Intelligence Artificielle
Trois défis à relever pour une diffusion stable

Le libérer de la diffusion stable de stability.ai diffusion latente modèle de synthèse d'image il y a quelques semaines peut être l'une des divulgations technologiques les plus importantes depuis le DeCSS en 1999; c'est certainement le plus grand événement dans le domaine de l'imagerie générée par l'IA depuis 2017 code de contrefaçon a été copié sur GitHub et forké dans ce qui allait devenir Laboratoire DeepFace et Échange de visage, ainsi que le logiciel deepfake de streaming en temps réel DeepFaceLive.
D'un coup, frustration des utilisateurs au cours de la restrictions de contenu dans l'API de synthèse d'images de DALL-E 2 ont été balayés, car il est apparu que le filtre NSFW de Stable Diffusion pouvait être désactivé en modifiant un seule ligne de code. Les Reddits Stable Diffusion centrés sur le porno ont vu le jour presque immédiatement et ont été réduits aussi rapidement, tandis que le camp des développeurs et des utilisateurs s'est divisé sur Discord entre les communautés officielles et NSFW, et Twitter a commencé à se remplir de fantastiques créations Stable Diffusion.
Pour le moment, chaque jour semble apporter une innovation étonnante de la part des développeurs qui ont adopté le système, avec des plugins et des compléments tiers écrits à la hâte pour Krita, Photoshop, Cinema4D, Mixeur, et de nombreuses autres plates-formes d'application.
En attendant, promptcraft – l'art désormais professionnel du « chuchotement de l'IA », qui pourrait bien être l'option de carrière la plus courte depuis « classeur Filofax » – est déjà en train de devenir commercialisé, tandis qu'une monétisation précoce de Stable Diffusion s'opère au Niveau Patreon, avec la certitude d'offres plus sophistiquées à venir, pour ceux qui ne veulent pas naviguer Basé sur Conda installations du code source ou les filtres NSFW proscriptifs des implémentations Web.
Le rythme de développement et la liberté d'exploration offerte aux utilisateurs progressent à une vitesse si vertigineuse qu'il est difficile de voir loin. En réalité, nous ne savons pas encore exactement à quoi nous avons affaire, ni quelles pourraient être les limites ou les possibilités.
Néanmoins, examinons trois de ce qui pourrait être les obstacles les plus intéressants et les plus difficiles à surmonter pour la communauté Stable Diffusion, qui s'est formée et qui connaît une croissance rapide, et qui, espérons-le, doit les surmonter.
1 : Optimisation des pipelines basés sur des tuiles
Présentés avec des ressources matérielles limitées et des limites strictes sur la résolution des images de formation, il semble probable que les développeurs trouveront des solutions de contournement pour améliorer à la fois la qualité et la résolution de la sortie Stable Diffusion. Un grand nombre de ces projets impliquent l'exploitation des limites du système, telles que sa résolution native de seulement 512 × 512 pixels.
Comme c'est toujours le cas avec les initiatives de vision par ordinateur et de synthèse d'images, Stable Diffusion a été entraînée sur des images au format carré, dans ce cas rééchantillonnées à 512 × 512, afin que les images sources puissent être régularisées et capables de s'adapter aux contraintes des GPU qui formé le modèle.
Par conséquent, la diffusion stable « pense » (si tant est qu'elle pense) en termes de 512×512, et certainement en termes carrés. De nombreux utilisateurs sondant actuellement les limites du système signalent que la diffusion stable produit les résultats les plus fiables et les moins instables à ce rapport hauteur/largeur plutôt contraint (voir « Gérer les extrêmes » ci-dessous).
Bien que diverses implémentations comportent une mise à l'échelle via RéelESRGAN (et peut corriger les visages mal rendus via GFPGAN) plusieurs utilisateurs développent actuellement des méthodes pour diviser les images en sections de 512x512px et assembler les images pour former des œuvres composites plus grandes.

Ce rendu 1024×576, une résolution habituellement impossible dans un seul rendu Stable Diffusion, a été créé en copiant et collant le fichier Python attention.py du DoggettX fork de Stable Diffusion (une version qui implémente la mise à l'échelle basée sur les tuiles) dans un autre fork. Source : https://old.reddit.com/r/StableDiffusion/comments/x6yeam/1024x576_with_6gb_nice/
Bien que certaines initiatives de ce type utilisent du code original ou d'autres bibliothèques, le port txt2imghd de GOBIG (un mode dans ProgRockDiffusion gourmand en VRAM) est configuré pour fournir bientôt cette fonctionnalité à la branche principale. Alors que txt2imghd est un port dédié de GOBIG, d'autres efforts des développeurs de la communauté impliquent différentes implémentations de GOBIG.

Une image commodément abstraite dans le rendu original de 512x512px (à gauche et deuxième à partir de la gauche) ; mise à l'échelle par ESGRAN, qui est maintenant plus ou moins native dans toutes les distributions Stable Diffusion ; et bénéficiant d'une « attention particulière » via une implémentation de GOBIG, produisant des détails qui, au moins dans les limites de la section d'image, semblent mieux mis à l'échelle. Ssource : https://old.reddit.com/r/StableDiffusion/comments/x72460/stable_diffusion_gobig_txt2imghd_easy_mode_colab/
Le type d'exemple abstrait présenté ci-dessus comporte de nombreux « petits royaumes » de détails qui conviennent à cette approche solipsiste de la mise à l'échelle, mais qui peuvent nécessiter des solutions plus complexes basées sur le code afin de produire une mise à l'échelle non répétitive et cohérente qui ne du dernier Comme s'il était composé de plusieurs éléments. Notamment dans le cas des visages humains, où nous sommes particulièrement sensibles aux aberrations ou aux artefacts « perturbants ». Par conséquent, les visages pourraient éventuellement nécessiter une solution dédiée.
Stable Diffusion ne dispose actuellement d'aucun mécanisme permettant de focaliser l'attention sur le visage lors d'un rendu, de la même manière que les humains priorisent les informations faciales. Bien que certains développeurs de la communauté Discord étudient des méthodes pour implémenter ce type d'« attention améliorée », il est actuellement beaucoup plus simple d'améliorer manuellement (et, à terme, automatiquement) le visage après le rendu initial.
Un visage humain possède une logique sémantique interne et complète qui ne se trouve pas dans une « tuile » du coin inférieur (par exemple) d'un bâtiment, et il est donc actuellement possible de « zoomer » très efficacement et de restituer un visage « esquissé » dans une sortie Stable Diffusion.

À gauche, le premier travail de Stable Diffusion avec le sujet « Photo couleur en pied de Christina Hendricks entrant dans un lieu bondé, vêtue d'un imperméable ; Canon 50, contact visuel, détails élevés, détails du visage élevés ». À droite, un visage amélioré obtenu en transmettant le visage flou et esquissé du premier rendu à Stable Diffusion grâce à Img2Img (voir les images animées ci-dessous).
En l'absence d'une solution d'inversion textuelle dédiée (voir ci-dessous), cela ne fonctionnera que pour les images de célébrités où la personne en question est déjà bien représentée dans les sous-ensembles de données LAION qui ont formé Stable Diffusion. Par conséquent, il fonctionnera sur des personnalités comme Tom Cruise, Brad Pitt, Jennifer Lawrence et une gamme limitée de véritables sommités médiatiques qui sont présentes dans un grand nombre d'images dans les données sources.
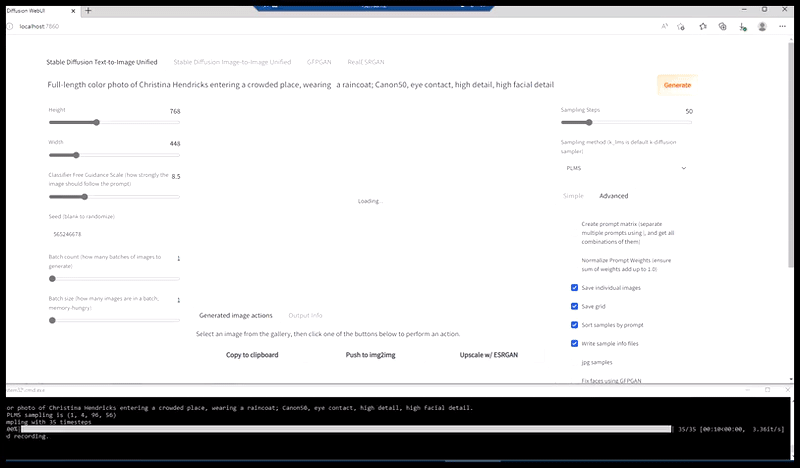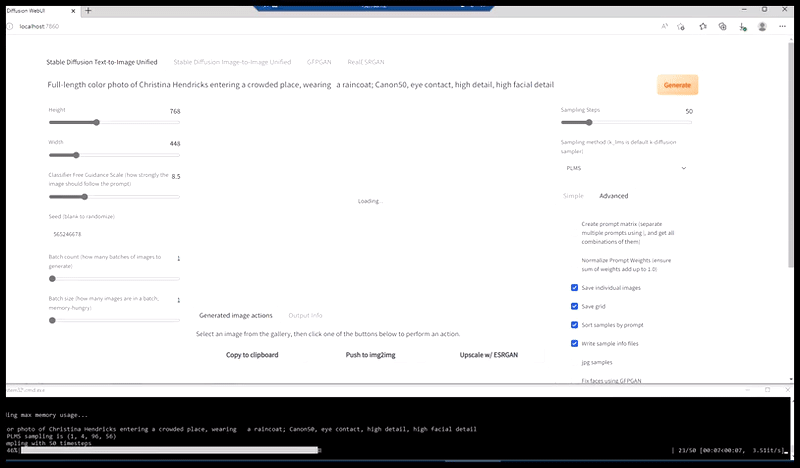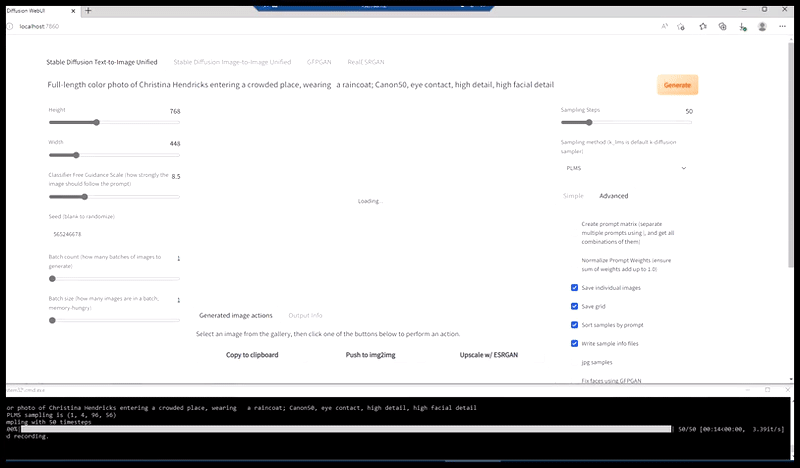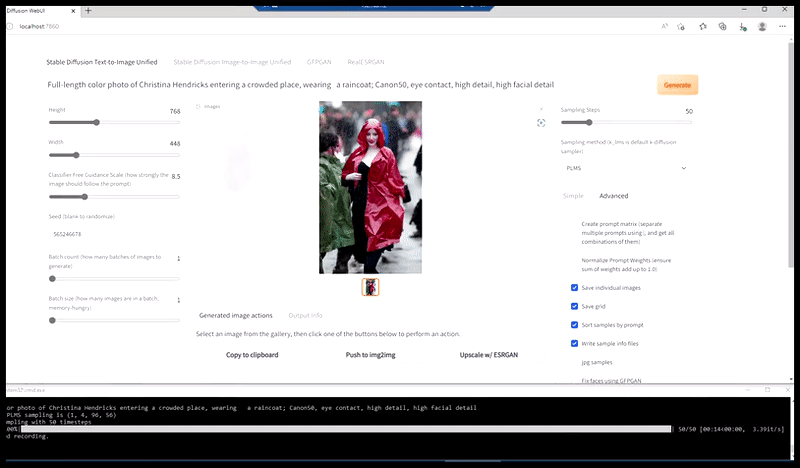
Générer une photo de presse plausible avec l'invite « Photo couleur en pied de Christina Hendricks entrant dans un endroit bondé, portant un imperméable ; Canon50, contact visuel, détails élevés, détails du visage élevés ».
Pour les célébrités ayant une carrière longue et durable, Stable Diffusion générera généralement une image de la personne à un âge récent (c'est-à-dire plus âgé), et il sera nécessaire d'ajouter des compléments rapides tels que 'jeune' or « en l'an [ANNÉE] » afin de produire des images plus jeunes.

Avec une carrière proéminente, très photographiée et cohérente s'étendant sur près de 40 ans, l'actrice Jennifer Connelly est l'une des rares célébrités de LAION qui permettent à Stable Diffusion de représenter une gamme d'âges. Source : préemballage Stable Diffusion, local, point de contrôle v1.4 ; invites liées à l'âge.
Cela est dû en grande partie à la prolifération de la photographie de presse numérique (plutôt que coûteuse, à base d'émulsion) à partir du milieu des années 2000, et à la croissance ultérieure du volume de sortie d'image en raison de l'augmentation des vitesses à large bande.
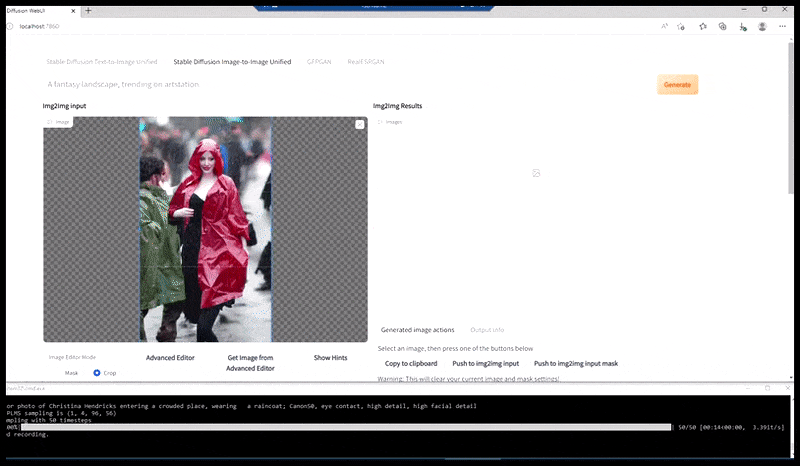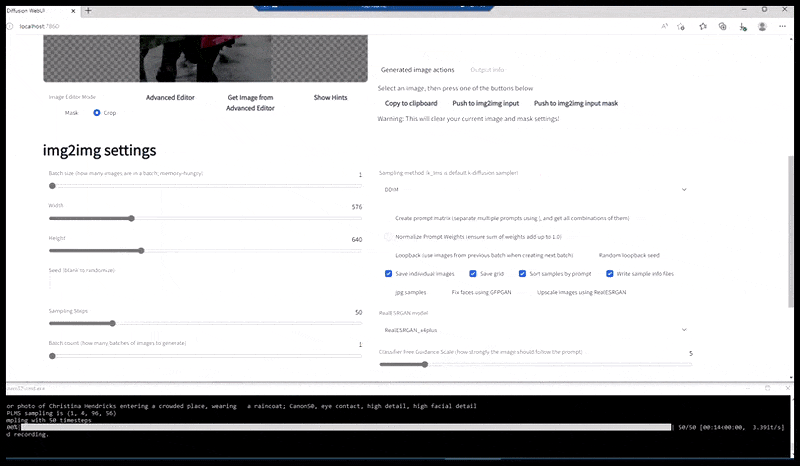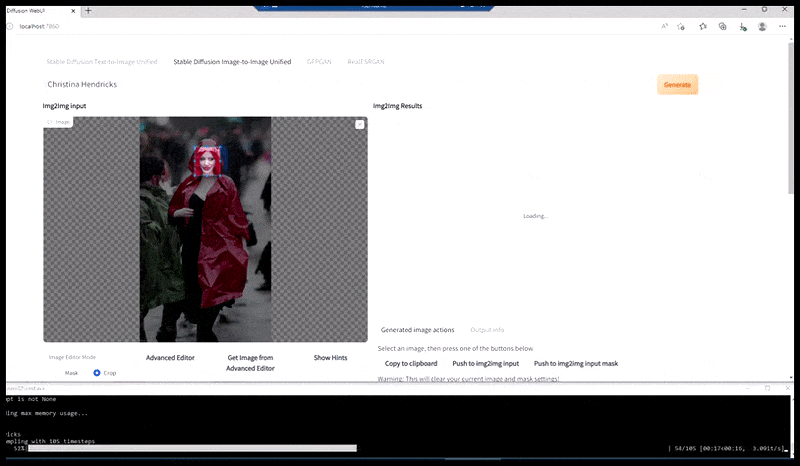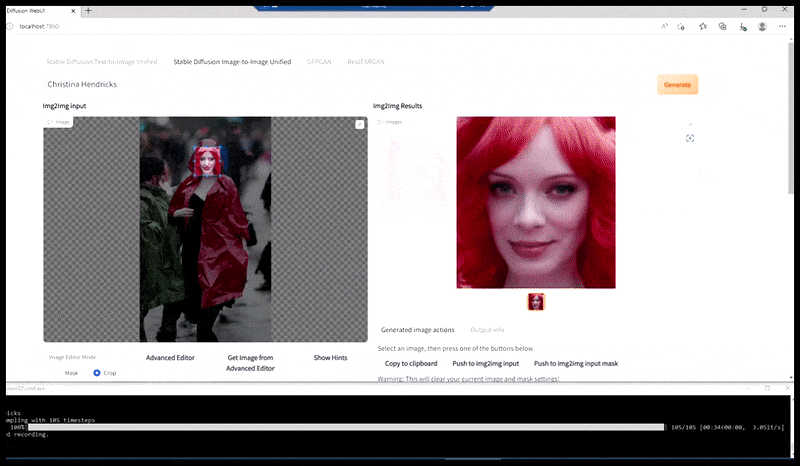
L'image rendue est transmise à Img2Img dans Stable Diffusion, où une « zone de mise au point » est sélectionnée et un nouveau rendu de taille maximale est réalisé uniquement à partir de cette zone, permettant à Stable Diffusion de concentrer toutes les ressources disponibles sur la recréation du visage.
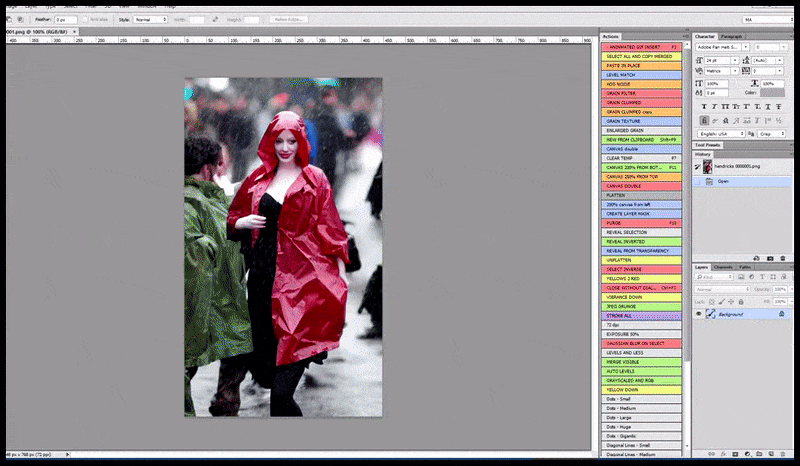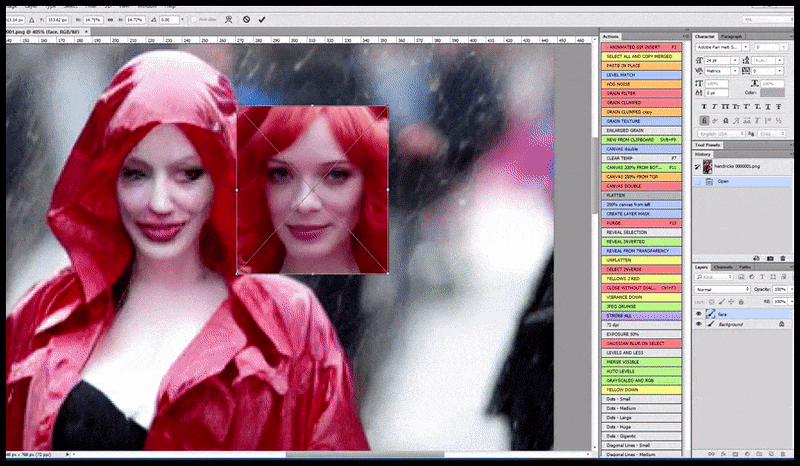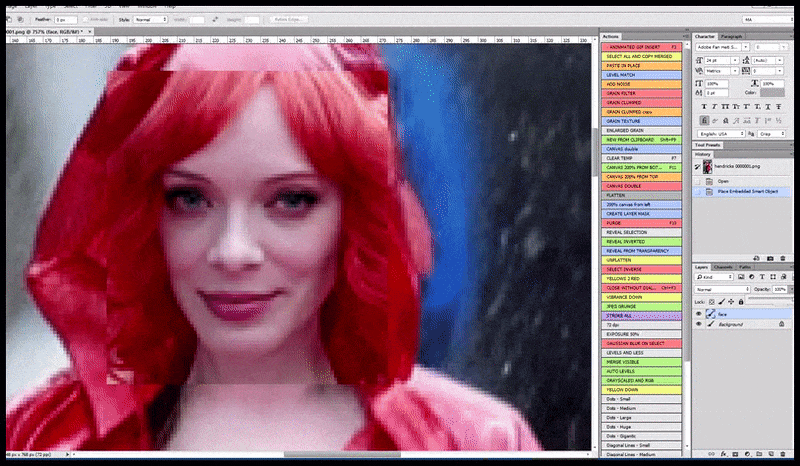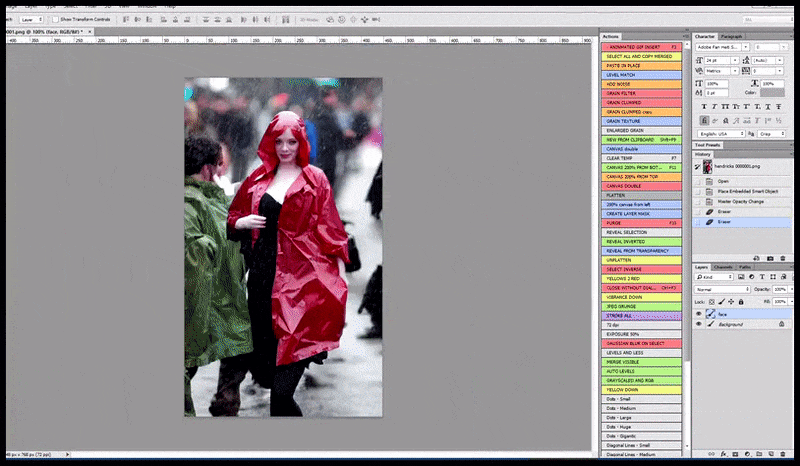
Recomposer le visage « à haute attention » dans le rendu d'origine. Outre les visages, ce processus ne fonctionne qu'avec des entités potentiellement connues, cohérentes et intégrées, comme une portion de la photo originale contenant un objet distinct, comme une montre ou une voiture. Agrandir une section de mur, par exemple, donnera un mur reconstitué d'aspect très étrange, car les rendus de tuiles ne tenaient pas compte du contexte plus large de cette « pièce de puzzle » lors du rendu.
Certaines célébrités de la base de données sont « pré-figées » dans le temps, soit parce qu'elles sont décédées prématurément (comme Marilyn Monroe), soit parce qu'elles n'ont connu qu'une notoriété éphémère, générant un volume important d'images en un temps limité. Polling Stable Diffusion fournit sans doute une sorte d'indice de popularité « actuel » pour les stars modernes et plus anciennes. Pour certaines célébrités, anciennes ou actuelles, les données sources ne contiennent pas suffisamment d'images pour obtenir une très bonne ressemblance, tandis que la popularité durable de certaines stars disparues depuis longtemps ou disparues permet d'obtenir une ressemblance raisonnable grâce au système.

Les rendus de diffusion stable révèlent rapidement quels visages célèbres sont bien représentés dans les données d'entraînement. Malgré son énorme popularité en tant qu'adolescente plus âgée au moment de la rédaction, Millie Bobby Brown était plus jeune et moins connue lorsque les ensembles de données source LAION ont été extraits du Web, ce qui rend problématique une ressemblance de haute qualité avec Stable Diffusion pour le moment.
Lorsque les données sont disponibles, les solutions haute résolution basées sur des mosaïques dans Stable Diffusion pourraient aller plus loin que de se concentrer sur le visage : elles pourraient potentiellement permettre des visages encore plus précis et détaillés en décomposant les traits du visage et en tournant toute la force du GPU local. ressources sur les caractéristiques saillantes individuellement, avant le réassemblage - un processus qui est actuellement, encore une fois, manuel.

Ceci n'est pas limité aux visages, mais il est limité aux parties d'objets qui sont au moins aussi prévisibles placées dans le contexte plus large de l'objet hôte, et qui sont conformes aux incorporations de haut niveau que l'on pourrait raisonnablement s'attendre à trouver dans une hyperscale base de données.
La véritable limite est la quantité de données de référence disponibles dans l'ensemble de données, car, à terme, les détails profondément itérés deviendront totalement « hallucinés » (c'est-à-dire fictifs) et moins authentiques.
Ces agrandissements granulaires de haut niveau fonctionnent dans le cas de Jennifer Connelly, car elle est bien représentée à travers une gamme d'âges dans LAION-esthétique (le sous-ensemble principal de LAION 5B que Stable Diffusion utilise), et généralement à travers LAION ; dans de nombreux autres cas, la précision souffrirait du manque de données, nécessitant soit un réglage fin (formation supplémentaire, voir « Personnalisation » ci-dessous) soit une inversion textuelle (voir ci-dessous).
Les tuiles sont un moyen puissant et relativement bon marché pour permettre à Stable Diffusion de produire une sortie haute résolution, mais la mise à l'échelle algorithmique de tuiles de ce type, si elle manque d'une sorte de mécanisme d'attention plus large et de niveau supérieur, peut ne pas être à la hauteur des attentes. pour les normes à travers une gamme de types de contenu.
2 : Résoudre les problèmes liés aux membres humains
Stable Diffusion ne fait pas honneur à son nom lorsqu'il s'agit de décrire la complexité des extrémités humaines. Les mains peuvent se multiplier de manière aléatoire, les doigts fusionner, des troisièmes jambes apparaissent sans prévenir et des membres existants disparaissent sans laisser de trace. À sa décharge, Stable Diffusion partage le problème avec ses congénères, et plus particulièrement avec DALL-E 2.

Résultats non édités des études DALL-E 2 et Stable Diffusion (1.4) de fin août 2022, tous deux montrant des problèmes aux membres. Le sujet est : « Une femme enlace un homme ».
Les fans de Stable Diffusion espérant que le prochain point de contrôle 1.5 (une version plus intensément entraînée du modèle, avec des paramètres améliorés) résoudrait la confusion des membres seront probablement déçus. Le nouveau modèle, qui sortira en dans environ deux semaines, est actuellement en première sur le portail commercial Stabilité.ai Studio de rêve, qui utilise la version 1.5 par défaut, et où les utilisateurs peuvent comparer la nouvelle sortie avec les rendus de leur système local ou d'autres systèmes 1.4 :

Source : prépack Local 1.4 et https://beta.dreamstudio.ai/

Source : prépack Local 1.4 et https://beta.dreamstudio.ai/

Source : prépack Local 1.4 et https://beta.dreamstudio.ai/
Comme c'est souvent le cas, la qualité des données pourrait bien être la principale cause contributive.
Les bases de données open source qui alimentent les systèmes de synthèse d'images tels que Stable Diffusion et DALL-E 2 sont capables de fournir de nombreuses étiquettes pour les humains individuels et l'action interhumaine. Ces étiquettes sont formées en symbiose avec leurs images associées ou segments d'images.

Les utilisateurs de Stable Diffusion peuvent explorer les concepts entraînés dans le modèle en interrogeant le jeu de données LAION-aesthetics, un sous-ensemble du jeu de données LAION 5B, qui alimente le système. Les images sont classées non pas par ordre alphabétique, mais par leur « score esthétique ». Source : https://rom1504.github.io/clip-retrieval/
A bonne hiérarchie des étiquettes individuelles et des classes contribuant à la représentation d'un bras humain serait quelque chose comme corps> bras> main> doigts> [sous-chiffres + pouce]> [segments de chiffres]> ongles.

Segmentation sémantique granulaire des parties d'une main. Même cette déconstruction inhabituellement détaillée laisse chaque « doigt » comme une entité unique, sans tenir compte des trois sections d'un doigt et des deux sections d'un pouce. Source : https://athitsos.utasites.cloud/publications/rezaei_petra2021.pdf
En réalité, il est peu probable que les images sources soient annotées de manière aussi cohérente sur l'ensemble de l'ensemble de données, et les algorithmes d'étiquetage non supervisés s'arrêteront probablement à la augmentation niveau de – par exemple – « main », et laisser les pixels intérieurs (qui contiennent techniquement des informations sur les « doigts ») comme une masse de pixels non étiquetés à partir desquels des caractéristiques seront dérivées arbitrairement, et qui peuvent se manifester dans les rendus ultérieurs comme un élément discordant.

Comment cela devrait être (en haut à droite, sinon en haut) et comment cela a tendance à être (en bas à droite), en raison de ressources limitées pour l'étiquetage ou de l'exploitation architecturale de ces étiquettes si elles existent dans l'ensemble de données.
Ainsi, si un modèle de diffusion latente parvient à rendre un bras, il va presque certainement au moins essayer de rendre une main à l'extrémité de ce bras, car bras>main est la hiérarchie minimale requise, assez élevée dans ce que l'architecture sait de « l'anatomie humaine ».
Après cela, les « doigts » peuvent être le plus petit groupe, même s'il existe 14 autres sous-parties de doigts/pouces à prendre en compte lors de la représentation des mains humaines.
Si cette théorie tient, il n'y a pas de véritable remède, en raison du manque de budget pour l'annotation manuelle à l'échelle du secteur et du manque d'algorithmes suffisamment efficaces qui pourraient automatiser l'étiquetage tout en produisant de faibles taux d'erreur. En effet, le modèle peut actuellement s'appuyer sur la cohérence anatomique humaine pour masquer les lacunes de l'ensemble de données sur lequel il a été formé.
Une raison possible pour laquelle il ne peut pas compter sur cela, récemment proposé au Stable Diffusion Discord, est que le modèle pourrait devenir confus quant au nombre correct de doigts qu'une main humaine (réaliste) devrait avoir parce que la base de données dérivée de LAION qui l'alimente comporte des personnages de dessins animés qui peuvent avoir moins de doigts (ce qui est en soi un raccourci économique).

Deux des responsables potentiels du syndrome du « doigt manquant » dans les modèles Stable Diffusion et similaires. Ci-dessous, des exemples de mains dessinées issues de l'ensemble de données LAION-aesthetics alimentant Stable Diffusion. Source : https://www.youtube.com/watch?v=0QZFQ3gbd6I
Si cela est vrai, alors la seule solution évidente est de recycler le modèle, en excluant le contenu humain non réaliste, en veillant à ce que les véritables cas d'omission (c'est-à-dire les amputés) soient correctement étiquetés comme des exceptions. Du seul point de vue de la conservation des données, ce serait tout un défi, en particulier pour les efforts communautaires qui manquent de ressources.
La deuxième approche consisterait à appliquer des filtres qui excluent un tel contenu (c'est-à-dire « main avec trois/cinq doigts ») de la manifestation au moment du rendu, de la même manière qu'OpenAI l'a fait, dans une certaine mesure, filtré GPT-3 et DALL-E2, afin que leur sortie puisse être régulée sans avoir besoin de recycler les modèles sources.

Pour Stable Diffusion, la distinction sémantique entre les doigts et même les membres peut devenir horriblement floue, rappelant le genre de films d'horreur « body horror » des années 1980, notamment ceux de David Cronenberg. Source : https://old.reddit.com/r/StableDiffusion/comments/x6htf6/a_study_of_stable_diffusions_strange_relationship/
Cependant, encore une fois, cela nécessiterait des étiquettes qui pourraient ne pas exister sur toutes les images concernées, nous laissant avec le même défi logistique et budgétaire.
On pourrait avancer qu'il reste deux voies à suivre : jeter plus de données sur le problème et appliquer des systèmes d'interprétation tiers qui peuvent intervenir lorsque des erreurs physiques du type décrit ici sont présentées à l'utilisateur final (à tout le moins, cette dernière option donnerait à OpenAI une méthode pour fournir des remboursements pour les rendus « d'horreur corporelle », si l'entreprise était motivée à le faire).
3 : Personnalisation
L'une des possibilités les plus intéressantes pour l'avenir de Stable Diffusion est la perspective d'utilisateurs ou d'organisations développant des systèmes révisés ; modifications qui permettent au contenu en dehors de la sphère LAION pré-entraînée d'être intégré dans le système - idéalement sans les dépenses ingouvernables de former à nouveau l'ensemble du modèle, ou le risque encouru lors de la formation d'un grand volume d'images nouvelles à un existant, mature et capable modèle.
Par analogie : si deux élèves moins doués rejoignent une classe avancée de trente élèves, soit ils assimileront et rattraperont leur retard, soit ils échoueront en tant qu'élèves atypiques ; dans les deux cas, la performance moyenne de la classe ne sera probablement pas affectée. En revanche, si 15 élèves moins doués rejoignent la classe, la courbe de notation de l'ensemble de la classe risque d'en pâtir.
De même, le réseau synergique et assez délicat de relations qui se construit sur une formation de modèle soutenue et coûteuse peut être compromis, dans certains cas effectivement détruit, par de nouvelles données excessives, ce qui réduit la qualité de sortie du modèle à tous les niveaux.
L'argument en faveur de cette démarche est principalement celui qui consiste à détourner complètement la compréhension conceptuelle des relations et des choses du modèle et à l'approprier pour la production exclusive de contenu similaire au matériel supplémentaire que vous avez ajouté.
Ainsi, former 500,000 XNUMX Simpsons cadres dans un point de contrôle de diffusion stable existant est susceptible, éventuellement, de vous obtenir une meilleure Simpsons simulateur que la version originale aurait pu offrir, en supposant que suffisamment de relations sémantiques larges survivent au processus (c'est-à-dire Homer Simpson mange un hot-dog, ce qui peut nécessiter du matériel sur les hot-dogs qui n'était pas dans votre matériel supplémentaire, mais qui existait déjà au point de contrôle), et en supposant que vous ne souhaitiez pas passer soudainement de Simpsons contenu à créer paysage fabuleux par Greg Rutkowski – parce que votre modèle post-entraîné a vu son attention massivement détournée et ne sera plus aussi efficace qu'avant pour faire ce genre de choses.
Un exemple notable de ceci est waifu-diffusion, qui a réussi 56,000 XNUMX images animées post-formées dans un point de contrôle de diffusion stable terminé et entraîné. C'est une perspective difficile pour un amateur, cependant, car le modèle nécessite un minimum exorbitant de 30 Go de VRAM, bien au-delà de ce qui sera probablement disponible pour le grand public dans les prochaines versions de la série 40XX de NVIDIA.

La formation de contenu personnalisé en diffusion stable via waifu-diffusion : le modèle a pris deux semaines de post-formation afin de produire ce niveau d'illustration. Les six images sur la gauche montrent la progression du modèle, au fur et à mesure de la formation, dans la création d'une sortie cohérente avec le sujet basée sur les nouvelles données de formation. Source : https://gigazine.net/gsc_news/en/20220121-how-waifu-labs-create/
De nombreux efforts pourraient être consacrés à de telles « forks » de points de contrôle de diffusion stable, mais la dette technique pourrait les freiner. Les développeurs du Discord officiel ont déjà indiqué que les versions ultérieures des points de contrôle ne seront pas nécessairement rétrocompatibles, même avec une logique rapide qui aurait pu fonctionner avec une version précédente, car leur principal intérêt est d'obtenir le meilleur modèle possible, plutôt que de prendre en charge les applications et processus hérités.
Par conséquent, une entreprise ou un individu qui décide de se diversifier d'un point de contrôle vers un produit commercial n'a en réalité aucun moyen de revenir en arrière ; sa version du modèle est, à ce stade, un « hard fork » et ne pourra pas tirer profit en amont des versions ultérieures de stability.ai, ce qui représente un engagement considérable.
L'espoir actuel et plus grand de personnalisation de Stable Diffusion est Inversion textuelle, où l'utilisateur s'entraîne dans une petite poignée de CLIP-images alignées.

Fruit d'une collaboration entre l'Université de Tel Aviv et NVIDIA, l'inversion textuelle permet la formation d'entités discrètes et nouvelles, sans détruire les capacités du modèle source. Source : https://textual-inversion.github.io/
La principale limitation apparente de l'inversion textuelle est qu'un très petit nombre d'images est recommandé - aussi peu que cinq. Cela produit effectivement une entité limitée qui peut être plus utile pour les tâches de transfert de style plutôt que pour l'insertion d'objets photoréalistes.
Néanmoins, des expériences sont actuellement en cours dans les différents Discords de Diffusion Stable qui utilisent un nombre beaucoup plus élevé d'images d'entraînement, et il reste à voir à quel point la méthode pourrait s'avérer productive. Encore une fois, la technique nécessite beaucoup de VRAM, de temps et de patience.
En raison de ces facteurs limitatifs, nous devrons peut-être attendre un certain temps avant de voir certaines des expériences d'inversion textuelle les plus sophistiquées des passionnés de Stable Diffusion - et de savoir si cette approche peut ou non « vous mettre dans l'image » d'une manière qui semble meilleure qu'un copier-coller Photoshop, tout en conservant la fonctionnalité étonnante des points de contrôle officiels.
Première publication le 6 septembre 2022.












