Intelligence artificielle
Comment la diffusion stable pourrait se développer en tant que produit grand public

Ironiquement, Stable Diffusion, le nouveau cadre de synthèse d’images par intelligence artificielle qui a conquis le monde, n’est ni stable ni vraiment « diffusé » – du moins, pas encore.
La gamme complète des capacités du système est répartie sur une variété d’offres en constante mutation provenant d’une poignée de développeurs qui échangent frénétiquement les dernières informations et théories dans diverses discussions sur Discord – et la grande majorité des procédures d’installation des packages qu’ils créent ou modifient sont très éloignées d’être « prêtes à l’emploi ».
Plutôt, elles tendent à nécessiter une installation en ligne de commande ou via BAT via GIT, Conda, Python, Miniconda et d’autres cadres de développement de pointe – des logiciels si rares parmi les consommateurs ordinaires que leur installation est fréquemment signalée par les fournisseurs d’antivirus et de logiciels anti-malware comme preuve d’un système hôte compromis.

Seule une petite sélection des étapes de l’installation standard de Stable Diffusion actuellement requise. De nombreuses distributions nécessitent également des versions spécifiques de Python, qui peuvent être en conflit avec les versions existantes installées sur l’ordinateur de l’utilisateur – bien que cela puisse être contourné avec des installations basées sur Docker et, dans une certaine mesure, grâce à l’utilisation d’environnements Conda.
Les fils de discussion dans les communautés Stable Diffusion SFW et NSFW sont inondés de conseils et d’astuces liés au piratage de scripts Python et d’installations standard, afin d’activer une fonctionnalité améliorée ou de résoudre des erreurs de dépendance fréquentes et une gamme d’autres problèmes.
Cela laisse le consommateur moyen, intéressé par la création d’images incroyables à partir de prompts textuels, pratiquement à la merci du nombre croissant d’interfaces Web API monétisées, dont la plupart offrent un nombre minimal de générations d’images gratuites avant de nécessiter l’achat de jetons.
De plus, presque toutes ces offres Web refusent de sortir du contenu NSFW (beaucoup duquel peut concerner des sujets non pornographiques d’intérêt général, tels que « la guerre ») qui distingue Stable Diffusion des services expurgés de DALL-E 2 d’OpenAI.
‘Photoshop pour Stable Diffusion’
Séduits par les images fabuleuses, osées ou autres mondes qui peuplent quotidiennement le hashtag #stablediffusion de Twitter, ce que le monde attend probablement, c’est ‘Photoshop pour Stable Diffusion’ – une application installable multiplateforme qui intègre la meilleure et la plus puissante fonctionnalité de l’architecture de Stability.ai, ainsi que les diverses innovations ingénieuses de la communauté de développement SD émergente, sans aucune fenêtre de ligne de commande flottante, routine d’installation et de mise à jour obscures et changeantes, ou fonctionnalités manquantes.
Ce que nous avons actuellement, dans la plupart des installations les plus capables, c’est une page Web variément élégante chevauchant une fenêtre de ligne de commande désincarnée, et dont l’URL est un port local :

Semblable aux applications de synthèse de CLI telles que FaceSwap et DeepFaceLab basé sur BAT, l’installation ‘prepack’ de Stable Diffusion montre ses racines de ligne de commande, avec l’interface accessible via un port local (voir le haut de l’image ci-dessus) qui communique avec la fonctionnalité de Stable Diffusion basée sur CLI.
Sans aucun doute, une application plus fluide est en route. Déjà, il existe plusieurs applications intégrales basées sur Patreon qui peuvent être téléchargées, telles que GRisk et NMKD (voir image ci-dessous) – mais aucune qui, pour l’instant, intègre la gamme complète de fonctionnalités que certaines des mises en œuvre les plus avancées et les moins accessibles de Stable Diffusion peuvent offrir.

Premiers packages de Stable Diffusion, légèrement ‘app-ized’. NMKD est le premier à intégrer la sortie CLI directement dans le GUI.
Jetons un coup d’œil à ce à quoi pourrait ressembler une mise en œuvre plus polie et intégrale de cette merveille open source étonnante – et quels défis elle pourrait affronter.
Considérations juridiques pour une application Stable Diffusion commerciale entièrement financée
Le facteur NSFW
Le code source de Stable Diffusion a été publié sous une licence extrêmement permissive qui n’interdit pas les réimplémentations commerciales et les œuvres dérivées qui s’appuient largement sur le code source.
Outre les constructions de Stable Diffusion basées sur Patreon mentionnées ci-dessus, ainsi que le nombre important de plugins d’application en cours de développement pour Figma, Krita, Photoshop, GIMP et Blender (entre autres), il n’y a pas de raison pratique pour laquelle une société de développement de logiciels bien financée ne pourrait pas développer une application Stable Diffusion beaucoup plus sophistiquée et capable. Du point de vue du marché, il y a toutes les raisons de croire que plusieurs de ces initiatives sont déjà bien engagées.
Ici, de tels efforts sont confrontés immédiatement au dilemme de savoir si, comme la majorité des API Web pour Stable Diffusion, l’application permettra ou non au filtre NSFW natif de Stable Diffusion (un fragment de code) d’être désactivé.
‘Enfouir’ l’interrupteur NSFW
Bien que la licence open source de Stability.ai pour Stable Diffusion comprenne une liste largement interprétable d’applications pour lesquelles elle peut ne pas être utilisée (ce qui inclut probablement le contenu pornographique et les deepfakes), la seule façon pour un fournisseur de prohiber efficacement une telle utilisation serait de compiler le filtre NSFW dans un exécutable opaque au lieu d’un paramètre dans un fichier Python, ou d’appliquer une comparaison de somme de contrôle sur le fichier Python ou le DLL qui contient la directive NSFW, de sorte que les rendus ne puissent pas se produire si les utilisateurs modifient ce paramètre.
Cela laisserait l’application putative « émascule » de la même manière que DALL-E 2 l’est actuellement, diminuant ainsi son attrait commercial. De plus, inévitablement, des versions « trafiquées » décompilées de ces composants (fichiers Python d’exécution d’origine ou fichiers DLL, comme ceux utilisés dans la gamme d’outils d’amélioration d’image AI de Topaz) émergeraient probablement dans la communauté de piratage/torrent pour contourner de telles restrictions, simplement en remplaçant les éléments obstructifs et en annulant les exigences de somme de contrôle.
À la fin, le fournisseur peut choisir de simplement répéter l’avertissement de Stability.ai contre les mauvaises utilisations qui caractérise la première exécution de nombreuses distributions de Stable Diffusion actuelles.
Cependant, les petits développeurs open source utilisant actuellement des avertissements décontractés de cette manière ont peu à perdre par rapport à une société de logiciels qui a investi des quantités importantes de temps et d’argent pour rendre Stable Diffusion complet et accessible – ce qui invite à une réflexion plus approfondie.
Responsabilité des deepfakes
Comme nous l’avons récemment noté, la base de données LAION-aesthetics, qui fait partie des 4,2 milliards d’images sur lesquelles les modèles en cours de Stable Diffusion ont été formés, contient un grand nombre d’images de célébrités, permettant aux utilisateurs de créer efficacement des deepfakes, y compris des deepfakes de célébrités pornographiques.

De notre article récent, quatre étapes de Jennifer Connelly au cours de quatre décennies de sa carrière, déduites de Stable Diffusion.
Ceci est une question distincte et plus controversée que la génération de « pornographie abstraite » (généralement) légale, qui ne représente pas de « personnes réelles » (bien que de telles images soient déduites de plusieurs photos réelles dans le matériel de formation).
Puisque de plus en plus d’États américains et de pays développent ou ont institué des lois contre la pornographie de deepfakes, la capacité de Stable Diffusion à créer des deepfakes de célébrités pourrait signifier qu’une application commerciale qui n’est pas entièrement censurée (c’est-à-dire qui peut créer du matériel pornographique) pourrait avoir besoin de certains moyens pour filtrer les visages de célébrités perçus.
Une méthode consisterait à fournir une liste noire intégrée de termes qui ne seraient pas acceptés dans un prompt utilisateur, liés aux noms de célébrités et aux personnages fictifs avec lesquels ils peuvent être associés. Présumablement, de tels paramètres devraient être institués dans plus de langues que l’anglais, car les données sources comportent d’autres langues. Une autre approche pourrait consister à intégrer des systèmes de reconnaissance de célébrités tels que ceux développés par Clarifai.
Il peut être nécessaire pour les producteurs de logiciels d’intégrer de telles méthodes, peut-être initialement désactivées, ce qui pourrait aider à empêcher une application autonome Stable Diffusion de générer des visages de célébrités, en attendant de nouvelles législations qui pourraient rendre une telle fonctionnalité illégale.
Une fois encore, cependant, une telle fonctionnalité pourrait inévitablement être décompilée et inversée par des parties intéressées ; cependant, le producteur de logiciels pourrait, dans cette éventualité, affirmer que cela constitue effectivement un vandalisme non autorisé – tant que ce type de rétro-ingénierie n’est pas rendu excessivement facile.
Fonctionnalités qui pourraient être incluses
Les fonctionnalités de base dans toute distribution de Stable Diffusion seraient attendues de toute application commerciale bien financée. Ceux-ci incluent la capacité d’utiliser des prompts textuels pour générer des images appropriées (texte-à-image) ; la capacité d’utiliser des esquisses ou d’autres images comme guides pour de nouvelles images générées (image-à-image) ; les moyens d’ajuster à quel point le système est censé être « imaginatif » ; un moyen de faire des compromis entre le temps de rendu et la qualité ; et d’autres « basiques », tels que l’archivage d’images et de prompts facultatif, et le rééchelonnement facultatif via RealESRGAN, et au moins une « correction de visage » de base avec GFPGAN ou CodeFormer.
C’est une installation « vanille » assez standard. Jetons un coup d’œil à certaines des fonctionnalités plus avancées actuellement en cours de développement ou d’extension, qui pourraient être intégrées dans une application Stable Diffusion traditionnelle et complète.
Stochastic Freezing
Même si vous réutilisez une graine d’un rendu réussi précédent, il est terriblement difficile d’obtenir que Stable Diffusion répète avec précision une transformation si une partie quelconque du prompt ou de l’image source (ou les deux) est modifiée pour un rendu ultérieur.
Ceci est un problème si vous souhaitez utiliser EbSynth pour imposer les transformations de Stable Diffusion sur une vidéo réelle de manière temporellement cohérente – bien que la technique puisse être très efficace pour des plans simples de tête et d’épaules :

Un mouvement limité peut rendre EbSynth un moyen efficace pour convertir les transformations de Stable Diffusion en vidéo réaliste. Source : https://streamable.com/u0pgzd
EbSynth fonctionne en extrapolant une petite sélection de « altérés » keyframes dans une vidéo qui a été rendue en une série de fichiers d’images (et qui peut plus tard être réassemblée en une vidéo).

Dans cet exemple du site EbSynth, une poignée de cadres d’une vidéo ont été peints de manière artistique. EbSynth utilise ces cadres comme guides de style pour altérer l’ensemble de la vidéo de manière à ce qu’elle corresponde au style peint.
Dans l’exemple ci-dessous, qui présente presque aucun mouvement du tout de l’instructeur de yoga blonde (réel) à gauche, Stable Diffusion a encore du mal à maintenir un visage cohérent, car les trois images étant transformées en tant que « keyframes » ne sont pas complètement identiques, même si elles partagent toutes la même graine numérique.

Ici, même avec le même prompt et la même graine pour les trois transformations, et très peu de changements entre les cadres source, les muscles du corps varient en taille et en forme, mais plus important encore, le visage est incohérent, entravant la cohérence temporelle dans un rendu potentiel d’EbSynth.
Bien que la vidéo SD/EbSynth ci-dessous soit très inventive, où les doigts de l’utilisateur sont transformés en (respectivement) une paire de jambes en pantalon et un canard, l’incohérence des pantalons typifie le problème que Stable Diffusion a pour maintenir la cohérence entre différents keyframes, même lorsque les cadres source sont similaires les uns aux autres et que la graine est cohérente.

Les doigts d’un homme deviennent un homme qui marche et un canard, via Stable Diffusion et EbSynth. Source : https://old.reddit.com/r/StableDiffusion/comments/x92itm/proof_of_concept_using_img2img_ebsynth_to_animate/
L’utilisateur qui a créé cette vidéo a commenté que la transformation du canard, qui est probablement la plus efficace des deux, n’a nécessité qu’un seul cadre transformé, alors qu’il a fallu rendre 50 images de Stable Diffusion pour créer les pantalons qui présentent plus d’incohérence temporelle. L’utilisateur a également noté qu’il a fallu cinq tentatives pour parvenir à une cohérence pour chacun des 50 keyframes.
Par conséquent, ce serait un grand avantage pour une application Stable Diffusion vraiment complète de fournir une fonctionnalité qui préserve les caractéristiques au maximum entre les keyframes.
Une possibilité serait de permettre à l’application de « geler » l’encode stochastique pour la transformation sur chaque cadre, ce qui ne peut actuellement être réalisé que en modifiant le code source manuellement. Comme l’exemple ci-dessous le montre, cela aide la cohérence temporelle, même s’il ne résout pas complètement le problème :

Un utilisateur Reddit a transformé des images de webcam de lui-même en différentes personnes célèbres en ne faisant pas seulement persister la graine (ce que toute mise en œuvre de Stable Diffusion peut faire), mais en s’assurant que le paramètre stochastic_encode() était identique dans chaque transformation. Cela a été réalisé en modifiant le code, mais pourrait facilement devenir un commutateur accessible à l’utilisateur. Il est clair, cependant, qu’il ne résout pas tous les problèmes temporels.
Inversion textuelle basée sur le cloud
Une meilleure solution pour éliciter des personnages et des objets temporellement cohérents consiste à « cuire » ceux-ci dans une inversion textuelle – un fichier de 5 Ko qui peut être formé en quelques heures sur la base de seulement cinq images annotées, qui peuvent ensuite être évoquées par un prompt spécial ‘*’, permettant par exemple une apparence persistante de personnages nouveaux pour inclusion dans un récit.

Des images associées à des étiquettes appropriées peuvent être converties en entités distinctes via l’inversion textuelle, et évoquées sans ambiguïté, et dans le contexte et le style corrects, par des mots de jeton spéciaux. Source : https://huggingface.co/docs/diffusers/training/text_inversion
Les inversions textuelles sont des fichiers adjacents au modèle très grand et entièrement formé que Stable Diffusion utilise, et sont effectivement « intégrés » dans le processus d’élicitation/prompting, de sorte qu’elles puissent participer aux scènes dérivées du modèle, et bénéficier de la vaste base de connaissances du modèle sur les objets, les styles, les environnements et les interactions.
Cependant, bien qu’une inversion textuelle ne prenne pas longtemps à former, elle nécessite une grande quantité de VRAM ; selon diverses procédures actuelles, quelque part entre 12, 20 et même 40 Go.
Puisque la plupart des utilisateurs occasionnels ne sont pas susceptibles d’avoir ce type de puissance GPU à leur disposition, des services cloud émergent déjà qui géreront l’opération, y compris une version Hugging Face. Bien qu’il existe des implémentations Google Colab qui peuvent créer des inversions textuelles pour Stable Diffusion, les exigences de VRAM et de temps nécessaires peuvent rendre celles-ci difficiles pour les utilisateurs de Colab de niveau gratuit.
Pour une application Stable Diffusion potentielle et bien investie, passer cette tâche lourde à leurs serveurs cloud semble une stratégie de monétisation évidente (en supposant qu’une application Stable Diffusion à faible coût ou gratuite soit imprégnée d’une telle fonctionnalité non gratuite, ce qui semble probable dans de nombreuses applications possibles qui émergeront de cette technologie dans les 6 à 9 prochains mois).
De plus, le processus relativement compliqué d’annotation et de mise en forme des images et du texte soumis pourrait bénéficier d’une automatisation dans un environnement intégré. Le facteur « addictif » potentiel de création d’éléments uniques qui peuvent explorer et interagir avec les vastes mondes de Stable Diffusion semblerait potentiellement compulsif, à la fois pour les passionnés et les utilisateurs plus jeunes.
Pondération de prompt versatile
Il existe de nombreuses mises en œuvre actuelles qui permettent à l’utilisateur d’attribuer plus d’importance à une section d’un long prompt textuel, mais l’instrumentalité varie beaucoup entre ceux-ci, et est souvent maladroite ou peu intuitive.
La fourche de Stable Diffusion très populaire par AUTOMATIC1111 peut, par exemple, diminuer ou augmenter la valeur d’un mot de prompt en l’encadrant entre des crochets simples ou multiples (pour une dé-emphase) ou des crochets carrés pour une emphase supplémentaire.

Les crochets carrés et/ou les parenthèses peuvent transformer votre petit-déjeuner dans cette version de Stable Diffusion de pondération de prompt, mais c’est un cauchemar au cholesterol de toute façon.
D’autres itérations de Stable Diffusion utilisent des points d’exclamation pour l’emphase, tandis que les plus polyvalents permettent aux utilisateurs d’attribuer des poids à chaque mot du prompt via le GUI.
Le système devrait également permettre des pondérations de prompt négatives – pas seulement pour les amateurs d’horreur, mais parce qu’il peut y avoir moins d’alarmes et plus d’édification dans l’espace latent de Stable Diffusion que notre utilisation limitée du langage peut évoquer.
Peinture extérieure
Peu de temps après l’ouverture en source de Stable Diffusion, OpenAI a tenté – en grande partie en vain – de reprendre un peu de son éclat DALL-E 2 en annonçant « l’outpainting », qui permet à l’utilisateur d’étendre une image au-delà de ses limites avec une logique sémantique et une cohérence visuelle.
Naturellement, cela a depuis été implémenté sous diverses formes pour Stable Diffusion, ainsi que dans Krita, et devrait certainement être inclus dans une version complète et « Photoshop » de Stable Diffusion.
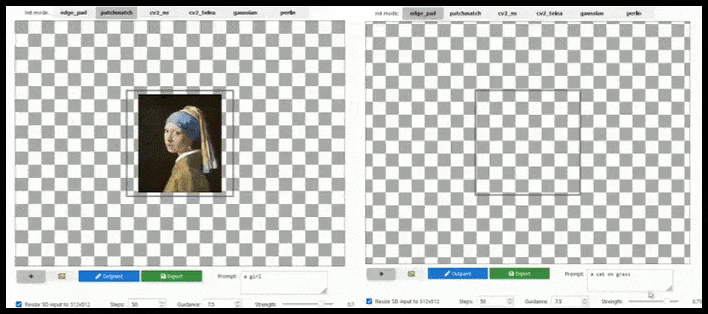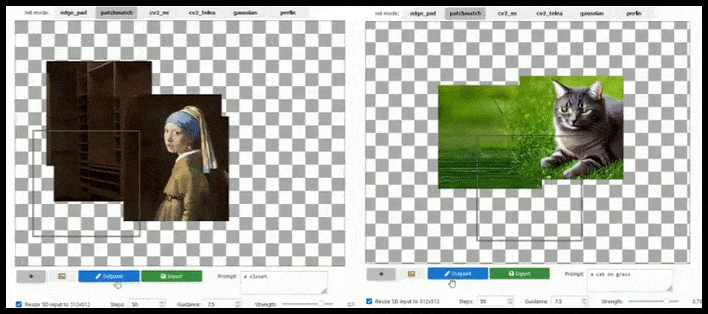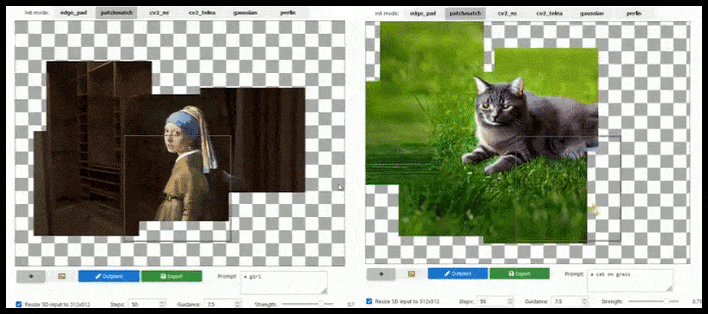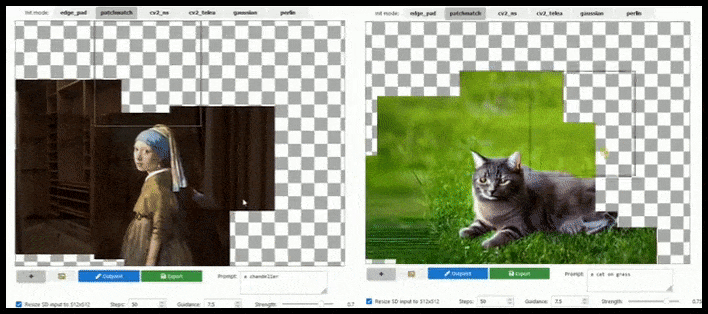
L’augmentation basée sur les tuiles peut étendre un rendu standard de 512×512 presque infiniment, tant que les prompts, l’image existante et la logique sémantique le permettent. Source : https://github.com/lkwq007/stablediffusion-infinity
Puisque Stable Diffusion est formé sur des images de 512x512px (et pour diverses autres raisons), il coupe fréquemment les têtes (ou d’autres parties essentielles du corps) des sujets humains, même lorsque le prompt indiquait clairement « accent sur la tête », etc..

Exemples typiques de « décapitation » de Stable Diffusion ; mais l’outpainting pourrait remettre George dans l’image.
Toute mise en œuvre d’outpainting du type illustré dans l’image animée ci-dessus (qui repose exclusivement sur les bibliothèques Unix, mais devrait être capable d’être reproduite sur Windows) devrait également être outillée comme un remède en un seul clic/prompt pour ce problème.
Actuellement, de nombreux utilisateurs étendent le canevas des représentations « décapitées » vers le haut, remplissent approximativement la zone de la tête et utilisent img2img pour compléter le rendu défectueux.
Masquage efficace qui comprend le contexte
Le masquage peut être une affaire terriblement aléatoire dans Stable Diffusion, selon la fourche ou la version en question. Fréquemment, lorsque cela est possible de dessiner un masque cohérent, la zone spécifiée se retrouve peinte avec un contenu qui ne prend pas en compte le contexte entier de l’image.
À une occasion, j’ai masqué les cornées d’une image de visage et fourni le prompt ‘yeux bleus’ comme masque pour peindre – seulement pour découvrir que j’avais l’air de regarder à travers deux yeux humains découpés à une image lointaine d’un loup surnaturel. Je suppose que j’ai de la chance que ce ne soit pas Frank Sinatra.
L’édition sémantique est également possible en identifiant le bruit qui a construit l’image en premier lieu, ce qui permet à l’utilisateur d’aborder des éléments structurels spécifiques dans un rendu sans interférer avec le reste de l’image :

Changer un élément dans une image sans masquage traditionnel et sans modifier le contenu adjacent, en identifiant le bruit qui a originellement créé l’image et en s’adressant aux parties de celui-ci qui ont contribué à la zone cible. Source : https://old.reddit.com/r/StableDiffusion/comments/xboy90/a_better_way_of_doing_img2img_by_finding_the/
Cette méthode repose sur l’échantillonneur K-Diffusion.
Filtres sémantiques pour les erreurs physiologiques
Comme nous l’avons mentionné précédemment, Stable Diffusion peut fréquemment ajouter ou soustraire des membres, en grande partie en raison de problèmes de données et de lacunes dans les annotations qui accompagnent les images qui l’ont formé.

Juste comme cet enfant turbulent qui a mis sa langue dehors dans la photo de classe, les atrocités biologiques de Stable Diffusion ne sont pas toujours immédiatement évidentes, et vous pourriez avoir partagé votre dernière œuvre d’art AI sur Instagram avant de remarquer les mains supplémentaires ou les membres fondus.
Il est si difficile de corriger ces types d’erreurs qu’il serait utile qu’une application Stable Diffusion complète contienne un système de reconnaissance anatomique qui utilise une segmentation sémantique pour calculer si l’image entrante présente des déficiences anatomiques graves (comme sur l’image ci-dessus), et la rejette en faveur d’un nouveau rendu avant de la présenter à l’utilisateur.

Bien sûr, vous pourriez vouloir rendre la déesse Kali, ou Docteur Octopus, ou même sauver une partie non affectée d’une image atteinte de membres, donc cette fonctionnalité devrait être un commutateur facultatif.
Si les utilisateurs pouvaient tolérer l’aspect télémétrie, de telles erreurs pourraient même être transmises de manière anonyme dans un effort d’apprentissage fédératif collectif qui pourrait aider les futurs modèles à améliorer leur compréhension de la logique anatomique.
Amélioration automatique de visage basée sur LAION
Comme je l’ai noté dans mon examen précédent de trois choses que Stable Diffusion pourrait aborder à l’avenir, il ne devrait pas être laissé uniquement à une version de GFPGAN pour essayer d’« améliorer » les visages rendus dans les premiers rendus.
Les « améliorations » de GFPGAN sont terriblement génériques, minent fréquemment l’identité de l’individu représenté et ne fonctionnent que sur un visage qui a reçu autant de temps de traitement et d’attention que n’importe quelle autre partie de l’image.
Par conséquent, un programme professionnel pour Stable Diffusion devrait être capable de reconnaître un visage (avec une bibliothèque légère standard telle que YOLO), d’appliquer toute la puissance de traitement GPU disponible pour le rendre à nouveau, et soit de fusionner le visage amélioré dans le rendu complet d’origine, soit de l’enregistrer séparément pour une recomposition manuelle. Actuellement, c’est une opération assez « main dans la main ».
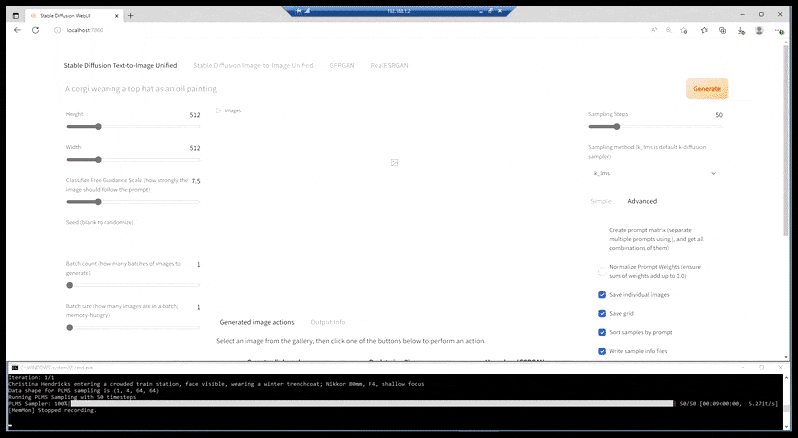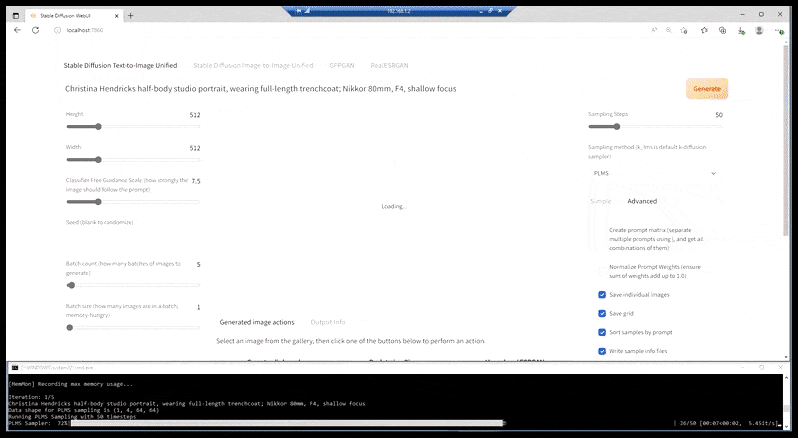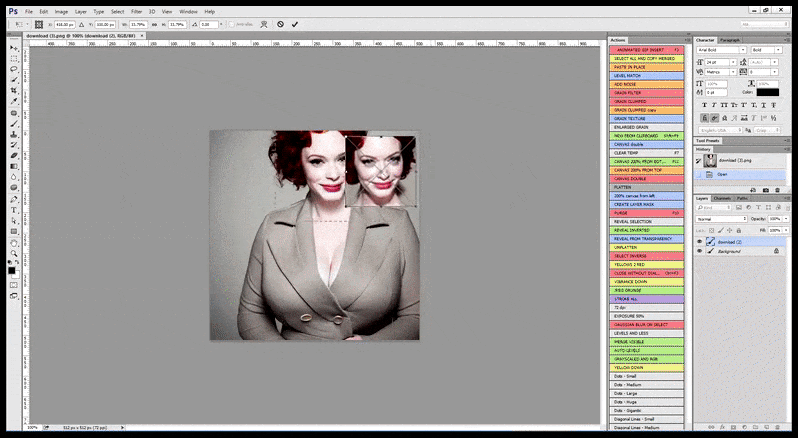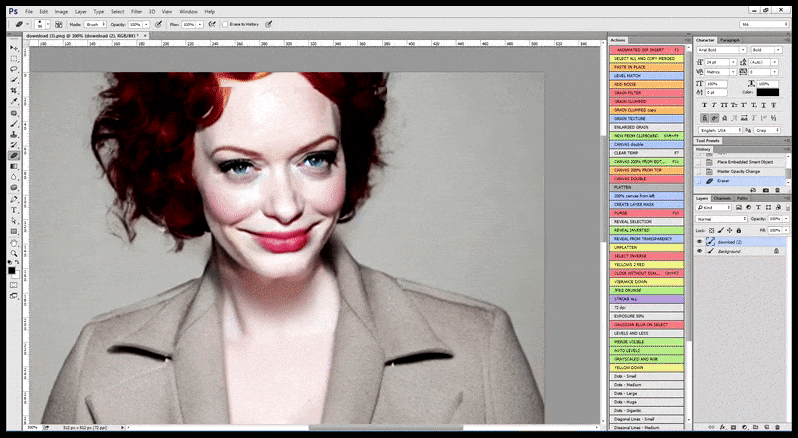
Dans les cas où Stable Diffusion a été formé sur un nombre adéquat d’images d’une célébrité, il est possible de concentrer toute la capacité de GPU sur un rendu ultérieur uniquement du visage de l’image rendue, ce qui est généralement une amélioration notable – et, contrairement à GFPGAN, tire parti des données formées par LAION, plutôt que de simplement ajuster les pixels rendus.
Recherches LAION en application
Depuis que les utilisateurs ont commencé à réaliser que la recherche dans la base de données LAION pour des concepts, des personnes et des thèmes pourrait être un aide pour une meilleure utilisation de Stable Diffusion, plusieurs explorateurs de LAION en ligne ont été créés, notamment haveibeentrained.com.

La fonction de recherche sur haveibeentrained.com permet aux utilisateurs d’explorer les images qui alimentent Stable Diffusion, et de découvrir si les objets, les personnes ou les idées qu’ils pourraient souhaiter évoquer du système sont susceptibles d’avoir été formées en son sein. De tels systèmes sont également utiles pour découvrir des entités adjacentes, telles que la façon dont les célébrités sont regroupées, ou la « prochaine idée » qui découle de l’idée actuelle. Source : https://haveibeentrained.com/?search_text=bowl%20of%20fruit
Bien que de tels bases de données Web révèlent parfois certaines des étiquettes qui accompagnent les images, le processus de généralisation qui se produit pendant la formation du modèle signifie qu’il est peu probable qu’une image particulière puisse être évoquée en utilisant son étiquette comme prompt.
De plus, la suppression de « mots d’arrêt » et la pratique de racinisation et de lemmatisation dans le traitement automatique du langage signifie que de nombreuses phrases affichées ont été divisées ou omises avant d’être formées dans Stable Diffusion.
Néanmoins, la façon dont les regroupements esthétiques se lient dans ces interfaces peut enseigner à l’utilisateur final beaucoup de choses sur la logique (ou, de manière arguable, la « personnalité ») de Stable Diffusion, et prouver un aide pour une meilleure production d’images.
Conclusion
Il existe de nombreuses autres fonctionnalités que j’aimerais voir dans une mise en œuvre de bureau native de Stable Diffusion, telles qu’une analyse d’image native basée sur CLIP, qui inverse le processus standard de Stable Diffusion et permet à l’utilisateur d’évoquer des phrases et des mots que le système associerait naturellement à l’image source, ou au rendu.
De plus, un rééchelonnement basé sur des tuiles réel serait une addition bienvenue, puisque ESRGAN est presque aussi grossier qu’un instrument que GFPGAN. Heureusement, les plans pour intégrer la mise en œuvre txt2imghd de GOBIG sont rapidement en train de rendre cela une réalité dans les distributions, et il s’agit d’un choix évident pour une itération de bureau.
Certaines autres demandes populaires des communautés Discord m’intéressent moins, telles que des dictionnaires de prompts intégrés et des listes applicables d’artistes et de styles, bien qu’un cahier ou un lexique personnalisable de phrases dans l’application semble une addition logique.
De même, les limites actuelles de l’animation humaine dans Stable Diffusion, bien que lancées par CogVideo et divers autres projets, restent incroyablement naissantes, et à la merci de la recherche en amont sur les priorités temporelles liées au mouvement humain authentique.
Pour l’instant, la vidéo Stable Diffusion est strictement psychedélique, bien qu’elle puisse avoir un avenir plus brillant dans la marionnette de deepfake, via EbSynth et d’autres initiatives de texte-à-vidéo relativement naissantes (et il vaut la peine de noter l’absence de personnes synthétisées ou « altérées » dans la vidéo promotionnelle la plus récente de Runway).
Une autre fonctionnalité précieuse serait le passage transparent de Photoshop, établi depuis longtemps dans l’éditeur de texture de Cinema4D, ainsi que dans d’autres mises en œuvre similaires. Avec cela, on peut facilement faire passer des images entre les applications et utiliser chaque application pour effectuer les transformations qu’elle excelle à réaliser.
Enfin, et peut-être plus important encore, un programme de bureau Stable Diffusion complet devrait être en mesure non seulement de basculer facilement entre les points de contrôle (c’est-à-dire les versions du modèle sous-jacent qui alimente le système), mais également de mettre à jour les inversions textuelles personnalisées qui fonctionnaient avec les versions de modèle officielles précédentes, mais qui pourraient sinon être cassées par les versions ultérieures du modèle (comme l’ont indiqué les développeurs sur le Discord officiel).
Ironiquement, l’organisation dans la meilleure position pour créer un tel puissant et intégré ensemble d’outils pour Stable Diffusion, Adobe, s’est alliée si fortement à l’initiative Content Authenticity Initiative qu’il pourrait sembler un pas de recul en termes de relations publiques – à moins qu’il ne positionne Stable Diffusion comme une évolution naturelle de ses importantes participations en photographie de stock.
Publié pour la première fois le 15 septembre 2022.












