
Tehisintellekt
RigNeRF: uus sügavvõltsimise meetod, mis kasutab närvikiirguse välju

Adobe'is välja töötatud uus uuring pakub esimest elujõulist ja tõhusat sügavvõltsimise meetodit, mis põhineb Neuraalsed kiirgusväljad (NeRF) – võib-olla esimene tõeline uuendus arhitektuuris või lähenemises viie aasta jooksul pärast süvavõltsingute esilekerkimist 2017. aastal.
Meetod, pealkirjaga RigNeRF, kasutab 3D-vormitavad näomudelid (3DMM-id) kui interstitsiaalne instrumentaalsuskiht soovitud sisendi (st NeRF-i renderdusse rakendatava identiteedi) ja närviruumi vahel – meetod, mis on viimastel aastatel laialdaselt kasutusele võetud Generative Adversarial Network (GAN) näo sünteesi lähenemisviisid, millest ükski pole veel video jaoks tootnud funktsionaalseid ja kasulikke näo asendamise raamistikke.

Erinevalt traditsioonilistest sügavvõltsitud videotest ei ole absoluutselt ükski siin kujutatud liikuv sisu "päris", vaid pigem uuritav närviruum, mida treeniti lühikeste kaadrite põhjal. Paremal näeme 3D morfeeruvat näomudelit (3DMM), mis toimib liidesena soovitud manipulatsioonide (naeratus, vaata vasakule, vaata üles jne) ja närvikiirguse välja tavaliselt raskesti kontrollitavate parameetrite vahel. visualiseerimine. Selle klipi kõrge eraldusvõimega versiooni ja muude näidete vaatamiseks vaadake Projekti lehelevõi selle artikli lõpus olevad manustatud videod. Allikas: https://shahrukhathar.github.io/2022/06/06/RigNeRF.html
3DMM-id on tõhusalt nägude CGI-mudelid, mille parameetreid saab kohandada abstraktsematele kujutise sünteesisüsteemidele, nagu NeRF ja GAN, mida muidu on raske juhtida.
See, mida näete ülaloleval pildil (keskmine pilt, sinises särgis mees) ja ka otse all olev pilt (vasakpoolne pilt, sinises särgis mees), ei ole "päris" video, milles on väike plaaster võltsnägu on peale kantud, kuid see on täielikult sünteesitud stseen, mis eksisteerib ainult mahulise neuraalse renderdusena – sealhulgas keha ja taust:

Otse ülaltoodud näites kasutatakse parempoolset tõsieluvideot (naine punases kleidis) jäädvustatud identiteedi (sinises särgis mees) vasakpoolses nukuks RigNeRF kaudu, mis (autorite väitel) on esimene. NeRF-põhine süsteem poosi ja väljenduse eraldamiseks, võimaldades samal ajal teostada uudseid vaatesünteese.
Ülaloleval pildil vasakpoolne meestegelane jäädvustati 70-sekundilisest nutitelefoni videost ja sisendandmeid (sealhulgas kogu stseeni teavet) treeniti seejärel stseeni saamiseks nelja V4 GPU kaudu.
Kuna 3DMM-stiilis parameetrilised platvormid on saadaval ka kui kogu keha parameetrilised CGI-puhverserverid (mitte lihtsalt näoseadmetega), avab RigNeRF potentsiaalselt võimaluse kogu keha sügavaks võltsimiseks, kus tõeline inimese liikumine, tekstuur ja väljendus edastatakse CGI-põhisele parameetrilisele kihile, mis teisendab tegevuse ja väljenduse renderdatud NeRF-i keskkondadeks ja videoteks. .
Mis puutub RigNeRF-i – kas see kvalifitseerub sügavvõltsimismeetodiks praeguses mõttes, et pealkirjad mõistavad seda terminit? Või on see lihtsalt järjekordne pooleldi segatud, samuti DeepFaceLabi ja muude töömahukate 2017. aasta ajastu autoencoder sügavvõltsimissüsteemide kasutamine?
Uue dokumendi teadlased on selles küsimuses ühemõttelised:
"Kuna RigNeRF on meetod, mis suudab nägusid reanimeerida, on halbade näitlejate poolt kalduvus seda kuritarvitada, et luua sügavaid võltsinguid."
Uus paber on pealkirjaga RigNeRF: täielikult juhitavad neuraalsed 3D-portreed, ja pärineb ShahRukh Athalt Stonybrooki ülikoolist, RigNeRF-i arendamise ajal Adobe praktikandilt ja veel neljalt Adobe Researchi autorilt.
Lisaks automaatkodeerijatel põhinevatele süvavõltsingutele
Enamiku viimaste aastate pealkirjadesse sattunud viiruste süvavõltsinguid toodab autoenkooder-põhised süsteemid, mis on tuletatud koodist, mis avaldati viivitamatult keelatud r/deepfakes subredditis 2017. aastal – kuigi mitte enne seda üle kopeeritud GitHubisse, kus see on praegu ühendatud üle tuhande korra, eriti populaarseks (kui vastuoluline) DeepFaceLab levitamine ja ka Näovahetus projekti.
Lisaks GAN-ile ja NeRF-ile on autoencoder raamistikud katsetanud ka 3DMM-e kui "juhiseid" täiustatud näo sünteesi raamistike jaoks. Selle näiteks on HifiFace projekt 2021. aasta juulist. Tundub, et sellest lähenemisviisist ei ole siiani välja kujunenud ühtegi kasutatavat või populaarset algatust.
Andmed RigNeRF-stseenide kohta saadakse nutitelefoni lühikeste videote jäädvustamisel. Projekti jaoks kasutasid RigNeRF-i teadlased kõigi katsete jaoks iPhone XR-i või iPhone 12-t. Võtte esimeses pooles palutakse subjektil teha mitmesuguseid näoilmeid ja kõnet, hoides samal ajal pead paigal, kui kaamerat tema ümber liigutatakse.
Jäädvustuse teisel poolel hoiab kaamera fikseeritud asendit, samal ajal kui objekt peab oma pead liigutama, näidates samal ajal mitmesuguseid ilmeid. Saadud 40–70-sekundiline kaader (umbes 1200–2100 kaadrit) esindab kogu andmestikku, mida mudeli koolitamiseks kasutatakse.
Andmete kogumise vähendamine
Seevastu automaatkodeerimissüsteemid, nagu DeepFaceLab, nõuavad suhteliselt töömahukat tuhandete erinevate fotode kogumist ja kureerimist, mis on sageli tehtud YouTube'i videotest ja muudest sotsiaalmeedia kanalitest, aga ka filmidest (kuulsuste sügavvõltsingute puhul).
Saadud koolitatud autoencoder mudelid on sageli mõeldud kasutamiseks erinevates olukordades. Kõige nõudlikumad "kuulsused" võivad aga ühe video jaoks terveid mudeleid nullist välja õpetada, hoolimata sellest, et treenimine võib kesta nädala või rohkemgi.
Hoolimata uue artikli teadlaste hoiatustest ei anna AI-pornot ja populaarseid YouTube'i/TikToki nn süvavõltsitud ümberlaadimisi kasutav „lapivärk” ja laiaulatuslikult kokku pandud andmestikud tõenäoliselt vastuvõetavaid ja järjepidevaid tulemusi sügavas võltsimissüsteemis, nagu RigNeRF, millel on stseenispetsiifiline metoodika. Arvestades uues töös kirjeldatud andmete kogumise piiranguid, võib see teatud määral osutuda täiendavaks kaitseks identiteedi juhusliku omastamise vastu pahatahtlike süvavõltsijate poolt.
NeRF-i kohandamine Deepfake Videoga
NeRF on fotogrammeetrial põhinev meetod, mille puhul väike hulk erinevatest vaatepunktidest tehtud lähtepilte koondatakse uuritavaks 3D-närviruumiks. See lähenemine tõusis esile selle aasta alguses, kui NVIDIA selle avalikustas Instant NeRF süsteem, mis on võimeline vähendama NeRF-i üüratu treeningaega minutiteks või isegi sekunditeks:

Instant NeRF. Allikas: https://www.youtube.com/watch?v=DJ2hcC1orc4
Saadud närvikiirguse välja stseen on sisuliselt staatiline keskkond, mida saab uurida, kuid mis on raske toimetada. Teadlased märgivad, et kaks varasemat NeRF-põhist algatust - HyperNeRF + E/P ja NerFACE – on astunud näovideo sünteesi ja (ilmselt täielikkuse ja hoolsuse huvides) seadnud RigNeRF-i testimisvoorus nende kahe raamistiku vastu:


RigNeRF, HyperNeRF ja NerFACE kvalitatiivne võrdlus. Kvaliteetsemate versioonide saamiseks vaadake lingitud lähtevideoid ja PDF-i. Staatilise pildi allikas: https://arxiv.org/pdf/2012.03065.pdf
Kuid antud juhul on tulemused, mis eelistavad RigNeRF-i, üsna anomaalsed kahel põhjusel: esiteks märgivad autorid, et „puudub töö õuntevaheliseks võrdluseks”; teiseks on see tinginud vajaduse piirata RigNeRF-i võimeid, et vähemalt osaliselt vastaks varasemate süsteemide piiratud funktsionaalsusele.
Kuna tulemused ei ole eelneva töö järkjärguline paranemine, vaid pigem kujutavad endast läbimurret NeRF-i redigeeritavuses ja kasulikkuses, jätame testimise kõrvale ja vaatame selle asemel, mida RigNeRF eelkäijatest erinevalt teeb.
Kombineeritud tugevused
NerFACE'i, mis võib NeRF-keskkonnas poosi/väljenduse juhtimist luua, peamine piirang seisneb selles, et see eeldab, et lähtematerjali jäädvustatakse staatilise kaameraga. See tähendab tegelikult, et see ei saa luua uudseid vaateid, mis ulatuvad kaugemale selle jäädvustamise piirangutest. See loob süsteemi, mis suudab luua liikuvaid portreesid, kuid mis ei sobi sügavvõltsitud videote jaoks.
Teisest küljest, kuigi HyperNeRF suudab genereerida uudseid ja hüperreaalseid vaateid, ei ole sellel vahendit, mis võimaldaks muuta peapoose või näoilmeid, mis jällegi ei too kaasa autoencoder-põhiste süvavõltsingute jaoks mingit konkurenti.
RigNeRF suudab need kaks eraldatud funktsiooni kombineerida, luues "kanoonilise ruumi", vaikimisi lähtetaseme, millest kõrvalekaldeid ja deformatsioone saab 3DMM-mooduli sisendi kaudu käivitada.
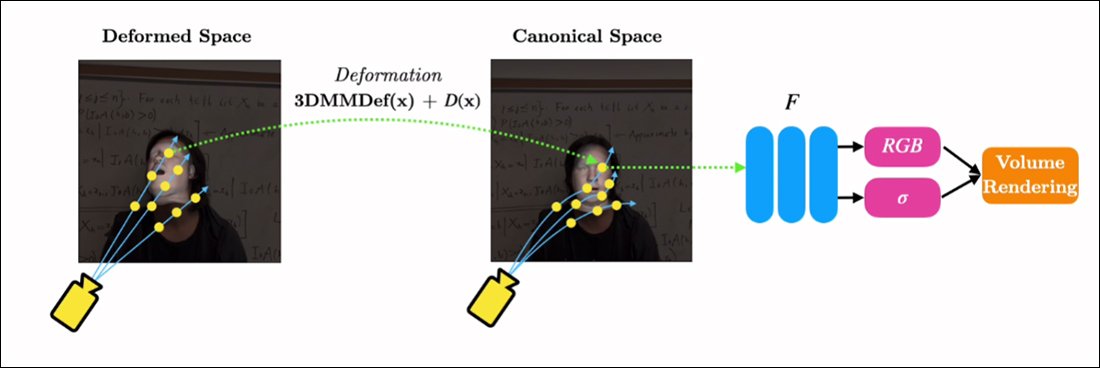
"Kanoonilise ruumi" loomine (pole poos, pole väljendit), millele 3DMM-i kaudu tekitatud deformatsioonid (st poosid ja väljendid) võivad mõjuda.
Kuna 3DMM-süsteemi ei sobitata täpselt jäädvustatud objektiga, on oluline seda protsessi käigus kompenseerida. RigNeRF saavutab selle deformatsiooniväljaga, mis on arvutatud alates a Mitmekihiline Perceptron (MLP), mis on tuletatud allikamaterjalist.

Kaamera parameetrid, mis on vajalikud deformatsioonide arvutamiseks, saadakse läbi COLMAP, samas kui iga kaadri avaldise ja kuju parameetrid saadakse Selle.
Positsioneerimist optimeeritakse veelgi maamärgi sobitamine ja COLMAP-i kaamera parameetrid ning arvutusressursside piirangute tõttu vähendatakse videoväljundit treeningu jaoks eraldusvõimeni 256 × 256 (riistvaraga piiratud kahanemisprotsess, mis vaevab ka automaatkodeerija sügavvõltsimise stseeni).
Pärast seda treenitakse deformatsioonivõrku neljal V100-l – tohutu riistvaraga, mis ei ole tõenäoliselt tavahuvilistele käeulatuses (samas on masinõppetreeningu puhul sageli võimalik aega kaubelda ja selle mudeliga lihtsalt leppida koolitus on päevade või isegi nädalate küsimus).
Kokkuvõtteks väidavad teadlased:
"Erinevalt teistest meetoditest suudab RigNeRF tänu 3DMM-i juhitava deformatsioonimooduli kasutamisele suure täpsusega modelleerida peapoose, näoilmeid ja täielikku 3D-portree stseeni, andes seega paremaid rekonstruktsioone teravate detailidega."
Lisateabe ja tulemuste saamiseks vaadake allolevaid manustatud videoid.


Esmakordselt avaldatud 15. juunil 2022.















