Tekoäly
SofGAN: GAN-kasvokuvien generoija, joka tarjoaa suuremman hallinnan
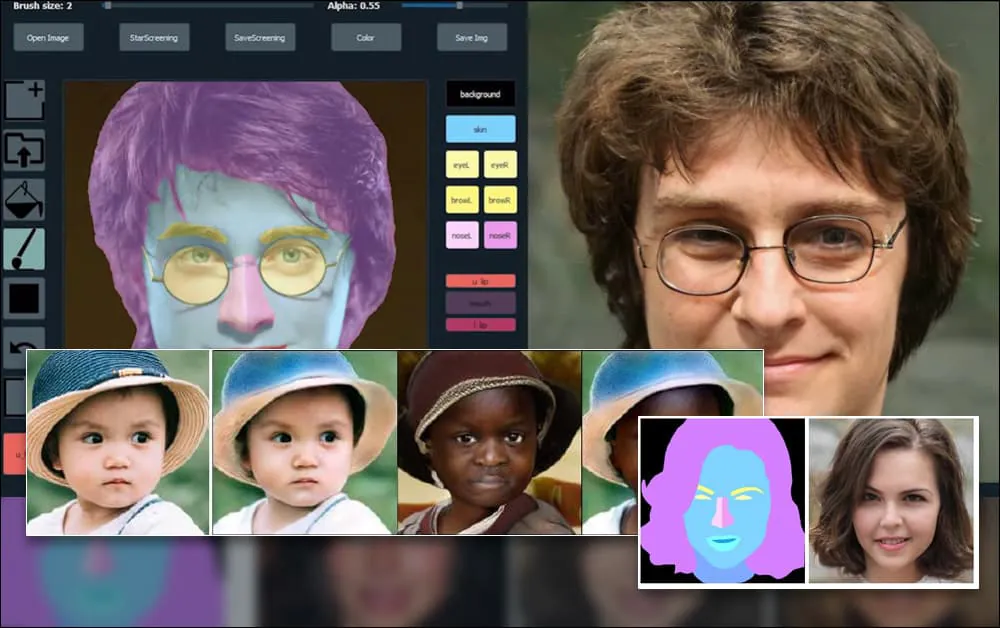
Shanghain ja Yhdysvaltain tutkijat ovat kehittäneet GAN-pohjaisen muotokuvien generointijärjestelmän, joka mahdollistaa käyttäjille uusien kasvojen luomisen aiempaa suuremmalla hallinnalla yksittäisiin näkökohtiin, kuten hiuksiin, silmiin, laseihin, tekstuureihin ja väreihin.
Järjestelmän monipuolisuuden osoittamiseksi luojat ovat tarjonneet Photoshop-tyylisen käyttöliittymän, jossa käyttäjä voi piirtää suoraan semanttisia segmentointielementtejä, jotka tulkitaan realistiseksi kuvaksi, ja jotka voidaan myös hankkia piirtämällä suoraan olemassa olevien valokuvien päälle.
Esimerkiksi alla olevassa kuvassa näytetään, kuinka näyttelijä Daniel Radcliffen kuva käytetään piirrosmallina (ja tavoitteena ei ole tuottaa hänen kaltaistensa kasvoja, vaan yleisesti fotorealistinen kuva). Kun käyttäjä täyttää eri elementtejä, kuten erillisiä piirteitä, kuten laseja, ne tunnistetaan ja tulkitaan tulostekuvassa:
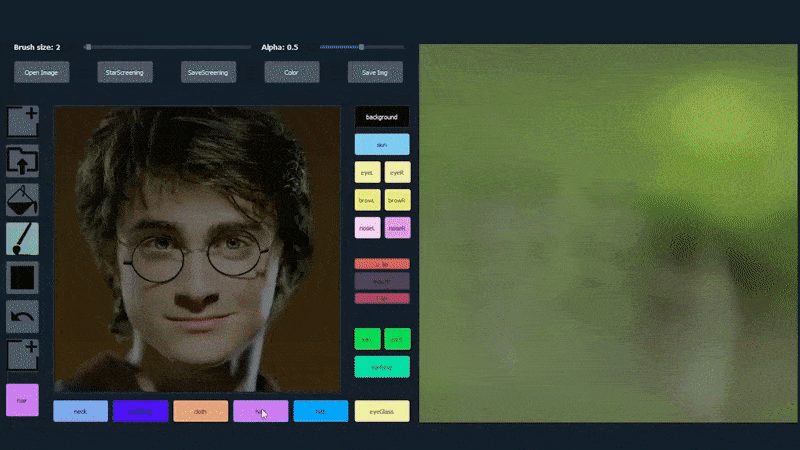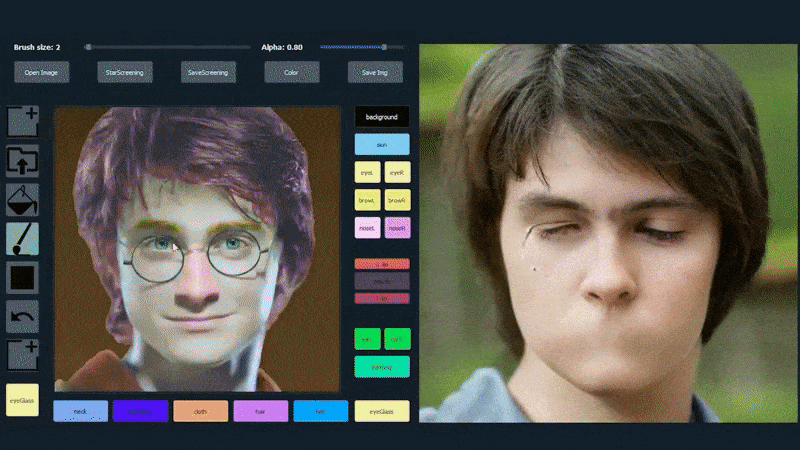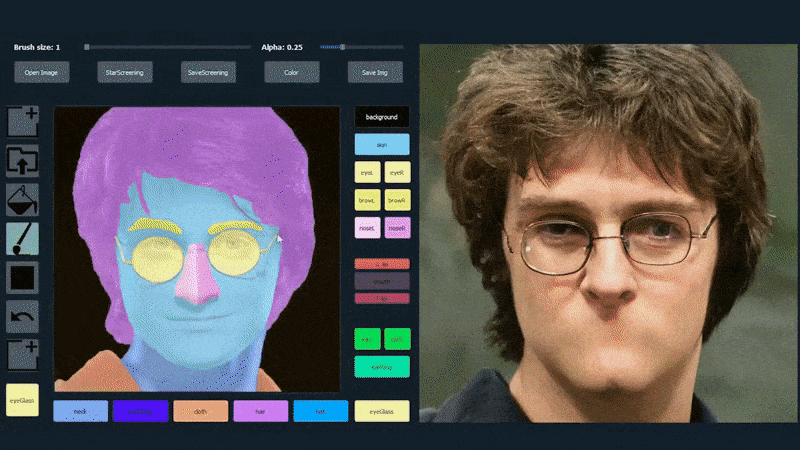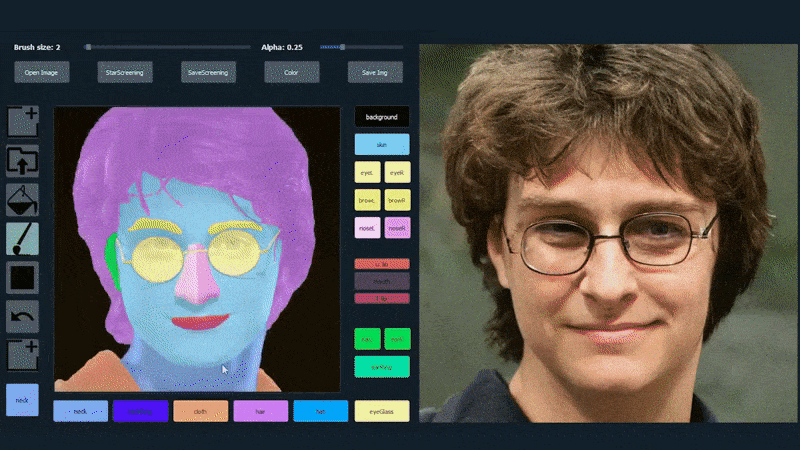
Käyttäen yhtä kuvaa piirrosmallina SofGAN-kasvokuvalle. Lähde: https://www.youtube.com/watch?v=xig8ZA3DVZ8
Artikkeli on nimeltään SofGAN: A Portrait Image Generator with Dynamic Styling, ja sen ovat johtaneet Anpei Chen ja Ruiyang Liu yhdessä kahden muun ShanghaiTech-yliopiston tutkijan ja yhden Kalifornian yliopiston San Diegon tutkijan kanssa.
Disentangling Features
Työn pääasiallinen panos ei ole niinkään käyttäjäystävällisessä käyttöliittymässä, vaan enemminkin “disentangling” -ominaisuuksissa, joissa opitut kasvonpiirteet, kuten asento ja tekstuuri, voidaan erottaa toisistaan, mikä mahdollistaa SofGAN:lle myös kasvojen generoimisen, jotka ovat kameran näkökulmasta katsottuna epäsuorassa kulmassa.

Harvinaista kasvokuvien generoijien joukossa, jotka perustuvat Generative Adversarial Networks -tekniikkaan, SofGAN voi muuttaa katselukulmaa halutessaan, koulutusaineiston mukaisesti. Lähde: https://arxiv.org/pdf/2007.03780.pdf
Koska tekstuuri on nyt eriytetty geometriasta, kasvon muoto ja tekstuuri voidaan myös muokata erillisinä kokonaisuuksina. Tämä mahdollistaa myös rodun muuttamisen alkuperäisistä kasvoista, mikä on aiemmin ollut kiistanalainen käytäntö, mutta nyt sillä on mahdollisesti hyödyllinen sovellus esimerkiksi tasa-arvoisempien koneoppimisaineistojen luomiseen.

SofGAN tukee myös keinotekoista vanhenemista ja ominaisuuskohtaista tyylin säätöä hienojakoisella tasolla, jota ei ole aiemmin nähty vastaavissa segmentointi>kuvajärjestelmissä, kuten NVIDIAN GauGAN ja Intelin pelipohjaisessa neurorenderöintijärjestelmässä.

SofGAN pystyy toteuttamaan vanhenemisen iteratiivisena tyylina.
SofGAN:n menetelmän toinen läpimurto on, että koulutus ei vaadi pareittaisia segmentointi/reaalikuvia, vaan se voidaan kouluttaa suoraan parittomista, maailmanlaajuisista kuvista.
Tutkijat toteavat, että SofGAN:n “disentangling” -arkkitehtuuri sai inspiraationsa perinteisistä kuvan renderöintijärjestelmistä, jotka hajottavat kuvan yksittäisiin osiin. Visuaalisten efektien työvirrassa komponentit yhdistetään usein yksityiskohtaisesti, ja jokaiselle komponentille on omat erikoistuneet asiantuntijat.
Semanttinen Occupancy Field (SOF)
Tämän saavuttamiseksi koneoppimisen kuvasynteesirunkossa tutkijat kehittivät semanttisen occupancy field (SOF), joka on laajennus perinteisestä occupancy field -tekniikasta, joka erottaa kasvokuvien yksittäiset osat. SOF koulutettiin kalibroituilla moninäkökulmaisilla semanttisilla segmentointikartoilla, ilman mitään ohjausta.

Useita iteraatioita yhdestä segmentointikartasta (alhaalla vasemmalla).
Lisäksi 2D-segmentointikartat saadaan säteilytallentamalla SOF:n tulostetta, ennen kuin ne teksturoidaan GAN-generaattorilla. “Synthetic” semanttiset segmentointikartat koodataan myös matalatiheysavaruuteen kolmen kerroksen koodarin kautta, jotta varmistetaan jatkuvuus, kun näkökulmaa muutetaan.
Koulutussuunnitelma sekoittaa tilallisesti kaksi satunnaista tyyliä kullekin semanttiselle alueelle:

SofGAN:n arkkitehtuuri.
Tutkijat väittävät, että SofGAN saavuttaa alemman Frechet Inception Distance (FID) kuin nykyiset vaihtoehtoiset valtavirta-lähestymistavat, sekä korkeamman Learned Perceptual Image Patch Similarity (LPIPS) -mittarin.
Aikaisemmat StyleGAN-lähestymistavat ovat usein kärsineet ominaisuussekoittumisesta, jossa kuvan muodostavat osat ovat kiinteästi sidottuja toisiinsa, mikä aiheuttaa ei-toivottuja elementtejä halutun elementin rinnalla (esim. korvakorut saattavat ilmestyä, kun korvan muoto renderöidään, ja se on koulutuksen aikana perustunut kuvaan, jossa korvakorut oli).

Säteilytallennus käytetään semanttisten segmentointikarttojen tilavuuden laskemiseen, mikä mahdollistaa useita näkökulmia.
Datasets and Training
Kolmea tietojoukkoa käytettiin SofGAN:n kehittämisessä: CelebAMask-HQ, joka sisältää 30 000 korkean resoluution kuvaa CelebA-HQ-tietojoukosta; NVIDIAN Flickr-Faces-HQ (FFHQ), joka sisältää 70 000 kuvaa, joissa tutkijat merkitsivät kuvat esikoulutetulla kasvoparserilla; ja itse tuotettu ryhmä 122 muotokuvaa, joissa on manuaalisesti merkityt semanttiset alueet.
SOF koostuu kolmesta koulutettavasta alimodulista – hyperverkosta, säteilytallentimesta (ks. yllä oleva kuva) ja luokittelijasta. Projektiin liittyvä Semantic Instance Wised (SIW) StyleGAN-generaattori on muodostettu samankaltaisesti kuin StyleGAN2 tietyissä suhteissa. Data-augmentaatio toteutetaan satunnaisella skaalauksella ja leikkaamisella, ja koulutuksessa on polun sääntely joka neljäs askel. Koko koulutusprosessi kesti 22 päivää saavuttaakseen 800 000 iteraatiota neljällä RTX 2080 Ti -näytönohjaimella CUDA 10.1:llä.
Tutkijat huomauttavat, että hyväksyttyjä, yleisiä, korkean tason tuloksia alkoi ilmestyä melko varhain koulutuksessa, 1500 iteraation jälkeen, kolme päivää koulutuksen aloittamisen jälkeen. Loppuosa koulutuksesta kului hitaasti tarkkojen yksityiskohtien, kuten hiusten ja silmien piirteiden, saavuttamiseen.
SofGAN saavuttaa yleensä realistisempia tuloksia yhdestä segmentointikartasta kuin kilpailevat menetelmät, kuten NVIDIAN SPADE ja Pix2PixHD, sekä SEAN.

Alla on tutkijoiden julkaisema video. Lisää itse isännöityjä videoita on saatavilla projektisivulla.
https://www.youtube.com/watch?v=xig8ZA3DVZ8













{kind=link}