Líderes de opinión
Tres técnicas de aprendizaje automático que preservan la privacidad para resolver el problema más importante de esta década
Por Amogh Tarcar, investigador de aprendizaje automático y IA, Persistent Systems.
La privacidad de los datos, según expertos de una amplia gama de dominios, será el problema más importante de esta década. Esto es particularmente cierto para el aprendizaje automático (ML), donde los algoritmos se alimentan de grandes cantidades de datos.
Tradicionalmente, las técnicas de modelado de ML han confiado en centralizar los datos de múltiples fuentes en un solo centro de datos. Después de todo, los modelos de ML son más poderosos cuando tienen acceso a grandes cantidades de datos. Sin embargo, existen una serie de desafíos de privacidad que conlleva esta técnica. Agregar datos diversos de múltiples fuentes es menos factible hoy en día debido a preocupaciones regulatorias como HIPAA, GDPR y CCPA. Además, centralizar los datos aumenta el alcance y la escala del mal uso de los datos y las amenazas de seguridad en forma de fugas de datos.
Para superar estos desafíos, se han desarrollado varios pilares de aprendizaje automático que preservan la privacidad (PPML) con técnicas específicas que reducen el riesgo de privacidad y garantizan que los datos permanezcan razonablemente seguros. A continuación, se presentan algunas de las más importantes:
1. Aprendizaje federado
El aprendizaje federado es una técnica de entrenamiento de ML que invierte el problema de agregación de datos. En lugar de agregar datos para crear un solo modelo de ML, el aprendizaje federado agrega modelos de ML en sí mismos. Esto garantiza que los datos nunca salgan de su ubicación de origen y permite que varias partes colaboren y construyan un modelo de ML común sin compartir directamente datos sensibles.
Funciona de la siguiente manera. Comienzas con un modelo de ML base que se comparte con cada nodo cliente. Estos nodos ejecutan un entrenamiento local en este modelo utilizando sus propios datos. Las actualizaciones del modelo se comparten periódicamente con el nodo coordinador, que procesa estas actualizaciones y las fusiona para obtener un nuevo modelo global. De esta manera, se obtienen los conocimientos de conjuntos de datos diversos sin tener que compartir estos conjuntos de datos.

Fuente: Persistent Systems
En el contexto de la atención médica, esta es una herramienta increíblemente poderosa y consciente de la privacidad para mantener los datos de los pacientes seguros mientras se les da a los investigadores la sabiduría de la multitud. Al no agregar los datos, el aprendizaje federado crea una capa adicional de seguridad. Sin embargo, los modelos y las actualizaciones de los modelos en sí mismos aún presentan un riesgo de seguridad si se dejan vulnerables.
2. Privacidad diferencial
Los modelos de ML a menudo son objetivos de ataques de inferencia de membresía. Supongamos que compartes tus datos de salud con un hospital para ayudar a desarrollar una vacuna contra el cáncer. El hospital mantiene tus datos seguros, pero utiliza el aprendizaje federado para entrenar un modelo de ML disponible públicamente. Unos meses más tarde, los hackers utilizan un ataque de inferencia de membresía para determinar si tus datos se utilizaron en el entrenamiento del modelo o no. Luego, pasan conocimientos a una compañía de seguros, que, en función de tu riesgo de cáncer, podría aumentar tus primas.
La privacidad diferencial garantiza que los ataques de adversarios a los modelos de ML no podrán identificar los puntos de datos específicos utilizados durante el entrenamiento, lo que mitiga el riesgo de exponer datos de entrenamiento sensibles en el aprendizaje automático. Esto se logra aplicando “ruido estadístico” para perturbar los datos o los parámetros del modelo de ML durante el entrenamiento, lo que hace difícil ejecutar ataques y determinar si los datos de una persona en particular se utilizaron para entrenar el modelo.
Por ejemplo, Facebook acaba de lanzar Opacus, una biblioteca de alta velocidad para entrenar modelos de PyTorch utilizando un algoritmo de entrenamiento de ML con privacidad diferencial llamado Diferenciación Privada Descenso de Gradiente Estocástico (DP-SGD). El gif a continuación muestra cómo utiliza el ruido para enmascarar los datos.

Fuente: Blog de Opacus de Facebook
Este ruido está gobernado por un parámetro llamado Epsilon. Si el valor de Epsilon es bajo, el modelo tiene una privacidad de datos perfecta pero una utilidad y precisión deficientes. Inversamente, si tienes un valor de Epsilon alto, tu privacidad de datos disminuirá mientras que tu precisión aumentará. El truco es encontrar un equilibrio para optimizar ambos.
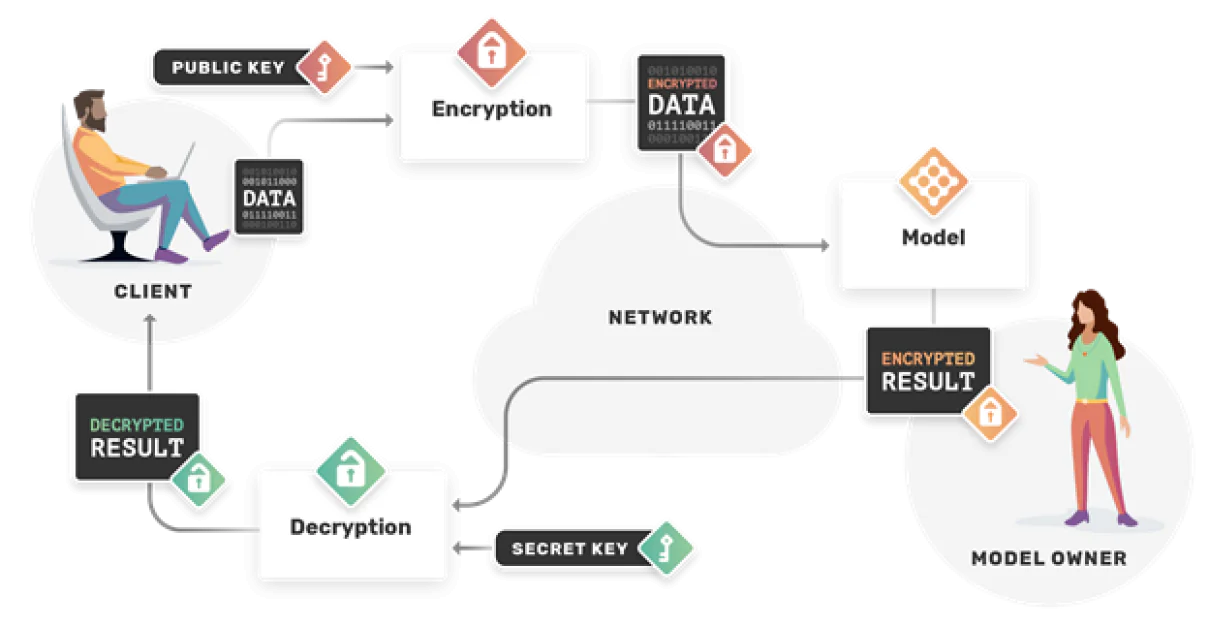
3. Cifrado homomórfico
El cifrado estándar tradicionalmente es incompatible con el aprendizaje automático porque una vez que los datos están cifrados, ya no pueden ser comprendidos por el algoritmo de ML. Sin embargo, el cifrado homomórfico es un esquema de cifrado especial que permite realizar ciertos tipos de cálculos.

Fuente: OpenMined
El poder de esto es que el entrenamiento puede ocurrir en un espacio completamente cifrado. No solo protege a los propietarios de los datos, sino que también protege a los propietarios del modelo. El propietario del modelo puede ejecutar inferencia en datos cifrados sin verlos nunca o malversarlos.
Cuando se aplica al aprendizaje federado, la fusión de actualizaciones del modelo puede ocurrir de manera segura porque tienen lugar en un entorno completamente cifrado, lo que reduce drásticamente el riesgo de ataques de inferencia de membresía.
La década de la privacidad
Al entrar en 2021, el aprendizaje automático que preserva la privacidad es un campo emergente con una investigación notablemente activa. Si la última década se trató de desbloquear los datos, esta década será sobre desbloquear los modelos de ML mientras se preserva la privacidad de los datos subyacentes a través del aprendizaje federado, la privacidad diferencial y el cifrado homomórfico. Estos presentan una forma prometedora de avanzar en las soluciones de aprendizaje automático de una manera consciente de la privacidad.












