Intelligence Artificielle
MagicDance : génération de vidéos de danse humaine réalistes

La vision par ordinateur est l’un des domaines les plus discutés dans l’industrie de l’IA, grâce à ses applications potentielles dans un large éventail de tâches en temps réel. Ces dernières années, les cadres de vision par ordinateur ont progressé rapidement, avec des modèles modernes désormais capables d'analyser les traits du visage, les objets et bien plus encore dans des scénarios en temps réel. Malgré ces capacités, le transfert du mouvement humain reste un formidable défi pour les modèles de vision par ordinateur. Cette tâche consiste à recibler les mouvements du visage et du corps d'une image ou d'une vidéo source vers une image ou une vidéo cible. Le transfert de mouvement humain est largement utilisé dans les modèles de vision par ordinateur pour styliser des images ou des vidéos, éditer du contenu multimédia, faire la synthèse humaine numérique et même générer des données pour des cadres basés sur la perception.
Dans cet article, nous nous concentrons sur MagicDance, un modèle basé sur la diffusion conçu pour révolutionner le transfert de mouvement humain. Le framework MagicDance vise spécifiquement à transférer des expressions faciales et des mouvements humains en 2D sur des vidéos de danse humaine stimulantes. Son objectif est de générer de nouvelles vidéos de danse basées sur des séquences de poses pour des identités cibles spécifiques tout en conservant l'identité d'origine. Le cadre MagicDance utilise une stratégie de formation en deux étapes, axée sur le démêlage des mouvements humains et les facteurs d'apparence tels que le teint, les expressions faciales et les vêtements. Nous approfondirons le framework MagicDance, en explorant son architecture, ses fonctionnalités et ses performances par rapport à d'autres frameworks de transfert de mouvement humain de pointe. Allons-y.
MagicDance : transfert réaliste du mouvement humain
Comme mentionné précédemment, le transfert de mouvements humains est l'une des tâches de vision par ordinateur les plus complexes en raison de la complexité impliquée dans le transfert de mouvements et d'expressions humaines de l'image ou de la vidéo source vers l'image ou la vidéo cible. Traditionnellement, les cadres de vision par ordinateur ont réalisé le transfert de mouvement humain en entraînant un modèle génératif spécifique à une tâche, notamment GAN ou Réseaux d'adversaires génératifs sur des ensembles de données cibles pour les expressions faciales et les poses corporelles. Bien que la formation et l’utilisation de modèles génératifs donnent des résultats satisfaisants dans certains cas, elles souffrent généralement de deux limites majeures.
- Ils s'appuient fortement sur un composant de déformation de l'image, ce qui leur fait souvent du mal à interpoler des parties du corps invisibles dans l'image source, soit en raison d'un changement de perspective, soit d'une auto-occlusion.
- Ils ne peuvent pas généraliser à d’autres images provenant de sources externes, ce qui limite leurs applications, notamment dans des scénarios en temps réel dans la nature.

Les modèles de diffusion modernes ont démontré des capacités exceptionnelles de génération d'images dans différentes conditions, et les modèles de diffusion sont désormais capables de présenter des visuels puissants sur un éventail de tâches en aval telles que la génération vidéo et l'inpainting d'images en apprenant à partir d'ensembles de données d'images à l'échelle du Web. En raison de leurs capacités, les modèles de diffusion pourraient constituer un choix idéal pour les tâches de transfert de mouvements humains. Bien que des modèles de diffusion puissent être mis en œuvre pour le transfert de mouvements humains, ils présentent certaines limites, soit en termes de qualité du contenu généré, soit en termes de préservation de l'identité, ou encore souffrent d'incohérences temporelles en raison des limites de la conception du modèle et de la stratégie de formation. De plus, les modèles basés sur la diffusion ne démontrent aucun avantage significatif par rapport Cadres GAN en termes de généralisabilité.
Pour surmonter les obstacles rencontrés par les cadres de diffusion et basés sur le GAN sur les tâches de transfert de mouvement humain, les développeurs ont introduit MagicDance, un nouveau cadre qui vise à exploiter le potentiel des cadres de diffusion pour le transfert de mouvement humain démontrant un niveau sans précédent de préservation de l'identité, une qualité visuelle supérieure, et la généralisabilité du domaine. À la base, le concept fondamental du framework MagicDance est de diviser le problème en deux étapes : le contrôle de l'apparence et le contrôle du mouvement, deux capacités requises par les frameworks de diffusion d'images pour fournir des sorties de transfert de mouvement précises.

La figure ci-dessus donne un bref aperçu du framework MagicDance et, comme on peut le voir, le framework utilise le Modèle de diffusion stable, et déploie également deux composants supplémentaires : Appearance Control Model et Pose ControlNet où le premier fournit un guidage d'apparence au modèle SD à partir d'une image de référence via l'attention tandis que le second fournit un guidage d'expression/pose au modèle de diffusion à partir d'une image ou d'une vidéo conditionnée. Le cadre utilise également une stratégie de formation en plusieurs étapes pour apprendre efficacement ces sous-modules afin de démêler le contrôle de la pose et l'apparence.
En résumé, le framework MagicDance est un
- Cadre novateur et efficace composé d'un contrôle de pose démêlé par l'apparence et d'un pré-entraînement au contrôle de l'apparence.
- Le framework MagicDance est capable de générer des expressions faciales humaines et des mouvements humains réalistes sous le contrôle des entrées de conditions de pose et des images ou vidéos de référence.
- Le framework MagicDance vise à générer un contenu humain cohérent en apparence en introduisant un module d'attention multi-source qui offre des conseils précis pour le framework Stable Diffusion UNet.
- Le framework MagicDance peut également être utilisé comme une extension ou un plug-in pratique pour le framework Stable Diffusion, et garantit également la compatibilité avec les poids des modèles existants car il ne nécessite pas de réglage supplémentaire des paramètres.
De plus, le framework MagicDance présente des capacités de généralisation exceptionnelles pour la généralisation de l'apparence et du mouvement.
- Généralisation des apparences : le framework MagicDance démontre des capacités supérieures lorsqu'il s'agit de générer des apparences diverses.
- Généralisation du mouvement : Le framework MagicDance a également la capacité de générer une large gamme de mouvements.
MagicDance : Objectifs et Architecture
Pour une image de référence donnée, soit d'un humain réel, soit d'une image stylisée, l'objectif principal du framework MagicDance est de générer une image de sortie ou une vidéo de sortie conditionnée par l'entrée et les entrées de pose {P, F} où P représente la pose humaine. squelette et F représente les repères du visage. L'image ou la vidéo de sortie générée doit être capable de préserver l'apparence et l'identité des humains impliqués ainsi que le contenu d'arrière-plan présent dans l'image de référence tout en conservant la pose et les expressions définies par les entrées de pose.
Architecture
Pendant la formation, le framework MagicDance est formé en tant que tâche de reconstruction de trame pour reconstruire la vérité terrain avec l'image de référence et poser l'entrée provenant de la même vidéo de référence. Lors des tests visant à réaliser le transfert de mouvement, l'entrée de pose et l'image de référence proviennent de différentes sources.
L'architecture globale du framework MagicDance peut être divisée en quatre catégories : étape préliminaire, pré-entraînement au contrôle de l'apparence, contrôle de pose démêlé par l'apparence et module de mouvement.
Stage préliminaire
Les modèles de diffusion latente ou LDM représentent des modèles de diffusion spécialement conçus pour fonctionner dans l'espace latent facilité par l'utilisation d'un auto-encodeur, et le cadre de diffusion stable est un exemple notable de LDM qui utilise un vecteur quantifié-variationnel. Encodeur automatique et l'architecture U-Net temporelle. Le modèle Stable Diffusion utilise un transformateur basé sur CLIP comme encodeur de texte pour traiter les entrées textuelles en convertissant les entrées de texte en intégrations. La phase de formation du framework Stable Diffusion expose le modèle à une condition de texte et une image d'entrée avec le processus impliquant l'encodage de l'image vers une représentation latente, et le soumet à une séquence prédéfinie d'étapes de diffusion dirigées par une méthode gaussienne. La séquence résultante produit une représentation latente bruyante qui fournit une distribution normale standard, l'objectif principal d'apprentissage du cadre de diffusion stable étant de débruiter les représentations latentes bruyantes de manière itérative en représentations latentes.
Pré-entraînement au contrôle de l'apparence
Un problème majeur du framework ControlNet original est son incapacité à contrôler de manière cohérente l'apparence des mouvements variant dans l'espace, bien qu'il ait tendance à générer des images avec des poses ressemblant étroitement à celles de l'image d'entrée, l'apparence globale étant principalement influencée par les entrées textuelles. Bien que cette méthode fonctionne, elle n'est pas adaptée au transfert de mouvement impliquant des tâches dans lesquelles ce ne sont pas les entrées textuelles mais l'image de référence qui sert de source principale d'informations sur l'apparence.
Le module de pré-formation sur le contrôle de l'apparence du framework MagicDance est conçu comme une branche auxiliaire pour fournir des conseils pour le contrôle de l'apparence dans une approche couche par couche. Plutôt que de s'appuyer sur des entrées de texte, le module global se concentre sur l'exploitation des attributs d'apparence de l'image de référence dans le but d'améliorer la capacité du cadre à générer les caractéristiques d'apparence avec précision, en particulier dans des scénarios impliquant une dynamique de mouvement complexe. De plus, seul le modèle de contrôle d'apparence peut être entraîné pendant la pré-formation au contrôle d'apparence.
Contrôle de pose démêlé par l'apparence
Une solution naïve pour contrôler la pose dans l'image de sortie consiste à intégrer directement le modèle ControlNet pré-entraîné au modèle de contrôle d'apparence pré-entraîné sans réglage fin. Cependant, l'intégration pourrait entraîner des difficultés avec le contrôle des poses indépendant de l'apparence, ce qui pourrait entraîner un écart entre les poses d'entrée et les poses générées. Pour remédier à cet écart, le framework MagicDance affine le modèle Pose ControlNet conjointement avec le modèle de contrôle d'apparence pré-entraîné.
Module de mouvement
Lorsqu'ils travaillent ensemble, le Pose ControlNet démêlé par l'apparence et le modèle de contrôle de l'apparence peuvent obtenir un transfert d'image à mouvement précis et efficace, bien que cela puisse entraîner une incohérence temporelle. Pour garantir la cohérence temporelle, le framework intègre un module de mouvement supplémentaire dans l'architecture principale Stable Diffusion UNet.
MagicDance : Pré-formation et ensembles de données
Pour la pré-formation, le framework MagicDance utilise un ensemble de données TikTok composé de plus de 350 vidéos de danse de durées variables entre 10 et 15 secondes capturant une seule personne dansant avec une majorité de ces vidéos contenant le visage et le haut du corps de l'humain. Le framework MagicDance extrait chaque vidéo individuelle à 30 FPS et exécute OpenPose sur chaque image individuellement pour déduire le squelette de pose, les poses des mains et les repères du visage.
Pour la pré-formation, le modèle de contrôle d'apparence est pré-entraîné avec une taille de lot de 64 sur 8 GPU NVIDIA A100 pendant 10 512 étapes avec une taille d'image de 512 x 16, suivi d'un réglage conjoint des modèles de contrôle de pose et de contrôle d'apparence avec une taille de lot de 20 pour XNUMX XNUMX étapes. Pendant la formation, le framework MagicDance échantillonne de manière aléatoire deux images comme cible et référence respectivement, les images étant recadrées à la même position et à la même hauteur. Lors de l'évaluation, le modèle recadre l'image de manière centrale au lieu de la recadrer de manière aléatoire.
MagicDance : Résultats
Les résultats expérimentaux menés sur le framework MagicDance sont démontrés dans l'image suivante et, comme on peut le voir, le framework MagicDance surpasse les frameworks existants comme Disco et DreamPose pour le transfert de mouvement humain sur toutes les métriques. Les frameworks comportant un « * » devant leur nom utilisent l'image cible directement comme entrée et incluent plus d'informations par rapport aux autres frameworks.
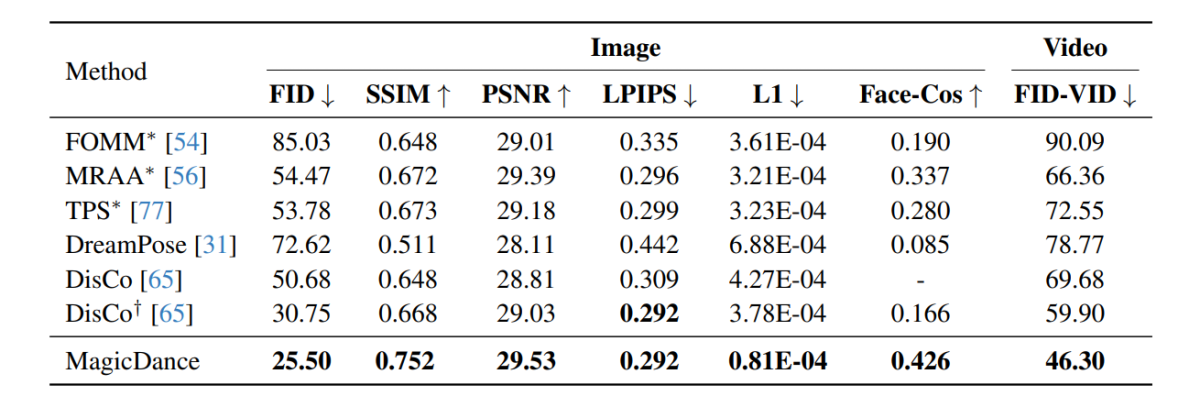
Il est intéressant de noter que le framework MagicDance atteint un score Face-Cos de 0.426, soit une amélioration de 156.62 % par rapport au framework Disco, et une augmentation de près de 400 % par rapport au framework DreamPose. Les résultats indiquent la robuste capacité du framework MagicDance à préserver les informations d'identité, et l'amélioration visible des performances indique la supériorité du framework MagicDance sur les méthodes de pointe existantes.
Les figures suivantes comparent la qualité de la génération vidéo humaine entre les frameworks MagicDance, Disco et TPS. Comme on peut l'observer, les résultats générés par les frameworks GT, Disco et TPS souffrent d'une identité de pose humaine et d'expressions faciales incohérentes.

De plus, l'image suivante montre la visualisation de l'expression faciale et du transfert de pose humaine sur l'ensemble de données TikTok, le cadre MagicDance étant capable de générer des expressions et des mouvements réalistes et vifs sous divers repères faciaux et de poser des entrées de squelette tout en préservant avec précision les informations d'identité de l'entrée de référence. image.

Il convient de noter que le framework MagicDance possède des capacités de généralisation exceptionnelles pour des images de référence hors domaine de poses et de styles invisibles avec une contrôlabilité d'apparence impressionnante, même sans aucun réglage supplémentaire sur le domaine cible, les résultats étant démontrés dans l'image suivante. .

Les images suivantes démontrent les capacités de visualisation du cadre MagicDance en termes de transfert d'expression faciale et de mouvement humain sans prise de vue. Comme on peut le voir, le cadre MagicDance se généralise parfaitement aux mouvements humains dans la nature.

MagicDance : Limites
OpenPose est un composant essentiel du framework MagicDance car il joue un rôle crucial dans le contrôle des poses, affectant considérablement la qualité et la cohérence temporelle des images générées. Cependant, le framework MagicDance a encore un peu de mal à détecter les repères faciaux et à poser les squelettes avec précision, en particulier lorsque les objets dans les images sont partiellement visibles ou montrent des mouvements rapides. Ces problèmes peuvent entraîner des artefacts dans l'image générée.
Conclusion
Dans cet article, nous avons parlé de MagicDance, un modèle basé sur la diffusion qui vise à révolutionner le transfert de mouvement humain. Le framework MagicDance tente de transférer des expressions faciales et des mouvements humains 2D sur des vidéos de danse humaine difficiles dans le but spécifique de générer de nouvelles vidéos de danse humaine basées sur des séquences de poses pour des identités cibles spécifiques tout en gardant l'identité constante. Le cadre MagicDance est une stratégie de formation en deux étapes pour le démêlage des mouvements humains et l'apparence comme le teint, les expressions faciales et les vêtements.
MagicDance est une nouvelle approche visant à faciliter la génération de vidéos humaines réalistes en incorporant le transfert d'expressions faciales et de mouvements, et en permettant une génération d'animations cohérentes dans la nature sans avoir besoin de réglages supplémentaires, ce qui démontre un progrès significatif par rapport aux méthodes existantes. En outre, le framework MagicDance démontre des capacités de généralisation exceptionnelles sur des séquences de mouvements complexes et diverses identités humaines, faisant du framework MagicDance le leader dans le domaine du transfert de mouvement et de la génération vidéo assistés par l'IA.












