
Tekoäly
Kohti reaaliaikaisia tekoälyihmisiä hermolumigraafin renderöinnillä

Huolimatta nykyisestä kiinnostuksesta hermosäteilykenttiä kohtaan (NeRF), teknologia, joka pystyy luomaan tekoälyn luomia 3D-ympäristöjä ja -objekteja, tämä uusi lähestymistapa kuvasynteesiteknologiaan vaatii edelleen paljon harjoittelua, ja siitä puuttuu toteutus, joka mahdollistaisi reaaliaikaiset, erittäin reagoivat rajapinnat.
Teollisuuden ja korkeakoulujen vaikuttavien nimien yhteistyö tarjoaa kuitenkin uuden otoksen tähän haasteeseen (tunnetaan yleisesti nimellä Novel View Synthesis tai NVS).
Tutkimus paperi, oikeutettu Neuraalinen Lumigraph Rendering, väittää noin kahden suuruusluokan parannusta viimeisimpään tekniikkaan, mikä edustaa useita askeleita kohti reaaliaikaista CG-renderöintiä koneoppimisputkien kautta.

Neuraalinen Lumigraph Rendering (oikealla) tarjoaa paremman erottelukyvyn sekoittuville artefakteille ja paremman tukosten käsittelyn aiempiin menetelmiin verrattuna. Lähde.
Vaikka kirjoituksessa mainitaan vain Stanfordin yliopisto ja holografisten näyttöjen teknologiayritys Raxium (joka toimii tällä hetkellä varkain tilassa), osallistujat sisältävät pääasiallisen koneoppimisen arkkitehti Googlessa, tietokoneella tutkija Adobella ja CTO at TarinaTiedosto (joka teki pääotsikot äskettäin William Shatnerin tekoälyversiolla).
Mitä tulee Shatnerin äskettäiseen julkisuuteen, StoryFile näyttää käyttävän NLR:ää uudessa prosessissaan luodakseen interaktiivisia tekoälyn luomia kokonaisuuksia yksittäisten ihmisten ominaisuuksiin ja kertomuksiin perustuen.

StoryFile suunnittelee tämän tekniikan käyttöä museonäytöksissä, online-interaktiivisissa kertomuksissa, holografisissa näytöissä, lisätyssä todellisuudessa (AR) ja kulttuuriperintödokumentaatiossa – ja näyttää myös katselevan NLR:n mahdollisia uusia sovelluksia rekrytointihaastatteluissa ja virtuaalisissa treffisovelluksissa:

Ehdotetut käyttötavat StoryFilen verkkovideosta. Lähde: https://www.youtube.com/watch?v=2K9J6q5DqRc
Volumetrinen kaappaus uusiin näkymän synteesirajapintoihin ja videoon
Volumetrisen kaappauksen periaate aiheesta kerääntyvien papereiden osalta on ajatus ottaa still-kuvia tai videoita aiheesta ja käyttää koneoppimista "täyttääkseen" näkökulmat, joita alkuperäinen ei kattanut. valikoima kameroita.
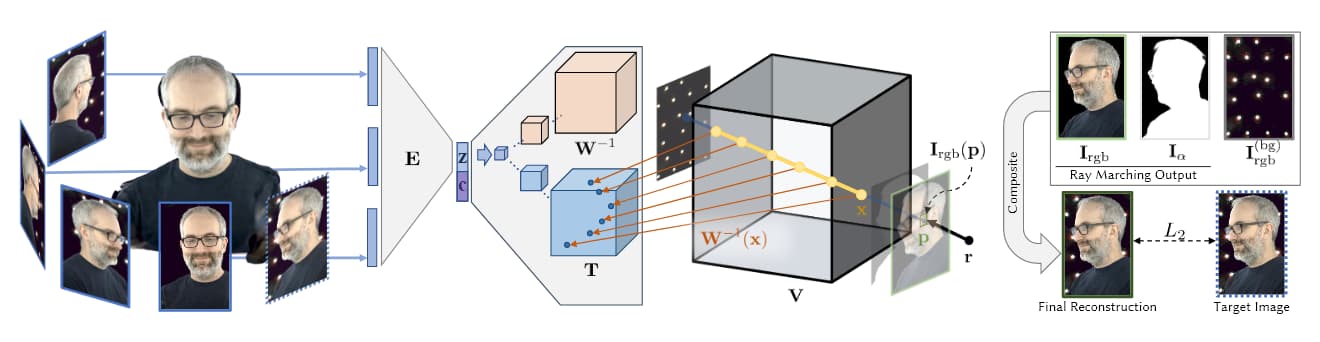
Lähde: https://research.fb.com/wp-content/uploads/2019/06/Neural-Volumes-Learning-Dynamic-Renderable-Volumes-from-Images.pdf
Yllä olevassa kuvassa, joka on otettu Facebookin AI 2019 AI -tutkimuksesta (katso alla), näemme tilavuuskaappauksen neljä vaihetta: useat kamerat saavat kuvia/materiaalia; kooderi/dekooderiarkkitehtuuri (tai muut arkkitehtuurit) laskea ja ketjuttaa näkymien suhteellisuuden; ray-marching-algoritmit laskevat vokseleihin (tai muut XYZ-tilageometriset yksiköt) tilavuusavaruuden kunkin pisteen osalta; ja (useimmissa kirjoissa) harjoittelua tapahtuu kokonaisen kokonaisuuden syntetisoimiseksi, jota voidaan manipuloida reaaliajassa.
Juuri tämä usein laaja ja paljon dataa vaativa koulutusvaihe on tähän mennessä pitänyt uudenlaisen näkymäsynteesin poissa reaaliaikaisesta tai erittäin reagoivasta kaappauksesta.
Se tosiasia, että Novel View Synthesis tekee täydellisen 3D-kartan tilavuusavaruudesta, tarkoittaa, että on suhteellisen triviaalia yhdistää nämä pisteet perinteiseen tietokoneella luotuun verkkoon, joka vangitsee ja artikuloi tehokkaasti CGI-ihmisen (tai minkä tahansa muun suhteellisen rajatun kohteen) kärpänen.
NeRF:ää käyttävät lähestymistavat luottavat pistepilviin ja syvyyskarttoihin interpolaatioiden luomiseksi sieppauslaitteiden harvojen näköpisteiden välillä:

NeRF voi tuottaa tilavuussyvyyttä laskemalla syvyyskarttoja CG-silmien luomisen sijaan. Lähde: https://www.youtube.com/watch?v=JuH79E8rdKc
Vaikka NeRF on kykenee Verkkojen laskennassa useimmat toteutukset eivät käytä tätä tilavuuskohtausten luomiseen.
Sitä vastoin implisiittinen erotettavissa oleva renderöijä (IDR) lähestymistapa, julkaistu Weizmann Institute of Sciencen lokakuussa 2020 tekemässä tutkimuksessa hyödynnetään sieppausryhmistä automaattisesti luotuja 3D-verkkotietoja:

Esimerkkejä IDR-kaappauksista, jotka on muutettu interaktiivisiksi CGI-verkoiksi. Lähde: https://www.youtube.com/watch?v=C55y7RhJ1fE
Vaikka NeRF:ltä puuttuu IDR:n kyky arvioida muotoa, IDR ei voi vastata NeRF:n kuvanlaatua, ja molemmat vaativat laajoja resursseja kouluttamiseen ja kokoamiseen (vaikka viimeaikaiset NeRF-innovaatiot ovat alku että ota yhteyttä tähän).

NLR:n mukautettu kamera, jossa on 16 GoPro HERO7 -kameraa ja 6 keskimmäistä Back-Bone H7PRO -kameraa. "Reaaliaikaisessa" renderöinnissa nämä toimivat vähintään 60 fps:n nopeudella. Lähde: https://arxiv.org/pdf/2103.11571.pdf
Sen sijaan Neural Lumigraph Rendering käyttää SIREENI (Sinusoidal Representation Networks) sisällyttääkseen kunkin lähestymistavan vahvuudet omaan kehykseensä, jonka tarkoituksena on tuottaa tulos, jota voidaan suoraan käyttää olemassa olevissa reaaliaikaisissa grafiikkaputkissa.
SIRENiä on käytetty vastaavia toteutuksia kuluneen vuoden aikana ja edustaa nyt a suosittu API-kutsu harrastaja Colabsille kuvasynteesiyhteisöissä; NLR:n innovaationa on kuitenkin soveltaa SIRENejä kaksiulotteiseen moninäkymäkuvan valvontaan, mikä on ongelmallista, koska SIREN tuottaa ylisovitettua yleisen sijaan.
Kun CG-verkko on erotettu matriisin kuvista, mesh rasteroidaan OpenGL:n kautta ja verkon huippupisteet kartoitetaan sopiviin pikseleihin, minkä jälkeen lasketaan eri osallistuvien karttojen sekoitus.
Tuloksena oleva verkko on yleisempi ja edustavampi kuin NeRF-verkko (katso kuva alla), vaatii vähemmän laskentaa eikä käytä liiallisia yksityiskohtia alueille (kuten sileälle kasvojen iholle), jotka eivät voi hyötyä siitä:

Lähde: https://arxiv.org/pdf/2103.11571.pdf
Negatiivinen puoli on se, että NLR:llä ei vielä ole kapasiteettia dynaamiseen valaistukseen tai uudelleen valaiseminen, ja tulostus on rajoitettu varjokarttoihin ja muihin kuvaushetkellä saatuihin valaistusnäkökohtiin. Tutkijat aikovat käsitellä tätä tulevassa työssään.
Lisäksi paperi myöntää, että NLR:n luomat muodot eivät ole yhtä tarkkoja kuin jotkut vaihtoehtoiset lähestymistavat, kuten esim. Pixelwise View -valinta rakenteettoman moninäkymästereolletai aiemmin mainittu Weizmann-instituutin tutkimus.
Volumetrisen kuvan synteesin nousu
Ajatus luoda 3D-kokonaisuuksia rajoitetusta valokuvasarjasta hermoverkkojen avulla juontaa juurensa ennen NeRF:ää, ja visionääripaperit ulottuvat vuoteen 2007 tai aikaisemmin. Vuonna 2019 Facebookin tekoälytutkimusosasto tuotti merkittävän tutkimuspaperin, Neuraaliset volyymit: Dynaamisten renderöivien volyymien oppiminen kuvista, joka mahdollisti ensimmäisenä koneoppimiseen perustuvan volyymikaappauksen luomat responsiiviset rajapinnat synteettisille ihmisille.

Facebookin vuoden 2019 tutkimus mahdollisti responsiivisen käyttöliittymän luomisen volyymihenkilölle. Lähde: https://research.fb.com/publications/neural-volumes-learning-dynamic-renderable-volumes-from-images/











