Intelligence Artificielle
Premier anniversaire de ChatGPT : remodeler l'avenir de l'interaction avec l'IA

En repensant à la première année de ChatGPT, il est clair que cet outil a profondément transformé le paysage de l'IA. Lancé fin 2022, ChatGPT s'est distingué par son style convivial et conversationnel, qui donnait l'impression d'interagir avec l'IA davantage qu'avec une personne. Cette nouvelle approche a rapidement séduit le public. Cinq jours seulement après son lancement, ChatGPT avait déjà attiré un million d'utilisateurs. Début 2023, ce chiffre a atteint environ 100 millions d'utilisateurs mensuels, et en octobre, la plateforme enregistrait environ 1.7 milliard de visites dans le monde. Ces chiffres en disent long sur sa popularité et son utilité.
Au cours de l'année écoulée, les utilisateurs ont trouvé de nombreuses façons créatives d'utiliser ChatGPT, des tâches simples comme la rédaction d'e-mails et la mise à jour de CV à la création d'entreprises prospères. Mais ce n'est pas seulement une question d'utilisation : la technologie elle-même a évolué et s'est améliorée. Initialement, ChatGPT était un service gratuit proposant des réponses textuelles détaillées. Il existe désormais ChatGPT Plus, qui inclut ChatGPT-4. Cette version mise à jour est entraînée sur davantage de données, donne moins de mauvaises réponses et comprend mieux les instructions complexes.
L'une des principales nouveautés est que ChatGPT peut désormais interagir de multiples façons : il peut écouter, parler et même traiter des images. Vous pouvez ainsi lui parler via son application mobile et lui montrer des images pour obtenir des réponses. Ces changements ont ouvert de nouvelles perspectives pour l'IA et ont transformé la perception que nous avons de son rôle dans nos vies.
Depuis ses débuts comme simple démonstration technologique jusqu'à son statut actuel d'acteur majeur du monde technologique, le parcours de ChatGPT est impressionnant. Initialement perçu comme un moyen de tester et d'améliorer les technologies grâce aux retours du public, il est rapidement devenu un élément essentiel du paysage de l'IA. Ce succès démontre l'efficacité du perfectionnement des grands modèles linguistiques (LLM) grâce à l'apprentissage supervisé et aux retours humains. ChatGPT peut ainsi traiter un large éventail de questions et de tâches.
La course au développement des systèmes d’IA les plus performants et les plus polyvalents a conduit à une prolifération de modèles à la fois open source et propriétaires comme ChatGPT. Comprendre leurs capacités générales nécessite des références complètes sur un large éventail de tâches. Cette section explore ces références, mettant en lumière la manière dont les différents modèles, y compris ChatGPT, se comparent les uns aux autres.
Évaluation des LLM : les repères
- Banc MT: Ce benchmark teste les capacités de conversation à plusieurs tours et de suivi d'instructions dans huit domaines : écriture, jeu de rôle, extraction d'informations, raisonnement, mathématiques, codage, connaissances STEM et sciences humaines/sociales. Des LLM plus forts comme GPT-4 sont utilisés comme évaluateurs.
- AlpagaEval: Basé sur l'ensemble d'évaluation AlpacaFarm, cet évaluateur automatique basé sur LLM compare les modèles aux réponses de LLM avancés comme GPT-4 et Claude, calculant le taux de victoire des modèles candidats.
- Classement ouvert LLM: Utilisant le harnais d'évaluation du modèle linguistique, ce classement évalue les LLM sur sept critères clés, y compris les défis de raisonnement et les tests de connaissances générales, dans des contextes de tir zéro et de quelques tirs.
- BIG-banc: Ce benchmark collaboratif couvre plus de 200 nouvelles tâches linguistiques, couvrant un large éventail de sujets et de langues. Il vise à sonder les LLM et à prédire leurs capacités futures.
- ChatEval: Un cadre de débat multi-agents qui permet aux équipes de discuter et d'évaluer de manière autonome la qualité des réponses de différents modèles sur des questions ouvertes et des tâches traditionnelles de génération de langage naturel.
Performances comparatives
En termes de références générales, les LLM open source ont montré des progrès remarquables. Lama-2-70B, par exemple, a obtenu des résultats impressionnants, en particulier après avoir été affiné avec les données d'instruction. Sa variante, Llama-2-chat-70B, a excellé dans AlpacaEval avec un taux de victoire de 92.66 %, dépassant GPT-3.5-turbo. Cependant, GPT-4 reste le favori avec un taux de victoire de 95.28 %.
Zéphyr-7B, un modèle plus petit, a démontré des capacités comparables à celles des LLM 70B plus grands, en particulier dans AlpacaEval et MT-Bench. Pendant ce temps, WizardLM-70B, affiné avec une gamme diversifiée de données d'instructions, a obtenu le score le plus élevé parmi les LLM open source sur MT-Bench. Cependant, il reste à la traîne par rapport à GPT-3.5-turbo et GPT-4.
Une entrée intéressante, GodziLLa2-70B, a obtenu un score compétitif dans le classement Open LLM, démontrant le potentiel des modèles expérimentaux combinant divers ensembles de données. De même, le Yi-34B, développé de toutes pièces, s'est démarqué avec des scores comparables au GPT-3.5-turbo et à peine derrière le GPT-4.
UltraLlama, grâce à son réglage fin sur des données diverses et de haute qualité, a égalé GPT-3.5-turbo dans ses références proposées et l'a même surpassé dans les domaines des connaissances mondiales et professionnelles.
Mise à l'échelle : l'essor des LLM géants
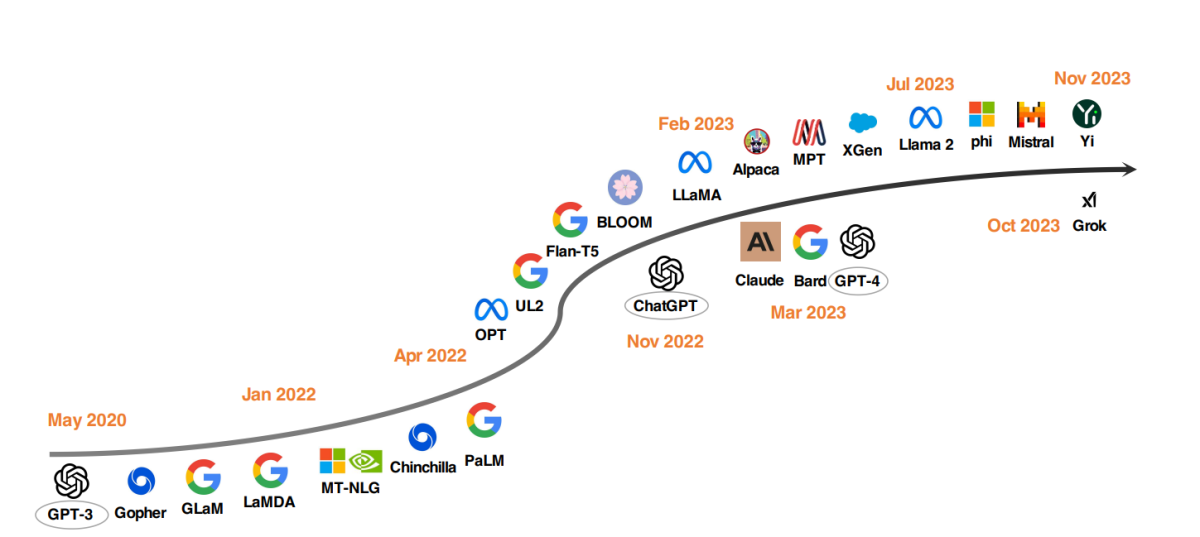
Top modèles LLM depuis 2020
Une tendance notable dans le développement des LLM est l'augmentation de la taille des paramètres des modèles. Des modèles comme Gopher, GLaM, LaMDA, MT-NLG et PaLM ont repoussé les limites, aboutissant à des modèles comptant jusqu'à 540 milliards de paramètres. Ces modèles ont démontré des capacités exceptionnelles, mais leur nature fermée a limité leur application à plus grande échelle. Cette limitation a stimulé l'intérêt pour le développement de LLM open source, une tendance qui prend de l'ampleur.
Parallèlement à l'augmentation de la taille des modèles, les chercheurs ont exploré des stratégies alternatives. Au lieu de se contenter d'agrandir les modèles, ils se sont concentrés sur l'amélioration du pré-entraînement des modèles plus petits. Parmi les exemples, citons Chinchilla et UL2, qui ont montré que plus n'est pas toujours synonyme de mieux ; des stratégies plus intelligentes peuvent également produire des résultats efficaces. Par ailleurs, une attention considérable a été portée à l'optimisation des instructions des modèles linguistiques, des projets comme FLAN, T0 et Flan-T5 apportant des contributions significatives dans ce domaine.
Le catalyseur ChatGPT
L'introduction d'OpenAI ChatGPT a marqué un tournant dans la recherche en PNL. Pour concurrencer OpenAI, des entreprises comme Google et Anthropic ont lancé leurs propres modèles, Bard et Claude respectivement. Bien que ces modèles affichent des performances comparables à ChatGPT dans de nombreuses tâches, ils restent inférieurs au dernier modèle d'OpenAI, GPT-4. Le succès de ces modèles est principalement attribué à l'apprentissage par renforcement à partir du feedback humain (RLHF), une technique qui fait l'objet de recherches croissantes en vue de son amélioration.
Rumeurs et spéculations autour de Q* (Q-Star) d'OpenAI
Des rapports récents suggèrent que les chercheurs d'OpenAI pourraient avoir réalisé des progrès significatifs dans l'IA avec le développement d'un nouveau modèle appelé Q* (prononcé Q star). Apparemment, Q* a la capacité d'effectuer des mathématiques au niveau de l'école primaire, un exploit qui a suscité des discussions parmi les experts sur son potentiel en tant que jalon vers l'intelligence artificielle générale (AGI). Bien qu'OpenAI n'ait pas commenté ces rapports, les rumeurs sur les capacités de Q* ont généré un enthousiasme et des spéculations considérables sur les réseaux sociaux et parmi les passionnés d'IA.
Le développement de Q* est remarquable car les modèles de langage existants comme ChatGPT et GPT-4, bien que capables d'effectuer certaines tâches mathématiques, ne sont pas particulièrement aptes à les gérer de manière fiable. Le défi réside dans la nécessité pour les modèles d’IA non seulement de reconnaître des modèles, comme ils le font actuellement grâce à l’apprentissage profond et aux transformateurs, mais également de raisonner et de comprendre les concepts abstraits. Les mathématiques, étant une référence en matière de raisonnement, nécessitent que l'IA planifie et exécute plusieurs étapes, démontrant une compréhension approfondie des concepts abstraits. Cette capacité marquerait une avancée significative dans les capacités de l’IA, s’étendant potentiellement au-delà des mathématiques à d’autres tâches complexes.
Cependant, les experts mettent en garde contre toute exagération concernant cette avancée. Si un système d'IA capable de résoudre des problèmes mathématiques de manière fiable constituerait une avancée impressionnante, cela ne présage pas nécessairement l'avènement d'une IA superintelligente, ou IAG. Les recherches actuelles en IA, notamment celles menées par OpenAI, se concentrent sur des problèmes élémentaires, avec des degrés de réussite variables dans des tâches plus complexes.
Le potentiel des applications avancées comme Q* est vaste, allant du tutorat personnalisé à l'assistance à la recherche scientifique et à l'ingénierie. Cependant, il est également important de gérer les attentes et d'identifier les limites et les problèmes de sécurité associés à ces avancées. Les inquiétudes concernant les risques existentiels de l'IA, une préoccupation fondamentale d'OpenAI, restent d'actualité, d'autant plus que les systèmes d'IA commencent à interagir davantage avec le monde réel.
Le mouvement LLM Open Source
Pour stimuler la recherche LLM open source, Meta a publié les modèles de la série Llama, déclenchant une vague de nouveaux développements basés sur Llama. Cela inclut des modèles affinés avec des données d'instructions, tels que Alpaca, Vicuna, Lima et WizardLM. La recherche s'oriente également vers l'amélioration des capacités des agents, le raisonnement logique et la modélisation de contexte long au sein du cadre basé sur Llama.
De plus, il existe une tendance croissante à développer des LLM puissants à partir de zéro, avec des projets comme MPT, Falcon, XGen, Phi, Baichuan, Mistral, Grok, et Yi. Ces efforts reflètent un engagement à démocratiser les capacités des LLM à source fermée, rendant les outils d'IA avancés plus accessibles et efficaces.
L'impact de ChatGPT et des modèles Open Source dans les soins de santé
Nous envisageons un avenir où les LLM faciliteront la prise de notes cliniques, le remplissage des formulaires de remboursement et l'accompagnement des médecins dans le diagnostic et la planification des traitements. Ce projet a retenu l'attention des géants de la technologie et des établissements de santé.
Microsoft discussions avec Epic, un fournisseur leader de logiciels de dossiers médicaux électroniques, annonce l'intégration des LLM dans le secteur de la santé. Des initiatives sont déjà en place à UC San Diego Health et au Stanford University Medical Center. De même, Google partenariats avec Mayo Clinic et Amazon Web ServicesLe lancement de HealthScribe, un service de documentation clinique sur l'IA, marque des progrès significatifs dans cette direction.
Cependant, ces déploiements rapides suscitent des inquiétudes quant à la cession du contrôle des médicaments aux intérêts des entreprises. Le caractère propriétaire de ces LLM les rend difficiles à évaluer. Leur éventuelle modification ou interruption pour des raisons de rentabilité pourrait compromettre les soins, la vie privée et la sécurité des patients.
Il est urgent d’adopter une approche ouverte et inclusive du développement du LLM dans le domaine des soins de santé. Les établissements de santé, les chercheurs, les cliniciens et les patients doivent collaborer à l'échelle mondiale pour créer des LLM open source pour les soins de santé. Cette approche, similaire à celle du Trillion Parameter Consortium, permettrait de mettre en commun les ressources informatiques, financières et l'expertise.












