Leaders d’opinion
Trois techniques d’apprentissage automatique préservant la confidentialité pour résoudre le problème le plus important de cette décennie
Par Amogh Tarcar, chercheur en apprentissage automatique et en intelligence artificielle, Persistent Systems.
La confidentialité des données, selon les experts de divers domaines, sera le problème le plus important de cette décennie. C’est particulièrement vrai pour l’apprentissage automatique (ML) où les algorithmes sont alimentés par des quantités massives de données.
Traditionnellement, les techniques de modélisation ML ont reposé sur la centralisation des données provenant de multiples sources dans un seul centre de données. Après tout, les modèles ML sont les plus puissants lorsqu’ils ont accès à d’énormes quantités de données. Cependant, il existe un certain nombre de défis de confidentialité qui accompagnent cette technique. L’agrégation de données diverses provenant de multiples sources est moins réalisable aujourd’hui en raison de préoccupations réglementaires telles que le HIPAA, le RGPD et le CCPA. De plus, la centralisation des données augmente la portée et l’ampleur des abus de données et des menaces de sécurité sous forme de fuites de données.
Pour surmonter ces défis, plusieurs piliers de l’apprentissage automatique préservant la confidentialité (PPML) ont été développés avec des techniques spécifiques qui réduisent les risques de confidentialité et garantissent que les données restent raisonnablement sécurisées. Voici quelques-unes des plus importantes :
1. Apprentissage fédéré
L’apprentissage fédéré est une technique d’entraînement ML qui inverse le problème d’agrégation des données. Au lieu d’agréger des données pour créer un seul modèle ML, l’apprentissage fédéré agrège les modèles ML eux-mêmes. Cela garantit que les données ne quittent jamais leur emplacement source et permet à plusieurs parties de collaborer et de construire un modèle ML commun sans partager directement des données sensibles.
Voici comment cela fonctionne. Vous commencez avec un modèle ML de base qui est ensuite partagé avec chaque nœud client. Ces nœuds exécutent ensuite une formation locale sur ce modèle en utilisant leurs propres données. Les mises à jour du modèle sont périodiquement partagées avec le nœud coordinateur, qui traite ces mises à jour et les fusionne pour obtenir un nouveau modèle global. De cette façon, vous obtenez les informations à partir de jeux de données diversifiés sans avoir à partager ces jeux de données.

Source: Persistent Systems
Dans le contexte des soins de santé, c’est un outil incroyablement puissant et respectueux de la confidentialité pour maintenir les données des patients en sécurité tout en donnant aux chercheurs la sagesse de la foule. En ne réunissant pas les données, l’apprentissage fédéré crée une couche de sécurité supplémentaire. Cependant, les modèles et les mises à jour des modèles présentent toujours un risque de sécurité s’ils sont laissés vulnérables.
2. Confidentialité différentielle
Les modèles ML sont souvent la cible d’attaques d’inférence de membership. Supposons que vous partagiez vos données de santé avec un hôpital pour aider à développer un vaccin contre le cancer. L’hôpital maintient vos données en sécurité, mais utilise l’apprentissage fédéré pour former un modèle ML accessible au public. Quelques mois plus tard, des hackers utilisent une attaque d’inférence de membership pour déterminer si vos données ont été utilisées pour former le modèle ou non. Ils transmettent ensuite des informations à une société d’assurance, qui, sur la base de votre risque de cancer, pourrait augmenter vos primes.
La confidentialité différentielle garantit que les attaques adverses contre les modèles ML ne pourront pas identifier les points de données spécifiques utilisés lors de la formation, atténuant ainsi le risque d’exposition de données sensibles de formation dans l’apprentissage automatique. Cela est réalisé en appliquant un « bruit statistique » pour perturber les données ou les paramètres du modèle ML lors de la formation, rendant difficile l’exécution d’attaques et la détermination de l’utilisation de données spécifiques d’un individu pour former le modèle.
Par exemple, Facebook a récemment publié Opacus, une bibliothèque à haute vitesse pour former des modèles PyTorch en utilisant un algorithme d’apprentissage automatique à confidentialité différentielle appelé Differentially Private Stochastic Gradient Descent (DP-SGD). Le gif ci-dessous met en évidence comment il utilise le bruit pour masquer les données.

Source: Blog Opacus de Facebook
Ce bruit est régi par un paramètre appelé Epsilon. Si la valeur Epsilon est faible, le modèle a une confidentialité des données parfaite mais une utilité et une précision faibles. Inversement, si vous avez une valeur Epsilon élevée, la confidentialité des données diminuera tandis que la précision augmentera. Le truc consiste à trouver un équilibre pour optimiser les deux.
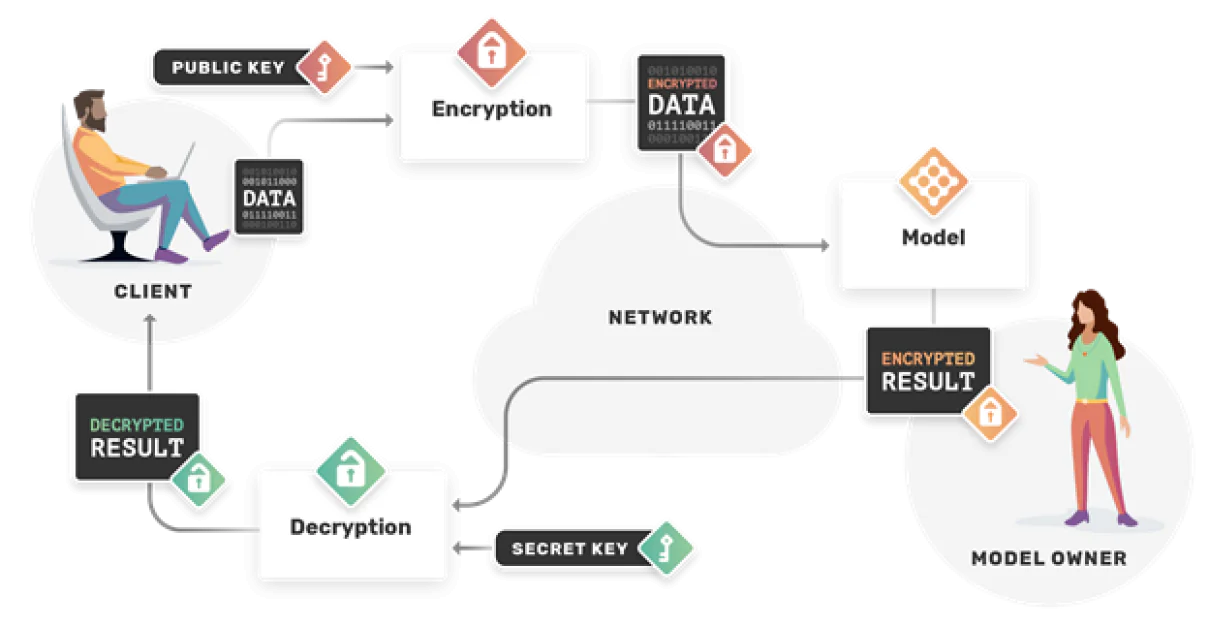
3. Chiffrement homomorphique
Le chiffrement standard est traditionnellement incompatible avec l’apprentissage automatique car, une fois les données chiffrées, elles ne peuvent plus être comprises par l’algorithme ML. Cependant, le chiffrement homomorphique est un schéma de chiffrement spécial qui nous permet de continuer à effectuer certains types de calculs.

Source: OpenMined
Le pouvoir de ceci est que la formation peut avoir lieu dans un espace entièrement chiffré. Il protège non seulement les propriétaires de données, mais également les propriétaires de modèles. Le propriétaire du modèle peut exécuter une inférence sur des données chiffrées sans jamais les voir ou les utiliser de manière abusive.
Lorsqu’il est appliqué à l’apprentissage fédéré, la fusion des mises à jour des modèles peut se produire de manière sécurisée car elles ont lieu dans un environnement entièrement chiffré, réduisant considérablement le risque d’attaques d’inférence de membership.
La décennie de la confidentialité
Alors que nous entrons dans 2021, l’apprentissage automatique préservant la confidentialité est un domaine émergent avec une recherche remarquablement active. Si la dernière décennie était consacrée à la désilotage des données, cette décennie sera consacrée à la désilotage des modèles ML tout en préservant la confidentialité des données sous-jacentes via l’apprentissage fédéré, la confidentialité différentielle et le chiffrement homomorphique. Ces présentent une nouvelle voie prometteuse pour faire progresser les solutions d’apprentissage automatique de manière respectueuse de la confidentialité.












