
Mesterséges Intelligencia
EfficientViT: Memóriahatékony látástranszformátor a nagy felbontású számítógépes látáshoz

Nagy modellkapacitásuknak köszönhetően a Vision Transformer modellek nagy sikert arattak az utóbbi időben. Teljesítményük ellenére a képátalakítós modelleknek van egy nagy hibájuk: figyelemre méltó számítási képességük magas számítási költségekkel jár, és ez az oka annak, hogy a képátalakítók nem az első választás a valós idejű alkalmazásokhoz. A probléma megoldására fejlesztők egy csoportja elindította az EfficientViT-t, a nagysebességű képátalakítók családját.
Amikor az EfficientViT-en dolgoztak, a fejlesztők megfigyelték, hogy az áramtranszformátor modellek sebességét gyakran korlátozzák a nem hatékony memóriaműveletek, különösen az MHSA vagy a Multi-Head Self Attention hálózat elemenkénti függvényei és tenzor-átalakítása. A nem hatékony memóriaműveletek leküzdésére az EfficientViT fejlesztői egy új építőelemen dolgoztak, szendvics elrendezést használva, azaz az EfficientViT modell egyetlen, memóriához kötött Multi-Head Self Attention hálózatot használ a hatékony FFN rétegek között, amely segít a memória hatékonyságának javításában, és az általános csatorna-kommunikációt is javítja. Ezenkívül a modell azt is felfedezi, hogy a figyelemtérképek gyakran nagy hasonlóságot mutatnak a fejek között, ami számítási redundanciához vezet. A redundancia problémájának megoldására az EfficientViT modell egy lépcsőzetes csoportfigyelő modult mutat be, amely a figyelemfelkeltő fejeket a teljes szolgáltatás különböző részeivel táplálja. A módszer nemcsak a számítási költségek megtakarítását segíti elő, hanem javítja a modell figyelmi diverzitását is.
Az EfficientViT modellel különböző forgatókönyvekben végzett átfogó kísérletek azt mutatják, hogy az EfficientViT felülmúlja a meglévő hatékony modelleket számítógépes látás miközben jó kompromisszumot talál a pontosság és a sebesség között. Vegyünk tehát egy mélyebb merülést, és fedezzük fel az EfficientViT modellt egy kicsit mélyebben.
A Vision Transformers és az EfficientViT bemutatása
A Vision Transformers továbbra is az egyik legnépszerűbb keretrendszer a számítógépes látásiparban, mert kiváló teljesítményt és nagy számítási képességet kínál. A képátalakító modellek pontosságának és teljesítményének folyamatosan javulásával azonban a működési költségek és a számítási többletköltségek is nőnek. Például a jelenlegi modellek, amelyekről ismert, hogy a legmodernebb teljesítményt nyújtják az ImageNet adatkészleteken, mint például a SwinV2 és a V-MoE, 3B, illetve 14.7B paramétereket használnak. Ezeknek a modelleknek a puszta mérete, valamint a számítási költségek és követelmények gyakorlatilag alkalmatlanná teszik őket valós idejű eszközökhöz és alkalmazásokhoz.
Az EfficientNet modell célja, hogy feltárja, hogyan lehet növelni a teljesítményt látástranszformátor modellek, valamint a hatékony és eredményes transzformátor alapú keretarchitektúrák tervezése mögött rejlő elvek megtalálása. Az EfficientViT modell olyan meglévő látástranszformátor keretrendszereken alapul, mint a Swim és a DeiT, és három alapvető tényezőt elemez, amelyek befolyásolják a modellek interferencia sebességét, beleértve a számítási redundanciát, a memória hozzáférést és a paraméterhasználatot. Továbbá a modell megfigyeli, hogy a képátalakító modellek sebessége a memóriához kötött, ami azt jelenti, hogy a CPU-k/GPU-k számítási teljesítményének teljes kihasználását tiltja vagy korlátozza a memóriaelérési késleltetés, ami negatív hatással van a transzformátorok futási sebességére. . Az MHSA vagy a Multi-Head Self Attention hálózat elemenkénti függvényei és tenzor-átalakítása a memória szempontjából leginkább nem hatékony műveletek. A modell azt is megfigyeli, hogy az FFN (feed forward network) és az MHSA közötti arány optimális beállítása jelentősen csökkentheti a memória-elérési időt a teljesítmény befolyásolása nélkül. Mindazonáltal a modell némi redundanciát is megfigyel a figyelemtérképeken, mivel a figyelmi fej hasonló lineáris vetületeket tanul meg.
A modell az EfficientViT kutatási munkája során elért eredmények végső művelése. A modell új feketével rendelkezik, szendvics elrendezéssel, amely egyetlen memóriához kötött MHSA réteget alkalmaz a továbbító hálózat vagy az FFN rétegek között. Ez a megközelítés nemcsak csökkenti a memóriához kötött műveletek végrehajtásához szükséges időt az MHSA-ban, hanem az egész folyamatot is hatékonyabbá teszi a memóriában, mivel több FFN réteget tesz lehetővé a különböző csatornák közötti kommunikáció megkönnyítésére. A modell egy új CGA vagy Cascaded Group Attention modult is alkalmaz, amelynek célja a számítások hatékonyabbá tétele azáltal, hogy csökkenti a számítási redundanciát nem csak a figyelemfejekben, hanem növeli a hálózat mélységét is, ami megnövekedett modellkapacitást eredményez. Végül a modell kibővíti az alapvető hálózati összetevők csatornaszélességét, beleértve az értékkivetítéseket, miközben csökkenti az alacsony értékű hálózati összetevőket, például a rejtett dimenziókat a betápláló hálózatokban, hogy újraeloszthassa a paramétereket a keretrendszerben.

Amint az a fenti képen is látható, az EfficientViT keretrendszer jobban teljesít, mint a jelenlegi legkorszerűbb CNN és ViT modellek mind pontosság, mind sebesség tekintetében. De hogyan sikerült az EfficientViT keretrendszernek felülmúlnia néhány jelenlegi korszerű keretrendszert? Találjuk ki.
EfficientViT: A Vision Transformerek hatékonyságának javítása
Az EfficientViT modell célja a meglévő látótranszformátor modellek hatékonyságának javítása három szempontból,
- Számítási redundancia.
- Memória hozzáférés.
- Paraméterhasználat.
A modell célja annak feltárása, hogy a fenti paraméterek hogyan befolyásolják a látótranszformátor modellek hatékonyságát, és hogyan lehet ezeket megoldani, hogy jobb eredményt, jobb hatásfokkal érjünk el. Beszéljünk róluk egy kicsit mélyebben.
Memória hozzáférés és hatékonyság
A modell sebességét befolyásoló egyik lényeges tényező a memória hozzáférés overhead vagy MAO. Amint az az alábbi képen is látható, a transzformátorban számos operátor, beleértve az elemenkénti összeadást, normalizálást és gyakori újraalakítást, a memória szempontjából nem hatékony műveletek, mivel különböző memóriaegységekhez való hozzáférést igényelnek, ami időigényes folyamat.
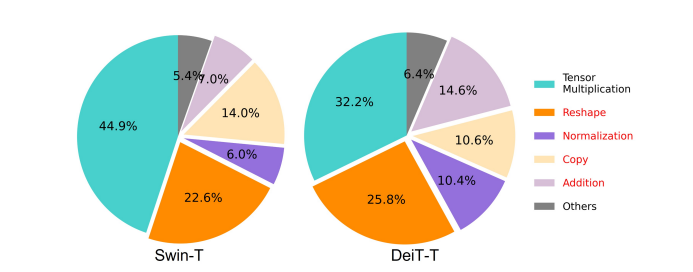
Bár vannak létező módszerek, amelyek leegyszerűsíthetik a standard softmax önfigyelem számításokat, például az alacsony rangú közelítés és a ritka figyelem, ezek gyakran korlátozott gyorsulást kínálnak, és rontják a pontosságot.
Másrészt az EfficientViT keretrendszer célja a memória-elérési költségek csökkentése azáltal, hogy csökkenti a keretrendszerben a nem hatékony memóriarétegek számát. A modell a DeiT-T-t és a Swin-T-t kis alhálózatokká skálázza le, nagyobb, 1.25-szeres és 1.5-szeres interferencia-áteresztő képességgel, és összehasonlítja ezen alhálózatok teljesítményét az MHSA-rétegek arányával. Amint az az alábbi képen látható, a megközelítés végrehajtása esetén körülbelül 20-40%-kal növeli az MHSA rétegek pontosságát.

Számítási hatékonyság
Az MHSA rétegek általában több altérbe vagy fejbe ágyazzák be a bemeneti szekvenciát, és egyenként számítják ki a figyelemleképezéseket, amiről ismert, hogy növeli a teljesítményt. A figyelemtérképek azonban számítási szempontból nem olcsók, és a számítási költségek feltárása érdekében az EfficientViT modell azt vizsgálja, hogyan csökkenthető a redundáns figyelem a kisebb ViT modellekben. A modell méri az egyes fejek maximális koszinusz-hasonlóságát minden blokkon belül a többi fej maximális koszinusz-hasonlóságát a szélességre csökkentett DeiT-T és Swim-T modellek betanításával, 1.25-szörös következtetési sebességgel. Amint az az alábbi képen is látható, nagyszámú hasonlóság van a figyelemfejek között, ami azt sugallja, hogy a modell számítási redundanciát okoz, mivel sok fej hajlamos megtanulni a pontos teljes jellemző hasonló vetületeit.

Annak érdekében, hogy a fejeket különböző minták megtanulására ösztönözze, a modell kifejezetten olyan intuitív megoldást alkalmaz, amelyben minden fej csak a teljes jellemző egy részét táplálja, ez a technika a csoportkonvolúció gondolatához hasonlít. A modell a módosított MHSA rétegeket tartalmazó leskálázott modellek különböző aspektusait tanítja.
Paraméter Hatékonyság
Az átlagos ViT-modellek öröklik a tervezési stratégiájukat, mint például az egyenértékű szélesség alkalmazása a vetítésekhez, a tágulási arány 4-re állítása FFN-ben, és az NLP transzformátorok fokozatai közötti emelés. Ezeknek az alkatrészeknek a konfigurációját gondosan újra kell tervezni a könnyű modulokhoz. Az EfficientViT modell a Taylor strukturált metszést alkalmazza, hogy automatikusan megtalálja a Swim-T és a DeiT-T rétegek alapvető összetevőit, és tovább tárja a mögöttes paraméter-kiosztási elveket. Bizonyos erőforrás-korlátok mellett a metszési módszerek eltávolítják a nem fontos csatornákat, és megtartják a kritikus csatornákat a lehető legnagyobb pontosság érdekében. Az alábbi ábra a csatornák és a bemeneti beágyazások arányát hasonlítja össze a Swin-T keretrendszeren végzett metszés előtt és után. Megfigyelték, hogy: Kiindulási pontosság: 79.1%; metszett pontosság: 76.5%.

A fenti kép azt mutatja, hogy a keretrendszer első két szakasza több, míg az utolsó két szakasz sokkal kevesebb méretet őriz meg. Ez azt jelentheti, hogy egy tipikus csatornakonfiguráció, amely minden szakasz után megduplázza a csatornát, vagy egyenértékű csatornákat használ az összes blokkhoz, jelentős redundanciát eredményezhet az utolsó néhány blokkban.
Hatékony látástranszformátor: építészet
A fenti elemzés során szerzett tanulságok alapján a fejlesztők egy új hierarchikus modell létrehozásán dolgoztak, amely gyors interferencia sebességet kínál, a EfficientViT modell. Nézzük meg részletesen az EfficientViT keretrendszer felépítését. Az alábbi ábra általános képet ad az EfficientViT keretrendszerről.
Az EfficientViT keretrendszer építőkövei
A hatékonyabb képátalakító hálózat építőelemét az alábbi ábra szemlélteti.

A keretrendszer lépcsőzetes csoportfigyelő modulból, memóriahatékony szendvics-elrendezésből és paraméter-újraelosztási stratégiából áll, amelyek a modell számítási, memória- és paraméterezési hatékonyságának javítására összpontosítanak. Beszéljünk róluk részletesebben.
Szendvics elrendezés
A modell egy új szendvics elrendezést használ, hogy hatékonyabb és hatékonyabb memóriablokkot építsen a keretrendszerhez. A szendvics elrendezés kevesebb memóriához kötött önfigyelő réteget használ, és memóriahatékonyabb előrecsatolt hálózatokat használ a csatornakommunikációhoz. Pontosabban, a modell egyetlen önfigyelő réteget alkalmaz a térbeli keveréshez, amely az FFN rétegek közé kerül. A kialakítás nemcsak az önfigyelő rétegek miatti memóriaidő-felhasználás csökkentését segíti elő, hanem az FFN rétegek használatának köszönhetően hatékony kommunikációt tesz lehetővé a hálózaton belül a különböző csatornák között. A modell egy további interakciós token réteget is alkalmaz minden előrecsatolt hálózati réteg előtt DWConv vagy Deceptive Convolution segítségével, és növeli a modell kapacitását a helyi strukturális információk induktív torzításának bevezetésével.
Lépcsőzetes csoportos figyelem
Az MHSA rétegekkel kapcsolatos egyik fő probléma a figyelemfelkeltő fejek redundanciája, amely a számításokat hatástalanabbá teszi. A probléma megoldására a modell a CGA-t vagy a Cascaded Group Attentiont javasolja a látótranszformátorokhoz, egy új figyelemmodult, amely a hatékony CNN-ek csoportkonvolúcióiból merít ihletet. Ebben a megközelítésben a modell az egyes fejeket a teljes jellemzők felosztásával táplálja, és ezért a figyelemszámítást kifejezetten fejek között bontja fel. A funkciók felosztása ahelyett, hogy a teljes funkciókat mindegyik fejbe táplálná, megtakarítja a számítást, és hatékonyabbá teszi a folyamatot, és a modell továbbra is azon dolgozik, hogy még tovább javítsa a pontosságot és kapacitását azáltal, hogy arra ösztönzi a rétegeket, hogy megtanulják a gazdagabb információval rendelkező jellemzők vetületeit.

Paraméter átcsoportosítás
A paraméterek hatékonyságának javítása érdekében a modell átcsoportosítja a paramétereket a hálózatban a kritikus modulok csatornaszélességének bővítésével, míg a nem túl fontos modulok csatornaszélességének csökkentésével. A Taylor-analízis alapján a modell vagy kis csatornaméreteket állít be a vetületekhez minden szakaszban minden fejben, vagy a modell lehetővé teszi, hogy a vetületek mérete megegyezzen a bemenettel. Az előrecsatolt hálózat bővítési arányát szintén 2-re csökkentik 4-ről, hogy segítsék a paraméter-redundanciát. A javasolt újraelosztási stratégia, amelyet az EfficientViT keretrendszer valósít meg, több csatornát oszt ki a fontos moduloknak, hogy lehetővé tegye számukra, hogy jobban megtanulják a reprezentációkat egy nagy dimenziós térben, ami minimálisra csökkenti a funkció információinak elvesztését. Továbbá az interferencia folyamat felgyorsítása és a modell hatékonyságának további növelése érdekében a modell automatikusan eltávolítja a redundáns paramétereket a nem fontos modulokból.

Az EfficientViT keretrendszer áttekintése a fenti képen magyarázható, ahol a részek,
- Az EfficientViT felépítése,
- Szendvics elrendezésű blokk,
- Lépcsőzetes csoportos figyelem.
EfficientViT: Hálózati architektúrák

A fenti kép az EfficientViT keretrendszer hálózati architektúráját foglalja össze. A modell bevezet egy átfedő patch beágyazást [20,80], amely 16 × 16 foltot ágyaz be C1 dimenziós tokenekbe, ami javítja a modell azon képességét, hogy jobban teljesítsen az alacsony szintű vizuális reprezentáció tanulásában. A modell architektúrája három szakaszból áll, ahol mindegyik szakasz egymásra rakja az EfficientViT keretrendszer javasolt építőelemeit, és az egyes részmintavételi rétegeken lévő tokenek száma (a felbontás 2-szeres almintavételezése) 4X-re csökken. Az almintavételezés hatékonyabbá tétele érdekében a modell egy részminta blokkot javasol, amely szintén rendelkezik a javasolt szendvics elrendezéssel, azzal az eltéréssel, hogy egy fordított maradék blokk helyettesíti a figyelemréteget, hogy csökkentse az információvesztést a mintavétel során. Ezenkívül a hagyományos LayerNorm(LN) helyett a modell a BatchNorm(BN)-t használja, mivel a BN összehajtható az előző lineáris vagy konvolúciós rétegekbe, ami futásidejű előnyt biztosít az LN-hez képest.
EfficientViT modellcsalád
Az EfficientViT modellcsalád 6 modellből áll, különböző mélységi és szélességi skálákkal, és minden szakaszhoz meghatározott számú fej van hozzárendelve. A modellek a kezdeti szakaszban kevesebb blokkot használnak, mint a végső szakaszban, ami hasonló a MobileNetV3 keretrendszerhez, mivel a korai szakaszban történő feldolgozás folyamata nagyobb felbontással időigényes. A szélességet fokozatosan növelik egy kis tényezővel a redundancia csökkentése érdekében a későbbi szakaszokban. Az alábbi táblázat az EfficientViT modellcsalád építészeti részleteit tartalmazza, ahol C, L és H a szélességet, mélységet és a fejek számát jelenti az adott szakaszban.

EfficientViT: A modell megvalósítása és eredményei
Az EfficientViT modell teljes kötegmérete 2,048, Timm & PyTorch segítségével épül fel, 300 korszakon keresztül, 8 Nvidia V100 GPU-val, koszinusz tanulási sebesség ütemezőt, AdamW optimalizálót használ, és képosztályozási kísérletét az ImageNeten végzi. -1K. A bemeneti képeket véletlenszerűen levágják és 224 × 224-es felbontásra méretezik át. A downstream képosztályozást magában foglaló kísérletekhez az EfficientViT keretrendszer 300 korszakra finomítja a modellt, és AdamW optimalizálót használ 256-os kötegmérettel. A modell a RetineNet-et használja a COCO objektum-észlelésére, és folytatja a modellek betanítását további 12 időszakra. korszakok azonos beállításokkal.
Eredmények az ImageNeten
Az EfficientViT teljesítményének elemzéséhez összehasonlítják az ImageNet adatkészlet jelenlegi ViT és CNN modelljeivel. Az összehasonlítás eredményeit a következő ábra mutatja be. Mint látható, az EfficientViT modellcsalád a legtöbb esetben felülmúlja a jelenlegi keretrendszert, és ideális kompromisszumot tud elérni a sebesség és a pontosság között.

Összehasonlítás a hatékony CNN-ekkel és az Efficient ViT-ekkel
A modell először összehasonlítja teljesítményét az Efficient CNN-ekkel, mint például az EfficientNet és a vanilla CNN-keretrendszerekkel, mint például a MobileNets. Látható, hogy a MobileNet keretrendszerekkel összehasonlítva az EfficientViT modellek jobb top-1 pontossági pontszámot érnek el, miközben Intel CPU-n 3.0-szer, illetve 2.5-szer gyorsabban futnak, illetve V100 GPU-n.
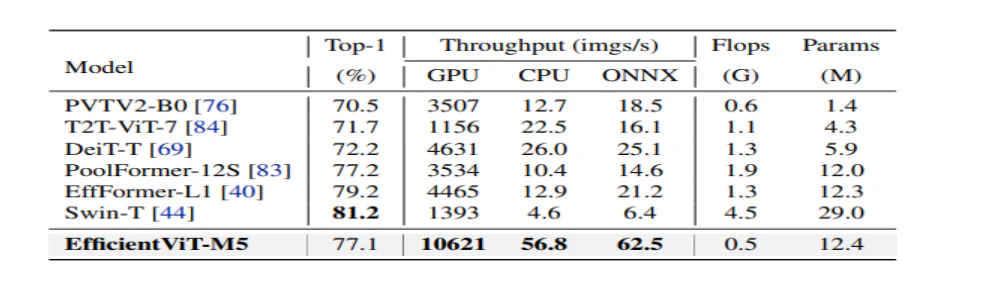
A fenti ábra az EfficientViT modell teljesítményét hasonlítja össze az ImageNet-1K adatkészleten futó, korszerű nagyméretű ViT modellekkel.
Downstream képosztályozás
Az EfficientViT modellt különféle downstream feladatokon alkalmazzák a modell transzfer tanulási képességeinek tanulmányozására, az alábbi képen pedig összefoglaljuk a kísérlet eredményeit. Amint látható, az EfficientViT-M5 modell jobb vagy hasonló eredményeket tud elérni az összes adatkészletben, miközben sokkal nagyobb átviteli sebességet tart fenn. Az egyetlen kivétel az autók adatkészlete, ahol az EfficientViT modell nem teljesíti a pontosságot.

Objektumfelismerés
Az EfficientViT objektumészlelési képességének elemzéséhez összehasonlítják a COCO objektumészlelési feladat hatékony modelljeivel, és az alábbi kép összefoglalja az összehasonlítás eredményeit.

Záró gondolatok
Ebben a cikkben beszéltünk az EfficientViT-ről, a gyorslátó transzformátor modellek családjáról, amelyek lépcsőzetes csoportfigyelést használnak, és memóriahatékony műveleteket biztosítanak. Az EfficientViT teljesítményének elemzésére lefolytatott kiterjedt kísérletek ígéretes eredményeket mutattak, mivel az EfficientViT modell a legtöbb esetben felülmúlja a jelenlegi CNN és vision transzformátor modelleket. Igyekeztünk elemezni azokat a tényezőket is, amelyek szerepet játszanak a látótranszformátorok interferencia-sebességének befolyásolásában.















