Tekoäly
Koulutus tietokoneen näön malleja satunnaisella melulla sen sijaan, että käytettäisiin oikeita kuvia

Tutkijat MIT:n tietojenkäsittely- ja tekoälylaboratoriosta (CSAIL) ovat kokeilleet satunnaisen melun käyttämistä tietokoneen näön dataseteissä koulutettaessa tietokoneen näön malleja, ja he ovat havainneet, että menetelmä on yllättävän tehokas:

Generatiiviset mallit kokeesta, lajiteltuina suorituskyvyn mukaan. Lähde: https://openreview.net/pdf?id=RQUl8gZnN7O
Syöttämällä ilmeistä ‘visuaalista roskaa’ suosittuihin tietokoneen näön arkkitehtuureihin ei pitäisi johtaa tällaisiin tuloksiin. Kuvan oikeassa reunassa mustat pylväät edustavat tarkkuuskohtaisia tuloksia (Imagenet-100) neljälle ‘oikealle’ datasetille. Vaikka ‘satunnaisen melun’ datasetit eivät voi vastata siihen, ne ovat lähes kaikki kunnioittavissa ylä- ja alarajoissa (punaiset viivat) tarkkuuden suhteen.
Tässä mielessä ‘tarkkuus’ ei tarkoita, että tulos välttämättä muistuttaa kasvoja, kirkkoa, pizzaa tai mitään muuta tiettyä aluetta, josta olet kiinnostunut luomaan kuvansynteesijärjestelmän, kuten Generatiivinen Adversarial Network tai encoder/decoder-kehyksen.
Sen sijaan se tarkoittaa, että CSAIL-mallit ovat johdattaneet laajasti soveltuvia keskeisiä ‘totuuksia’ kuvadatasta, joka on niin selvästi rakenteeton, ettei se pitäisi pystyä tarjoamaan sitä.
Monimuotoisuus Vs. Luonnollisuus
Nämä tulokset eivät myöskään voida johtua ylioppimisesta: elävän keskustelun avaus kirjoittajien ja arvostelijoiden välillä Open Review -palvelussa paljastaa, että sekoittamalla eri sisältöä visuaalisesti monimuotoisista dataseteistä (kuten ‘kuolleet lehdet’, ‘fraktaalit’ ja ‘menetelmällinen melu’ – katso kuva alla) koulutusdatasettiin parantaa tarkkuutta näissä kokeissa.
Tämä viittaa (ja se on vallankumouksellinen käsite) uudenlaiseen ‘aliohittamiseen’, jossa ‘monimuotoisuus’ voittaa ‘luonnollisuuden’.
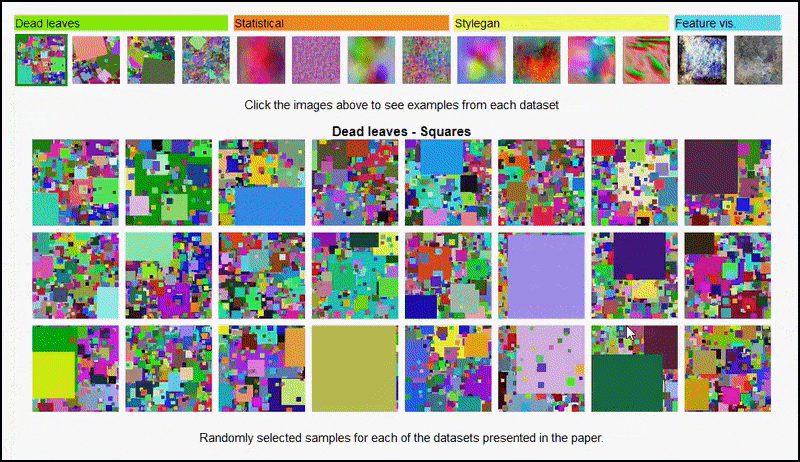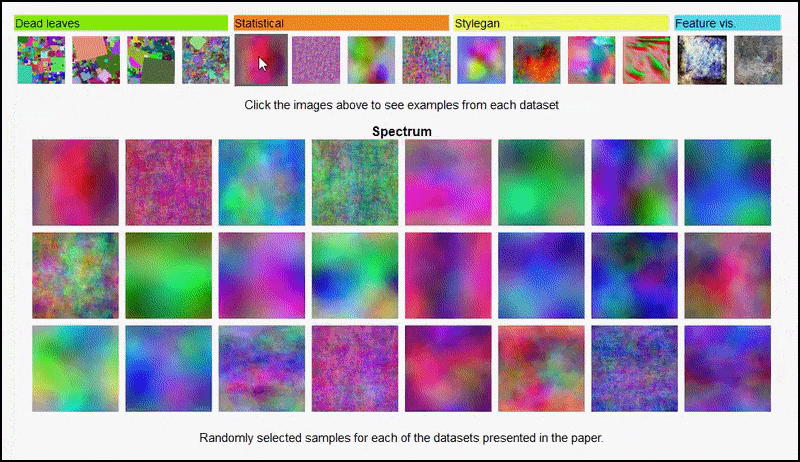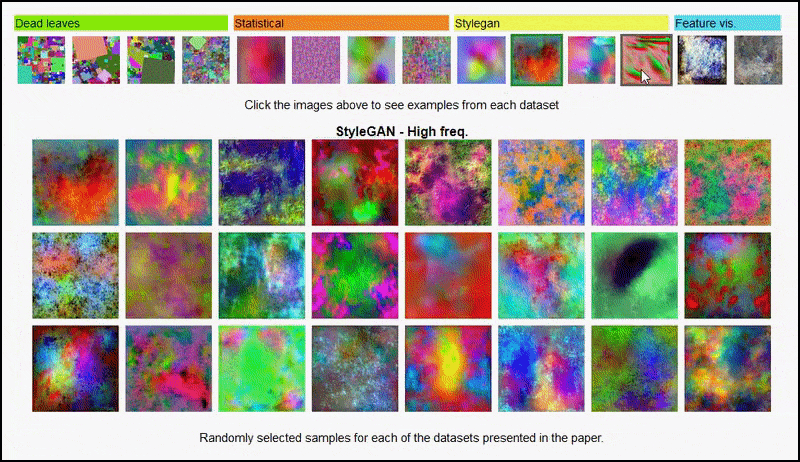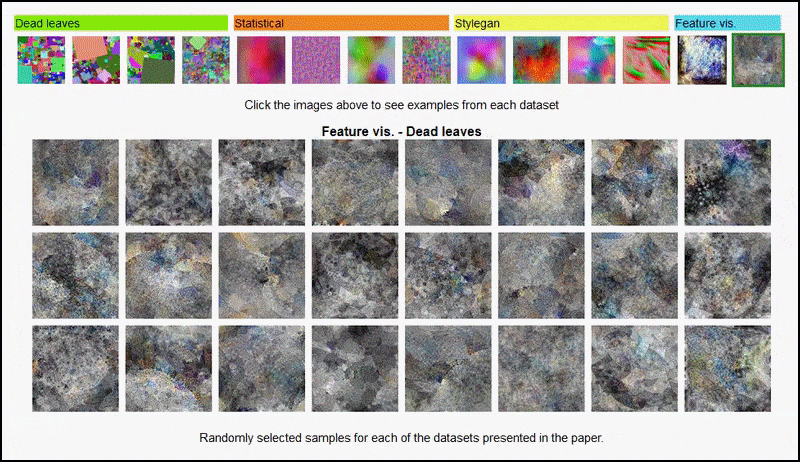
Hankkeen sivu aloitteesta sallii interaktiivisesti tarkastella eri tyypin satunnaisten kuvadatasettien käyttöä kokeessa. Lähde: https://mbaradad.github.io/learning_with_noise/
Tutkijoiden saamat tulokset asettavat kyseenalaiseksi perussuhteen kuvapohjaisen neuroverkkojen ja ‘oikean maailman’ kuvien välillä, joita heittävät niille hälyttävissä suuremmassa määrin joka vuosi, ja viittaavat siihen, että tarve hankkia, kuratoida ja muutoin hallita hyperskaalaisia kuvadatasettejä saattaa lopulta tulla tarpeettomaksi. Kirjoittajat toteavat:
‘Nykyiset näköjärjestelmät koulutetaan valtavilla dataseteillä, ja nämä datasetit tulevat kustannuksin: kuratointi on kallista, ne periytyvät ihmisten harhautumisista, ja niiden yksityisyyden ja käytön oikeuksien suhteen on ongelmia. Vastatakseen näihin kustannuksiin, mielenkiinto on kasvanut opettelussa halvempien tietolähteiden avulla, kuten merkityksettömistä kuvista.’
‘Tässä paperissa menemme askelen eteenpäin ja kysymme, voimmeko tehdä ilman oikeita kuvadatasettejä kokonaan, opettelemalla menetelmällisistä meluprosesseista.’
Tutkijat ehdottavat, että nykyisten koneoppimisarkkitehtuurien nykyinen joukko saattaa olla johtava jotain paljon perustavampaa (tai ainakin odottamatonta) kuvista, kuin mitä aiemmin ajateltiin, ja että ‘järjettömät’ kuvat voivat mahdollisesti antaa paljon tätä tietoa paljon halvemmalla, jopa mahdollisella käytöllä ad hoc -synteettistä dataa, datasetin generoivien arkkitehtuurien kautta, jotka generoivat satunnaisia kuvia koulutuksen aikana:
‘‘Tunnistamme kaksi avainominaisuutta, jotka tekevät hyvää synteettistä dataa visuaalisten järjestelmien koulutukseen: 1) luonnollisuus, 2) monimuotoisuus. Mielenkiintoista kyllä, luonnollisin data ei aina ole paras, koska luonnollisuus voi tulla monimuotoisuuden kustannuksella.’
‘Se, että luonnollinen data auttaa, ei välttämättä ole yllättävää, ja se viittaa siihen, että todella, laajamittainen oikea data on arvokasta. Kuitenkin löysimme, että se, mikä on ratkaisevaa, ei ole se, että data olisi oikea, vaan se, että se olisi luonnollinen, eli se on vangittava tiettyjä rakenteellisia ominaisuuksia oikeasta datasta.’
‘Monet näistä ominaisuuksista voidaan vangita yksinkertaisiin melumalleihin.’

Piirrosvisualisoinnit AlexNet-johtuvasta kooderista joistakin satunnaisten kuvadataseteistä, jotka kirjoittajat käyttivät, kattavat 3. ja 5. (loppu) konvoluutio kerrosta. Tässä käytetty menetelmä noudattaa Google AI -tutkimuksessa vuonna 2017 esitettyä lähestymistapaa.
Paperi, joka esiteltiin 35. konferenssissa NeurIPS 2021:ssa Sydneyn, on nimeltään Katselemalla melua, ja se tulee kuudesta tutkijasta CSAIL:sta, joilla on yhtäläinen panos.
Työ suositeltiin yksimielisesti valaistuksi valinnaksi NeurIPS 2021:ssa, ja vertaisarvostelijat kuvasivat paperia ‘tieteelliseksi läpimurroksi’, joka avaa ‘loistavan tutkimusalueen’, vaikka se herättää yhtä paljon kysymyksiä kuin se vastaa.
Paperissa kirjoittajat toteavat:
‘Olemme osoittaneet, että, kun suunnitellaan tuloksia aiemmasta tutkimuksesta luonnollisen kuvastatistiikasta, nämä datasetit voivat onnistuneesti kouluttaa visuaalisia edustuksia. Toivomme, että tämä paperi motivoi uusien generatiivisten mallien tutkimista, jotka pystyvät tuottamaan rakenteista melua saavuttaen jopa parempaa suorituskykyä, kun niitä käytetään monissa visuaalisissa tehtävissä.’
‘Onko mahdollista saavuttaa sama suorituskyky kuin ImageNet-esityksellä? Ehkä ilman suurta koulutusjoukkoa tietyn tehtävän osalla paras esitys ei välttämättä ole käyttää standardia oikeaa datasettiä, kuten ImageNetiä.’












