Inteligencia artificial
Entrenamiento de modelos de visión por computadora con ruido aleatorio en lugar de imágenes reales

Los investigadores del Laboratorio de Ciencia y Inteligencia Artificial de la Computadora del MIT (CSAIL) han experimentado con el uso de imágenes de ruido aleatorio en conjuntos de datos de visión por computadora para entrenar modelos de visión por computadora, y han descubierto que, en lugar de producir basura, el método es sorprendentemente efectivo:

Modelos generativos del experimento, ordenados por rendimiento. Fuente: https://openreview.net/pdf?id=RQUl8gZnN7O
Alimentar aparente ‘basura visual’ a arquitecturas de visión por computadora populares no debería resultar en este tipo de rendimiento. En el extremo derecho de la imagen de arriba, las columnas negras representan puntuaciones de precisión (en Imagenet-100) para cuatro conjuntos de datos ‘reales’. Mientras que los conjuntos de datos de ‘ruido aleatorio’ que los preceden (representados en varios colores, véase el índice superior izquierdo) no pueden igualar eso, están casi todos dentro de límites respetables superior e inferior (líneas discontinuas rojas) para la precisión.
En este sentido, ‘precisión’ no significa que un resultado necesariamente se parezca a un rostro, una iglesia, una pizza, o cualquier otro dominio particular para el que pueda estar interesado en crear un sistema de síntesis de imágenes, como una Red Adversaria Generativa o un marco de codificador/decodificador.
Más bien, significa que los modelos de CSAIL han derivado ‘verdades’ centrales ampliamente aplicables de los datos de imagen tan aparentemente no estructurados que no deberían ser capaces de suministrarlos.
Diversidad Vs. Naturalismo
Tampoco pueden estos resultados atribuirse a sobreajuste: una animada discusión entre los autores y revisores en Open Review revela que mezclar diferentes contenidos de conjuntos de datos visualmente diversos (como ‘hojas muertas’, ‘fractales’ y ‘ruido procedural’ – véase la imagen a continuación) en un conjunto de datos de entrenamiento mejora la precisión en estos experimentos.
Esto sugiere (y es un poco una noción revolucionaria) un nuevo tipo de ‘subajuste’, donde ‘diversidad’ supera a ‘naturalismo’.
La página del proyecto permite ver interactivamente los diferentes tipos de conjuntos de datos de imágenes aleatorias utilizados en el experimento. Fuente: https://mbaradad.github.io/learning_with_noise/
Los resultados obtenidos por los investigadores cuestionan la relación fundamental entre las redes neuronales basadas en imágenes y las imágenes del ‘mundo real’ que se les lanzan en volúmenes cada vez mayores cada año, e implican que la necesidad de obtener, curar y manejar conjuntos de datos de imágenes de hipercala puede volverse eventualmente redundante. Los autores afirman:
‘Los sistemas de visión actuales se entrenan en conjuntos de datos enormes, y estos conjuntos de datos conllevan costos: la curación es costosa, heredan sesgos humanos, y hay preocupaciones sobre la privacidad y los derechos de uso. Para contrarrestar estos costos, ha surgido el interés en aprender de fuentes de datos más baratas, como imágenes no etiquetadas.
‘En este artículo, vamos un paso más allá y preguntamos si podemos prescindir por completo de los conjuntos de datos de imágenes reales, aprendiendo de procesos de ruido procedural.’
Los investigadores sugieren que la actual cosecha de arquitecturas de aprendizaje automático puede estar infiriendo algo mucho más fundamental (o, al menos, inesperado) de las imágenes de lo que se pensaba anteriormente, y que las imágenes ‘sin sentido’ pueden potencialmente impartir una gran cantidad de este conocimiento de manera mucho más barata, incluso con el posible uso de datos sintéticos ad hoc, a través de arquitecturas de generación de conjuntos de datos que generan imágenes aleatorias en el momento del entrenamiento:
‘Identificamos dos propiedades clave que hacen que los datos sintéticos sean buenos para entrenar sistemas de visión: 1) naturalismo, 2) diversidad. Curiosamente, los datos más naturalistas no siempre son los mejores, ya que el naturalismo puede tener un costo en términos de diversidad.
‘El hecho de que los datos naturalistas ayuden puede no ser sorprendente, y sugiere que, de hecho, los datos reales a gran escala tienen valor. Sin embargo, encontramos que lo que es crucial no es que los datos sean reales, sino que sean naturalistas, es decir, deben capturar ciertas propiedades estructurales de los datos reales.
‘Muchas de estas propiedades pueden capturarse en modelos de ruido simples.’

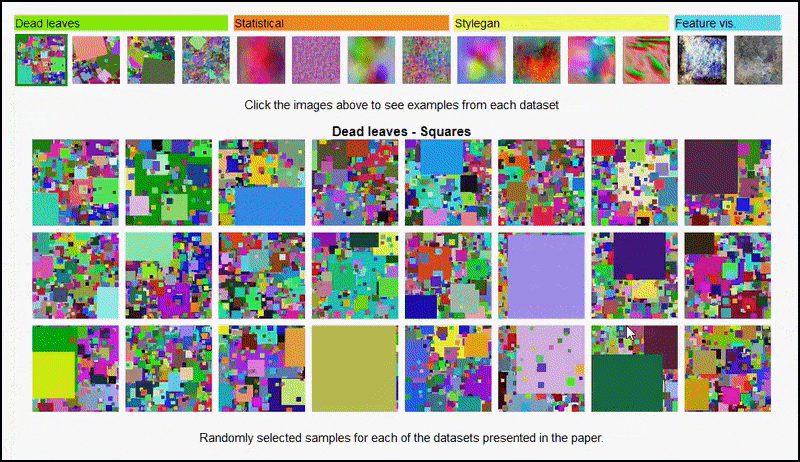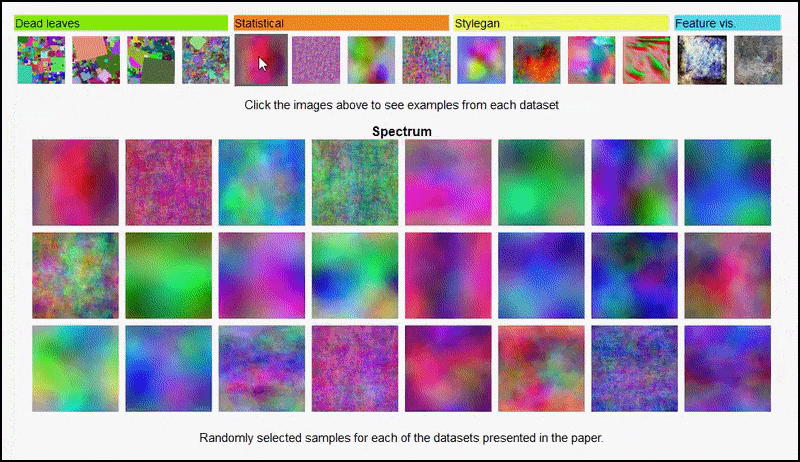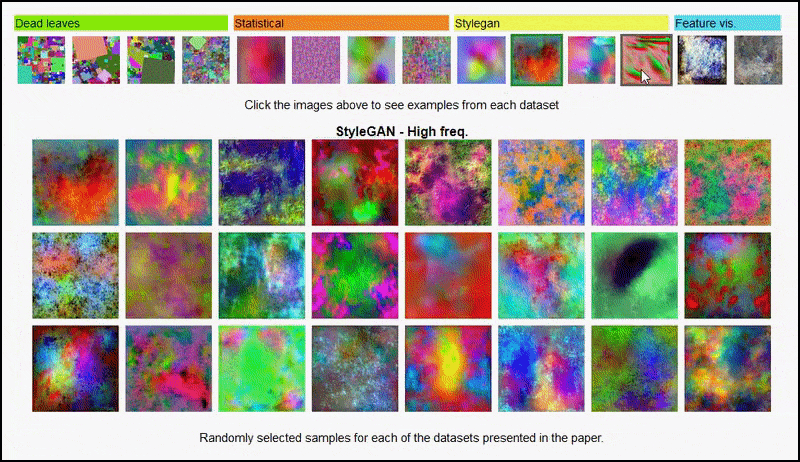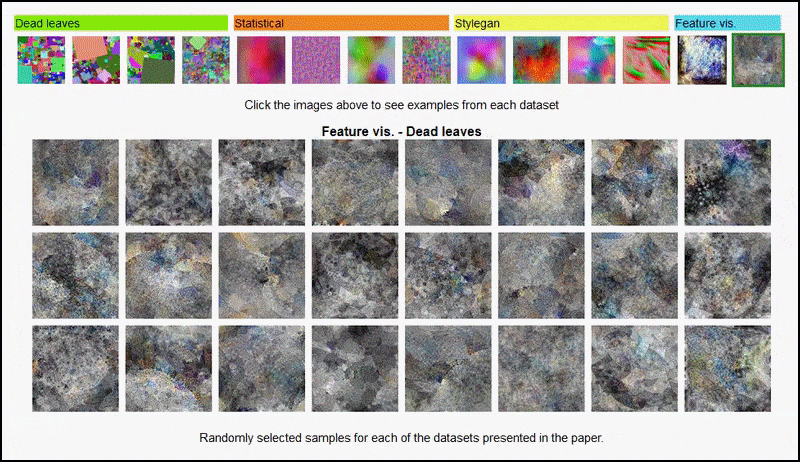
Visualizaciones de características resultantes de un codificador derivado de AlexNet en algunos de los varios conjuntos de datos de ‘imágenes aleatorias’ utilizados por los autores, cubriendo la 3ª y 5ª (final) capa convolucional. La metodología utilizada aquí sigue la establecida en la investigación de Google AI de 2017.
El artículo, presentado en la 35ª Conferencia sobre Procesamiento de Información Neural (NeurIPS 2021) en Sydney, se titula Aprender a ver mirando el ruido, y procede de seis investigadores de CSAIL, con contribución igual.
El trabajo fue recomendado por consenso para una selección de destacados en NeurIPS 2021, con comentaristas que caracterizan el artículo como ‘un avance científico’ que abre un ‘gran área de estudio’, incluso si plantea tantas preguntas como respuestas.
En el artículo, los autores concluyen:
‘Hemos demostrado que, cuando se diseñan utilizando resultados de investigaciones anteriores sobre estadísticas de imágenes naturales, estos conjuntos de datos pueden entrenar con éxito representaciones visuales. Esperamos que este artículo motive el estudio de nuevos modelos generativos capaces de producir ruido estructurado que logre un rendimiento aún mayor cuando se utilice en una variedad de tareas visuales.
‘¿Sería posible igualar el rendimiento obtenido con el preentrenamiento de ImageNet? Tal vez, en ausencia de un conjunto de entrenamiento grande específico para una tarea particular, el mejor preentrenamiento no sea utilizar un conjunto de datos real estándar como ImageNet.’












