Tekoäly
Luo omat generatiiviset vastakkainasettelijaverkkosi piirroksilla

Carnegie Mellonista ja MIT:stä olevat tutkijat ovat kehittäneet uuden metodologian, joka mahdollistaa käyttäjälle oman generatiivisen vastakkainasettelijaverkon (GAN) kuvien luomisjärjestelmän luomisen yksinkertaisesti piirtämällä osoittavia viivapiirroksia.
Tällainen järjestelmä voisi mahdollistaa loppukäyttäjälle kuvien luomisjärjestelmien luomisen, jotka pystyvät luomaan erittäin tarkkoja kuvia, kuten tiettyjä eläimiä, rakennusten tyyppejä ja jopa yksittäisiä ihmisiä. Tällä hetkellä useimmat GAN-kuvien luomisjärjestelmät tuottavat laajoja ja melko satunnaisia tuloksia, joissa on rajoitettu mahdollisuus määritellä tiettyjä ominaisuuksia, kuten eläinten rotu, ihmisten hiusten tyypit, arkkitehtuurin tyylit tai todelliset kasvonpiirteet.
Lähestymistapa, josta on kerrottu artikkelissa Piirrä oma GAN, käyttää uutta piirrosliittymää tehokkaana “hakufunktiona” löytääksesi ominaisuuksia ja luokkia muuten ylikuormitettujen kuvatietokantojen joukosta, jotka saattavat sisältää tuhansia erilaisia objekteja, mukaan lukien monia alaluokkia, jotka eivät ole merkityksellisiä käyttäjän aikomukselle.
GAN koulutetaan tästä suodatetusta kuvien alijoukosta.
Piirtämällä tarkalleen objektityyppiä, jonka kanssa käyttäjä haluaa kalibroida GANin, kehyksen generoivat ominaisuudet erikoistuvat tähän luokkaan. Esimerkiksi, jos käyttäjä haluaa luoda kehyksen, joka luo tietyn kissatyypin (ei vain mitä tahansa vanhaa kissaa, kuten This Cat Does Not Exist), heidän piirroksensa toimivat suodattimena, joka poistaa epäolennaiset kissaluokat.

Lähde: https://peterwang512.github.io/GANSketching/
Tutkimus on johtanut Sheng Yu-Wangia Carnegie Mellonin yliopistosta, yhdessä kollegansa Jun-Yan Zhun ja David Bauin kanssa MIT:n tietojenkäsittely- ja tekoälylaboratoriosta.
Menetelmä itsessään on kutsuttu ‘GAN-piirroksiksi’, ja se käyttää syötteenä annettuja piirroksia suoraan muuttaakseen ‘malli-GAN-mallin’ painoja kohdistamaan tunnistettuun domeeniin tai alidomeeniin erilaisten vastakkainasettelijoiden tappion kautta.
Eri sääntömenetelmiä tutkittiin varmistamaan, että mallin tuloste on monipuolinen, säilyttäen samalla korkean kuvanlaadun. Tutkijat loivat näytteellisiä sovelluksia, jotka pystyvät interpoloimaan latenttiluvun ja suorittamaan kuvanmuokkaustoimia.
Tämä [$class] ei ole olemassa
GAN-pohjaiset kuvien luomisjärjestelmät ovat muodostuneet muodiksi, ellei meemeiksi, viimeisten vuosien aikana, projektien lisääntyessä, jotka pystyvät luomaan kuvia olemattomista asioista, mukaan lukien ihmiset, vuokra-asunnot, välipalat, jalat, hevoset, poliitikot ja hyönteiset, muun muassa.
GAN-pohjaiset kuvien luomisjärjestelmät luodaan kokoamalla tai kuratoidessa laajoja tietokantoja, jotka sisältävät kuvia kohdekuvasta, kuten kasvoista tai hevosoista; kouluttamalla malleja, jotka yleistävät joukon ominaisuuksia kuvissa tietokannassa; ja toteuttamalla generoivat moduulit, jotka voivat tuottaa satunnaisia esimerkkejä opitun ominaisuuksien perusteella.

DeepFacePencilin piirrosten tuloste. Monia samankaltaisia piirros-kuvaprojekteja on olemassa. Lähde: https://arxiv.org/pdf/2008.13343.pdf
Korkeatulosteiset ominaisuudet ovat ensimmäisiä, jotka konkretisoidaan koulutusprosessin aikana, ja ne ovat vastaavia kuin maalarin ensimmäiset laajat värikuorrutukset kanvakselle. Nämä korkeatulosteiset ominaisuudet korreloivat lopulta tarkempiin ominaisuuksiin (esim. kissan silmänkiilto ja terävät viikset, eikä vain geneerinen beigen vaahto, joka edustaa päätä).
Tiedän, mitä tarkoitat…
Karttamalla suhdetta näiden varhaisempien alkuperäisten muotojen ja lopulta yksityiskohtaisten tulkintojen välillä, jotka saadaan myöhemmin koulutusprosessin aikana, on mahdollista johtaa suhteita “epämääräisten” ja “tarkkojen” kuvien välillä, jolloin käyttäjät voivat luoda monipuolisia ja fotorealistisia kuvia karkeista viivapiirroksista.
NVIDIA julkaisi hiljattain pöytäversion pitkäaikaisesta GauGAN-tutkimuksestaan GAN-pohjaisen maiseman luomiseksi, joka osoittaa helposti tämän periaatteen:
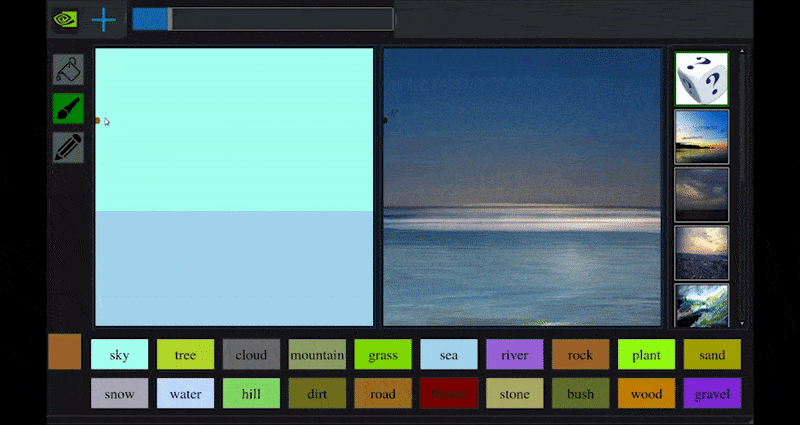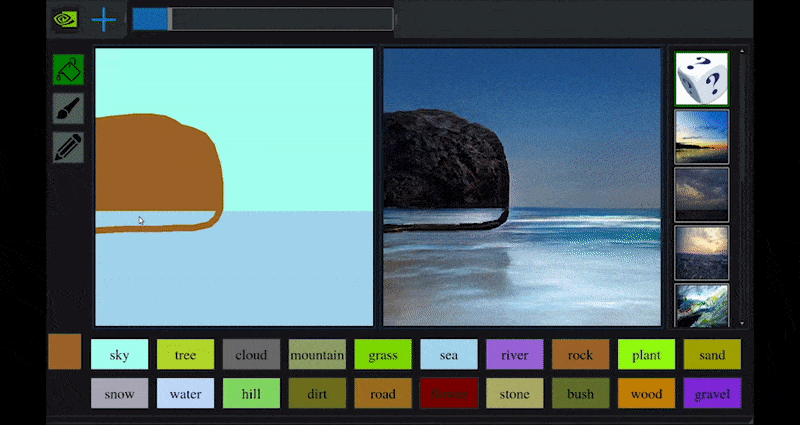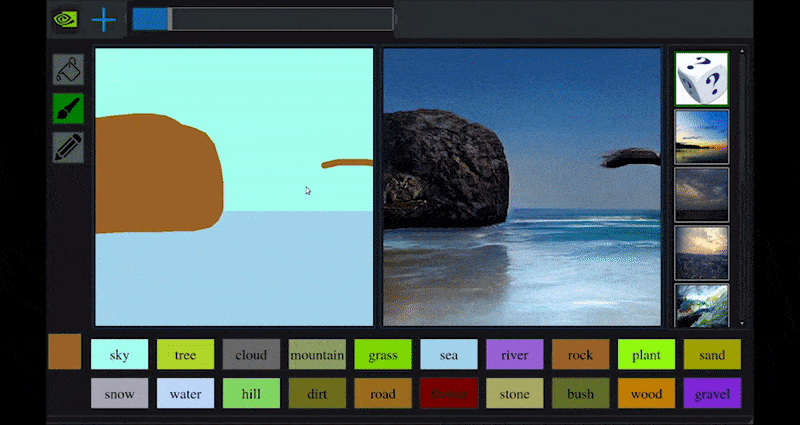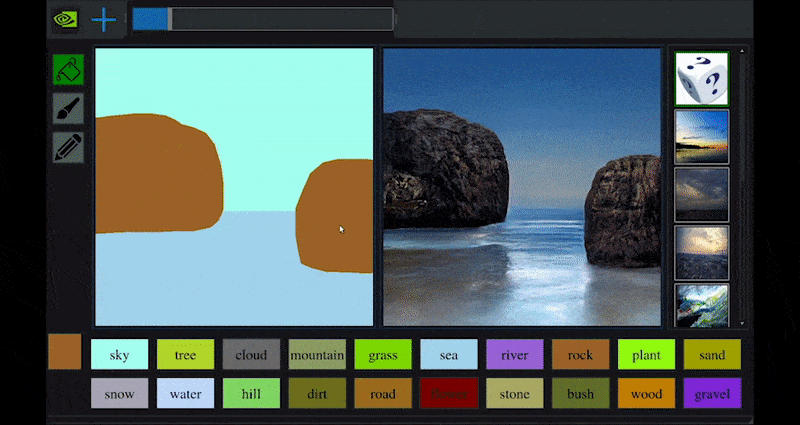
Lähestyskohtia käännetään rikkaiksi maisemikuviksi NVIDIA:n GauGANin ja nyt NVIDIA Canvas -sovelluksen kautta. Lähde: https://rossdawson.com/futurist/implications-of-ai/future-of-ai-image-synthesis/
Samanlainen DeepFacePencil on käyttänyt samaa periaatetta luomaan piirroskäyttöisiä fotorealistisia kuvien luojia eri aloille.

DeepFacePencilin arkkitehtuuri.
Piirros-kuvan yksinkertaisuus
Uuden artikkelin GAN-piirroslähestymistapa pyrkii poistamaan vaativan datan keräämisen ja kuratoinnin, joka on tyypillisesti osa GAN-kuvajärjestelmien kehittämistä, käyttämällä käyttäjän syötettä määrittämään, mikä alijoukko kuvista muodostaa koulutusdatan.
Järjestelmä on suunniteltu vaativan vain pienen määrän syötteenä annettuja piirroksia kalibroidakseen kehyksen. Järjestelmä kääntää toiminnon PhotoSketch-järjestelmän, joka on yhteinen tutkimushanke vuodelta 2019 Carnegie Mellonin, Adoben, Uber ATG:n ja Argo AI:n tutkijoiden kanssa, ja se sisältyy uuteen työhön. PhotoSketch oli suunniteltu luomaan taiteellisia piirroksia kuvista, ja se sisältää jo tehokkaan karttamisen epämääräisten ja tarkkojen kuvien luomissuhteita.
Koulutusprosessin osalta uusi menetelmä muuttaa vain StyleGAN2:n painoja. Koska kuvadata, jota käytetään, on vain osa koko saatavilla olevasta datasta, pelkästään muokkaamalla karttaverkkoa saadaan toivottuja tuloksia.
Menetelmää arvioitiin useilla suosituilla alaluokilla, mukaan lukien hevonen, kirkot ja kissat.

Princetonin yliopiston LSUN-tietokanta vuodelta 2016 käytettiin ydinmateriaalina, josta johdettiin kohde-alaluokat. Jotta voidaan perustaa piirroskarttajärjestelmä, joka on robusti maailmanlaajuisten käyttäjien piirrosten ominaisuuksille, järjestelmä koulutetaan Microsoftin QuickDraw-tietokannasta vuosina 2021-2016.
Vaikka piirroskarttamerkit PhotoSketchin ja QuickDraw’n välillä ovat melko erilaiset, tutkijat totesivat, että heidän kehyksensä onnistuu hyvin ylittämään ne melko helposti yksinkertaisissa asennoissa, vaikka monimutkaisemmat asennot (kuten kissat makaa) osoittautuvat haasteellisemmiksi, ja hyvin abstraktit käyttäjän syötteet (esim. liian karkeat piirrokset) heikentävät tulosten laatua.

Latenttiluvun ja luonnollisen kuvanmuokkauksen tila
Tutkijat kehittivät kaksi sovellusta perustyön pohjalta: latenttiluvun muokkaus ja kuvanmuokkaus. Latenttiluvun muokkaus tarjoaa tulkiteltavat käyttöliittymät, jotka toteutetaan koulutuksen aikana, ja sallivat laajan vaihtelun pysyen uskollisena kohdealueelle ja miellyttävän yhdenmukaisen vaihtelun muutoksissa.

Sileä latenttiluvun interpolointi GAN-piirrosten mukaisilla malleilla.
Latenttiluvun muokkauskomponentti perustui GANSpace-projektiin vuodelta 2020, joka on yhteinen hanke Aalto-yliopiston, Adoben, NVIDIA:n kanssa.
Yksittäinen kuva voidaan myös syöttää mukautettuun malliin, jolloin voidaan suorittaa luonnollista kuvanmuokkausta. Tässä sovelluksessa yksittäinen kuva projisoidaan mukautettuun GAN:iin, mahdollistaen suoran muokkauksen ja säilyttäen korkean latenttiluvun muokkausominaisuudet, jos sitä on käytetty.

Tässä todellinen kuva on käytetty syötteenä GAN:iin (kissamalli), joka muokkaa syötettä vastaamaan piirroksia. Tämä mahdollistaa kuvanmuokkauksen piirtämällä.
Vaikka järjestelmä on konfiguroitavissa, se ei ole suunniteltu toimimaan reaaliajassa, ainakin koulutuksen ja kalibroinnin osalta. Tällä hetkellä GAN-piirros vaatii 30 000 koulutusiteraatiota. Järjestelmä vaatii myös pääsyn alkuperäisiin koulutusdataan alkuperäiselle mallille.
Tapauksissa, joissa tietokanta on avoimen lähdekoodin ja sen lisenssi sallii paikallisen kopioinnin, tämä voidaan toteuttaa sisällyttämällä lähde-data paikallisesti asennettuun pakettiin, vaikka se vaatisi merkittävän levytilan; tai käsittelemällä dataa etäältä, pilviin perustuvalla lähestymistavalla, joka tuo mukanaan verkkoliikenteen viiveet ja (tapauksissa, joissa prosessointi tapahtuu pilvessä) mahdolliset laskennalliset kustannukset.

Muodonmuutokset mukautetuista FFHQ-malleista, jotka on koulutettu vain neljällä ihmisten luomalla piirroksella.












