Tekoäly
Kasvojen uudelleenmuokkaus videossa koneoppimisen avulla

Kiinan ja Yhdistyneen kuningaskunnan tutkimusyhteistyö on kehittänyt uuden menetelmän kasvojen muokkaamiseksi videossa. Tekniikka mahdollistaa vakuuttavan kasvonsillan levennys- ja kapeutensa muokkaamisen, korkealla johdonmukaisuudella ja ilman virheitä.
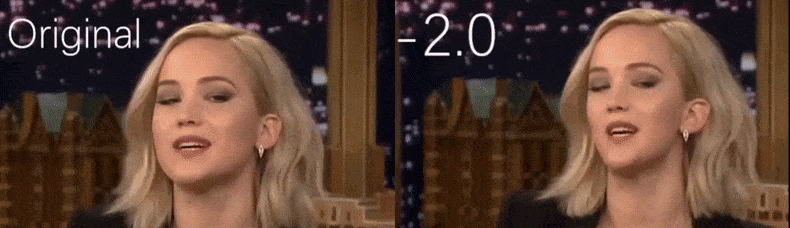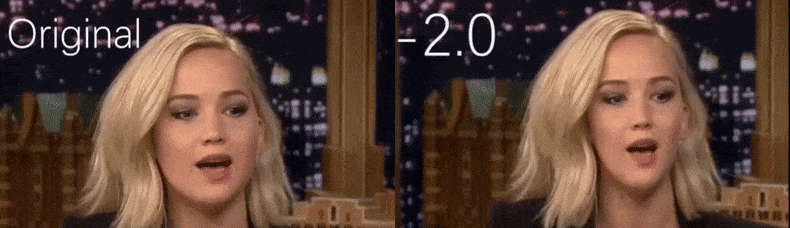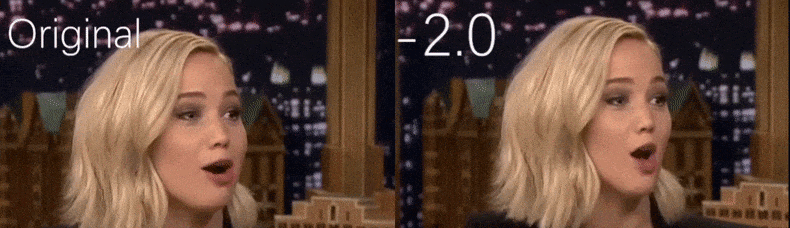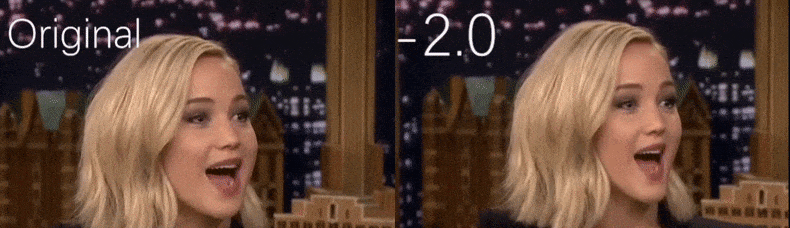
YouTube-videosta, jota tutkijat käyttivät lähdemateriaalina, näyttelijä Jennifer Lawrence näyttää enemmän kalpeana persoonana (oikea). Katso liitetty video artikkelin alaosassa, jossa on paljon enemmän esimerkkejä paremmassa resoluutiossa. Lähde: https://www.youtube.com/watch?v=tA2BxvrKvjE
Tällainen muodonmuutos on yleensä mahdollista vain perinteisillä CGI-menetelmillä, jotka vaatisivat kokonaan uudelleenluomisen kasvoja yksityiskohtaisen ja kalliin motion-capping-, rigging- ja texturing-menetelmien avulla.
Sen sijaan, mitä CGI:ä tässä tekniikassa on, se on integroitu neurorunkoon parametrina 3D-kasvotietona, jota käytetään myöhemmin koneoppimismenetelmän perustana.

Perinteiset parametrinen kasvot ovat yhä enemmän ohjeita muodonmuutosprosesseille, jotka käyttävät AI:ta sen sijaan, että CGI:ä. Lähde: https://arxiv.org/pdf/2205.02538.pdf
Tekijät toteavat:
‘Tavoitteemme on luoda korkealaatuisia muokattuja videokuvia kasvojen muodonmuokkauksella, joka perustuu luonnolliseen kasvojen muodonmuutokseen todellisessa maailmassa. Tätä voidaan käyttää sovelluksiin, kuten kasvojen kauneusmuodon luomiseen ja kasvojen liioittelua visuaalisia vaikutuksia varten.’
Vaikka 2D-kasvomuokkaus ja vääristymä on ollut kuluttajien saatavilla Photoshoppin myötä (ja johtanut outoihin ja usein epähyväksyttäviin alakulttuureihin kasvojen vääristymisen ja kehon dysmorfian ympärillä), on se vaikea temppu toteuttaa videossa ilman CGI:ä.

Mark Zuckerbergin kasvonmitat laajennettiin ja kavennettiin uudella kiinalais-brittiläisellä tekniikalla.
Kehon muokkaus on tällä hetkellä kiinnostuksen aihe tietokoneen näköalalla, pääasiassa sen potentiaalin vuoksi muodin verkkokaupassa, vaikka jonkun teko täyttymään pidemmäksi tai luurankomaisemmaksi on edelleen haasteellista.
Samanlainen kasvojen muodonmuutos videokuvassa johdonmukaisella ja vakuuttavalla tavalla on ollut aiemman tutkimuksen aihe uuden tutkimuksen tekijöillä, vaikka se toteutus kärsi virheistä ja rajoituksista. Uusi järjestelmä laajentaa aiemman tutkimuksen mahdollisuuksia staattisesta videotuotokseen.
Uusi järjestelmä koulutettiin työpöytätietokoneella, jossa on AMD Ryzen 9 3950X ja 32 GB muistia, ja se käyttää OpenCV:n optista virtausta liikkeen karttojen luomiseen, jota sileää StructureFlow-kehyksellä; Kasvojen suunnittelun verkkoa (FAN) kasvojen määritykseen, jota myös käytetään suositussa deepfake-paketeissa; ja Ceres Solveria optimointiongelmien ratkaisemiseen.

Äärimmäinen esimerkki kasvojen laajentamisesta uudella järjestelmällä.
Artikkeli on otsikoitu Parametrinen kasvojen muokkaus videossa, ja se on peräisin kolmelta Zhejiangin yliopiston tutkijalta ja yhdeltä Bathin yliopiston tutkijalta.
Kasvojen muokkaus
Uuden järjestelmän työkierto on määriteltävä tapauksissa, joissa subjekti kääntyy pois. Tämä on yksi suurimmista haasteista deepfake-ohjelmistossa, koska FAN-kohdistimet eivät voi ottaa huomioon näitä tapauksia, ja ne alkavat heiketä laadussa, kun kasvo kääntyy pois tai on peitetty.
Uusi järjestelmä voi välttää tämän ansan määrittelemällä reunaeenergian, joka pystyy vastaamaan 3D-kasvojen (3DMM) ja 2D-kasvojen (määritelty FAN-kohdistimilla) välistä rajaa.
Optimointi
Hyödyllinen käyttö tällaiselle järjestelmälle olisi toteuttaa reaaliaikainen muodonmuutos, esimerkiksi videopuheluiden suodattimissa. Nykyinen kehys ei mahdollista tätä, ja tarvittavat laskentaresurssit tekisivät “live”-muodonmuokkauksen merkittäväksi haasteeksi.
Artikkelin mukaan, olettaen 24 fps-videokohdetta, kehysprosessien viive on 16,344 sekuntia jokaiselle sekunnille kohtauksista, ja lisäksi on yksittäisiä iskuja identiteetin arvioinnille ja 3D-kasvojen muodonmuokkaukselle (321 ms ja 160 ms).
Optimointi on avainasemassa edistymiseen viiveen laskemiseksi. Koska yhteinen optimointi kaikissa kehyksissä lisäisi prosessiin merkittävää kuormitusta, ja init-tyyppinen optimointi (olettaen koko videon johdonmukaisen identiteetin ensimmäisestä kehyksestä) voisi johtaa poikkeamiin, tekijät ovat omaksuneet harvan scheman laskemaan kehyskertoimien kertoimia käytännöllisillä välein.
Yhteinen optimointi suoritetaan tämän kehysosajoukon kohdalla, mikä johtaa hoikkaamman prosessin jälleenrakentamiseen.
Kasvojen muokkaus
Käytetty muokkaustekniikka on sopeutus tekijöiden vuoden 2020 työstä Deep Shapely Portraits (DSP).

Deep Shapely Portraits, ACM Multimedian 2020-esitelmä. Artikkeli on johtavien tutkijoiden ZJU-Tencent Game and Intelligent Graphics Innovation Technology Joint Labista. Lähde: http://www.cad.zju.edu.cn/home/jin/mm2020/demo.mp4
Tekijät toteavat ‘Laajennamme tätä menetelmää yhden monokulaarisen kuvan muokkaamisesta koko kuvasekvenssin muokkaamiseen.’
Testit
Artikkeli toteaa, että ei ollut vertailukelpoista aineistoa, jotta uutta menetelmää voitiin arvioida. Sen sijaan tekijät vertasivat kehyksiä heidän muokatusta videotuotoksestaan staattiseen DSP-tuotokseen.

Uuden järjestelmän testaaminen staattisia kuvia Deep Shapely Portraitsista.
Tekijät toteavat, että DSP-menetelmästä johtuvat virheet johtuvat siitä, että se käyttää harvaa karttaa – ongelmaa, jonka uusi kehys ratkaisee tiheän kartan avulla. Lisäksi videota, jonka DSP tuottaa, artikkeli väittää, demonstroi sileäyttä ja visuaalista yhtenäisyyttä.
Tekijät toteavat:
‘Tulokset osoittavat, että lähestymistapamme voi luotettavasti tuottaa yhtenäisiä muokattuja videokuvia, kun taas kuvapohjainen menetelmä voi helposti johtaa havaittaviin vilkkuvien virheiden ilmestyessä.’
Katso liitetty video alla, jossa on lisää esimerkkejä:
Julkaistu ensimmäisen kerran 9. toukokuuta 2022. Muutettu klo 18.00 EET, korvattu ‘kenttä’ sanalla ‘funktio’ SDF:lle.












