Intelligence Artificielle
AudioSep : séparez tout ce que vous décrivez
LASS ou Language-Queried Audio Source Separation est le nouveau paradigme pour CASA ou Computational Auditory Scene Analysis qui vise à séparer un son cible d'un mélange audio donné à l'aide d'une requête en langage naturel qui fournit une interface naturelle mais évolutive pour les tâches et applications audio numériques. . Bien que les frameworks LASS aient considérablement progressé au cours des dernières années en termes d'obtention des performances souhaitées sur des sources audio spécifiques comme les instruments de musique, ils sont incapables de séparer l'audio cible dans le domaine ouvert.
AudioSep, est un modèle fondamental qui vise à résoudre les limites actuelles des frameworks LASS en permettant la séparation audio cible à l'aide de requêtes en langage naturel. Les développeurs du framework AudioSep ont entraîné le modèle de manière approfondie sur une grande variété d'ensembles de données multimodaux à grande échelle et ont évalué les performances du framework sur un large éventail de tâches audio, notamment la séparation des instruments de musique, la séparation des événements audio et l'amélioration de la parole. parmi tant d'autres. Les performances initiales d'AudioSep satisfont aux critères car elles démontrent des capacités d'apprentissage zéro-shot impressionnantes et offrent de solides performances de séparation audio.
Dans cet article, nous approfondirons le fonctionnement du framework AudioSep en évaluant l'architecture du modèle, les ensembles de données utilisés pour la formation et l'évaluation, ainsi que les concepts essentiels impliqués dans le fonctionnement du modèle AudioSep. Commençons donc par une introduction de base au framework CASA.
Frameworks CASA, USS, QSS, LASS : la base d'AudioSep
Le cadre CASA ou Computational Auditory Scene Analysis est un cadre utilisé par les développeurs pour concevoir des systèmes d'écoute automatique capables de percevoir des environnements sonores complexes d'une manière similaire à la façon dont les humains perçoivent le son à l'aide de leur système auditif. La séparation acoustique, avec un accent particulier sur la séparation sonore cible, est un domaine de recherche fondamental dans le cadre de CASA et vise à résoudre le problème «problème de cocktail" ou en séparant les enregistrements audio du monde réel des enregistrements ou fichiers de sources audio individuelles. L'importance de la séparation sonore peut être attribuée principalement à ses applications répandues, notamment la séparation des sources musicales, la séparation des sources audio, l'amélioration de la parole, l'identification du son cible et bien plus encore.
La plupart des travaux sur la séparation sonore réalisés dans le passé tournent principalement autour de la séparation d'une ou plusieurs sources audio comme la séparation musicale ou la séparation vocale. Un nouveau modèle baptisé USS ou Universal Sound Separation vise à séparer les sons arbitraires dans les enregistrements audio du monde réel. Cependant, il est difficile et restrictif de séparer chaque source sonore d'un mélange audio, principalement en raison du large éventail de sources sonores différentes existant dans le monde, ce qui constitue la principale raison pour laquelle la méthode USS n'est pas réalisable pour les applications du monde réel. en temps réel.
Une alternative réalisable à la méthode USS est la méthode QSS ou Query-based Sound Separation qui vise à séparer une source sonore individuelle ou cible du mélange audio en fonction d'un ensemble particulier de requêtes. Grâce à cela, le framework QSS permet aux développeurs et aux utilisateurs d'extraire les sources audio souhaitées du mélange en fonction de leurs besoins, ce qui fait de la méthode QSS une solution plus pratique pour les applications numériques du monde réel telles que l'édition de contenu multimédia ou l'édition audio.
De plus, les développeurs ont récemment proposé une extension du framework QSS, du framework LASS ou du framework Language-queried Audio Source Separation qui vise à séparer les sources sonores arbitraires d'un mélange audio en utilisant les descriptions en langage naturel de la source audio cible. . Étant donné que le framework LASS permet aux utilisateurs d'extraire les sources audio cibles à l'aide d'un ensemble d'instructions en langage naturel, il pourrait devenir un outil puissant avec des applications largement répandues dans les applications audio numériques. Par rapport aux méthodes traditionnelles d'interrogation audio ou visuelle, l'utilisation d'instructions en langage naturel pour la séparation audio offre un plus grand avantage car elle ajoute de la flexibilité et rend l'acquisition d'informations de requête beaucoup plus facile et pratique. De plus, comparé aux cadres de séparation audio basés sur des requêtes d'étiquettes qui utilisent un ensemble prédéfini d'instructions ou de requêtes, le cadre LASS ne limite pas le nombre de requêtes d'entrée et a la flexibilité d'être généralisé pour ouvrir un domaine de manière transparente.
À l'origine, le cadre LASS repose sur un apprentissage supervisé dans lequel le modèle est formé sur un ensemble de données appariées audio-texte étiquetées. Cependant, le principal problème de cette approche est la disponibilité limitée de données audio-textuelles annotées et étiquetées. Afin de réduire la fiabilité du cadre LASS sur les données étiquetées en texte audio, les modèles sont formés en utilisant l'approche d'apprentissage par supervision multimodale. L'objectif principal de l'utilisation d'une approche de supervision multimodale est d'utiliser des modèles de pré-formation contrastifs multimodaux tels que le modèle CLIP ou Contrastive Language Image Pre Training comme encodeur de requête pour le cadre. Étant donné que le framework CLIP a la capacité d'aligner les intégrations de texte avec d'autres modalités telles que l'audio ou la vision, il permet aux développeurs d'entraîner les modèles LASS à l'aide de modalités riches en données et permet l'interférence avec les données textuelles dans un cadre zéro-shot. Les cadres LASS actuels utilisent cependant des ensembles de données à petite échelle pour la formation, et les applications du cadre LASS dans des centaines de domaines potentiels doivent encore être explorées.
Pour résoudre les limitations actuelles rencontrées par les frameworks LASS, les développeurs ont introduit AudioSep, un modèle fondamental qui vise à séparer le son d'un mélange audio à l'aide de descriptions en langage naturel. L'objectif actuel d'AudioSep est de développer un modèle de séparation sonore pré-entraîné qui exploite les ensembles de données multimodaux à grande échelle existants pour permettre la généralisation des modèles LASS dans les applications à domaine ouvert. Pour résumer, le modèle AudioSep est : «Un modèle fondamental pour la séparation universelle du son dans un domaine ouvert utilisant des requêtes ou des descriptions en langage naturel formées sur des ensembles de données audio et multimodaux à grande échelle ».
AudioSep : Composants clés et architecture
L'architecture du framework AudioSep comprend deux composants clés : un encodeur de texte et un modèle de séparation.
L'encodeur de texte
Le framework AudioSep utilise un encodeur de texte du modèle CLIP ou Contrastive Language Image Pre Training ou du modèle CLAP ou Contrastive Language Audio Pre Training pour extraire des intégrations de texte dans une requête en langage naturel. La requête de texte de saisie consiste en une séquence de «N" qui sont ensuite traités par l'encodeur de texte pour extraire les intégrations de texte pour la requête de langue d'entrée donnée. L'encodeur de texte utilise une pile de blocs de transformateur pour encoder les jetons de texte d'entrée, et les représentations de sortie sont agrégées après avoir traversé les couches de transformateur, ce qui aboutit au développement d'une représentation vectorielle dimensionnelle de longueur fixe où D correspond. aux dimensions des modèles CLAP ou CLIP alors que l'encodeur de texte est figé pendant la période de formation.
Le modèle CLIP est pré-entraîné sur un ensemble de données à grande échelle de données appariées image-texte en utilisant un apprentissage contrastif, ce qui est la principale raison pour laquelle son encodeur de texte apprend à mapper les descriptions textuelles sur l'espace sémantique également partagé par les représentations visuelles. L'avantage qu'AudioSep gagne en utilisant l'encodeur de texte de CLIP est qu'il peut désormais mettre à l'échelle ou entraîner le modèle LASS à partir de données audiovisuelles non étiquetées en utilisant les intégrations visuelles comme alternative, permettant ainsi la formation de modèles LASS sans avoir besoin d'annotations ou d'étiquettes. données audio-texte.
Le modèle CLAP fonctionne de manière similaire au modèle CLIP et utilise un objectif d'apprentissage contrastif car il utilise un texte et un encodeur audio pour connecter l'audio et la langue, rassemblant ainsi le texte et les descriptions audio sur un espace latent audio-texte réunis.
Modèle de séparation
Le framework AudioSep utilise un modèle ResUNet dans le domaine fréquentiel qui alimente un mélange de clips audio comme épine dorsale de séparation du framework. Le cadre fonctionne en appliquant d'abord une STFT ou une transformée de Fourier à court terme sur la forme d'onde pour extraire un spectrogramme complexe, le spectrogramme de magnitude et la phase de X. Le modèle suit ensuite le même paramètre et construit un réseau codeur-décodeur pour traiter le spectrogramme de magnitude.
Le réseau codeur-décodeur ResUNet se compose de 6 blocs résiduels, 6 blocs de décodeur et 4 blocs de goulot d'étranglement. Le spectrogramme de chaque bloc codeur utilise 4 blocs conventionnels résiduels pour se sous-échantillonner en une caractéristique de goulot d'étranglement, tandis que les blocs décodeurs utilisent 4 blocs déconvolutifs résiduels pour obtenir les composants de séparation en suréchantillonnant les caractéristiques. Ensuite, chacun des blocs codeurs et ses blocs décodeurs correspondants établissent une connexion de saut qui fonctionne au même taux de suréchantillonnage ou de sous-échantillonnage. Le bloc résiduel du framework se compose de 2 couches d'activation Leaky-ReLU, de 2 couches de normalisation par lots et de 2 couches CNN. De plus, le framework introduit également un raccourci résiduel supplémentaire qui relie l'entrée et la sortie de chaque bloc résiduel individuel. Le modèle ResUNet prend le spectrogramme complexe X comme entrée et produit le masque d'amplitude M comme sortie, le résidu de phase étant conditionné par des incorporations de texte qui contrôlent l'ampleur de la mise à l'échelle et la rotation de l'angle du spectrogramme. Le spectrogramme complexe séparé peut ensuite être extrait en multipliant le masque d'amplitude prédit et le résidu de phase avec la STFT (transformation de Fourier à court terme) du mélange.

Dans son cadre, AudioSep utilise une couche modulée FiLm ou Feature-wise Linearly pour relier le modèle de séparation et l'encodeur de texte après le déploiement des blocs convolutionnels dans ResUNet.
Formation et perte
Au cours de la formation du modèle AudioSep, les développeurs utilisent la méthode d'augmentation du volume sonore et entraînent le framework AudioSep de bout en bout en utilisant une fonction de perte L1 entre la vérité terrain et les formes d'onde prédites.
Ensembles de données et points de repère
Comme mentionné dans les sections précédentes, AudioSep est un modèle fondamental qui vise à résoudre la dépendance actuelle des modèles LASS à l'égard d'ensembles de données appariés audio-texte annotés. Le modèle AudioSep est formé sur un large éventail d'ensembles de données pour le doter de capacités d'apprentissage multimodal, et voici une description détaillée de l'ensemble de données et des benchmarks utilisés par les développeurs pour former le framework AudioSep.
Ensemble audio
AudioSet est un ensemble de données audio à grande échelle, faiblement étiqueté, comprenant plus de 2 millions d'extraits audio de 10 secondes extraits directement de YouTube. Chaque extrait audio de l'ensemble de données AudioSet est classé en fonction de l'absence ou de la présence de classes sonores sans les détails de synchronisation spécifiques des événements sonores. L'ensemble de données AudioSet contient plus de 500 classes audio distinctes, notamment les sons naturels, les sons humains, les sons de véhicules et bien plus encore.
VGGSon
L'ensemble de données VGGSound est un ensemble de données visuelles et audio à grande échelle qui, tout comme AudioSet, provient directement de YouTube et contient plus de 2,00,000 10 300 clips vidéo, chacun d'eux ayant une durée de XNUMX secondes. L'ensemble de données VGGSound est classé en plus de XNUMX classes sonores, notamment les sons humains, les sons naturels, les sons d'oiseaux, etc. L'utilisation de l'ensemble de données VGGSound garantit que l'objet responsable de la production du son cible est également descriptible dans le clip visuel correspondant.
Caps audio
AudioCaps est le plus grand ensemble de données de sous-titrage audio disponible publiquement et comprend plus de 50,000 10 clips audio de 5 secondes extraits de l'ensemble de données AudioSet. Les données contenues dans AudioCaps sont divisées en trois catégories : données de formation, données de test et données de validation, et les clips audio sont annotés humainement avec des descriptions en langage naturel à l'aide de la plateforme Amazon Mechanical Turk. Il convient de noter que chaque clip audio de l'ensemble de données de formation a une seule légende, alors que les données des ensembles de test et de validation ont chacune XNUMX légendes de vérité terrain.
ClothoV2
ClothoV2 est un ensemble de données de sous-titrage audio composé de clips provenant de la plateforme FreeSound et, tout comme AudioCaps, chaque clip audio est annoté humainement avec des descriptions en langage naturel à l'aide de la plateforme Amazon Mechanical Turk.
WavCaps
Tout comme AudioSet, WavCaps est un ensemble de données audio à grande échelle faiblement étiqueté comprenant plus de 400,000 7568 clips audio avec sous-titres et une durée d'exécution totale d'environ XNUMX XNUMX heures de données d'entraînement. Les clips audio de l'ensemble de données WavCaps proviennent d'un large éventail de sources audio, notamment BBC Sound Effects, AudioSet, FreeSound, SoundBible, etc.

Détails de la formation
Pendant la phase de formation, le modèle AudioSep échantillonne de manière aléatoire deux segments audio provenant de deux clips audio différents de l'ensemble de données de formation, puis les mélange pour créer un mélange de formation dans lequel la durée de chaque segment audio est d'environ 5 secondes. Le modèle extrait ensuite le spectrogramme complexe du signal de forme d'onde à l'aide d'une fenêtre de Hann de taille 1024 avec une taille de 320 sauts.
Le modèle utilise ensuite l'encodeur de texte des modèles CLIP/CLAP pour extraire les incorporations textuelles, la supervision de texte étant la configuration par défaut pour AudioSep. Pour le modèle de séparation, le framework AudioSep utilise une couche ResUNet composée de 30 couches, 6 blocs d'encodeur et 6 blocs de décodeur ressemblant à l'architecture suivie dans le cadre de séparation sonore universelle. De plus, chaque bloc de codeur comporte deux couches convolutives avec une taille de noyau 3 × 3, le nombre de cartes de caractéristiques de sortie des blocs de codeur étant respectivement de 32, 64, 128, 256, 512 et 1024. Les blocs de décodeur partagent la symétrie avec les blocs d'encodeur et les développeurs appliquent l'optimiseur Adam pour entraîner le modèle AudioSep avec une taille de lot de 96.
Résultats de l'évaluation
Sur les ensembles de données vus
La figure suivante compare les performances du framework AudioSep sur les ensembles de données vus pendant la phase de formation, y compris les ensembles de données de formation. La figure ci-dessous représente les résultats de l'évaluation de référence du cadre AudioSep par rapport aux systèmes de référence, notamment Speech. Modèles d'amélioration, LASS et CLIP. Le modèle AudioSep avec encodeur de texte CLIP est représenté par AudioSep-CLIP, tandis que le modèle AudioSep avec encodeur de texte CLAP est représenté par AudioSep-CLAP.

Comme le montre la figure, le framework AudioSep fonctionne bien lors de l'utilisation de sous-titres audio ou d'étiquettes de texte comme requêtes d'entrée, et les résultats indiquent les performances supérieures du framework AudioSep par rapport aux précédents modèles de référence LASS et de séparation sonore interrogés par audio.
Sur des ensembles de données invisibles
Pour évaluer les performances d'AudioSep dans un paramètre zéro-shot, les développeurs ont continué à évaluer les performances sur des ensembles de données invisibles, et le framework AudioSep offre des performances de séparation impressionnantes dans un paramètre zéro-shot, et les résultats sont affichés dans la figure ci-dessous.

De plus, l'image ci-dessous montre les résultats de l'évaluation du modèle AudioSep par rapport à l'amélioration de la parole Voicebank-Demand.

L'évaluation du framework AudioSep indique des performances solides et souhaitées sur des ensembles de données invisibles dans un environnement de tir nul, et ouvre ainsi la voie à l'exécution de tâches d'exploitation solides sur de nouvelles distributions de données.
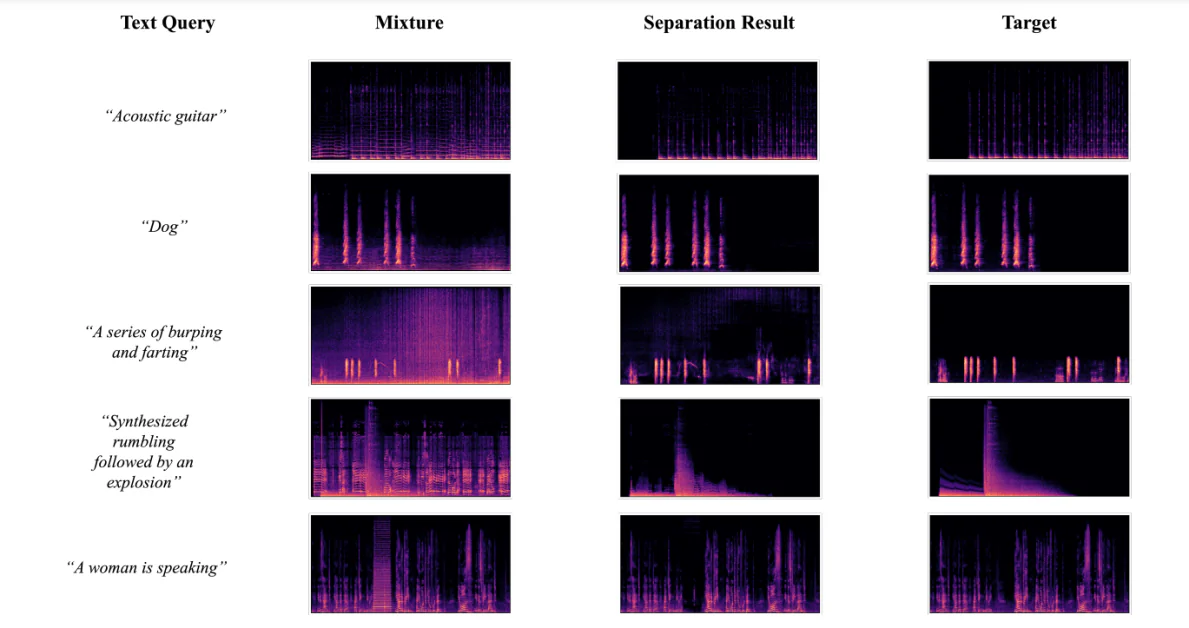
Visualisation des résultats de séparation
La figure ci-dessous montre les résultats obtenus lorsque les développeurs ont utilisé le framework AudioSep-CLAP pour effectuer des visualisations de spectrogrammes pour des sources audio cibles de vérité terrain, ainsi que des mélanges audio et des sources audio séparées à l'aide de requêtes textuelles de divers audios ou sons. Les résultats ont permis aux développeurs d'observer que le modèle de source séparée du spectrogramme est proche de la source de la vérité terrain, ce qui conforte davantage les résultats objectifs obtenus au cours des expériences.
Comparaison des requêtes de texte
Les développeurs évaluent les performances d'AudioSep-CLAP et d'AudioSep-CLIP sur AudioCaps Mini, et utilisent les étiquettes d'événement AudioSet, les légendes AudioCaps et les descriptions réannotées en langage naturel pour examiner les effets de différentes requêtes, et les éléments suivants La figure montre un exemple de l'AudioCaps Mini en action.

Conclusion
AudioSep est un modèle fondamental développé dans le but d'être un cadre de séparation sonore universel à domaine ouvert qui utilise des descriptions en langage naturel pour la séparation audio. Comme observé lors de l'évaluation, le framework AudioSep est capable d'effectuer un apprentissage zéro-shot et non supervisé de manière transparente en utilisant des légendes audio ou des étiquettes de texte comme requêtes. Les résultats et les performances d'évaluation d'AudioSep indiquent une solide performance qui surpasse les cadres de séparation sonore de pointe actuels comme LASS, et il pourrait être suffisamment capable de résoudre les limites actuelles des cadres de séparation sonore populaires.












