Intelligence artificielle
Le premier anniversaire de ChatGPT : redéfinir l’avenir de l’interaction avec l’IA

En réfléchissant à la première année de ChatGPT, il est clair que cet outil a considérablement changé le paysage de l’IA. Lancé à la fin de 2022, ChatGPT s’est démarqué par son style conversationnel convivial qui a rendu l’interaction avec l’IA plus ressemblante à une conversation avec une personne qu’à une machine. Cette nouvelle approche a rapidement attiré l’attention du public. Dans les cinq jours suivant sa sortie, ChatGPT avait déjà attiré un million d’utilisateurs. Au début de 2023, ce nombre a gonflé à environ 100 millions d’utilisateurs par mois, et en octobre, la plateforme a attiré environ 1,7 milliard de visites dans le monde. Ces chiffres parlent de sa popularité et de son utilité.
Au cours de la dernière année, les utilisateurs ont trouvé toutes sortes de façons créatives d’utiliser ChatGPT, des tâches simples comme la rédaction d’e-mails et la mise à jour de CV à la création de entreprises prospères. Mais ce n’est pas seulement la façon dont les gens l’utilisent ; la technologie elle-même a grandi et s’est améliorée. Initialement, ChatGPT était un service gratuit offrant des réponses textuelles détaillées. Maintenant, il y a ChatGPT Plus, qui inclut ChatGPT-4. Cette version mise à jour est formée sur plus de données, donne moins de réponses incorrectes et comprend mieux les instructions complexes.
L’une des mises à jour les plus importantes est que ChatGPT peut maintenant interagir de plusieurs manières – il peut écouter, parler et même traiter des images. Cela signifie que vous pouvez lui parler via son application mobile et lui montrer des photos pour obtenir des réponses. Ces changements ont ouvert de nouvelles possibilités pour l’IA et ont changé la façon dont les gens perçoivent et pensent au rôle de l’IA dans leur vie.
De ses débuts en tant que démo technique à son statut actuel de grand joueur dans le monde de la technologie, le parcours de ChatGPT est assez impressionnant. Initialement, il était considéré comme un moyen de tester et d’améliorer la technologie en obtenant des commentaires du public. Mais il est rapidement devenu une partie essentielle du paysage de l’IA. Ce succès montre à quel point il est efficace de peaufiner les grands modèles de langage (LLM) avec un apprentissage supervisé et des commentaires humains. En conséquence, ChatGPT peut gérer une large gamme de questions et de tâches.
La course pour développer les systèmes d’IA les plus capables et les plus polyvalents a conduit à une prolifération de modèles à la fois open-source et propriétaires comme ChatGPT. Comprendre leurs capacités générales nécessite des benchmarks complets sur un large éventail de tâches. Cette section explore ces benchmarks, jetant un éclairage sur la façon dont les différents modèles, y compris ChatGPT, se comparent les uns aux autres.
Évaluation des LLM : Les Benchmarks
- MT-Bench : Ce benchmark teste les capacités de conversation et de suivi d’instructions à plusieurs tours sur huit domaines : écriture, jeu de rôle, extraction d’informations, raisonnement, mathématiques, codage, connaissances STEM et sciences humaines. Des LLM plus solides comme GPT-4 sont utilisés comme évaluateurs.
- AlpacaEval : Basé sur l’ensemble d’évaluation AlpacaFarm, cet évaluateur automatique LLM évalue les modèles par rapport aux réponses de LLM avancés comme GPT-4 et Claude, en calculant le taux de victoire des modèles candidats.
- Open LLM Leaderboard : En utilisant le Language Model Evaluation Harness, ce tableau de bord évalue les LLM sur sept benchmarks clés, notamment des défis de raisonnement et des tests de connaissances générales, dans les paramètres zero-shot et few-shot.
- BIG-bench : Ce benchmark collaboratif couvre plus de 200 tâches de langage nouvelles, allant de sujets divers et de langues. Il vise à sonder les LLM et à prédire leurs capacités futures.
- ChatEval : Un cadre de débat multi-agents qui permet aux équipes de discuter et d’évaluer de manière autonome la qualité des réponses de différents modèles sur des questions ouvertes et des tâches de génération de langage naturel traditionnelles.
Performances comparatives
En termes de benchmarks généraux, les LLM open-source ont montré des progrès remarquables. Llama-2-70B, par exemple, a obtenu des résultats impressionnants, en particulier après avoir été peaufiné avec des données d’instruction. Sa variante, Llama-2-chat-70B, a excellé dans AlpacaEval avec un taux de victoire de 92,66 %, dépassant GPT-3.5-turbo. Cependant, GPT-4 reste le leader avec un taux de victoire de 95,28 %.
Zephyr-7B, un modèle plus petit, a démontré des capacités comparables aux LLM de 70B, en particulier dans AlpacaEval et MT-Bench. Pendant ce temps, WizardLM-70B, peaufiné avec une gamme diversifiée de données d’instruction, a obtenu le score le plus élevé parmi les LLM open-source sur MT-Bench. Cependant, il a toujours été distancé par GPT-3.5-turbo et GPT-4.
Une entrée intéressante, GodziLLa2-70B, a obtenu un score compétitif sur le Open LLM Leaderboard, mettant en évidence le potentiel des modèles expérimentaux combinant des ensembles de données diversifiés. De même, Yi-34B, développé à partir de zéro, s’est démarqué avec des scores comparables à GPT-3.5-turbo et légèrement inférieurs à GPT-4.
UltraLlama, avec son peaufinage sur des données diverses et de haute qualité, a égalé GPT-3.5-turbo dans les benchmarks proposés et a même dépassé dans les domaines des connaissances mondiales et professionnelles.
Augmentation de l’échelle : l’essor des LLM géants
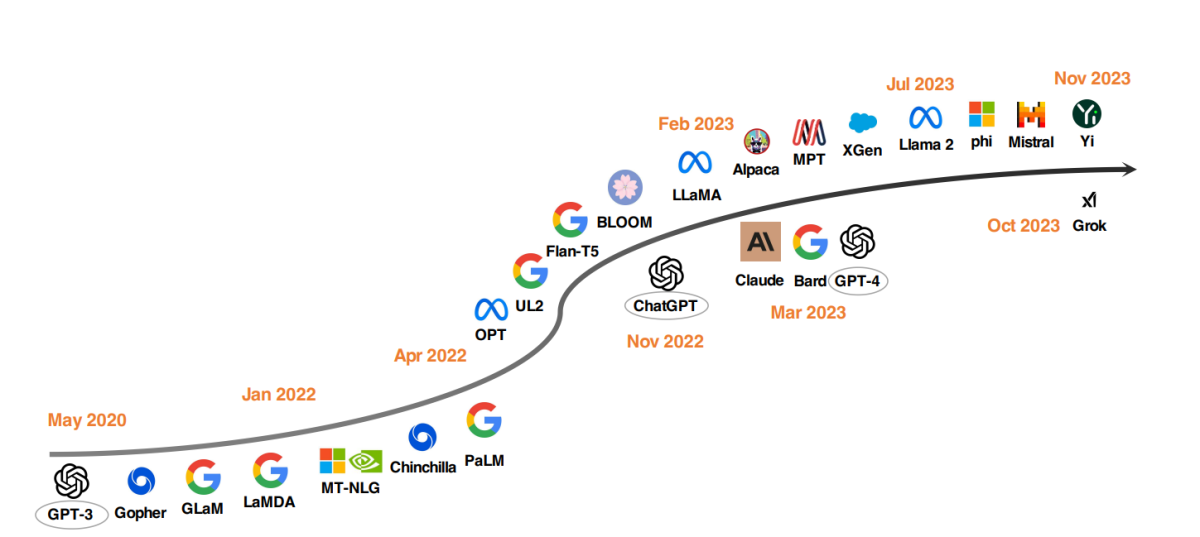
Les principaux modèles LLM depuis 2020
Une tendance notable dans le développement des LLM a été l’augmentation de l’échelle des paramètres de modèle. Des modèles comme Gopher, GLaM, LaMDA, MT-NLG et PaLM ont repoussé les limites, aboutissant à des modèles avec jusqu’à 540 milliards de paramètres. Ces modèles ont montré des capacités exceptionnelles, mais leur nature propriétaire a limité leur application plus large. Cette limitation a suscité l’intérêt pour le développement de LLM open-source, une tendance qui gagne en momentum.
En parallèle avec l’augmentation de la taille des modèles, les chercheurs ont exploré des stratégies alternatives. Au lieu de simplement rendre les modèles plus grands, ils se sont concentrés sur l’amélioration de la pré-formation de modèles plus petits. Des exemples incluent Chinchilla et UL2, qui ont montré que plus n’est pas toujours mieux ; des stratégies plus intelligentes peuvent donner des résultats efficaces. De plus, il y a eu une attention considérable sur le réglage d’instruction des modèles de langage, avec des projets comme FLAN, T0 et Flan-T5 faisant des contributions significatives dans ce domaine.
Le catalyseur ChatGPT
L’introduction de ChatGPT par OpenAI a marqué un tournant dans la recherche en NLP. Pour concurrencer OpenAI, des entreprises comme Google et Anthropic ont lancé leurs propres modèles, Bard et Claude, respectivement. Même si ces modèles montrent des performances comparables à ChatGPT dans de nombreuses tâches, ils sont toujours distancés par le dernier modèle d’OpenAI, GPT-4. Le succès de ces modèles est principalement attribué à l’apprentissage par renforcement à partir de commentaires humains (RLHF), une technique qui reçoit une attention de recherche accrue pour une amélioration future.
Rumeurs et spéculations autour de Q* (Q-Star) d’OpenAI
Des rapports récents suggèrent que les chercheurs d’OpenAI pourraient avoir réalisé une avancée significative dans l’IA avec le développement d’un nouveau modèle appelé Q* (prononcé Q star). Prétendument, Q* a la capacité de réaliser des mathématiques de niveau scolaire primaire, une prouesse qui a suscité des discussions parmi les experts sur son potentiel en tant que jalon vers l’intelligence artificielle générale (AGI). Même si OpenAI n’a pas commenté ces rapports, les capacités présumées de Q* ont généré un grand enthousiasme et des spéculations sur les médias sociaux et parmi les enthousiastes de l’IA.
Le développement de Q* est remarquable car les modèles de langage existants comme ChatGPT et GPT-4, même s’ils sont capables de certaines tâches mathématiques, ne sont pas particulièrement habiles à les gérer de manière fiable. Le défi réside dans le besoin pour les modèles d’IA de ne pas seulement reconnaître des modèles, comme ils le font actuellement à travers l’apprentissage profond et les transformateurs, mais également de raisonner et de comprendre des concepts abstraits. Les mathématiques, servant de référence pour la raison, nécessitent que l’IA planifie et exécute plusieurs étapes, démontrant une compréhension approfondie des concepts abstraits. Cette capacité marquerait un saut significatif dans les capacités de l’IA, potentiellement s’étendant au-delà des mathématiques à d’autres tâches complexes.
Cependant, les experts mettent en garde contre la surestimation de ce développement. Même si un système d’IA qui résout de manière fiable des problèmes mathématiques serait une réalisation impressionnante, cela ne signifie pas nécessairement l’avènement de l’IA superintelligente ou de l’AGI. La recherche actuelle en IA, y compris les efforts d’OpenAI, s’est concentrée sur des problèmes élémentaires, avec des degrés variables de succès dans des tâches plus complexes.
Les applications potentielles d’avancées comme Q* sont vastes, allant de la tutorielle personnalisée à l’aide dans la recherche scientifique et l’ingénierie. Cependant, il est important de gérer les attentes et de reconnaître les limites et les préoccupations de sécurité associées à de telles avancées. Les préoccupations concernant les risques existentiels de l’IA, une crainte fondamentale d’OpenAI, restent pertinentes, en particulier à mesure que les systèmes d’IA commencent à interagir davantage avec le monde réel.
Le mouvement LLM open-source
Pour stimuler la recherche sur les LLM open-source, Meta a publié la série de modèles Llama, déclenchant une vague de nouveaux développements basés sur Llama. Cela inclut des modèles peaufinés avec des données d’instruction, tels que Alpaca, Vicuna, Lima et WizardLM. La recherche se divise également pour améliorer les capacités d’agent, le raisonnement logique et la modélisation de contexte long dans le cadre basé sur Llama.
De plus, il y a une tendance croissante à développer des LLM puissants à partir de zéro, avec des projets comme MPT, Falcon, XGen, Phi, Baichuan, Mistral, Grok et Yi. Ces efforts reflètent un engagement à démocratiser les capacités des LLM propriétaires, rendant les outils d’IA avancés plus accessibles et efficaces.
L’impact de ChatGPT et des modèles open-source sur la santé
Nous sommes en train de regarder un avenir où les LLM aideront à la prise de notes cliniques, au remplissage de formulaires pour les remboursements et à soutenir les médecins dans la planification du diagnostic et du traitement. Cela a attiré l’attention à la fois des géants de la technologie et des institutions de soins de santé.
Les discussions de Microsoft avec Epic, un fournisseur de logiciels de dossiers médicaux électroniques de premier plan, signalent l’intégration de LLM dans les soins de santé. Des initiatives sont déjà en place à UC San Diego Health et au Centre médical de l’Université de Stanford. De même, les partenariats de Google avec Mayo Clinic et le lancement par Amazon Web Services de HealthScribe, un service de documentation clinique basé sur l’IA, marquent des progrès importants dans cette direction.
Cependant, ces déploiements rapides soulèvent des inquiétudes quant à l’abandon du contrôle de la médecine aux intérêts corporatifs. La nature propriétaire de ces LLM rend difficile leur évaluation. Leur modification ou leur abandon pour des raisons de rentabilité pourrait compromettre les soins aux patients, la confidentialité et la sécurité.
Le besoin urgent est d’une approche ouverte et inclusive du développement de LLM dans les soins de santé. Les institutions de soins de santé, les chercheurs, les cliniciens et les patients doivent collaborer à l’échelle mondiale pour construire des LLM open-source pour les soins de santé. Cette approche, similaire à la Trillion Parameter Consortium, permettrait de mettre en commun les ressources computationnelles, financières et l’expertise.












