Tekoäly
Zero123++: Yksittäinen kuva konsistenttiin moninäkökulmaan perustuvaan diffuusiopohjaiseen malliin

Viime vuosina on nähty nopea edistys askel generatiivisten mallien suorituskyvyssä, tehokkuudessa ja luovissa kyvyissä, jotka hyödyntävät laajoja tietoja ja 2D-diffuusiomenetelmiä. Nykyään generatiiviset AI-mallit ovat erittäin kykeneviä luomaan erilaisia 2D- ja jossain määrin 3D-sisältöjä, kuten tekstiä, kuvia, videoita, GIF-ejä ja paljon muuta.
Tässä artikkelissa puhumme Zero123++-kehyksestä, joka on kuvan ehdollistava diffuusiopohjainen generatiivinen AI-malli, jonka tavoitteena on luoda 3D-yhdenmukaisia moninäkökulmakuva kertaa yhdestä näkökulmasta. Hyödyntääkseen eniten etukäteen koulutettujen generatiivisten mallien etuja, Zero123++-kehys toteuttaa useita koulutus- ja ehdollistamismenetelmiä vähentääksesi vaivaa, joka tarvitaan Stable Diffusion -kuva-mallien hienosäätöön. Puhumme syvemmällä Zero123++-kehyksen arkkitehtuurista, toiminnasta ja tuloksista, ja analysoimme sen kykyä luoda korkealaatuisia moninäkökulmakuva kertaa yhdestä kuvasta. Aloita.
Zero123 ja Zero123++: Johdanto
Zero123++-kehys on kuvan ehdollistava diffuusiopohjainen generatiivinen AI-malli, jonka tavoitteena on luoda 3D-yhdenmukaisia moninäkökulmakuva kertaa yhdestä näkökulmasta. Zero123++-kehys on jatkoa Zero123- tai Zero-1-to-3-kehykselle, joka hyödyntää zero-shot-novel-view-kuvasynteesitekniikkaa avoimen lähdekoodin yksittäisen kuvan 3D-muunnoksiin. Vaikka Zero123++-kehys tarjoaa lupaavia tuloksia, kehyksen generoimissa kuvissa on näkyviä geometrisiä epäjohdonmukaisuuksia, ja se on pääsyy, miksi 3D-kohtauksien ja moninäkökulmakuva välillä on edelleen kuilu.
Zero-1-to-3-kehys toimii useiden muiden kehysten perustana, kuten SyncDreamer, One-2-3-45, Consistent123 ja useat muut, jotka lisäävät ylimääräisiä kerroksia Zero123-kehykseen saadakseen yhdenmukaisemmat tulokset 3D-kuvien generoimisessa. Muiden kehysten, kuten ProlificDreamer, DreamFusion, DreamGaussian ja useiden muiden, lähestymistapa perustuu optimointiin saadakseen 3D-kuvat eri epäjohdonmukaisista malleista. Vaikka nämä tekniikat ovat tehokkaita ja ne tuottavat tyydyttäviä 3D-kuvia, tuloksia voisi parantaa toteuttamalla perusdiffuusiomalli, joka pystyy generoimaan moninäkökulmakuva yhdenmukaisesti. Vastaavasti Zero123++-kehys ottaa Zero-1-to-3-kehyksen ja hienosäätää uuden moninäkökulmaisen perusdiffuusiomallin Stable Diffusionista.
Zero-1-to-3-kehyksessä jokainen uusi näkökulma generoidaan itsenäisesti, ja tämä lähestymistapa johtaa epäjohdonmukaisuuksiin generoiduissa näkökulmissa, koska diffuusiomallit ovat otannaisia. Ratkaistakseen tämän ongelman Zero123++-kehys ottaa tiling-asettelun, jossa objekti ympäröidään kuudella näkökulmalla yhteen kuvaan, ja varmistaa oikean yhdenmukaisen jakautumisen objektin moninäkökulmaisten kuvien osalta.
Parantaminen ehdollistamisessa ja yhdenmukaisuudessa
Yritettäessä parantaa kuvan ehdollistamista ja moninäkökulmaisten kuvien yhdenmukaisuutta Zero123++-kehys toteutti erilaisia tekniikoita, joiden ensisijainen tavoite oli uudelleenkäyttää aikaisemmin esikoulutetun Stable Diffusion -mallin tekniikoita.
Moninäkökulmainen generointi
Moninäkökulmaisten kuvien yhdenmukaisen generoinnin välttämätön laatu on mallinnetaan moninäkökulmaisten kuvien yhdistettyä jakautumista oikein. Zero-1-to-3-kehyksessä moninäkökulmaisten kuvien välinen korrelaatio jätetään huomiotta, koska jokaiselle kuvalle kehys mallintaa ehdollisen marginaalijakautumisen itsenäisesti ja erikseen. Sen sijaan Zero123++-kehyksessä kehittäjät ovat valinneet tiling-asettelun, jossa kuusi kuvaa yhdistetään yhteen kehykseen moninäkökulmaisen generoinnin vuoksi, ja prosessi on havainnollistettu seuraavassa kuvassa.
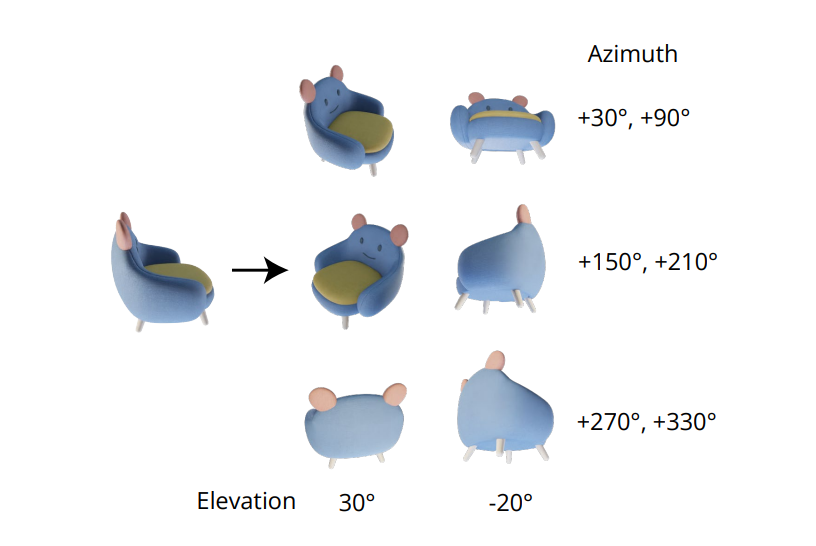

Lisäksi on huomattu, että objektien suunnat voivat hämärtää kouluttaessa mallia kameran asennoilla, ja estääkseen tämän hämärtymisen Zero-1-to-3-kehys kouluttaa kameran asennoilla, jotka sisältävät korkeuskulmat ja suhteellisen asimon azimutin syötteenä. Toteuttaakseen tämän lähestymistavan on tarpeen tietää syötteenä käytetyn näkökulman korkeuskulma, jota käytetään määrittämään suhteellinen asento uusille näkökulmille. Yrittäessään tietää tämän korkeuskulman kehykset usein lisäävät korkeuskulman arviomoduulin, ja tämä lähestymistapa johtaa usein lisävirheisiin putkessa.
Melun aikataulu
Stable Diffusionin alkuperäinen melun aikataulu, lineaarinen melun aikataulu, keskittyy ennen kaikkea paikallisiin yksityiskohtiin, mutta kuten voidaan nähdä seuraavasta kuvasta, siinä on vain muutamia askelia, joissa on alhainen SNR eli signaali-melun suhde.


Nämä alhaisen signaali-melun suhteen askelten tapahtuvat varhain puhdistusvaiheessa, joka on kriittinen vaihe globaalin matalataajuisen rakenteen määrittelyssä. Puhdistusvaiheen askelten vähentäminen, joko häiriössä tai koulutuksessa, johtaa usein suurempaan rakenteelliseen vaihteluun. Vaikka tämä asettelu on ihanteellinen yksittäisen kuvan generoimiselle, se rajoittaa kehyksen kykyä varmistaa globaali yhdenmukaisuus eri näkökulmien välillä. Päästäkseen tämän esteen yli Zero123++-kehys hienosäätää LoRA-mallin Stable Diffusion 2 v-prediction -kehyksessä suorittamaan leikkimistä, ja tulokset on havainnollistettu alla.

Skaalattoman lineaarisen melun aikataulun kanssa LoRA-malli ei ylikouluta, vaan vaaleentaa vain kuvaa hieman. Toisaalta, työskennellessä lineaarisen melun aikataulun kanssa LoRA-kehys generoi onnistuneesti tyhjän kuvan riippumatta syötteenä olevasta kuvauksesta, mikä osoittaa melun aikataulun vaikutuksen kehyksen sopeutumiskykyyn uusiin vaatimuksiin globaalisti.
Skaalattu viitehuomio paikallisille ehdollistamisille
Yhden näkökulman syöte tai ehdollistamiskuvat Zero-1-to-3-kehyksessä yhdistetään meluisiin syötteisiin ominaisuusulottuvuudessa melun kuvaamiseksi kuvan ehdollistamisessa.
Tämä yhdistäminen johtaa virheelliseen pikselikohtaiseen spatialiseen vastaavuuteen kohdekuvan ja syötteen välillä. Tarjoatakseen oikean paikallisen ehdollistamissyötteen Zero123++-kehys käyttää skaalattua viitehuomioita, jossa suoritetaan puhdistus-UNet-malli viitekuvalla, ja liitetään arvo-matriisit ja itsehuomion avain viitekuvasta vastaaviin huomiokerroksiin, kun mallin syöte puhdistetaan, ja se on havainnollistettu seuraavassa kuvassa.

Viitehuomio-lähestymistapa pystyy ohjaamaan diffuusiomallin generoimaan kuvia, jotka jakavat samanlaista tekstuuria viitekuvan kanssa, ja semanttista sisältöä ilman hienosäätöä. Hienosäätöä käytettäessä viitehuomio-lähestymistapa tarjoaa erinomaisia tuloksia, kun latentti on skaalattu.

Globaali ehdollistaminen: FlexDiffuse
Alkuperäisessä Stable Diffusion -lähestymistavassa tekstiupotukset ovat ainoat globaalin upotuksen lähteet, ja lähestymistapa käyttää CLIP-kehystä tekstienkoodaajana suorittamaan ristinäytteitä tekstiupotuksien ja mallin latenttien välillä. Tuloksena kehittäjät voivat käyttää tekstiavaruuden ja tuloksellisten CLIP-kuvien välistä vastaavuutta globaaleihin kuvan ehdollistamisiin.
Zero123++-kehys ehdottaa koulutettavissa olevan lineaarisen ohjausmekanismin käyttämistä globaalin kuvan ehdollistamisen sisällyttämiseksi kehykseen vähäisellä hienosäätöllä, ja tulokset on havainnollistettu seuraavassa kuvassa. Kuten voidaan nähdä, ilman globaalin kuvan ehdollistamista kehyksen generoimien sisältöjen laatu on tyydyttävä näkyville alueille, jotka vastaavat syötteenä olevaa kuvaa. Kuitenkin näkymättömien alueiden laatu, joita kehys generoi, heikkenee merkittävästi, mikä johtuu mallin kyvyttömyydestä johtaa objektin globaaleja semantiikkaa.

Mallin arkkitehtuuri
Zero123++-kehys on koulutettu Stable Diffusion 2v-mallin kanssa perustana käyttäen erilaisia lähestymistapoja ja tekniikoita, jotka on mainittu artikkelissa. Zero123++-kehys on esikoulutettu Objaverse-tietokannassa, joka on renderöity satunnaisilla HDRI-valaistuksilla. Kehys myös omaksuu vaiheittaisen koulutusohjelman, jota käytetään Stable Diffusion Image Variations -kehyksessä pyrkien vähentämään hienosäätöä ja säilyttämään niin paljon kuin mahdollista aiemmasta Stable Diffusionista.
Zero123++-kehyksen toiminta voidaan jakaa seuraaviin vaiheisiin. Ensimmäisessä vaiheessa kehys hienosäätää Stable Diffusionin ristihuomio- ja itsehuomiokerrosten KV-matriiseja AdamW-optimisaattorilla, 1000 lämmittelyaskella ja kosinioppiainevyöhykkeellä, joka maksimoi 7×10^-5. Toisessa vaiheessa kehys käyttää erittäin konservatiivista vakio-oppimisnopeutta 2000 lämmittelyjoukolla ja käyttää Min-SNR-lähestymistä maksimoimaan tehokkuutta koulutuksen aikana.
Zero123++: Tulokset ja suorituskykyvertailu
Laadullinen suorituskyky
Arvioidakseen Zero123++-kehyksen suorituskykyä sen laadun perusteella, se verrataan SyncDreameriin ja Zero-1-to-3-XL:ään, kahteen parhaimpaan valtavirtaisten sisällön generoimisen kehyksiin. Kehyksiä verrataan neljään syötteenä olevaan kuvaan, joilla on erilainen laajuus. Ensimmäinen kuva on sähköinen lelukissa, joka on otettu suoraan Objaverse-tietokannasta, ja se tarjoaa suuren epävarmuuden objektin takaosassa. Toinen kuva on palonsammuttimen kuva, ja kolmas on koiran kuva, joka istuu rakettia, generoitu SDXL-mallilla. Viimeinen kuva on anime-illustraatio. Tarvittavat korkeuskulmat kehyksille saadaan käyttämällä One-2-3-4-5-kehyksen korkeuskulman arviointimenetelmää, ja taustan poisto saadaan aikaan SAM-kehyksen avulla. Kuten voidaan nähdä, Zero123++-kehys generoi korkealaatuisia moninäkökulmakuva kertaa yhdenmukaisesti, ja se pystyy yleistämään ulkopuolelle 2D-illustraatioihin ja AI-generoitiin kuviin yhtä hyvin.


Määrällinen analyysi
Määrällisesti verrataksesi Zero123++-kehyksen valtavirtaisten Zero-1-to-3- ja Zero-1-to-3-XL-kehyksiin, kehittäjät arvioivat Learned Perceptual Image Patch Similarity (LPIPS) -pisteytystä näissä malleissa validointijoukon tietojen perusteella, joka on osa Objaverse-tietokantaa. Arvioidakseen mallin suorituskykyä moninäkökulmaisen kuvan generoimisessa, kehittäjät yhdistävät viitekuvat ja kuusi generoituja kuvaa ja laskevat sitten LPIPS-pisteytystä. Tulokset on esitetty alla, ja kuten voidaan nähdä, Zero123++-kehys saavuttaa parhaimman suorituskyvyn validointijoukossa.

Teksti-moninäkökulma-arviointi
Arvioidakseen Zero123++-kehyksen kykyä teksti-moninäkökulmaisen sisällön generoimisessa, kehittäjät käyttävät ensin SDXL-kehyksen tekstipromptteja kuvan generoimiseen ja sitten käyttävät Zero123++-kehyksen generoimaan kuvan. Tulokset on esitetty seuraavassa kuvassa, ja kuten voidaan nähdä, verrattuna Zero-1-to-3-kehykseen, joka ei voi taata moninäkökulmaisen generoinnin, Zero123++-kehys palauttaa yhdenmukaisia, realistisia ja yksityiskohtaisia moninäkökulmakuva käyttämällä teksti-kuva-moninäkökulmaista lähestymistapaa.

Zero123++ Depth ControlNet
Lisäksi perus-Zero123++-kehyksestä, kehittäjät ovat julkaisseet Depth ControlNet Zero123++-version, joka on syvyyden ohjattu versio alkuperäisestä kehyksestä, joka on rakennettu ControlNet-arkkitehtuurilla. Normalisoidut lineaariset kuvat renderöidään seuraavien RGB-kuvien kanssa, ja ControlNet-kehys koulutetaan ohjaamaan Zero123++-kehyksen geometriaa syvyyden havainnon avulla.


Johtopäätös
Tässä artikkelissa olemme puhuneet Zero123++:sta, joka on kuvan ehdollistava diffuusiopohjainen generatiivinen AI-malli, jonka tavoitteena on luoda 3D-yhdenmukaisia moninäkökulmakuva kertaa yhdestä näkökulmasta. Hyödyntääkseen eniten etukäteen koulutettujen generatiivisten mallien etuja, Zero123++-kehys toteuttaa useita koulutus- ja ehdollistamismenetelmiä vähentääksesi vaivaa, joka tarvitaan Stable Diffusion -kuva-mallien hienosäätöön. Olemme myös keskustelleet erilaisista lähestymistavoista ja parannuksista, jotka Zero123++-kehys toteuttaa saadakseen tulokset, jotka ovat vertailukelpoisia ja jopa ylittävät nykyisten valtavirtaisten kehysten saavutukset.
Kuitenkin, vaikka se on tehokas ja pystyy generoimaan korkealaatuisia moninäkökulmakuva kertaa yhdenmukaisesti, Zero123++-kehys on edelleen parantamisen varassa, ja mahdollisia tutkimusalueita ovat kaksivaiheinen hienosäätömalli, joka voisi ratkaista Zero123++:n kyvyttömyyden täyttää globaaleja yhdenmukaisuuden vaatimuksia, sekä lisäksi skaalautuvuutta, jotta se voisi generoida kuvia, jotka ovat vielä laadukkaampia.
- Kaksivaiheinen hienosäätömalli, joka voisi ratkaista Zero123++:n kyvyttömyyden täyttää globaaleja yhdenmukaisuuden vaatimuksia.
- Lisäksi skaalautuvuutta, jotta se voisi generoida kuvia, jotka ovat vielä laadukkaampia.












