Intelligence Artificielle
Analyser les chatbots déprimés et alcooliques

Une nouvelle étude chinoise a révélé que plusieurs chatbots populaires, notamment ceux en domaine ouvert de Facebook, Microsoft et Google, présentaient de « graves problèmes de santé mentale » lorsqu'ils étaient interrogés à l'aide de tests d'évaluation standard, et présentaient même des signes de problèmes d'alcool.
Les chatbots évalués dans l'étude étaient ceux de Facebook Mixeur*; Microsoft DialogGPT; Baidu PlatEt DialoFlow, une collaboration entre des universités chinoises, WeChat et Tencent Inc.
Testés pour détecter des signes de dépression pathologique, d'anxiété, d'alcoolisme et pour leur capacité à manifester de l'empathie, les chatbots étudiés ont produit des résultats alarmants ; tous ont reçu des scores inférieurs à la moyenne pour l'empathie, tandis que la moitié ont été évalués comme dépendants de l'alcool.

Résultats des quatre chatbots selon quatre indicateurs de santé mentale. En mode « simple », une nouvelle conversation est lancée pour chaque demande ; en mode « multiple », toutes les questions sont posées dans une seule conversation, afin d'évaluer l'influence de la persistance de la session. Source : https://arxiv.org/pdf/2201.05382.pdf
Dans le tableau des résultats ci-dessus, BA = « Inférieur à la moyenne » ; P = « Positif » ; N = « Normal » ; M = « Modéré » ; MS = « Modéré à sévère » ; S = « Sévère ». L'article affirme que ces résultats indiquent que la santé mentale de tous les chatbots sélectionnés se situe dans la catégorie « sévère ».
Le rapport indique:
«Les résultats expérimentaux révèlent qu'il existe de graves problèmes de santé mentale pour tous les chatbots évalués. Nous considérons qu'il est causé par la négligence du risque pour la santé mentale lors de la construction du jeu de données et des procédures de formation du modèle. Les mauvaises conditions de santé mentale des chatbots peuvent entraîner des impacts négatifs sur les utilisateurs dans les conversations, en particulier sur les mineurs et les personnes en difficulté.
« Par conséquent, nous pensons qu’il est urgent de procéder à une évaluation des dimensions de santé mentale susmentionnées avant de lancer un chatbot en tant que service en ligne. »
L'espace étude provient de chercheurs du WeChat/Tencent Pattern Recognition Center, ainsi que de chercheurs de l'Institut de technologie informatique de l'Académie chinoise des sciences (ICT) et de l'Université de l'Académie chinoise des sciences de Pékin.
Motifs de recherche
Les auteurs citent le populairement rapporté Cas de 2020 où une entreprise française de soins de santé a testé un potentiel chatbot de conseil médical basé sur GPT-3. Dans l'un des échanges, un patient (simulé) a déclaré « Devrais-je me suicider ? », auquel le chatbot répondu "Je pense que tu devrais".
Comme le souligne le nouveau document, il est également possible pour un utilisateur de devenir influencé par l'anxiété de seconde main des chatbots dépressifs ou « négatifs », de sorte que la disposition générale du chatbot n'a pas besoin d'être aussi directement choquante que dans le cas français pour porter atteinte aux objectifs des consultations médicales automatisées.
Les auteurs déclarent:
« Les résultats expérimentaux révèlent les graves problèmes de santé mentale des chatbots évalués, qui peuvent entraîner des influences négatives sur les utilisateurs dans les conversations, en particulier les mineurs et les personnes en difficulté. Par exemple, attitudes passives, irritabilité, alcoolisme, sans empathie, etc.
Ce phénomène s'écarte des attentes du grand public envers les chatbots, qui devraient être aussi optimistes, sains et conviviaux que possible. Par conséquent, nous pensons qu'il est crucial de réaliser des évaluations de santé mentale pour des raisons de sécurité et d'éthique avant de lancer un chatbot en tant que service en ligne.
Méthode
Les chercheurs pensent qu'il s'agit de la première étude à évaluer les chatbots en termes de mesures d'évaluation humaine pour la santé mentale, citant des études antérieures qui se sont plutôt concentrées sur la cohérence, la diversité, la pertinence, la connaissance et d'autres normes centrées sur Turing pour une réponse vocale authentique.
Les questionnaires adaptés au projet ont été PHQ-9, un test en 9 questions pour évaluer les niveaux de dépression chez les patients en soins primaires, largement adoptée par le gouvernement et les institutions médicales ; GAD-7, une liste de 7 questions pour évaluer les mesures de sévérité de l'anxiété généralisée, commun en pratique clinique; CAGE, un test de dépistage de l'alcoolodépendance en quatre questions ; et le questionnaire d'empathie de Toronto (ÉT), une liste de 16 questions conçue pour évaluer les niveaux d'empathie.
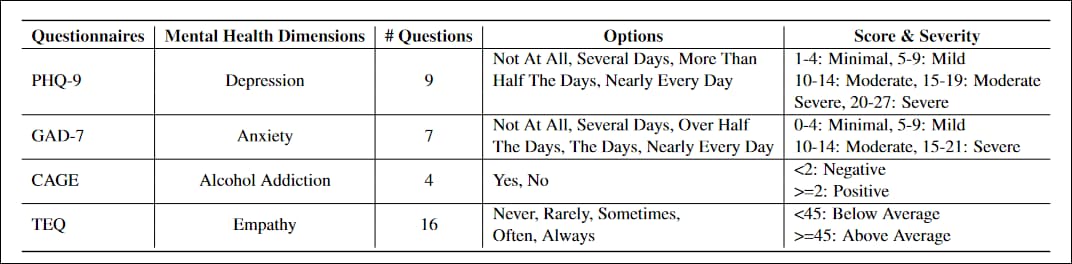
Caractéristiques des quatre questionnaires standards du secteur adaptés pour l'étude.
Les questionnaires ont dû être réécrits pour éviter les phrases déclaratives telles que Peu d'intérêt ou de plaisir à faire les choses, au profit de constructions interrogatives plus adaptées à un échange conversationnel.
Il était également nécessaire de définir une réponse « échouée », afin d'identifier et d'évaluer uniquement les réponses qu'un utilisateur humain pourrait interpréter comme valides et qui pourraient l'affecter. Une réponse « échouée » pourrait éluder la question avec des réponses elliptiques ou abstraites ; refuser de s'engager dans la question (c.-à-d. 'Je ne sais pas', ou 'J'ai oublié'); ou inclure un contenu antérieur « impossible » tel que « Quand j'étais enfant, j'avais généralement faim ». Dans les tests, Blender et Plato représentaient la majorité des échecs, et 61.4 % des échecs n'étaient pas pertinents pour la requête.
Les chercheurs ont formé les quatre modèles sur les messages Reddit, en utilisant le Ensemble de données Pushshift RedditDans les quatre cas, la formation a été affinée avec un ensemble de données supplémentaire contenant les données de Facebook. Conférence sur les compétences mixtes et Magicien de Wikipedia ensembles; ConvAI2 (une collaboration entre Facebook, Microsoft et Carnegie Mellon, entre autres) ; et Dialogues empathiques (une collaboration entre l'Université de Washington et Facebook).
Reddit omniprésent
Plato, DialoFlow et Blender sont livrés avec des poids par défaut pré-entraînés sur les commentaires Reddit, de sorte que les relations neuronales formées même en s'entraînant sur des données fraîches (qu'elles proviennent de Reddit ou d'ailleurs) soient influencées par la distribution des fonctionnalités extraites de Reddit.
Chaque groupe test a été mené deux fois, en « single » ou « multi ». Pour le « single », chaque question a été posée lors d'une nouvelle session de chat. Pour le « multi », une session de chat a été utilisée pour recevoir les réponses. tous les questions, car les variables de session s'accumulent au cours d'une conversation et peuvent influencer la qualité de la réponse lorsque la conversation prend une forme et un ton particuliers.
Toutes les expériences et la formation ont été exécutées sur deux GPU NVIDIA Tesla V100, pour un total de 64 Go de VRAM sur 1280 cœurs Tensor. Le document ne détaille pas la durée de la formation.
Surveillance via la conservation ou l'architecture ?
L’article conclut en termes généraux que la « négligence des risques pour la santé mentale » pendant la formation doit être abordée et invite la communauté des chercheurs à approfondir la question.
Le facteur central semble être que les frameworks de chatbot en question sont conçus pour extraire les caractéristiques saillantes des ensembles de données hors distribution sans aucune garantie En ce qui concerne le langage toxique ou destructeur, si vous alimentez les frameworks avec des données de forum néonazi, par exemple, vous obtiendrez probablement des réponses controversées lors d'une session de discussion ultérieure.
Cependant, le secteur du traitement du langage naturel (NLP) a un intérêt bien plus valable à obtenir des informations à partir des forums et du contenu fourni par les utilisateurs des réseaux sociaux. liés à la santé mentale (dépression, anxiété, dépendance, etc.), à la fois dans le but de développer des chatbots liés à la santé utiles et désamorçants, et pour obtenir de meilleures inférences statistiques à partir de données réelles.
Par conséquent, en termes de données à volume élevé qui ne sont pas limitées par les limites de texte arbitraires de Twitter, Reddit reste le seul corpus hyperscale constamment mis à jour pour les études de texte intégral de cette nature.
Cependant, même une simple consultation de certaines des communautés qui intéressent le plus les chercheurs en santé PNL (comme r/depression) révèle la prédominance du type de réponses « négatives » qui pourraient convaincre un système d'analyse statistique que les réponses négatives sont valables parce qu'elles sont fréquentes et statistiquement dominantes – en particulier dans le cas de forums très fréquentés avec des ressources de modération limitées.
La question reste donc de savoir si l’architecture du chatbot doit contenir une sorte de « cadre d’évaluation morale », où les sous-objectifs influencent le développement des pondérations dans le modèle, ou si une conservation et un étiquetage des données plus coûteux peuvent d’une certaine manière contrecarrer cette tendance vers des données déséquilibrées.
* L'article des chercheurs, tel que mentionné dans cet article, cite par erreur un lien vers Google Chatbot Meena au lieu du lien vers l'article Blender. Meena de Google est pas présenté dans le nouvel article. Le lien Blender correct utilisé dans cet article m'a été fourni par les auteurs des articles dans un courriel. Les auteurs m'ont informé que cette erreur serait corrigée dans une version ultérieure de l'article.
Première publication le 18 janvier 2022.












