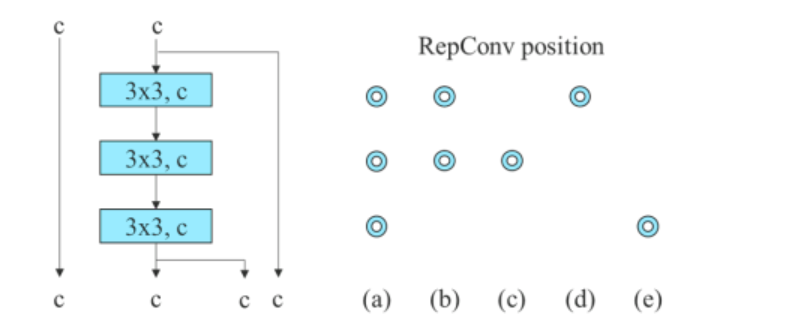
Továbbá, amikor a maradék alapú modellel foglalkozik, a YOLOv7 algoritmus fordított sötét blokkot használ, mivel az eredeti sötét blokk nem tartalmaz 3 × 3 konvolúciós blokkot. Az alábbi ábra a Reversed CSPDarknet architektúráját mutatja, amely felcseréli a 3×3 és az 1×1 konvolúciós réteg helyzetét. 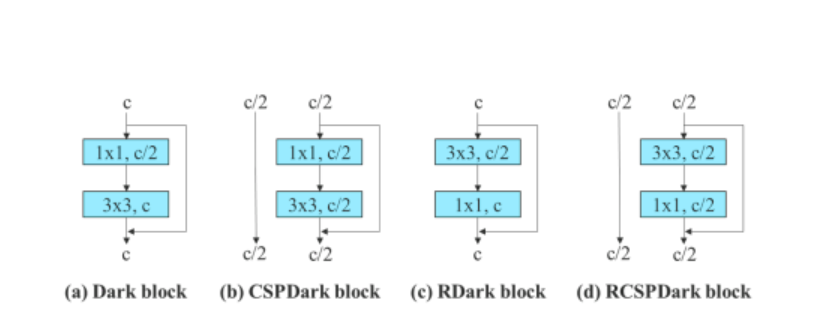
A segédvezető asszisztensének javasolt elvesztése
A segédfejhez tartozó asszisztens veszteséghez a YOLOv7 modell összehasonlítja a segédfej és a vezetőfej módszer független címke-hozzárendelését.

A fenti ábra a javasolt segédfejre vonatkozó vizsgálat eredményeit tartalmazza. Látható, hogy a modell általános teljesítménye növekszik az asszisztensi veszteség növekedésével. Ezenkívül a YOLOv7 modell által javasolt vezetővezérelt címke-hozzárendelés jobban teljesít, mint a független vezető-hozzárendelési stratégiák.
YOLOv7 eredmények
A fenti kísérletek alapján itt van a YOLov7 teljesítményének eredménye más objektumészlelési algoritmusokkal összehasonlítva.

A fenti ábra összehasonlítja a YOLOv7 modellt más objektumfelismerő algoritmusokkal, és egyértelműen megfigyelhető, hogy a YOLOv7 felülmúlja a többi kifogásérzékelő modellt Átlagos pontosságú (AP) v/s kötegelt interferencia.
Ezenkívül az alábbi ábra összehasonlítja a YOLOv7 v/s más valós idejű kifogásérzékelő algoritmusainak teljesítményét. A YOLOv7 ismét sikeres volt a többi modellnél az általános teljesítmény, pontosság és hatékonyság tekintetében.

Íme néhány további megfigyelés a YOLOv7 eredményeiből és teljesítményéből.
- A YOLOv7-Tiny a YOLO család legkisebb modellje, több mint 6 millió paraméterrel. A YOLOv7-Tiny átlagos pontossága 35.2%, és összehasonlítható paraméterekkel felülmúlja a YOLOv4-Tiny modelleket.
- A YOLOv7 modell több mint 37 millió paraméterrel rendelkezik, és felülmúlja a magasabb paraméterekkel rendelkező modelleket, mint például a YOLov4.
- A YOLOv7 modell rendelkezik a legmagasabb mAP és FPS sebességgel az 5-160 FPS tartományban.
Következtetés
A YOLO vagy a You Only Look Once a korszerű tárgyészlelési modell a modern számítógépes látásban. A YOLO algoritmus nagy pontosságáról és hatékonyságáról ismert, és ennek eredményeként széles körben alkalmazható a valós idejű objektumészlelési iparágban. Amióta 2016-ban bemutatták az első YOLO algoritmust, a kísérletek lehetővé tették a fejlesztők számára a modell folyamatos fejlesztését.
A YOLOv7 modell a YOLO család legújabb tagja, és az eddigi legerősebb YOLo algoritmus. Ebben a cikkben a YOLOv7 alapjairól beszéltünk, és megpróbáltuk elmagyarázni, mi teszi a YOLOv7-et olyan hatékonysá.















