
Tekoäly
Suora asetusten optimointi: täydellinen opas

Suurten kielimallien (LLM) yhteensovittaminen ihmisten arvojen ja mieltymysten kanssa on haastavaa. Perinteiset menetelmät, mm Ihmisten palautteesta oppimisen vahvistaminen (RLHF), ovat tasoittaneet tietä integroimalla ihmisen panoksia mallien tulosteiden tarkentamiseen. RLHF voi kuitenkin olla monimutkaista ja resurssiintensiivistä, mikä vaatii huomattavaa laskentatehoa ja tietojenkäsittelyä. Suora asetusten optimointi (DPO) on uusi ja virtaviivaisempi lähestymistapa, joka tarjoaa tehokkaan vaihtoehdon näille perinteisille menetelmille. Yksinkertaistamalla optimointiprosessia DPO ei vain vähennä laskentataakkaa, vaan myös parantaa mallin kykyä mukautua nopeasti ihmisten mieltymyksiin.
Tässä oppaassa sukeltamme syvälle tietosuojavastaavaan ja tutkimme sen perusteita, toteutusta ja käytännön sovelluksia.
Asetusten kohdistamisen tarve
Tietosuojavastaavien ymmärtämiseksi on ratkaisevan tärkeää ymmärtää, miksi LLM:ien sovittaminen ihmisten mieltymyksiin on niin tärkeää. Huolimatta vaikuttavista ominaisuuksistaan, LLM:t, jotka on koulutettu valtaviin tietokokonaisuuksiin, voivat joskus tuottaa tuloksia, jotka ovat epäjohdonmukaisia, puolueellisia tai väärin kohdistettuja inhimillisten arvojen kanssa. Tämä virhe voi ilmetä useilla tavoilla:
- Luodaan vaarallista tai haitallista sisältöä
- Epätarkkojen tai harhaanjohtavien tietojen antaminen
- Harjoitustiedoissa esiintyy harhoja
Näiden ongelmien ratkaisemiseksi tutkijat ovat kehittäneet tekniikoita LLM:ien hienosäätämiseksi käyttämällä ihmisten palautetta. Näkyvin näistä lähestymistavoista on ollut RLHF.
RLHF:n ymmärtäminen: DPO:n edeltäjä
RLHF (Inforcement Learning from Human Feedback) on ollut yleisin tapa sovittaa LLM:t ihmisten mieltymyksiin. Puretaan RLHF-prosessi ymmärtääksemme sen monimutkaisuuden:
a) Valvottu hienosäätö (SFT): Prosessi alkaa hienosäätämällä esikoulutettu LLM korkealaatuisten vastausten tietojoukolle. Tämä vaihe auttaa mallia luomaan osuvampia ja johdonmukaisempia tuloksia kohdetehtävälle.
b) Palkintomallinnus: Erillinen palkkiomalli on koulutettu ennustamaan ihmisten mieltymyksiä. Tähän sisältyy:
- Luodaan vastauspareja annetuille kehotteille
- Ihmiset arvioivat, minkä vastauksen he haluavat
- Mallin kouluttaminen ennustamaan nämä mieltymykset
c) Vahvistusoppiminen: Hienosäädettyä LLM:ää optimoidaan sitten edelleen vahvistusoppimisen avulla. Palkkiomalli antaa palautetta, joka ohjaa LLM:ää luomaan vastauksia, jotka vastaavat ihmisten mieltymyksiä.
Tässä on yksinkertaistettu Python-pseudokoodi havainnollistamaan RLHF-prosessia:
Vaikka RLHF on tehokas, sillä on useita haittoja:
- Se vaatii koulutusta ja useiden mallien ylläpitoa (SFT, palkkiomalli ja RL-optimoitu malli)
- RL-prosessi voi olla epävakaa ja herkkä hyperparametreille
- Se on laskennallisesti kallista ja vaatii monia eteenpäin- ja taaksepäinkulkuja mallien läpi
Nämä rajoitukset ovat motivoineet etsimään yksinkertaisempia, tehokkaampia vaihtoehtoja, mikä on johtanut DPO:n kehittämiseen.
Suora asetusten optimointi: ydinkäsitteet

Suora asetusten optimointi https://arxiv.org/abs/2305.18290
Tämä kuva erottelee kaksi erilaista lähestymistapaa LLM-tulosteiden kohdistamiseen ihmisten mieltymyksiin: RLHF (Reforcement Learning from Human Feedback) ja Direct Preference Optimization (DPO). RLHF luottaa palkitsemismalliin ohjatakseen kielimallin käytäntöä iteratiivisten palautesilmukoiden kautta, kun taas DPO optimoi mallin tulosteet suoraan vastaamaan ihmisten toivomia vastauksia preferenssitietojen avulla. Tämä vertailu tuo esiin kunkin menetelmän vahvuudet ja mahdolliset sovellukset ja antaa näkemyksiä siitä, kuinka tulevia LLM:itä voitaisiin kouluttaa vastaamaan paremmin ihmisten odotuksia.
Tärkeimmät ideat DPO:n takana:
a) Implisiittinen palkkiomallinnus: DPO eliminoi erillisen palkkiomallin tarpeen käsittelemällä itse kielimallia implisiittisenä palkkiofunktiona.
b) Käytäntöpohjainen muotoilu: Palkitsemistoiminnon optimoinnin sijaan DPO optimoi suoraan käytännön (kielimallin) maksimoidakseen ensisijaisten vastausten todennäköisyyden.
c) Suljetun muodon ratkaisu: DPO hyödyntää matemaattista näkemystä, joka mahdollistaa suljetun muodon ratkaisun optimaaliseen käytäntöön välttäen iteratiivisten RL-päivitysten tarpeen.
DPO:n käyttöönotto: Käytännön ohje
Alla olevassa kuvassa on koodikatkelma, joka toteuttaa DPO-häviötoiminnon PyTorchin avulla. Tällä toiminnolla on ratkaiseva rooli hiottaessa sitä, kuinka kielimallit priorisoivat tuotoksia ihmisten mieltymysten perusteella. Tässä on erittely tärkeimmistä komponenteista:
- Toiminnon allekirjoitus:
dpo_losstoiminto ottaa useita parametreja mukaan lukien käytäntölokin todennäköisyydet (pi_logps), viitemallin lokin todennäköisyydet (ref_logps), ja indeksit, jotka edustavat haluttuja ja epäsuotuisia täydennyksiä (yw_idxs,yl_idxs). Lisäksi abetaparametri ohjaa KL-rangaistuksen voimakkuutta. - Lokin todennäköisyyserotus: Koodi poimii loki-todennäköisyydet halutuille ja epäsuotuisille täydennyksille sekä käytäntö- että viitemalleista.
- Lokisuhteen laskenta: Ensisijaisten ja ei-toivottujen valmistumisten logaritmistodennäköisyyksien välinen ero lasketaan sekä käytäntö- että viitemallille. Tämä suhde on kriittinen määritettäessä optimoinnin suuntaa ja suuruutta.
- Tappio- ja palkkiolaskenta: Tappio lasketaan käyttämällä
logsigmoidfunktio, kun taas palkkiot määritetään skaalaamalla käytäntö- ja viitelokin todennäköisyyksien välinen erobeta.

DPO-häviötoiminto PyTorchin avulla
Sukellaan DPO:n takana olevaan matematiikkaan ymmärtääksemme, kuinka se saavuttaa nämä tavoitteet.
DPO:n matematiikka
DPO on fiksu uudelleenmuotoilu preferenssioppimisongelmasta. Tässä on vaiheittainen erittely:
a) Lähtökohta: KL-rajoitettu palkkion maksimointi
Alkuperäinen RLHF-tavoite voidaan ilmaista seuraavasti:
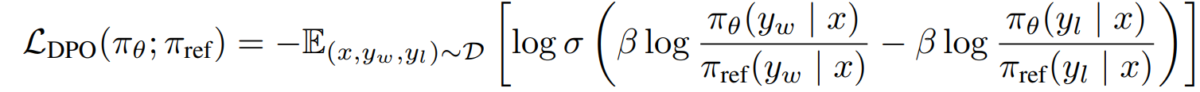
- πθ on käytäntö (kielimalli), jota optimoimme
- r(x,y) on palkkiofunktio
- πref on viitekäytäntö (yleensä alkuperäinen SFT-malli)
- β ohjaa KL-hajoamisrajoitteen voimakkuutta
b) Optimaalinen vakuutuslomake: Voidaan osoittaa, että optimaalinen politiikka tälle tavoitteelle on seuraava:
π_r(y|x) = 1/Z(x) * πref(y|x) * exp(1/β * r(x,y))Missä Z(x) on normalisointivakio.
c) Palkintopolitiikan kaksinaisuus: Tietosuojavastaavan keskeinen näkemys on ilmaista palkitsemistoiminto optimaalisen politiikan avulla:
r(x,y) = β * log(π_r(y|x) / πref(y|x)) + β * log(Z(x))d) Preference-malli Olettaen, että asetukset noudattavat Bradley-Terry-mallia, voimme ilmaista todennäköisyyden suosia y1:tä y2:n sijaan seuraavasti:
p*(y1 ≻ y2 | x) = σ(r*(x,y1) - r*(x,y2))Missä σ on logistinen funktio.
e) DPO:n tavoite Korvaamalla palkkiopolitiikkamme kaksinaisuuden etuusmalliin, saavutamme DPO:n tavoitteen:
L_DPO(πθ; πref) = -E_(x,y_w,y_l)~D [log σ(β * log(πθ(y_w|x) / πref(y_w|x)) - β * log(πθ(y_l|x) / πref(y_l|x)))]Tämä tavoite voidaan optimoida käyttämällä tavallisia gradienttilaskeutumistekniikoita ilman RL-algoritmeja.
Täytäntöönpano DPO
Nyt kun ymmärrämme DPO:n taustalla olevan teorian, katsotaan kuinka se toteutetaan käytännössä. Me käytämme Python ja PyTorch tälle esimerkille:
import torch
import torch.nn.functional as F
class DPOTrainer:
def __init__(self, model, ref_model, beta=0.1, lr=1e-5):
self.model = model
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
"""
pi_logps: policy logprobs, shape (B,)
ref_logps: reference model logprobs, shape (B,)
yw_idxs: preferred completion indices in [0, B-1], shape (T,)
yl_idxs: dispreferred completion indices in [0, B-1], shape (T,)
beta: temperature controlling strength of KL penalty
Each pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single preference pair.
"""
# Extract log probabilities for the preferred and dispreferred completions
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
# Calculate log-ratios
pi_logratios = pi_yw_logps - pi_yl_logps
ref_logratios = ref_yw_logps - ref_yl_logps
# Compute DPO loss
losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios))
rewards = self.beta * (pi_logps - ref_logps).detach()
return losses.mean(), rewards
def train_step(self, batch):
x, yw_idxs, yl_idxs = batch
self.optimizer.zero_grad()
# Compute log probabilities for the model and the reference model
pi_logps = self.model(x).log_softmax(-1)
ref_logps = self.ref_model(x).log_softmax(-1)
# Compute the loss
loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
loss.backward()
self.optimizer.step()
return loss.item()
# Usage
model = YourLanguageModel() # Initialize your model
ref_model = YourLanguageModel() # Load pre-trained reference model
trainer = DPOTrainer(model, ref_model)
for batch in dataloader:
loss = trainer.train_step(batch)
print(f"Loss: {loss}")
Haasteet ja tulevaisuuden suunnat
Vaikka DPO tarjoaa merkittäviä etuja perinteisiin RLHF-lähestymistapoihin verrattuna, haasteita ja lisätutkimuksia on edelleen:
a) Skaalautuvuus suurempiin malleihin:
Kielimallien koon kasvaessa edelleen DPO:n tehokas soveltaminen malleihin, joissa on satoja miljardeja parametreja, on edelleen avoin haaste. Tutkijat tutkivat tekniikoita, kuten:
- Tehokkaat hienosäätömenetelmät (esim. LoRA, etuliitteen viritys)
- Jaettu koulutusoptimointi
- Gradienttitarkistus- ja sekatarkkuusharjoittelu
Esimerkki LoRA:n käytöstä DPO:n kanssa:
from peft import LoraConfig, get_peft_model
class DPOTrainerWithLoRA(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
self.model = get_peft_model(model, lora_config)
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
# Usage
base_model = YourLargeLanguageModel()
dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
b) Multi-Task ja Few-Shot -sovitus:
Aktiivinen tutkimusalue on sellaisten DPO-tekniikoiden kehittäminen, jotka voivat mukautua tehokkaasti uusiin tehtäviin tai alueisiin rajoitetuilla preferenssitiedoilla. Tutkittavia lähestymistapoja ovat mm.
- Meta-oppimiskehykset nopeaan sopeutumiseen
- Tietosuojavastaavan pikasäätöinen hienosäätö
- Siirrä oppimista yleisistä mieltymysmalleista tietyille aloille
c) Epäselvien tai ristiriitaisten asetusten käsitteleminen:
Reaalimaailman asetustiedot sisältävät usein epäselvyyksiä tai ristiriitoja. Tietosuojavastaavan tällaisten tietojen luotettavuuden parantaminen on ratkaisevan tärkeää. Mahdollisia ratkaisuja ovat mm.
- Todennäköisyyspohjainen mieltymysmallinnus
- Aktiivinen oppiminen ratkaisemaan epäselvyyksiä
- Usean agentin mieltymysten yhdistäminen
Esimerkki todennäköisyyspohjaisesta mieltymysmallintamisesta:
class ProbabilisticDPOTrainer(DPOTrainer):
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob):
# Compute log ratios
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1)
loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) +
(1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff))
return loss.mean()
# Usage
trainer = ProbabilisticDPOTrainer(model, ref_model)
loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% confidence in preference
d) DPO:n yhdistäminen muihin kohdistustekniikoihin:
Tietosuojavastaavan integroiminen muihin linjausmenetelmiin voi johtaa vankempiin ja tehokkaampiin järjestelmiin:
- Perustuslailliset tekoälyperiaatteet nimenomaiseen rajoitteiden tyydyttämiseen
- Keskustelu ja rekursiivinen palkkiomallinnus monimutkaiseen mieltymysten saamiseen
- Käänteinen vahvistusoppiminen taustalla olevien palkitsemistoimintojen päättelemiseksi
Esimerkki DPO:n yhdistämisestä perustuslailliseen tekoälyyn:
class ConstitutionalDPOTrainer(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None):
super().__init__(model, ref_model, beta, lr)
self.constraints = constraints or []
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
constraint_loss = 0
for constraint in self.constraints:
constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs)
return base_loss + constraint_loss
# Usage
def safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs):
# Implement safety checking logic
unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps)
return torch.relu(unsafe_score - 0.5) # Penalize if unsafe score > 0.5
constraints = [safety_constraint]
trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)
Käytännön huomioita ja parhaita käytäntöjä
Kun otat DPO:n käyttöön todellisissa sovelluksissa, ota huomioon seuraavat vinkit:
a) Tietojen laatu: Asetustietojesi laatu on ratkaisevan tärkeää. Varmista, että tietojoukkosi:
- Kattaa laajan valikoiman syötteitä ja haluttuja käyttäytymismalleja
- Siinä on johdonmukaiset ja luotettavat mieltymysmerkinnät
- Tasapainottaa erityyppisiä mieltymyksiä (esim. tosiasiallisuus, turvallisuus, tyyli)
b) Hyperparametrien viritys: Vaikka DPO:lla on vähemmän hyperparametreja kuin RLHF:llä, viritys on silti tärkeää:
- β (beta): Hallitsee tyytyväisyyden ja vertailumallista poikkeamisen välistä kompromissia. Aloita arvoista ympärilläsi 0.1-0.5.
- Oppimisnopeus: Käytä tavallista hienosäätöä alhaisempaa oppimisnopeutta, tyypillisesti alueella 1e-6 - 1e-5.
- Eräkoko: Suuremmat eräkoot (32-128) toimivat usein hyvin mieltymysten oppimisessa.
c) Iteratiivinen tarkennus: DPO:ta voidaan soveltaa iteratiivisesti:
- Kouluta alkuperäinen malli DPO:n avulla
- Luo uusia vastauksia koulutetun mallin avulla
- Kerää uusia mieltymystietoja näistä vastauksista
- Opettele uudelleen käyttämällä laajennettua tietojoukkoa

Suoran asetusten optimoinnin suorituskyky
Tämä kuva näyttää GPT-4:n kaltaisten LLM:ien suorituskyvyn verrattuna ihmisten arvioihin eri koulutustekniikoissa, mukaan lukien suora asetusten optimointi (DPO), valvottu hienosäätö (SFT) ja proksimaalisen politiikan optimointi (PPO). Taulukko paljastaa, että GPT-4:n lähdöt ovat yhä enemmän linjassa ihmisten mieltymysten kanssa, erityisesti yhteenvetotehtävissä. GPT-4:n ja ihmisten arvioijien välinen yhteisymmärrys osoittaa mallin kyvyn luoda sisältöä, joka resonoi ihmisten arvioijien kanssa, melkein yhtä tarkasti kuin ihmisten luoma sisältö.
Tapaustutkimukset ja sovellukset
Havainnollistaaksemme DPO:n tehokkuutta, katsotaanpa joitain tosielämän sovelluksia ja joitain sen muunnelmia:
- Iteratiivinen DPO: Snorkelin (2023) kehittämä versio yhdistää hylkäysnäytteenoton DPO:n kanssa, mikä mahdollistaa tarkemman valintaprosessin harjoitusdatalle. Iteroimalla useita mieltymysten näytteenottokierroksia, malli pystyy paremmin yleistämään ja välttämään ylisovittamisen meluisiin tai puolueellisiin mieltymyksiin.
- IPO (Iteratiivinen asetusten optimointi): Esitteli Azar et ai. (2023), IPO lisää regularisointitermin estääkseen ylisovituksen, joka on yleinen ongelma preferenssipohjaisessa optimoinnissa. Tämän laajennuksen avulla mallit voivat säilyttää tasapainon asetuksien noudattamisen ja yleistyskyvyn säilyttämisen välillä.
- KTO (Tietämyksen siirron optimointi): Uudempi muunnos julkaisusta Ethayarajh et al. (2023), KTO luopuu binääriasetuksista kokonaan. Sen sijaan se keskittyy tiedon siirtämiseen vertailumallista politiikkamalliin, optimoiden tasaisemman ja johdonmukaisemman linjauksen inhimillisten arvojen kanssa.
- Monimuotoinen DPO verkkotunnusten väliseen oppimiseen Xu et ai. (2024): Lähestymistapa, jossa DPO:ta sovelletaan eri modaliteeteissa – tekstissä, kuvassa ja äänessä – ja se osoittaa monipuolisuutensa mallien mukauttamisessa ihmisten mieltymyksiin erilaisissa tietotyypeissä. Tämä tutkimus korostaa DPO:n mahdollisuuksia luoda kattavampia tekoälyjärjestelmiä, jotka pystyvät käsittelemään monimutkaisia, multimodaalisia tehtäviä.











