
Artificial Intelligence
एकल प्रश्न के लिए GPT-शैली भाषा मॉडल बनाना

चीन के शोधकर्ताओं ने उच्च मात्रा डेटासेट के प्रशिक्षण में शामिल समय और धन के बढ़ते निषेधात्मक खर्च से बचते हुए GPT-3-शैली प्राकृतिक भाषा प्रसंस्करण प्रणाली बनाने के लिए एक किफायती तरीका विकसित किया है - एक बढ़ती प्रवृत्ति जो अन्यथा अंततः एआई के इस क्षेत्र को कमजोर करने की धमकी देती है। FAANG खिलाड़ियों और उच्च-स्तरीय निवेशकों के लिए।
प्रस्तावित रूपरेखा को कहा जाता है कार्य-संचालित भाषा मॉडलिंग (टीएलएम)। अरबों शब्दों और हजारों लेबल और कक्षाओं के विशाल संग्रह पर एक विशाल और जटिल मॉडल को प्रशिक्षित करने के बजाय, टीएलएम एक बहुत छोटे मॉडल को प्रशिक्षित करता है जो वास्तव में सीधे मॉडल के अंदर एक क्वेरी को शामिल करता है।

वाम, उच्च मात्रा भाषा मॉडल के लिए एक विशिष्ट हाइपरस्केल दृष्टिकोण; ठीक है, प्रति-विषय या प्रति-प्रश्न के आधार पर एक बड़े भाषा कोष का पता लगाने के लिए टीएलएम की स्लिमलाइन विधि। स्रोत: https://arxiv.org/pdf/2111.04130.pdf
प्रभावी रूप से, एक विशाल और बोझिल सामान्य भाषा मॉडल बनाने के बजाय, जो विभिन्न प्रकार के प्रश्नों का उत्तर दे सकता है, एक एकल प्रश्न का उत्तर देने के लिए एक अद्वितीय एनएलपी एल्गोरिदम या मॉडल तैयार किया जाता है।
टीएलएम के परीक्षण में, शोधकर्ताओं ने पाया कि नया दृष्टिकोण ऐसे परिणाम प्राप्त करता है जो पूर्व-प्रशिक्षित भाषा मॉडल जैसे समान या बेहतर हैं रोबर्टा-बड़ा, और हाइपरस्केल एनएलपी सिस्टम जैसे ओपनएआई का जीपीटी-3, गूगल का ट्रिलियन पैरामीटर स्विच ट्रांसफार्मर आदर्श, कोरिया हाइपरक्लोवर, AI21 लैब्स' जुरासिक 1, और माइक्रोसॉफ्ट का मेगेट्रॉन-ट्यूरिंग एनएलजी 530बी.
चार डोमेन में आठ वर्गीकरण डेटासेट पर टीएलएम के परीक्षणों में, लेखकों ने अतिरिक्त रूप से पाया कि सिस्टम प्रशिक्षण एफएलओपी को कम कर देता है (प्रति सेकंड फ्लोटिंग पॉइंट ऑपरेशन) परिमाण के दो आदेशों द्वारा आवश्यक। शोधकर्ताओं को उम्मीद है कि टीएलएम एक ऐसे क्षेत्र को 'लोकतांत्रिक' बना सकता है जो तेजी से विशिष्ट होता जा रहा है, एनएलपी मॉडल इतने बड़े हैं कि उन्हें वास्तविक रूप से स्थानीय स्तर पर स्थापित नहीं किया जा सकता है, और इसके बजाय, जीपीटी -3 के मामले में, पीछे बैठे हैं महंगा और OpenAI के सीमित-पहुँच वाले API और, अब, Microsoft Azure.
लेखकों का कहना है कि प्रशिक्षण समय में दो परिमाण की कटौती करने से एक दिन के लिए 1,000 जीपीयू से अधिक की प्रशिक्षण लागत कम होकर 8 घंटों में केवल 48 जीपीयू रह जाती है।
नई रिपोर्ट शीर्षक है बड़े पैमाने पर पूर्व प्रशिक्षण के बिना स्क्रैच से एनएलपी: एक सरल और कुशल ढांचा, और बीजिंग में सिंघुआ विश्वविद्यालय के तीन शोधकर्ताओं और चीन स्थित एआई विकास कंपनी रिकरंट एआई, इंक. के एक शोधकर्ता से आता है।
अप्राप्य उत्तर
RSI लागत प्रशिक्षण के प्रभावी, सर्व-उद्देश्यीय भाषा मॉडल को तेजी से एक संभावित 'थर्मल सीमा' के रूप में जाना जा रहा है, जिस हद तक प्रदर्शनकारी और सटीक एनएलपी वास्तव में संस्कृति में फैल सकता है।
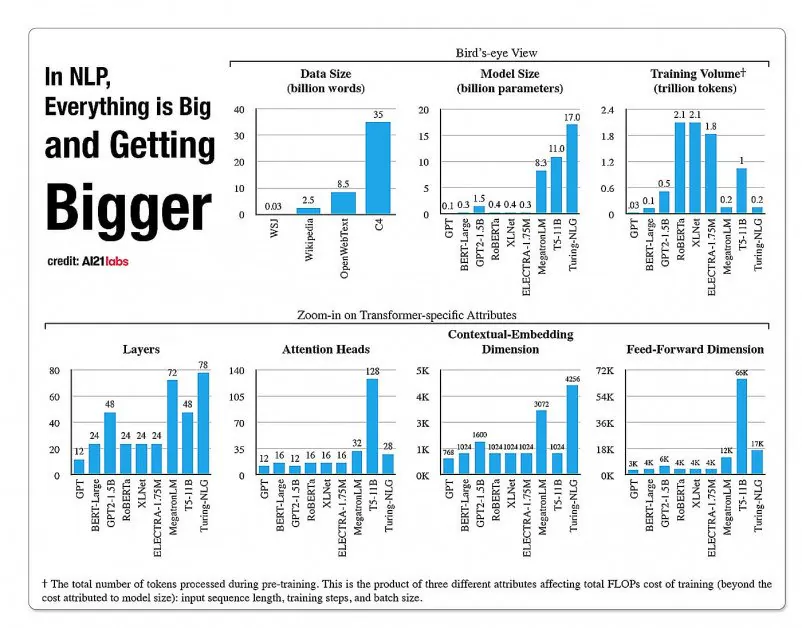
ए2020 लैब्स की 121 रिपोर्ट से एनएलपी मॉडल आर्किटेक्चर में पहलुओं की वृद्धि पर आंकड़े। स्रोत: https://arxiv.org/pdf/2004.08900.pdf
2019 में एक शोधकर्ता परिकलित इसे प्रशिक्षित करने में $61,440 USD का खर्च आता है एक्सएलनेट मॉडल (एनएलपी कार्यों में बीईआरटी को हराने के लिए उस समय रिपोर्ट की गई) 2.5 उपकरणों में 512 कोर पर 64 दिनों में, जबकि जीपीटी-3 है अनुमानित प्रशिक्षित करने में 12 मिलियन डॉलर की लागत आई - अपने पूर्ववर्ती जीपीटी-200 को प्रशिक्षित करने की लागत से 2 गुना (हालांकि हाल के पुन: अनुमानों का दावा है कि इसे अब प्रशिक्षित किया जा सकता है) मात्र $4,600,000 सबसे कम कीमत वाले क्लाउड जीपीयू पर)।
क्वेरी आवश्यकताओं के आधार पर डेटा के सबसेट
इसके बजाय, नया प्रस्तावित आर्किटेक्चर एक बड़े भाषा डेटाबेस से जानकारी के सबसेट को परिभाषित करने के लिए एक प्रकार के फ़िल्टर के रूप में क्वेरी का उपयोग करके सटीक वर्गीकरण, लेबल और सामान्यीकरण प्राप्त करना चाहता है, जिसे उत्तर प्रदान करने के लिए क्वेरी के साथ प्रशिक्षित किया जाएगा। एक सीमित विषय पर.
लेखक कहते हैं:
'टीएलएम दो प्रमुख विचारों से प्रेरित है। सबसे पहले, मनुष्य विश्व ज्ञान के केवल एक छोटे से हिस्से का उपयोग करके किसी कार्य में महारत हासिल करता है (उदाहरण के लिए, छात्रों को परीक्षा के लिए रटने के लिए, दुनिया की सभी पुस्तकों में से केवल कुछ अध्यायों की समीक्षा करने की आवश्यकता होती है)।
'हमारा अनुमान है कि किसी विशिष्ट कार्य के लिए बड़े कोष में बहुत अधिक अतिरेक है। दूसरा, बिना लेबल वाले डेटा पर भाषा मॉडलिंग उद्देश्य को अनुकूलित करने की तुलना में पर्यवेक्षित लेबल डेटा पर प्रशिक्षण डाउनस्ट्रीम प्रदर्शन के लिए अधिक डेटा कुशल है। इन प्रेरणाओं के आधार पर, टीएलएम सामान्य कोष के एक छोटे उपसमूह को पुनः प्राप्त करने के लिए कार्य डेटा को प्रश्नों के रूप में उपयोग करता है। इसके बाद पुनर्प्राप्त डेटा और कार्य डेटा दोनों का उपयोग करके पर्यवेक्षित कार्य उद्देश्य और भाषा मॉडलिंग उद्देश्य को संयुक्त रूप से अनुकूलित किया जाता है।'
अत्यधिक प्रभावी एनएलपी मॉडल प्रशिक्षण को किफायती बनाने के अलावा, लेखक कार्य-संचालित एनएलपी मॉडल का उपयोग करने में कई फायदे देखते हैं। एक के लिए, शोधकर्ता अनुक्रम लंबाई, टोकननाइजेशन, हाइपरपैरामीटर ट्यूनिंग और डेटा प्रतिनिधित्व के लिए कस्टम रणनीतियों के साथ अधिक लचीलेपन का आनंद ले सकते हैं।
शोधकर्ता हाइब्रिड भविष्य प्रणालियों के विकास की भी आशा करते हैं जो प्रशिक्षण समय के मुकाबले अधिक बहुमुखी प्रतिभा और सामान्यीकरण के मुकाबले पीएलएम के सीमित पूर्व-प्रशिक्षण (जो अन्यथा वर्तमान कार्यान्वयन में अपेक्षित नहीं है) का व्यापार करते हैं। वे सिस्टम को इन-डोमेन शून्य-शॉट सामान्यीकरण विधियों की प्रगति के लिए एक कदम आगे मानते हैं।
परीक्षण और परिणाम
टीएलएम का परीक्षण चार डोमेन - बायोमेडिकल विज्ञान, समाचार, समीक्षा और कंप्यूटर विज्ञान में आठ कार्यों में वर्गीकरण चुनौतियों पर किया गया था। कार्यों को उच्च-संसाधन और निम्न-संसाधन श्रेणियों में विभाजित किया गया था। उच्च संसाधन कार्यों में 5,000 से अधिक कार्य डेटा शामिल हैं, जैसे एजीन्यूज़ और RCT, दूसरों के बीच में; कम संसाधन वाले कार्य शामिल हैं केमप्रोट और एसीएल-एआरसी, साथ ही अतिपक्षपातपूर्ण समाचार पहचान डेटासेट.
शोधकर्ताओं ने कॉर्पस-बीईआरटी और कॉर्पस-रॉबर्टा नामक दो प्रशिक्षण सेट विकसित किए, जो बाद वाले का आकार पहले से दस गुना अधिक है। प्रयोगों में सामान्य पूर्व-प्रशिक्षित भाषा मॉडल की तुलना की गई बर्ट (गूगल से) और रॉबर्टा (फेसबुक से) नई वास्तुकला के लिए।
पेपर का मानना है कि यद्यपि टीएलएम एक सामान्य विधि है, और व्यापक और उच्च-मात्रा वाले अत्याधुनिक मॉडल की तुलना में इसका दायरा और प्रयोज्यता अधिक सीमित होनी चाहिए, यह डोमेन-अनुकूली फाइन-ट्यूनिंग विधियों के करीब प्रदर्शन करने में सक्षम है।

BERT और रोबर्टा-आधारित सेटों के विरुद्ध TLM के प्रदर्शन की तुलना करने के परिणाम। परिणाम तीन अलग-अलग प्रशिक्षण पैमानों पर औसत एफ1 स्कोर सूचीबद्ध करते हैं, और मापदंडों की संख्या, कुल प्रशिक्षण गणना (एफएलओपी) और प्रशिक्षण कोष के आकार को सूचीबद्ध करते हैं।
लेखकों का निष्कर्ष है कि टीएलएम ऐसे परिणाम प्राप्त करने में सक्षम है जो पीएलएम से तुलनीय या बेहतर हैं, आवश्यक एफएलओपी में पर्याप्त कमी के साथ, और प्रशिक्षण कोष के केवल 1/16वें हिस्से की आवश्यकता होती है। मध्यम और बड़े पैमाने पर, टीएलएम स्पष्ट रूप से औसतन 0.59 और 0.24 अंक तक प्रदर्शन में सुधार कर सकता है, जबकि प्रशिक्षण डेटा आकार को परिमाण के दो आदेशों तक कम कर सकता है।
'ये परिणाम पुष्टि करते हैं कि टीएलएम अत्यधिक सटीक है और पीएलएम की तुलना में कहीं अधिक कुशल है। इसके अलावा, टीएलएम को बड़े पैमाने पर दक्षता में अधिक लाभ मिलता है। यह इंगित करता है कि बड़े पैमाने के पीएलएम को अधिक सामान्य ज्ञान संग्रहीत करने के लिए प्रशिक्षित किया गया होगा जो किसी विशिष्ट कार्य के लिए उपयोगी नहीं है।'















