
Best Of
10 parasta koneoppimisalgoritmia
Vaikka elämmekin GPU-kiihdytetyn koneoppimisen poikkeuksellisten innovaatioiden aikaa, viimeisimmät tutkimuspaperit sisältävät usein (ja näkyvästi) algoritmeja, jotka ovat vuosikymmeniä, joissakin tapauksissa jopa 70 vuotta vanhoja.
Jotkut saattavat väittää, että monet näistä vanhemmista menetelmistä kuuluvat pikemminkin "tilastollisen analyysin" kuin koneoppimisen leiriin, ja mieluummin ajoittuvat alan tuloon vain vuoteen 1957 asti, jolloin Perceptronin keksintö.
Ottaen huomioon, missä määrin nämä vanhemmat algoritmit tukevat koneoppimisen uusimpia trendejä ja otsikoita herättäviä kehityssuuntia ja ovat niihin kietoutunut, tämä asenne on kiistanalainen. Katsotaanpa siis joitain "klassisia" rakennuspalikoita, jotka tukevat uusimpia innovaatioita, sekä joitain uudempia merkintöjä, jotka tekevät ennakkotarjouksen tekoälyn hall of fameen.
1: muuntajat
Vuonna 2017 Google Research johti tutkimusyhteistyötä, joka huipentui paperi Huomio on kaikki mitä tarvitset. Teos hahmotteli uudenlaista arkkitehtuuria, joka edisti huomiomekanismit enkooderin/dekooderin ja toistuvien verkkomallien "putkistosta" omaksi keskeiseksi muunnosteknologiaksi.
Lähestymistapa dubattiin Muuntaja, ja siitä on sittemmin tullut vallankumouksellinen menetelmä luonnollisen kielen käsittelyssä (NLP), joka käyttää muun muassa autoregressiivistä kielimallia ja AI-juliste GPT-3:a.
![]()
Transformers ratkaisi ongelman tyylikkäästi sekvenssin transduktio, jota kutsutaan myös "muunnokseksi", joka käsittelee syöttösekvenssit lähtösekvensseiksi. Muuntaja myös vastaanottaa ja hallitsee dataa jatkuvalla tavalla peräkkäisten erien sijaan, mikä mahdollistaa "muistin pysyvyyden", jota RNN-arkkitehtuuria ei ole suunniteltu saamaan. Tarkemman yleiskatsauksen muuntajista katso viiteartikkelimme.
Toisin kuin RNN:t (Recurrent Neural Networks), jotka olivat alkaneet hallita ML-tutkimusta CUDA-aikakaudella, Transformer-arkkitehtuuri voitiin myös helposti rinnastettu, mikä avaa tien tuottavaan käsitellä paljon laajempaa dataa kuin RNN:t.
Suosittu käyttö
Transformers valloitti yleisön mielikuvituksen vuonna 2020 julkaisemalla OpenAI:n GPT-3:n, jolla oli tuolloin ennätys. 175 miljardia parametria. Tämä ilmeisen huikea saavutus jäi lopulta myöhempien projektien, kuten vuoden 2021, varjoon. vapauta Microsoftin Megatron-Turing NLG 530B, jossa (kuten nimestä voi päätellä) on yli 530 miljardia parametria.

Hyperscale Transformer NLP -projektien aikajana. Lähde: Microsoft
Muuntaja-arkkitehtuuri on myös siirtynyt NLP:stä tietokonenäköön, mikä antaa virtaa a uusi sukupolvi kuvasynteesikehykset, kuten OpenAI:t CLIP ja DALL-E, jotka käyttävät teksti->kuva-aluekartoitusta epätäydellisten kuvien viimeistelyyn ja uusien kuvien syntetisoimiseen koulutetuilta verkkotunnuksilta yhä useamman asiaan liittyvien sovellusten joukossa.

DALL-E yrittää viimeistellä osittaisen kuvan Platonin rintakuvasta. Lähde: https://openai.com/blog/dall-e/
2: Generative Adversarial Networks (GAN)
Vaikka muuntajat ovat saaneet poikkeuksellista huomiota tiedotusvälineissä GPT-3:n julkaisun ja käyttöönoton myötä, Generatiivinen kilpaileva verkosto (GAN) on tullut tunnistettavaksi omaksi brändiksi, ja se saattaa lopulta liittyä siihen deepfake verbinä.
Ensimmäinen ehdotettu vuonna 2014 ja käytetään ensisijaisesti kuvasynteesiin, Generatiivinen Adversarial Network arkkitehtuuri koostuu a Generaattori ja diskriminaattoria. Generator selaa tuhansia datajoukon kuvia ja yrittää iteratiivisesti rekonstruoida niitä. Jokaisella yrityksellä Diskriminaattori arvostelee generaattorin työtä ja lähettää generaattorin takaisin tekemään paremmin, mutta ilman käsitystä siitä, miten edellinen rekonstruktio epäonnistui.

Lähde: https://developers.google.com/machine-learning/gan/gan_structure
Tämä pakottaa generaattorin tutkimaan monia väyliä sen sijaan, että olisi seurannut mahdollisia sokeita kujia, jotka olisivat johtaneet, jos Diskriminaattori olisi kertonut sille, missä se meni pieleen (katso #8 alla). Kun koulutus on ohi, generaattorilla on yksityiskohtainen ja kattava kartta tietojoukon pisteiden välisistä suhteista.

Paperista GAN-tasapainon parantaminen lisäämällä tilatietoisuutta: uusi kehys kiertää GAN:n joskus salaperäisen piilevän tilan läpi ja tarjoaa responsiivisen välineen kuvasynteesiarkkitehtuurille. Lähde: https://genforce.github.io/eqgan/
Analogisesti tämä on ero yhden tylsän työmatkan oppimisen välillä Lontoon keskustaan vai vaivalloisen hankkimisen välillä Tieto.
Tuloksena on korkeatasoinen kokoelma ominaisuuksia koulutetun mallin piilevässä tilassa. Korkean tason ominaisuuden semanttinen indikaattori voisi olla "henkilö", kun taas ominaisuuteen liittyvän spesifisyyden kautta tapahtuva laskeutuminen voi paljastaa muita opittuja ominaisuuksia, kuten "mies" ja "nainen". Alemmilla tasoilla aliominaisuudet voivat jakautua "blondiin", "valkoihoisiin" ym.
Kietoutuminen on huomattava ongelma GAN:ien ja enkooderi/dekooderikehysten piilevässä tilassa: onko GAN:in luoman naisen kasvojen hymy piilevän tilan "identiteettinsä" sotkeutunut piirre vai onko se rinnakkaishaara?

Tämän henkilön GAN- luomia kasvoja ei ole olemassa. Lähde: https://this-person-does-not-exist.com/en
Viimeiset pari vuotta ovat tuoneet mukanaan kasvavan määrän uusia tutkimushankkeita tässä suhteessa, mikä kenties tasoittaa tietä ominaisuustason Photoshop-tyyliselle muokkaukselle GAN:n piilevää tilaa varten, mutta tällä hetkellä monet muutokset ovat tehokkaita. kaikki tai ei mitään -paketteja. Erityisesti NVIDIAn vuoden 2021 lopulla julkaistu EditGAN-julkaisu saavuttaa a korkea tulkintataso piilevässä tilassa semanttisten segmentointimaskien avulla.
Suosittu käyttö
Sen lisäksi, että he osallistuvat (itse asiassa melko rajoitetusti) suosittuihin syväväärennösvideoihin, kuva-/videokeskeiset GAN-verkot ovat lisääntyneet viimeisten neljän vuoden aikana ja kiehtoneet tutkijoita ja yleisöä. Uusien julkaisujen huimaavan nopeuden ja tiheyden pysyminen on haaste, vaikka GitHub-arkisto Mahtavia GAN-sovelluksia tavoitteena on tarjota kattava luettelo.
Generatiiviset vastakkaiset verkot voivat teoriassa saada ominaisuuksia mistä tahansa hyvin kehystetystä toimialueesta, teksti mukaan lukien.
3: SVM
peräisin vuonna 1963, Tuki Vector Machine (SVM) on ydinalgoritmi, joka esiintyy usein uudessa tutkimuksessa. SVM:ssä vektorit kartoittavat datapisteiden suhteellisen sijainnin tietojoukossa, kun taas tuki vektorit rajaavat eri ryhmien, piirteiden tai piirteiden välisiä rajoja.
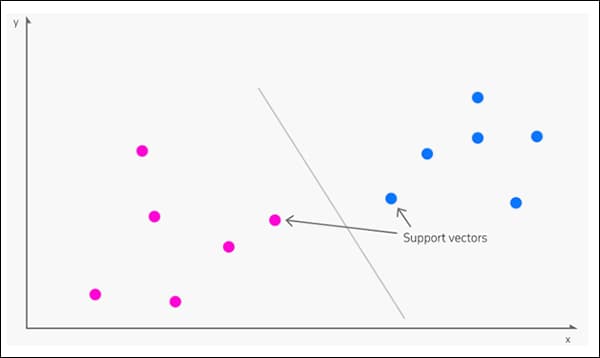
Tukivektorit määrittelevät ryhmien väliset rajat. Lähde: https://www.kdnuggets.com/2016/07/support-vector-machines-simple-explanation.html
Johdettua rajaa kutsutaan a hypertaso.
Alhaisilla ominaisuustasoilla SVM on kaksiulotteinen (kuva yllä), mutta jos tunnistettuja ryhmiä tai tyyppejä on enemmän, siitä tulee kolmiulotteinen.

Syvempi joukko pisteitä ja ryhmiä vaatii kolmiulotteisen SVM:n. Lähde: https://cml.rhul.ac.uk/svm.html
Suosittu käyttö
Koska tuet Vector Machines voivat käsitellä tehokkaasti ja agnostisesti monenlaisia korkeaulotteisia tietoja, niitä esiintyy laajalti useilla koneoppimisen aloilla, mukaan lukien syvän väärennöksen tunnistus, kuvan luokittelu, vihapuheen luokitus, DNA-analyysi ja väestörakenteen ennuste, monien muiden joukossa.
4: K-Means Clustering
Klusterointi yleensä on ohjaamaton oppiminen lähestymistapaa, joka pyrkii luokittelemaan datapisteet läpi tiheyden arvio, luomalla kartan tutkittavan tiedon jakautumisesta.

K-Means klusteroi jumalallisia segmenttejä, ryhmiä ja yhteisöjä dataan. Lähde: https://aws.amazon.com/blogs/machine-learning/k-means-clustering-with-amazon-sagemaker/
K-tarkoittaa klusterointia Siitä on tullut tämän lähestymistavan suosituin toteutus, joka jakaa tietopisteet erottuviin "K-ryhmiin", jotka voivat osoittaa demografisia sektoreita, verkkoyhteisöjä tai mitä tahansa muuta mahdollista salaista aggregaatiota, joka odottaa löytämistään raakatilastotiedoista.

K-Means-analyysissä muodostuu klustereita. Lähde: https://www.geeksforgeeks.org/ml-determine-the-optimal-value-of-k-in-k-means-clustering/
K-arvo itsessään on määräävä tekijä prosessin hyödyllisyydessä ja klusterin optimaalisen arvon määrittämisessä. Aluksi K-arvo määrätään satunnaisesti ja sen ominaisuuksia ja vektorin ominaisuuksia verrataan naapureihinsa. Ne naapurit, jotka muistuttavat eniten datapistettä satunnaisesti annetulla arvolla, määrätään sen klusteriin iteratiivisesti, kunnes data on tuottanut kaikki prosessin sallimat ryhmittelyt.
Klusterien välisten eri arvojen neliöidyn virheen tai 'kustannus' käyrä paljastaa an kyynärpää dataa varten:

"Kynärpää" klusterikaaviossa. Lähde: https://www.scikit-yb.org/en/latest/api/cluster/elbow.html
Kyynärpää on konseptiltaan samanlainen kuin tapa, jolla menetys tasoittuu laskevaksi tuotoksi tietojoukon harjoittelun lopussa. Se edustaa pistettä, jossa ryhmien välisiä eroja ei enää tule ilmeiseksi, mikä osoittaa hetken siirtyä seuraaviin vaiheisiin dataputkessa tai muuten raportoida havainnoista.
Suosittu käyttö
K-Means Clustering on ilmeisistä syistä ensisijainen teknologia asiakasanalyysissä, koska se tarjoaa selkeän ja selitettävän menetelmän suurten kaupallisten tietueiden muuttamiseksi demografisiksi oivalluksiksi ja "viimeiksi".
Tämän sovelluksen ulkopuolella käytetään myös K-Means Clusteringia maanvyörymien ennustus, lääketieteellisten kuvien segmentointi, kuvasynteesi GAN:ien kanssa, asiakirjan luokitteluja kaupunkisuunnittelu, monien muiden mahdollisten ja todellisten käyttötarkoitusten joukossa.
5: Random Forest
Random Forest on yhtyeen oppiminen menetelmä, joka laskee tulosten keskiarvon joukosta päätöksentekopuut luoda yleisen ennusteen lopputuloksesta.

Lähde: https://www.tutorialandexample.com/wp-content/uploads/2019/10/Decision-Trees-Root-Node.png
Jos olet tutkinut sitä edes niin vähän kuin katsonut Paluu tulevaisuuteen Trilogia, päätöspuu itsessään on melko helppo käsitteellistää: edessäsi on useita polkuja, ja jokainen polku haarautuu uuteen lopputulokseen, joka puolestaan sisältää muita mahdollisia polkuja.
In vahvistaminen oppiminen, saatat vetäytyä polulta ja aloittaa uudelleen aikaisemmasta asenteesta, kun taas päätöspuut sitoutuvat matkoinsa.
Siten Random Forest -algoritmi on olennaisesti hajaveto päätöksille. Algoritmia kutsutaan "satunnaiseksi", koska se tekee ad hoc valintoja ja havaintoja ymmärtääkseen mediaani päätöspuutaulukon tulosten summa.
Koska se ottaa huomioon useita tekijöitä, Random Forest -lähestymistapa voi olla vaikeampi muuntaa merkityksellisiksi kaavioiksi kuin päätöspuu, mutta se on todennäköisesti huomattavasti tuottavampi.
Päätöspuut ovat alttiita ylisovitukselle, jolloin saadut tulokset ovat datakohtaisia eivätkä todennäköisesti yleisty. Random Forestin mielivaltainen tietopisteiden valinta taistelee tätä taipumusta vastaan ja kohdistaa tiedon merkityksellisiin ja hyödyllisiin edustaviin trendeihin.

Päätöspuun regressio. Lähde: https://scikit-learn.org/stable/auto_examples/tree/plot_tree_regression.html
Suosittu käyttö
Kuten monet tämän luettelon algoritmit, Random Forest toimii tyypillisesti tietojen "varhaisena" lajittelijana ja suodattimena, ja sellaisena sitä esiintyy jatkuvasti uusissa tutkimuspapereissa. Joitakin esimerkkejä Random Forestin käytöstä ovat mm Magneettiresonanssikuvan synteesi, Bitcoinin hintaennuste, väestönlaskennan segmentointi, tekstin luokittelu ja luottokorttipetosten havaitseminen.
Koska Random Forest on koneoppimisarkkitehtuurien matalan tason algoritmi, se voi myös edistää muiden matalan tason menetelmien suorituskykyä sekä visualisointialgoritmeja, mukaan lukien Induktiivinen klusterointi, Ominaisuuden muunnokset, tekstiasiakirjojen luokittelu käyttämällä niukkoja ominaisuuksiaja putkilinjojen näyttäminen.
6: Naiivi Bayes
Yhdessä tiheysarvion kanssa (katso 4, yllä), a naiivi Bayes luokitin on tehokas mutta suhteellisen kevyt algoritmi, joka pystyy arvioimaan todennäköisyyksiä datan laskettujen ominaisuuksien perusteella.

Ominaisuussuhteet naiivissa Bayes-luokittimessa. Lähde: https://www.sciencedirect.com/topics/computer-science/naive-bayes-model
Termi "naiivi" viittaa olettamukseen Bayesin lause että ominaisuudet eivät liity toisiinsa, tunnetaan nimellä ehdollinen riippumattomuus. Jos omaksut tämän kannan, käveleminen ja puhuminen kuin ankka eivät riitä osoittamaan, että olemme tekemisissä ankan kanssa, eikä mitään "ilmeisiä" oletuksia hyväksytä ennenaikaisesti.
Tämä akateemisen ja tutkivan kurinalaisuuden taso olisi ylivoimaista silloin, kun "tervettä järkeä" on saatavilla, mutta se on arvokas standardi, kun käydään läpi monia epäselvyyksiä ja mahdollisesti toisiinsa liittymättömiä korrelaatioita, joita koneoppimistietojoukossa saattaa olla.
Alkuperäisessä Bayes-verkossa ominaisuuksia koskevat pisteytystoiminnot, mukaan lukien kuvauksen vähimmäispituus ja Bayesin maalinteko, joka voi asettaa datalle rajoituksia datapisteiden välisten arvioitujen yhteyksien ja näiden yhteyksien virtaussuunnan suhteen.
Naiivi Bayes-luokitin sitä vastoin toimii olettamalla, että tietyn kohteen piirteet ovat riippumattomia, ja käyttää myöhemmin Bayesin lausetta laskeakseen tietyn objektin todennäköisyyden sen ominaisuuksien perusteella.
Suosittu käyttö
Naive Bayes -suodattimet ovat hyvin edustettuina sairauden ennustaminen ja dokumenttien luokittelu, roskapostin suodatus, mielipiteen luokitus, suositusjärjestelmätja petosten havaitseminen, muiden sovellusten joukossa.
7: K- Lähimmät naapurit (KNN)
Ensin ehdotti Yhdysvaltain ilmavoimien ilmailulääketieteen koulu vuonna 1951, ja sen on mukauduttava 20-luvun puolivälin laskentalaitteiston huippuunsa, K-Lähimmät naapurit (KNN) on kevyt algoritmi, joka on edelleen näkyvästi esillä akateemisissa julkaisuissa ja yksityisen sektorin koneoppimistutkimusaloitteissa.
KNN:tä on kutsuttu "laiskaksi oppijaksi", koska se skannaa tyhjentävästi tietojoukon arvioidakseen datapisteiden välisiä suhteita sen sijaan, että se vaatisi täysimittaisen koneoppimismallin koulutusta.

KNN-ryhmä. Lähde: https://scikit-learn.org/stable/modules/neighbors.html
Vaikka KNN on arkkitehtonisesti hoikka, sen systemaattinen lähestymistapa asettaa huomattavan vaatimuksen luku-/kirjoitusoperaatioille, ja sen käyttö erittäin suurissa aineistoissa voi olla ongelmallista ilman lisätekniikoita, kuten PCA (Principal Component Analysis), joka voi muuttaa monimutkaisia ja suuria tietojoukkoja. sisään edustavia ryhmiä jonka KNN voi kulkea pienemmällä vaivalla.
A Tuoreen tutkimuksen arvioi useiden algoritmien tehokkuuden ja taloudellisuuden, joiden tehtävänä oli ennustaa, lähteekö työntekijä yrityksestä, ja havaitsi, että seitsemän vuoden ikäinen KNN oli parempi kuin nykyaikaisemmat kilpailijat tarkkuuden ja ennakoivan tehokkuuden suhteen.
Suosittu käyttö
Kaikesta suositusta konseptinsa ja toteutuksensa yksinkertaisuudesta huolimatta KNN ei ole juuttunut 1950-luvulle, vaan se on mukautettu DNN-keskeisempi lähestymistapa Pennsylvania State Universityn vuoden 2018 ehdotuksessa, ja se on edelleen keskeinen varhaisen vaiheen prosessi (tai jälkikäsittelyn analyyttinen työkalu) monissa paljon monimutkaisemmissa koneoppimiskehyksissä.
Eri kokoonpanoissa KNN:ää on käytetty tai varten online-allekirjoituksen vahvistus, kuvan luokittelu, tekstin louhinta, sadon ennusteja kasvot, muiden sovellusten ja liitäntöjen lisäksi.

KNN-pohjainen kasvojentunnistusjärjestelmä koulutuksessa. Source: https://pdfs.semanticscholar.org/6f3d/d4c5ffeb3ce74bf57342861686944490f513.pdf
8: Markovin päätösprosessi (MDP)
Amerikkalaisen matemaatikko Richard Bellmanin esittelemä matemaattinen viitekehys vuonna 1957, Markovin päätösprosessi (MDP) on yksi peruslohkoista vahvistaminen oppiminen arkkitehtuurit. Käsitteellinen algoritmi itsessään, se on mukautettu lukuisiin muihin algoritmeihin ja toistuu usein nykyisessä AI/ML-tutkimuksessa.
MDP tutkii tietoympäristöä arvioimalla sen nykyistä tilaa (eli missä se on tiedoissa) päättääkseen, mitä datan solmua tutkia seuraavaksi.

Lähde: https://www.sciencedirect.com/science/article/abs/pii/S0888613X18304420
Markovin peruspäätösprosessi asettaa etusijalle lyhyen aikavälin edut toivottavampiin pitkän aikavälin tavoitteisiin nähden. Tästä syystä se on yleensä upotettu vahvistetun oppimisen kattavamman politiikan arkkitehtuuriin, ja siihen vaikuttavat usein rajoittavat tekijät, kuten esim. alennettu palkintoja muut muuttavat ympäristömuuttujat, jotka estävät sitä kiirehtimästä kohti välitöntä tavoitetta ottamatta huomioon laajempaa toivottua tulosta.
Suosittu käyttö
MDP:n matalan tason konsepti on laajalle levinnyt sekä tutkimuksessa että koneoppimisen aktiivisessa käyttöönotossa. Sitä on ehdotettu IoT-turvallisuusjärjestelmät, kalan kerääminenja markkinoiden ennustaminen.
Sen lisäksi ilmeinen soveltuvuus shakissa ja muissa tiukasti peräkkäisissä peleissä MDP on myös luonnollinen kilpailija robotiikkajärjestelmien menettelykoulutus, kuten näemme alla olevasta videosta.

9: Termitaajuus-käänteinen asiakirjataajuus
Termitaajuus (TF) jakaa sen, kuinka monta kertaa sana esiintyy asiakirjassa, kyseisen asiakirjan sanojen kokonaismäärällä. Siis sana tiiviste kerran esiintyvän tuhannen sanan artikkelissa termitaajuus on 0.001. TF itsessään on suurelta osin hyödytön termien tärkeyden indikaattorina, koska merkityksettömiä artikkeleita (esim. a, ja, Ishayoiden opettamanja it) hallitsevat.
Saadakseen termille merkityksellisen arvon käänteinen asiakirjataajuus (IDF) laskee sanan TF:n useissa tietojoukossa olevissa asiakirjoissa ja antaa matalan arvosanan erittäin korkealle taajuudelle. ohitettavien sanojen, kuten artikkeleita. Tuloksena saadut piirrevektorit normalisoidaan kokonaisiksi arvoiksi, ja jokaiselle sanalle annetaan sopiva paino.

TF-IDF painottaa termien merkityksellisyyttä useissa asiakirjoissa esiintymistiheyden perusteella, ja harvinaisempi esiintyminen on näkyvyyden osoitus. Lähde: https://moz.com/blog/inverse-document-frequency-and-the-importance-of-uniqueness
Vaikka tämä lähestymistapa estää semanttisesti tärkeiden sanojen katoamisen harha, taajuuden painon kääntäminen ei automaattisesti tarkoita, että matalataajuinen termi on emme poikkeava, koska jotkut asiat ovat harvinaisia ja arvoton. Siksi harvoin esiintyvän termin on todistettava arvonsa laajemmassa arkkitehtonisessa kontekstissa esittämällä (jopa harvoin asiakirjaa kohden) useissa tietojoukon asiakirjoissa.
Siitä huolimatta ikä, TF-IDF on tehokas ja suosittu menetelmä passien alkusuodattamiseen Natural Language Processing -kehyksessä.
Suosittu käyttö
Koska TF-IDF on osallistunut ainakin jonkin verran Googlen pitkälti okkulttisen PageRank-algoritmin kehitykseen viimeisen kahdenkymmenen vuoden aikana, siitä on tullut hyvin laajasti hyväksytty manipuloivana SEO-taktiikkana John Muellerin 2019:stä huolimatta mitätöintiin sen merkityksestä hakutuloksille.
PageRank-salaisuuden vuoksi ei ole selvää näyttöä siitä, että TF-IDF on emme tällä hetkellä tehokas taktiikka Googlen rankingissa nousuun. Sytyttävä keskustelu IT-ammattilaisten keskuudessa viime aikoina osoittaa yleisen ymmärryksen, olipa oikein tai ei, että termin väärinkäyttö voi silti johtaa parantuneeseen hakukoneoptimointiin (vaikka lisää syytökset monopolin väärinkäytöstä ja liiallinen mainonta hämärtää tämän teorian rajoja).
10: Stokastinen gradienttilasku
Stokastinen gradienttilasku (SGD) on yhä suositumpi menetelmä koneoppimismallien koulutuksen optimointiin.
Gradient Descent itsessään on menetelmä optimoida ja myöhemmin kvantifioida mallin harjoittelun aikana tekemä parannus.
Tässä mielessä 'kaltevuus' tarkoittaa kaltevuutta alaspäin (eikä väripohjaista asteikkoa, katso alla oleva kuva), jossa vasemmalla olevan 'kukkulan' korkein kohta edustaa harjoitusprosessin alkua. Tässä vaiheessa malli ei ole vielä kertaakaan nähnyt koko dataa eikä ole oppinut tarpeeksi datan välisistä suhteista tehokkaiden muunnosten tuottamiseksi.

Gradienttilasku FaceSwap-harjoittelussa. Voimme nähdä, että harjoittelu on tasaantunut jonkin aikaa toisella puoliskolla, mutta on lopulta palautunut alaspäin gradienttia kohti hyväksyttävää lähentymistä.
Alin piste oikealla edustaa konvergenssia (piste, jossa malli on yhtä tehokas kuin se koskaan tulee asetettujen rajoitusten ja asetusten alaisena).
Gradientti toimii tietueena ja ennustajana virhesuhteen (kuinka tarkasti malli on tällä hetkellä kartoittanut datasuhteet) ja painojen (asetukset, jotka vaikuttavat tapaan, jolla malli oppii) välillä.
Tätä edistymistä voidaan käyttää tiedottamaan a oppimisnopeusaikataulu, automaattinen prosessi, joka käskee arkkitehtuuria muuttumaan rakeisemmaksi ja tarkemmaksi, kun varhaiset epämääräiset yksityiskohdat muuttuvat selkeiksi suhteiksi ja kartoituksiksi. Itse asiassa gradienttihäviö tarjoaa juuri-in-time-kartan siitä, mihin koulutuksen tulisi mennä seuraavaksi ja miten sen tulisi edetä.
Stochastic Gradient Descentin innovaatio on, että se päivittää mallin parametrit jokaisessa harjoitusesimerkissä iteraatiokohtaisesti, mikä yleensä nopeuttaa matkaa konvergenssiin. Hypermittakaavaisten tietokokonaisuuksien myötä viime vuosina SGD:n suosio on kasvanut viime aikoina yhtenä mahdollisena tapana käsitellä logistisia ongelmia.
Toisaalta SGD:llä on negatiivisia seurauksia ominaisuuden skaalausta varten, ja se saattaa vaatia enemmän iteraatioita saman tuloksen saavuttamiseksi, mikä edellyttää lisäsuunnittelua ja lisäparametreja verrattuna tavalliseen Gradient Descentiin.
Suosittu käyttö
Konfiguroitavuutensa ansiosta ja puutteistaan huolimatta SGD:stä on tullut suosituin neuroverkkojen sovitusalgoritmi. Yksi SGD:n konfiguraatio, josta on tulossa hallitseva uusissa AI/ML-tutkimuspapereissa, on Adaptive Moment Estimation (ADAM, otettu käyttöön) valinta. vuonna 2015) optimoija.
ADAM mukauttaa kunkin parametrin oppimisnopeuden dynaamisesti ('adaptiivinen oppimisnopeus') sekä sisällyttää aikaisempien päivitysten tulokset myöhempään konfiguraatioon ('momentum'). Lisäksi se voidaan konfiguroida käyttämään myöhempiä innovaatioita, kuten Nesterov Momentum.
Jotkut kuitenkin väittävät, että liikemäärän käyttö voi myös nopeuttaa ADAM:ia (ja vastaavia algoritmeja) a optimaalinen johtopäätös. Kuten useimmat koneoppimisen tutkimussektorin syrjäytyneet reunat, SGD on työn alla.
Julkaistu ensimmäisen kerran 10. Muutettu 2022 EET – muotoilu.















