
Tehisintellekt
Google näeb ette GPT-3-laadse päringusüsteemi ilma otsingutulemusteta

Nelja Google'i teadlase uus dokument pakub välja „ekspertide” süsteemi, mis suudab autoriteetselt vastata kasutajate küsimustele ilma võimalike otsingutulemuste loendit esitamata, sarnaselt küsimuste ja vastuste paradigmaga, mis on saanud avalikkuse tähelepanu GPT-3 tulekuga minevikus. aastal.
. paber, pealkirjaga Otsingu ümbermõtestamine: diletantidest ekspertide tegemine, viitab sellele, et praegune standard, mille kohaselt esitatakse kasutajale päringule vastuseks otsingutulemuste loend, on „kognitiivne koorem”, ning teeb ettepaneku parandada loomuliku keele töötlemise süsteemi (NLP) võimet anda autoriteetne ja lõplik vastus. .
Väljapakutud „eksperdi”-domeeniülese oraakli mudeli kohaselt koondatakse tuhanded võimalikud otsingutulemuste allikad keelemudelisse, selle asemel, et olla kasutajate jaoks selgesõnaliselt kättesaadavad uurimusliku ressursina, mida nad saavad ise hinnata ja navigeerida. Allikas: https://arxiv.org/pdf/2105.02274.pdf
Dokumendis, mida juhtis Donald Metzler Google Researchis, tehakse ettepanek täiustada mitme domeeniga oraakli vastuseid, mida saab praegu saada süvaõppega autoregressiivsetest keelemudelitest, nagu GPT-3. Peamised kavandatavad täiustused on a) see, et mudel suudab täpselt tsiteerida vastuse andnud allikaid ja b) et mudel ei saakshallutsineerivadvastuseid või olematu lähtematerjali väljamõtlemist, mis on praegu selliste arhitektuuride puhul probleemiks.
Mitme domeeni koolitus ja võimalused
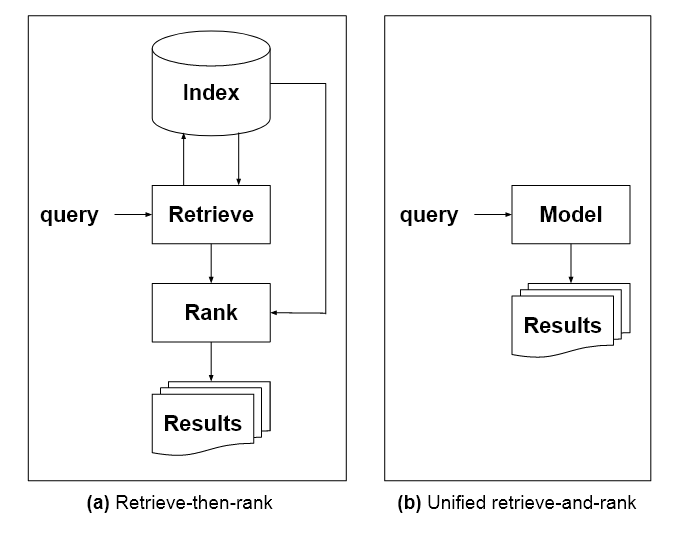
Lisaks õpetatakse välja pakutud keelemudelit, mida dokumendis kirjeldatakse kui "Kõigi teabeotsinguülesannete ühtset mudelit", mitmetes valdkondades, sealhulgas piltides ja tekstis. See vajaks ka arusaamist teadmiste päritolust, mis GPT-3 stiilis arhitektuurides puudub.
„Indekside asendamiseks ühe ühtse mudeliga peab mudelil endal olema võimalik teadmisi dokumendiidentifikaatorite universumist, samamoodi nagu traditsioonilised indeksid. Üks viis selle saavutamiseks on eemalduda traditsioonilistest LM-idest ja liikuda korpuse mudelite poole, mis modelleerivad ühiselt termini-termini, termini-dokumendi ja dokumendi-dokumendi suhteid.

Ülaloleval pildil on kolm lähenemisviisi vastuseks kasutaja päringule: vasakul on Google'i algoritmilistes otsingutulemustes kaudsed keelemudelid valinud ja seadnud prioriteediks "parima vastuse", kuid jätnud selle paljude parimaks tulemuseks. Center, GPT-3 stiilis vestlusvastus, mis räägib autoriteetselt, kuid ei õigusta oma väiteid ega viita allikatele. Eks pakutud ekspertide süsteem sisaldab järjestatud otsingutulemuste „parima vastuse” otse didaktilisse vastusesse, akadeemilises stiilis joonealuses märkuses olevad tsitaadid (ei ole kujutatud algsel pildil), mis näitavad vastuse aluseks olevaid allikaid.
Mürgiste ja ebatäpsete tulemuste eemaldamine
Teadlased märgivad, et otsinguindeksite dünaamiline ja pidevalt ajakohastatud olemus on väljakutse, mida seda laadi masinõppemudelis täielikult korrata. Näiteks kui kunagi usaldusväärset allikat on õpetatud otse mudeli maailma mõistma, võib selle mõju eemaldamine (näiteks pärast selle diskrediteerimist) olla keerulisem kui lihtsalt URL-i eemaldamine SERP-idest, kuna andmekontseptsioonid võivad muutuda abstraktne ja koolituses assimilatsiooni ajal laialdaselt esindatud.
Lisaks tuleks sellist mudelit pidevalt koolitada, et pakkuda uutele artiklitele ja väljaannetele samaväärset reageerimisvõimet, nagu praegu pakub Google'i pidev allikate otsimine. Sisuliselt tähendab see pidevat ja automatiseeritud kasutuselevõttu, erinevalt praegusest korrast, kus vabas vormis otsingualgoritmi kaaludes ja seadistustes tehakse väiksemaid muudatusi, kuid algoritmi ennast uuendatakse tavaliselt harva.
Ründepinnad tsentraliseeritud ekspert-oraakli jaoks
Pidevalt uusi andmeid assimileeriv ja üldistav tsentraliseeritud mudel võib muuta otsingupäringute rünnakupinna.
Praegu võib ründaja saada kasu, saavutades kõrge asetuse domeenide või lehtede puhul, mis sisaldavad valeinformatsiooni või pahatahtlikku koodi. Läbipaistmatuma "ekspertide" oraakli egiidi all väheneb oluliselt võimalus kasutajaid ründedomeenidesse suunata, kuid mürgiste andmerünnakute süstimise võimalus suureneb oluliselt.
Seda seetõttu, et pakutud süsteem ei kõrvalda otsingu järjestamise algoritmi, vaid peidab selle kasutaja eest, automatiseerides tõhusalt parima tulemuse/tulemuste prioriteedi ja küpsetades selle (või need) didaktiliseks väiteks. Pahatahtlikud kasutajad on juba pikka aega suutnud korraldada rünnakuid Google'i otsingualgoritmi vastu müüa võltstooteid, otsesed kasutajad pahavara levitavatele domeenidelevõi eesmärkidel poliitiline manipuleerimine, paljude muude kasutusjuhtude hulgas.
Mitte AGI
Teadlased rõhutavad, et tõenäoliselt ei kvalifitseeru selline süsteem tehisintellektiks (AGI) ja asetaks universaalse asjatundliku reageerija väljavaate loomuliku keele töötlemise konteksti, arvestades kõiki väljakutseid, millega sellised mudelid praegu silmitsi seisavad.
Dokumendis tuuakse välja viis kõrgekvaliteedilise vastuse nõuet:
1: autoriteet
Nagu praeguste järjestamisalgoritmide puhul, näib, et autoriteet tuleneb kvaliteetsetelt domeenidelt pärinevatest tsitaatidest, mida peetakse iseenesest autoriteetseteks. Teadlased jälgivad:
„Vastused peaksid looma sisu väga autoriteetsetest allikatest ammutades. See on veel üks põhjus, miks selgesõnalisemate seoste loomine terminite jadade ja dokumendi metaandmete vahel on nii oluline. Kui kõik korpuse dokumendid on varustatud autoriteetsuse skooriga, tuleks seda skoori mudeli treenimisel, vastuste genereerimisel või mõlemal arvesse võtta.
Kuigi teadlased ei väida, et traditsioonilised SERP-i tulemused muutuksid kättesaamatuks, kui seda tüüpi ekspert-oraakel leitakse olevat tulemuslik ja populaarne, esitab kogu artikkel siiski traditsioonilist järjestussüsteemi ja otsingutulemuste loendeid aastakümnete valguses. vana ja aegunud teabeotsingusüsteem.
„Asjaolu, et järjestamine on selle paradigma kriitiline komponent, on sümptom otsingusüsteemist, mis pakub kasutajatele potentsiaalsete vastuste valikut, mis põhjustab kasutajale üsna märkimisväärse kognitiivse koormuse. Soov tagastada vastuseid järjestatud tulemuste loendite asemel oli üheks motiveerivaks teguriks küsimustele vastamissüsteemide väljatöötamisel. '
2: läbipaistvus
Teadlased kommenteerivad:
Võimaluse korral tuleks kasutajatele esitatava teabe päritolu teha neile kättesaadavaks. Kas see on peamine teabeallikas? Kui ei, siis mis on esmane allikas?
3: Käsitsemise eelarvamus
Töös märgitakse, et eelkoolitatud keelemudelid ei ole mõeldud empiirilise tõe hindamiseks, vaid andmete domineerivate suundumuste üldistamiseks ja tähtsuse järjekorda seadmiseks. Ta möönab, et see direktiiv avab mudeli rünnakutele (nagu juhtus Microsofti oma tahtmatult rassistlik vestlusbot aastal 2016) ja et selliste kallutatud süsteemireaktsioonide eest kaitsmiseks on vaja abisüsteeme.
4: Mitmekülgsete vaatepunktide lubamine
Dokumendis pakutakse välja ka mehhanismid, mis tagavad vaatepunktide paljususe:
„Loodud vastused peaksid esindama erinevaid vaatenurki, kuid ei tohiks olla polariseerivad. Näiteks vaidlusi tekitavate teemade päringute puhul tuleks teema mõlemat poolt õiglaselt ja tasakaalustatult käsitleda. Sellel on ilmselgelt tihedad seosed mudeli eelarvamusega.
5: juurdepääsetav keel
Lisaks täpsete tõlgete pakkumisele juhtudel, kui autoriteetseks peetav vastus on teises keeles, soovitatakse dokumendis kapseldatud vastused "kirjutada võimalikult lihtsate sõnadega".















