Santé
Détermination de l’ivresse avec l’analyse d’apprentissage automatique des yeux
Les chercheurs d’Allemagne et du Chili ont développé un nouveau cadre d’apprentissage automatique capable d’évaluer si une personne est ivre, sur la base d’images proches de l’infrarouge de leurs yeux.
Les recherches visent à développer des systèmes de « fitness pour le devoir » en temps réel capables d’évaluer la préparation d’un individu à effectuer des tâches critiques telles que la conduite ou l’exploitation de machines, et utilisent un détecteur d’objets nouveau et formé à partir de zéro qui peut individuer les composants de l’œil d’un sujet à partir d’une seule image et les évaluer par rapport à une base de données qui comprend des images d’yeux ivres et non ivres.

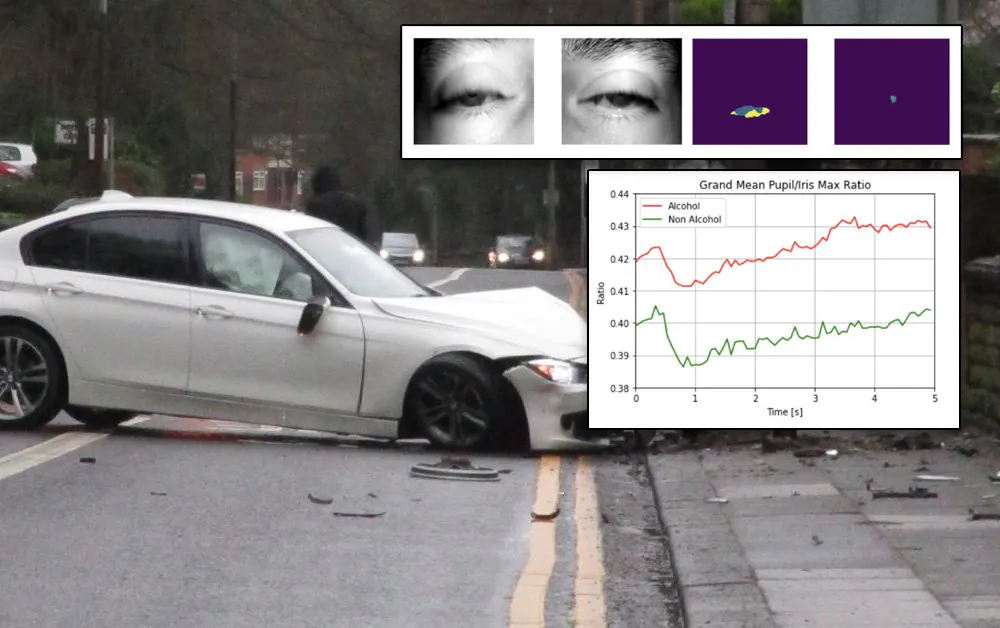
You Only Look Once (YOLO) individue les yeux du sujet, après quoi le cadre sépare les instances et effectue une segmentation pour diviser l’image de l’œil en ses parties constituantes. Source : https://arxiv.org/pdf/2106.15828.pdf
Initialement, le système capture et individue une image de chaque œil avec le cadre de détection d’objets You-Only-Look-Once (YOLO). Après cela, deux réseaux optimisés sont utilisés pour diviser les images de l’œil en régions sémantiques – le réseau d’attention Criss Cross (CCNet) publié en 2020 par l’Université des sciences et de la technologie de Huazhong, et l’algorithme de segmentation DenseNet10, également développé par plusieurs des chercheurs de la nouvelle étude au Chili.

Segmentation obtenue à partir d’images d’yeux proches de l’infrarouge. Source : https://www.researchgate.net/publication/346903035_Towards_an_Efficient_Segmentation_Algorithm_for_Near-Infrared_Eyes_Images#pf6
Les deux algorithmes n’utilisent que 122 514 et 210 732 paramètres respectivement – une dépense frugale, en comparaison avec certains des plus grands ensembles de fonctionnalités dans des modèles similaires, et allant à l’encontre de la tendance générale vers des volumes de données plus importants dans les cadres d’apprentissage automatique.
Base de données des ivres
Pour éclairer le cadre d’apprentissage automatique, les chercheurs ont développé une base de données originale comprenant 266 sujets ivres et 765 sujets sobres.

Exemples de la base de données obtenue de sujets ivres et non ivres.
Les sujets devaient se tenir debout devant deux caméras Iritech d’origine, la gamme Gemini/Venus, pour faire face à l’appareil, et être enregistrés sobres. Après cela, ils ont consommé 200 ml d’alcool, et ont été capturés à intervalles de 15 minutes à mesure que leurs niveaux d’alcool dans le sang augmentaient, jusqu’à la dernière séance 60 minutes après la consommation de l’alcool.
Cela a produit 21 309 images, qui ont ensuite été annotées à l’aide de la bibliothèque Python imgaug.
Préparation des données pour le monde réel
Ce n’était pas un flux de travail hautement automatisé, malgré les outils avancés utilisés – l’étiquetage manuel des images des yeux a été décrit par les chercheurs comme « un processus très exigeant et chronophage », et a duré plus d’un an.
Les données ont été augmentées de manière agressive avec une série de méthodes conçues pour dégrader et mettre au défi le système, en reproduisant les conditions du monde réel, notamment les flocons de neige, le bruit de Poisson (pour simuler la dégradation du capteur à faible lumière), le flou, les éclaboussures et les effets de pluie. En outre, l’utilisation de la capture infrarouge élimine le besoin de conditions de lumière idéales, qui ne peuvent pas être garanties dans les déploiements économiques et pratiques.
Ce travail acharné a finalement payé avec un niveau de précision de 98,60 % pour la capture et la segmentation des yeux.

Segmentation de l’iris avec la méthode des moindres carrés.
Test
Le cadre de segmentation a été testé avec cinq plateformes : Osiris, DeepVOG, DenseNet10 (voir ci-dessus), CCNet (voir ci-dessus), et Grand-Mean. Dans tous les cas, l’analyse a démontré des résultats réussis pour la corrélation de la dilatation de la pupille au niveau d’ivresse, bien qu’une approche hybride utilisant DenseNet et CCNet ait prouvé être la plus efficace.
Les chercheurs prévoient que leur travail pourra éventuellement être intégré dans un capteur d’iris NIR standard, et notent que l’effort herculéen de production de la base de données d’yeux ivres contributive est un avantage probable pour ce secteur de la recherche biométrique.
Test d’ivresse pour les consommateurs et l’industrie par évaluation des yeux
La nouvelle recherche s’appuie sur une littérature antérieure notable, notamment un article de 2015 de chercheurs du Brésil et des États-Unis, qui a proposé une méthode systématique et rationnalisée d’évaluation de l’ivresse à partir de la réponse pupillaire. Les chercheurs de cet article ont observé que l’alcool réduit l’efficacité cérébrale et altère la vision nocturne d’un facteur de 25 %, et le temps de réaction de 30 %, avec des niveaux de gravité variables selon les niveaux de tolérance individuels.

Source : https://pixellab.group/publication/2015/pinheiro2015/pinheiro2015.pdf
Le problème principal pour la diffusion de ces technologies est la portabilité. Dès 2003, la société de recherche britannique Hampton Knight a proposé un système d’évaluation de l’ivresse par analyse des yeux – bien qu’il coûtait 10 000 livres sterling à l’époque.
Une étude préliminaire de 2012 menée à New Delhi et aux États-Unis a également exploré la possibilité d’utiliser des techniques d’intelligence artificielle systématiques pour dériver un score d’ivresse à partir d’images oculaires, bien qu’avec moins de succès que la recherche actuelle. Cette étude a également contribué un ensemble de données précieux (IITD Iris Under Alcohol Influence) au corpus de travail dans ce domaine.
Cependant, les innovations récentes dans le calcul de bord et les ressources matérielles d’apprentissage automatique mobile optimisé ouvrent le champ à des applications beaucoup plus mobiles de contrôles préalables à l’activité pour l’ivresse, notamment des capteurs dans les véhicules qui pourraient potentiellement ajouter des contrôles d’iris aux méthodes actuelles qui intéressent le système de détection d’alcool pour la sécurité (DADSS) en cours de développement aux États-Unis – qui jusqu’à présent s’est appuyé sur des capteurs d’alcool cutané et l’évaluation de l’air dans les véhicules pour les vapeurs d’alcool.
Un rapport de 2020 a estimé que l’adoption de technologies de ce type pourrait sauver 11 000 vies par an aux États-Unis seulement.












