Angle d’Anderson
Création d’un modèle de langage de type GPT pour une seule question

Des chercheurs de Chine ont développé une méthode économique pour créer des systèmes de traitement du langage naturel de type GPT-3 tout en évitant les coûts de plus en plus prohibitifs de temps et d’argent liés à la formation de grands volumes de données – une tendance qui menace de reléguer ce secteur de l’IA aux joueurs de FAANG et aux investisseurs de haut niveau.
Le cadre proposé s’appelle Task-Driven Language Modeling (TLM). Au lieu de former un modèle énorme et complexe sur un vaste corpus de milliards de mots et de milliers d’étiquettes et de classes, le TLM forme un modèle beaucoup plus petit qui incorpore réellement une requête à l’intérieur du modèle.

À gauche, une approche typique de modèles de langage à grande échelle ; à droite, la méthode TLM pour explorer un grand corpus de langage sur une base par sujet ou par question. Source: https://arxiv.org/pdf/2111.04130.pdf
En effet, un algorithme ou un modèle NLP unique est produit pour répondre à une seule question, au lieu de créer un modèle de langage général énorme et encombrant qui peut répondre à une variété plus large de questions.
Lors des tests du TLM, les chercheurs ont constaté que la nouvelle approche obtient des résultats similaires ou meilleurs que les modèles de langage pré-entraînés tels que RoBERTa-Large, et les systèmes NLP à grande échelle tels que GPT-3 d’OpenAI, le commutateur de paramètres TRILLION de Google Modèle, HyperClover de la Corée , Jurassic 1 d’AI21 Labs , et Megatron-Turing NLG 530B de Microsoft .
Dans les essais du TLM sur huit ensembles de données de classification sur quatre domaines, les auteurs ont également constaté que le système réduit les opérations de pointage flottant (FLOPs) nécessaires pour la formation de deux ordres de grandeur. Les chercheurs espèrent que le TLM peut « démocratiser » un secteur qui devient de plus en plus élite, avec des modèles NLP si grands qu’ils ne peuvent pas réaliste-ment être installés localement, et qui se trouvent, dans le cas de GPT-3, derrière les API coûteuses et à accès limité d’OpenAI et, désormais, de Microsoft Azure.
Les auteurs déclarent que la réduction du temps de formation de deux ordres de grandeur réduit le coût de formation sur 1 000 GPU pendant une journée à seulement 8 GPU pendant 48 heures.
Le nouveau rapport s’intitule NLP From Scratch Without Large-Scale Pretraining: A Simple and Efficient Framework, et provient de trois chercheurs de l’Université Tsinghua à Pékin, et d’un chercheur de l’entreprise de développement d’IA basée en Chine, Recurrent AI, Inc.
Réponses inabordables
Le coût de la formation de modèles de langage efficaces et polyvalents devient de plus en plus caractérisé comme une sorte de « limite thermique » à la mesure dans laquelle la NLP performante et précise peut vraiment se diffuser dans la culture.
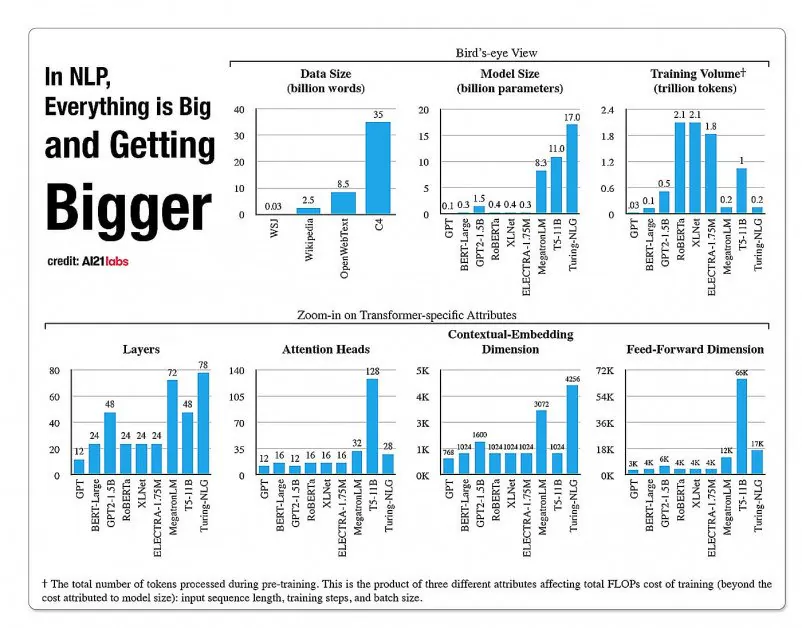
Statistiques sur la croissance des facettes dans les architectures de modèles NLP, à partir d’un rapport de 2020 par A121 Labs. Source: https://arxiv.org/pdf/2004.08900.pdf
En 2019, un chercheur a calculé qu’il en coûte 61 440 $ pour former le modèle XLNet (rapporté à l’époque pour battre BERT dans les tâches NLP) sur 2,5 jours sur 512 cœurs sur 64 appareils, tandis que GPT-3 est estimé à 12 millions de dollars pour la formation – 200 fois le coût de la formation de son prédécesseur, GPT-2 (bien que des réestimations récentes affirment qu’il pourrait être formé maintenant pour un simple 4 600 000 $ sur les GPU cloud les moins chers).
Sous-ensembles de données basés sur les besoins de requête
Au lieu de cela, la nouvelle architecture proposée cherche à dériver des classifications, des étiquettes et des généralisations précises en utilisant une requête comme un filtre pour définir un sous-ensemble d’informations à partir d’un grand corpus de langage qui sera formé, avec la requête, afin de fournir des réponses sur un sujet limité.
Les auteurs déclarent :
‘TLM est motivé par deux idées clés. Premièrement, les humains maîtrisent une tâche en utilisant seulement une petite partie des connaissances mondiales (par exemple, les étudiants n’ont besoin de revoir que quelques chapitres, parmi tous les livres du monde, pour réviser un examen).
‘Nous supposons qu’il y a beaucoup de redondance dans le grand corpus pour une tâche spécifique. Deuxièmement, la formation sur des données étiquetées supervisées est beaucoup plus efficace en termes de données pour les performances en aval que l’optimisation de l’objectif de modélisation de langage sur des données non étiquetées. Sur la base de ces motivations, le TLM utilise les données de tâche comme requêtes pour récupérer un petit sous-ensemble du corpus général. Cela est suivi d’une optimisation conjointe d’un objectif de tâche supervisée et d’un objectif de modélisation de langage en utilisant à la fois les données récupérées et les données de tâche.’
Outre le fait de rendre la formation de modèles NLP efficaces abordables, les auteurs voient un certain nombre d’avantages à l’utilisation de modèles NLP à base de tâches. Tout d’abord, les chercheurs peuvent bénéficier d’une plus grande flexibilité, avec des stratégies personnalisées pour la longueur de séquence, la tokenisation, le réglage des hyperparamètres et les représentations de données.
Les chercheurs prévoient également le développement de systèmes hybrides futurs qui font des compromis entre une formation préalable limitée d’un PLM (qui n’est pas prévue dans la mise en œuvre actuelle) et une plus grande polyvalence et généralisation contre les temps de formation. Ils considèrent le système comme un pas en avant pour le progrès des méthodes de généralisation à zéro tir en domaine.
Tests et résultats
Le TLM a été testé sur des défis de classification dans huit tâches sur quatre domaines – sciences biomédicales, actualités, critiques et informatique. Les tâches ont été divisées en catégories à ressources élevées et à ressources faibles. Les tâches à ressources élevées comprenaient plus de 5 000 données de tâche, telles que AGNews et RCT, entre autres ; les tâches à ressources faibles comprenaient ChemProt et ACL-ARC, ainsi que le dataset de détection d’actualités partisanes.
Les chercheurs ont développé deux ensembles de formation intitulés Corpus-BERT et Corpus-RoBERTa, le dernier étant dix fois plus grand que le premier. Les expériences ont comparé les modèles de langage pré-entraînés généraux BERT (de Google) et RoBERTA (de Facebook) à la nouvelle architecture.
Le document observe que même si le TLM est une méthode générale, et devrait être plus limitée dans son champ d’application et sa portée que les modèles plus larges et plus volumineux de pointe, il est capable de performer près des méthodes de fine-tuning adaptatives de domaine.

Résultats de la comparaison des performances du TLM par rapport aux ensembles basés sur BERT et RoBERTa. Les résultats répertorient un score F1 moyen sur trois échelles de formation différentes, et répertorient le nombre de paramètres, le calcul de formation total (FLOPs) et la taille du corpus de formation.
Les auteurs concluent que le TLM est capable d’obtenir des résultats comparables ou meilleurs que les PLM, avec une réduction substantielle des FLOPs nécessaires, et nécessitant seulement 1/16ème du corpus de formation. Sur les échelles moyennes et grandes, le TLM peut améliorer les performances de 0,59 et 0,24 points en moyenne, tout en réduisant la taille des données de formation de deux ordres de grandeur.
‘Ces résultats confirment que le TLM est très précis et beaucoup plus efficace que les PLM. De plus, le TLM gagne plus d’avantages en efficacité à plus grande échelle. Cela indique que les PLM à plus grande échelle pourraient avoir été formés pour stocker plus de connaissances générales qui ne sont pas utiles pour une tâche spécifique.’












