
Tehisintellekt
ST-NeRF: koostamine ja redigeerimine video sünteesi jaoks

Hiina teaduskonsortsium on arenenud tehnikaid, et viia redigeerimis- ja komponeerimisvõimalused ühe viimase aasta kuumima kujutise sünteesi uurimise sektorisse – Neural Radiance Fields (NeRF). Süsteem kannab nime ST-NeRF (Spatio-Temporal Coherent Neural Radiance Field).
See, mis alloleval pildil näib olevat füüsiline kaamerapann, on tegelikult lihtsalt kasutaja, kes "kerib" 4D-ruumis eksisteeriva videosisu vaatepunkte. POV ei ole lukustatud videol kujutatud inimeste sooritusvõimega, kelle liigutusi saab vaadata mis tahes 180-kraadise raadiuse osast.

Video iga tahk on diskreetselt jäädvustatud element, mis on kokku pandud ühtseks stseeniks, mida saab dünaamiliselt uurida.
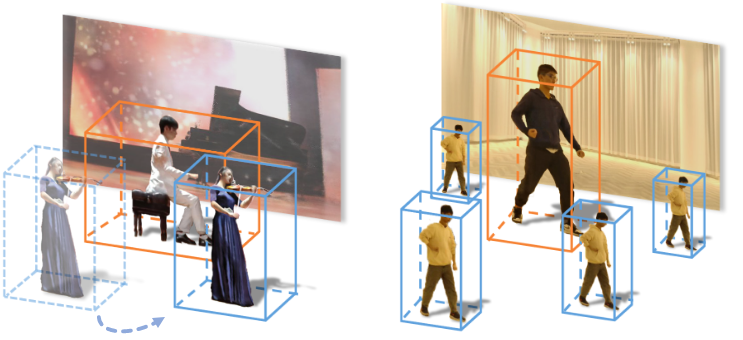
Tahke saab stseenis vabalt dubleerida või suurust muuta:

Lisaks saab iga tahu ajalist käitumist hõlpsasti muuta, aeglustada, tagurpidi käivitada või mitmel viisil manipuleerida, avades tee filtriarhitektuuridele ja äärmiselt kõrgele tõlgendatavuse tasemele.

Kaks erinevat NeRF-i tahku töötavad samas stseenis erineva kiirusega. Allikas: https://www.youtube.com/watch?v=Wp4HfOwFGP4
Esinejaid või keskkondi ei ole vaja rotoskoopida ega lasta esinejatel sooritada oma liigutusi pimesi ja väljaspool kavandatud stseeni konteksti. Selle asemel jäädvustatakse materjal loomulikult 16 videokaameraga, mis katavad 180 kraadi:


Eespool kujutatud kolm elementi, kaks inimest ja keskkond, on erinevad ja on välja toodud ainult illustratiivsetel eesmärkidel. Igaüht saab välja vahetada ja iga üksiku võtteajajoone varasemas või hilisemas punktis stseeni sisestada.
ST-NeRF on närvikiirguse väljade uurimise innovatsioon (NeRF), masinõpperaamistik, mille abil sünteesitakse mitme vaatepunkti jäädvustamine navigeeritavaks virtuaalruumiks ulatusliku koolituse abil (kuigi ühe vaatepunkti jäädvustamine on ka NeRF-i uurimistöö alamsektor).

Neuraalse kiirguse väljad koondavad mitu jäädvustamisvaatepunkti üheks sidusaks ja navigeeritavaks 3D-ruumiks, kusjuures lüngad katvuse vahel on hinnatud ja närvivõrgu poolt renderdatud. Kui kasutatakse videot (mitte fotosid), on renderdusressursid sageli märkimisväärsed. Allikas: https://www.matthewtancik.com/nerf
Huvi NeRF-i vastu on viimase üheksa kuu jooksul muutunud intensiivseks ja Reddit on seda säilitanud nimekiri Tuletis- või uurimuslike NeRF-dokumentide hulgas on praegu loetletud kuuskümmend projekti.

Vaid mõned paljudest algse NeRF-i paberi väljalangevustest. Allikas: https://crossminds.ai/graphlist/nerf-neural-radiance-fields-ai-research-graph-60708936c8663c4cfa875fc2/
Taskukohane koolitus
Paber on valminud koostöös Shanghai Tehnikaülikooli teadlaste ja DGene digitaaltehnoloogia, ja on teatud entusiasmiga vastu võetud aadressil Open Review.
ST-NeRF pakub mitmeid uuendusi võrreldes varasemate algatustega ML-st tuletatud navigeeritavates videoruumides. Vähe sellest, et see saavutab vaid 16 kaameraga kõrge realistlikkuse. Kuigi Facebooki oma DyNeRF kasutab ainult kahte kaamerat rohkem, pakub see palju piiratumat navigeeritavat kaare.

Näide Facebooki DyNeRF-i keskkonnast, kus liikumisväli on piiratum ja stseeni rekonstrueerimiseks on vaja rohkem kaameraid ruutmeetri kohta. Allikas: https://neural-3d-video.github.io
Lisaks sellele, et DyNeRF puudub võimalus redigeerida ja kombineerida üksikuid tahke, on see arvutusressursside osas eriti kallis. Seevastu Hiina teadlased väidavad, et nende andmete koolituskulud jäävad vahemikku 900–3,000 dollarit, võrreldes nüüdisaegse videogeneratsiooni mudeli DVDGAN ja intensiivsete süsteemide, nagu DyNeRF, 30,000 XNUMX dollariga.
Arvustajad on ka märkinud, et ST-NeRF teeb suure uuenduse liikumise õppimise protsessi lahtisidumisel kujutise sünteesi protsessist. See eraldamine võimaldab redigeerimist ja koostamist, kusjuures varasemad lähenemisviisid on piiravad ja lineaarsed.
Kuigi 16 kaamerat on sellise täieliku poolringi jaoks väga piiratud hulk, loodavad teadlased hilisemas töös seda arvu veelgi vähendada, kasutades puhverserveri eelskaneeritud staatilisi taustasid ja rohkem andmepõhiseid stseeni modelleerimismeetodeid. Samuti loodavad nad lisada valgustuse taastamise võimalused, a hiljutine uuendus NeRF-i uuringutes.
ST-NeRF piirangute käsitlemine
Akadeemiliste CS-tööde kontekstis, mis kipuvad uue süsteemi tegelikku kasutatavust äraviskamislõigusse jätma, on isegi piirangud, mida teadlased ST-NeRF-i puhul tunnistavad.
Nad märgivad, et süsteem ei saa praegu stseeni konkreetseid objekte isikustada ja eraldi renderdada, kuna filmitud inimesed segmenteeritakse üksikuteks üksusteks süsteemi kaudu, mis on loodud inimeste, mitte objektide äratundmiseks – probleem, mis näib olevat YOLO ja sarnaste seadmete abil hõlpsasti lahendatav. raamistike, mille raskem töö inimvideo väljavõtmiseks on juba tehtud.
Kuigi teadlased märgivad, et aegluubis ei ole praegu võimalik genereerida, näib vähe, et selle rakendamine takistaks olemasolevaid uuendusi kaadri interpolatsioonis, näiteks DAIN ja RIFE.
Nagu kõigi NeRF-i rakenduste puhul ja paljudes teistes arvutinägemise uurimise sektorites, võib ST-NeRF ebaõnnestuda tõsise oklusiooni korral, kui subjekt on ajutiselt teise isiku või objekti poolt varjatud ja seda võib olla raske pidevalt jälgida või täpselt kindlaks teha. pärast uuesti omandada. Nagu mujalgi, võib see probleem oodata eelnevaid lahendusi. Vahepeal tunnistavad teadlased, et nendes suletud raamides on vajalik käsitsi sekkumine.
Lõpuks märgivad teadlased, et inimeste segmenteerimisprotseduurid põhinevad praegu värvierinevustel, mis võib viia kahe inimese tahtmatusse koondamiseni üheks segmenteerimisplokiks – komistuskiviks, mis ei piirdu ST-NeRF-iga, vaid on omane kasutatavale raamatukogule. võib-olla saaks lahendada optilise vooluanalüüsi ja muude esilekerkivate tehnikatega.
Esmakordselt avaldatud 7. mail 2021.















