Inteligencia Artificial
Tres desafíos por delante para la difusión estable

El , de la difusión estable de Stability.ai difusión latente modelo de síntesis de imagen hace un par de semanas puede ser una de las revelaciones tecnológicas más importantes desde DeCSS en 1999; es sin duda el mayor evento en imágenes generadas por IA desde 2017. código de falsificación profunda se copió en GitHub y se bifurcó en lo que se convertiría ProfundoFaceLab y el Intercambio cara, así como el software deepfake de transmisión en tiempo real cara profunda en vivo.
De un golpe, frustración del usuario sobre la restricciones de contenido En la API de síntesis de imágenes de DALL-E 2 se dejaron de lado, ya que se descubrió que el filtro NSFW de Stable Diffusion se podía desactivar cambiando un única línea de código. Los Reddits de Stable Diffusion centrados en la pornografía surgieron casi de inmediato y se eliminaron con la misma rapidez, mientras que el campo de desarrolladores y usuarios se dividió en Discord en las comunidades oficial y NSFW, y Twitter comenzó a llenarse con fantásticas creaciones de Stable Diffusion.
Por el momento, cada día parece traer alguna innovación sorprendente de los desarrolladores que han adoptado el sistema, con complementos y complementos de terceros que se escriben apresuradamente para Krita, Photoshop, Cinema4D, Batidora de vaso - Blendery muchas otras plataformas de aplicaciones.
Mientras tanto, pronta – el arte ahora profesional del 'susurro de IA', que puede terminar siendo la opción profesional más corta desde la 'carpeta Filofax' – ya se está convirtiendo comercializado, mientras que la monetización temprana de Stable Diffusion está teniendo lugar en el nivel de patreon, con la certeza de que vendrán ofertas más sofisticadas, para aquellos que no estén dispuestos a navegar basado en Conda instalaciones del código fuente, o los filtros NSFW proscriptivos de las implementaciones basadas en la web.
El ritmo de desarrollo y la libertad de exploración de los usuarios avanzan a una velocidad tan vertiginosa que es difícil prever el futuro. En esencia, aún no sabemos exactamente a qué nos enfrentamos ni cuáles podrían ser las limitaciones o posibilidades.
No obstante, echemos un vistazo a tres de los obstáculos que podrían ser más interesantes y desafiantes que la comunidad de Stable Diffusion, que se ha formado y crece rápidamente, debe enfrentar y, con suerte, superar.
1: Optimización de canalizaciones basadas en mosaicos
Presentado con recursos de hardware limitados y límites estrictos en la resolución de las imágenes de entrenamiento, parece probable que los desarrolladores encuentren soluciones para mejorar tanto la calidad como la resolución de la salida de Stable Diffusion. Muchos de estos proyectos están configurados para explotar las limitaciones del sistema, como su resolución nativa de solo 512 × 512 píxeles.
Como siempre es el caso con las iniciativas de síntesis de imágenes y visión por computadora, Stable Diffusion se entrenó en imágenes de proporción cuadrada, en este caso remuestreadas a 512 × 512, para que las imágenes de origen pudieran regularizarse y ajustarse a las limitaciones de las GPU que entrenó el modelo.
Por lo tanto, Stable Diffusion "piensa" (si es que piensa) en términos de 512×512, y ciertamente en términos cuadrados. Muchos usuarios que actualmente exploran los límites del sistema informan que Stable Diffusion produce los resultados más fiables y con menos fallos en esta relación de aspecto bastante limitada (véase "Abordando las extremidades" más adelante).
Aunque varias implementaciones cuentan con escalamiento a través de RealESRGAN (y puede corregir caras mal representadas a través de GFPGAN) varios usuarios están desarrollando actualmente métodos para dividir imágenes en secciones de 512x512px y unir las imágenes para formar obras compuestas más grandes.

Este renderizado de 1024 × 576, una resolución normalmente imposible en un solo renderizado de difusión estable, se creó copiando y pegando el archivo de Python de atención.py del PerrogettX bifurcación de Stable Diffusion (una versión que implementa escalado basado en mosaicos) en otra bifurcación. Fuente: https://old.reddit.com/r/StableDiffusion/comments/x6yeam/1024x576_with_6gb_nice/
Aunque algunas iniciativas de este tipo utilizan código original u otras bibliotecas, el puerto txt2imghd de GOBIG (un modo en ProgRockDiffusion hambriento de VRAM) está configurado para proporcionar esta funcionalidad a la rama principal pronto. Si bien txt2imghd es un puerto dedicado de GOBIG, otros esfuerzos de los desarrolladores de la comunidad involucran diferentes implementaciones de GOBIG.

Una imagen convenientemente abstracta en el render original de 512x512px (izquierda y segunda desde la izquierda); escalada mediante ESGRAN, que ahora es más o menos nativo en todas las distribuciones de difusión estable; y a la que se le ha dado "atención especial" mediante una implementación de GOBIG, produciendo detalles que, al menos dentro de los límites de la sección de la imagen, parecen mejor escalados.Fuente: https://old.reddit.com/r/StableDiffusion/comments/x72460/stable_diffusion_gobig_txt2imghd_easy_mode_colab/
El tipo de ejemplo abstracto presentado arriba tiene muchos 'pequeños reinos' de detalles que se adaptan a este enfoque solipsista para aumentar la escala, pero que pueden requerir soluciones impulsadas por código más desafiantes para producir un aumento de escala cohesivo y no repetitivo que no look Como si estuviera ensamblado a partir de muchas piezas. Sobre todo en el caso de los rostros humanos, donde estamos inusualmente sensibles a las aberraciones o a los artefactos "discordantes". Por lo tanto, los rostros podrían eventualmente requerir una solución específica.
Actualmente, Stable Diffusion no cuenta con un mecanismo para enfocar la atención en el rostro durante el renderizado, de la misma forma que los humanos priorizamos la información facial. Aunque algunos desarrolladores en las comunidades de Discord están considerando métodos para implementar este tipo de "atención mejorada", actualmente es mucho más fácil mejorar el rostro manualmente (y, eventualmente, automáticamente) después del renderizado inicial.
Un rostro humano tiene una lógica semántica interna y completa que no se encontrará en un "mosaico" de la esquina inferior de (por ejemplo) un edificio y, por lo tanto, actualmente es posible "acercar" de manera muy efectiva y volver a renderizar un rostro "esquematizado" en la salida de Difusión estable.

Izquierda, el trabajo inicial de Stable Diffusion con la consigna «Fotografía a color de cuerpo entero de Christina Hendricks entrando en un lugar concurrido, con impermeable; Canon 50, contacto visual, alto nivel de detalle, alto nivel de detalle facial». Derecha, un rostro mejorado obtenido al devolver a Stable Diffusion el rostro borroso y esbozado del primer renderizado mediante Img2Img (ver imágenes animadas a continuación).
En ausencia de una solución de inversión textual dedicada (ver a continuación), esto solo funcionará para imágenes de celebridades donde la persona en cuestión ya está bien representada en los subconjuntos de datos LAION que entrenaron Stable Diffusion. Por lo tanto, funcionará con personas como Tom Cruise, Brad Pitt, Jennifer Lawrence y una gama limitada de luminarias genuinas de los medios que están presentes en una gran cantidad de imágenes en los datos de origen.
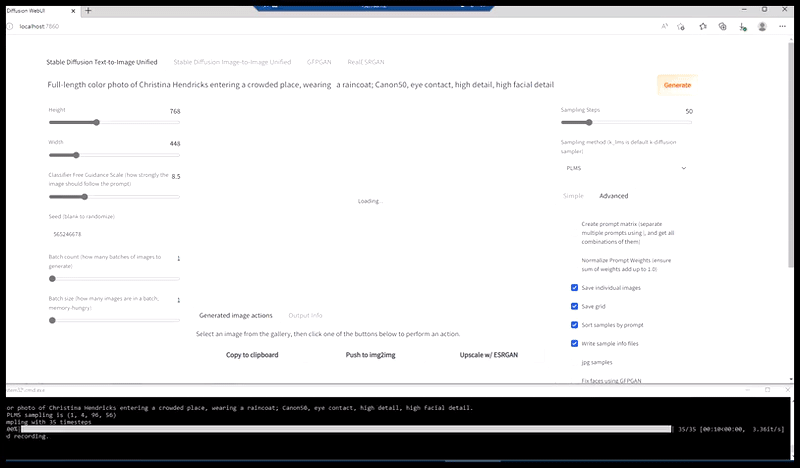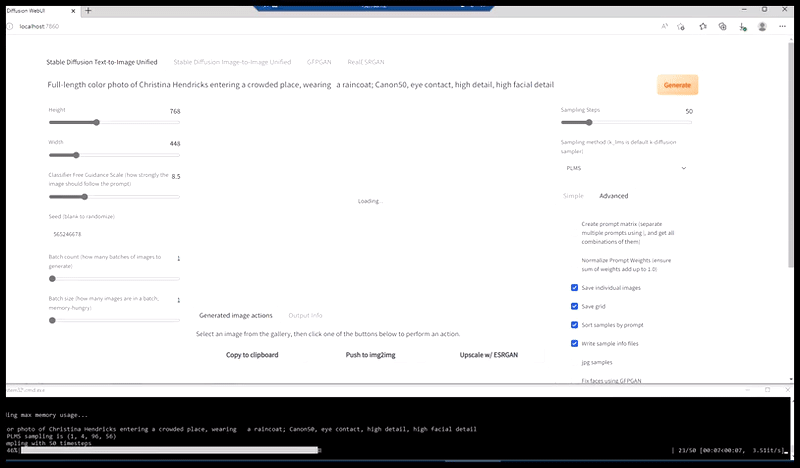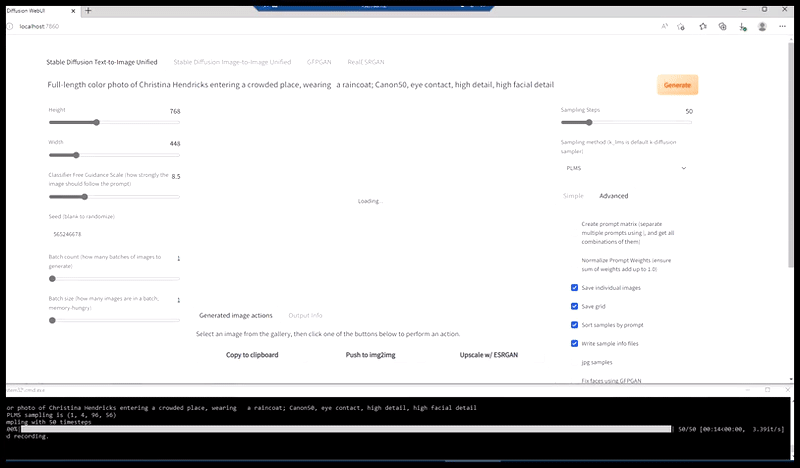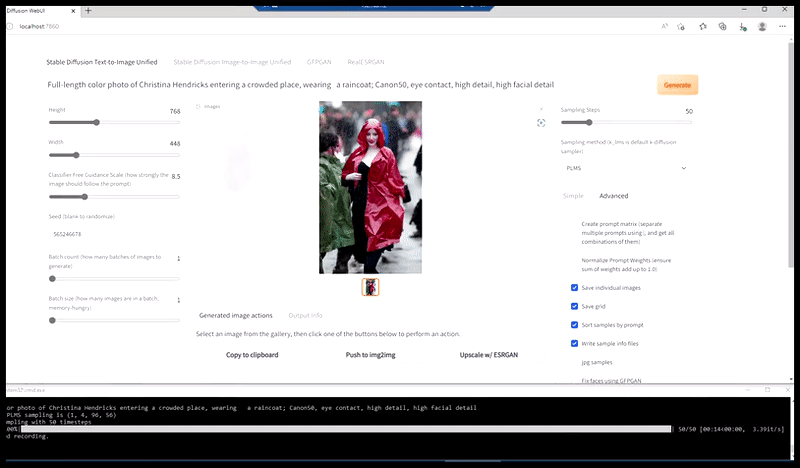
Generar una imagen de prensa plausible con el mensaje 'Fotografía a color de cuerpo entero de Christina Hendricks entrando a un lugar lleno de gente, vistiendo un impermeable; Canon 50, contacto visual, alto nivel de detalle, alto nivel de detalle facial'.
Para celebridades con carreras largas y duraderas, Stable Diffusion generalmente generará una imagen de la persona a una edad reciente (es decir, mayor), y será necesario agregar complementos rápidos como 'joven' or 'en el año [AÑO]' para producir imágenes más jóvenes.

Con una carrera prominente, muy fotografiada y consistente que abarca casi 40 años, la actriz Jennifer Connelly es una de las pocas celebridades en LAION que permiten que Stable Diffusion represente una variedad de edades. Fuente: Prepack Stable Diffusion, local, punto de control v1.4; indicaciones relacionadas con la edad.
Esto se debe en gran parte a la proliferación de fotografías de prensa digitales (en lugar de costosas, basadas en emulsión) a partir de mediados de la década de 2000 y al crecimiento posterior en el volumen de salida de imágenes debido al aumento de las velocidades de banda ancha.
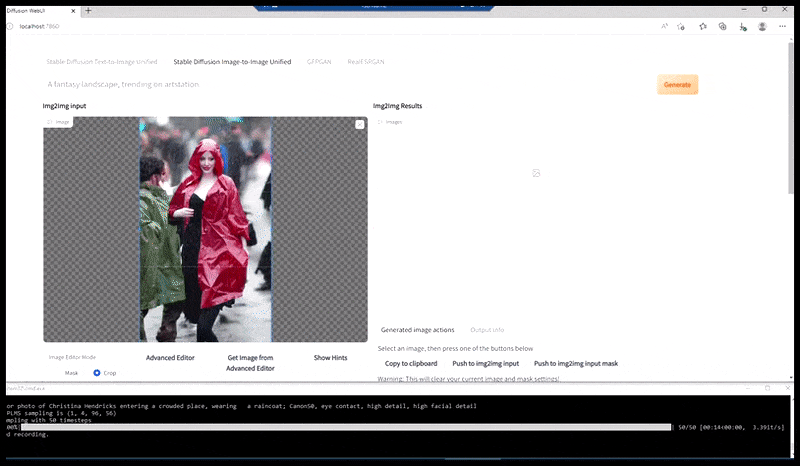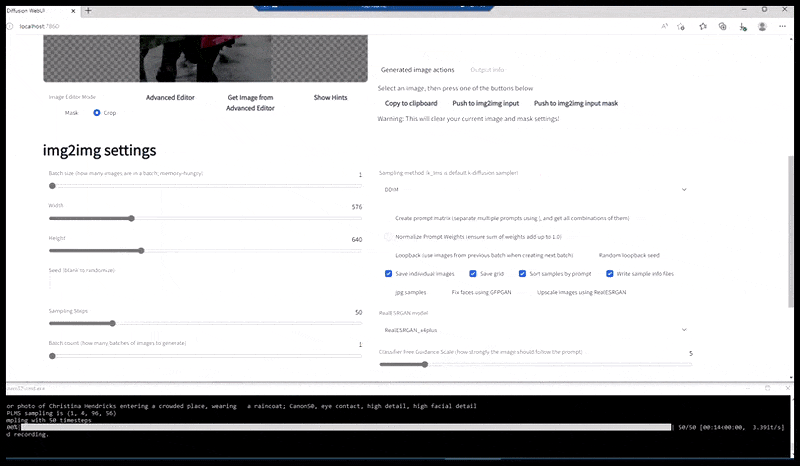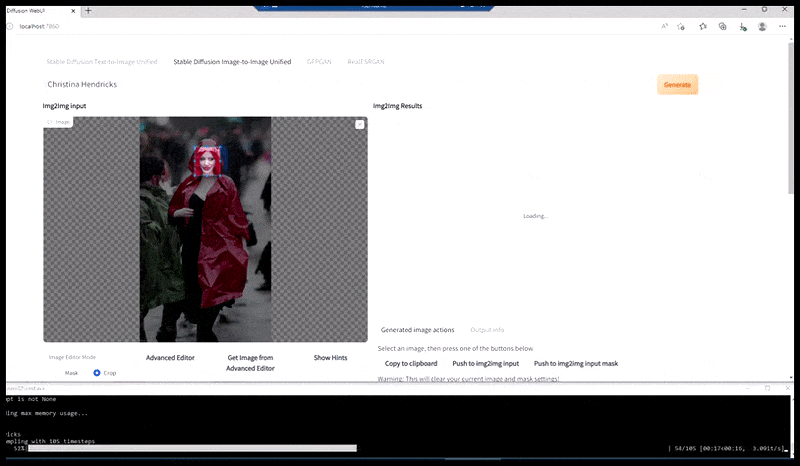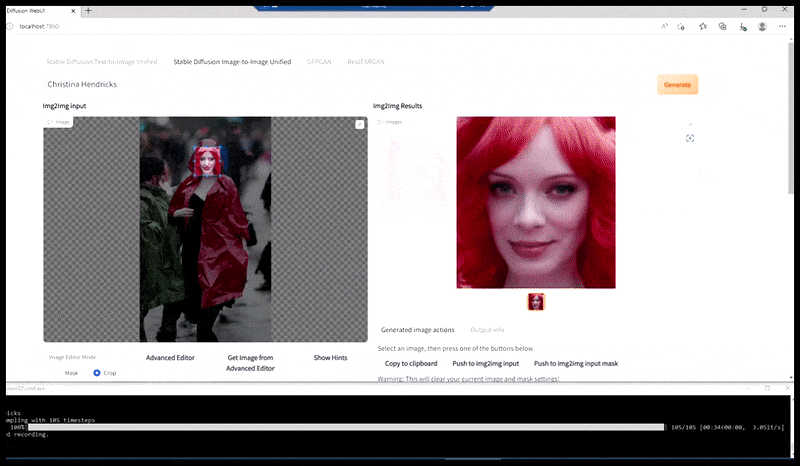
La imagen renderizada pasa a Img2Img en Stable Diffusion, donde se selecciona un "área de enfoque" y se realiza una nueva renderización de tamaño máximo solo de esa área, lo que permite que Stable Diffusion concentre todos los recursos disponibles en recrear el rostro.
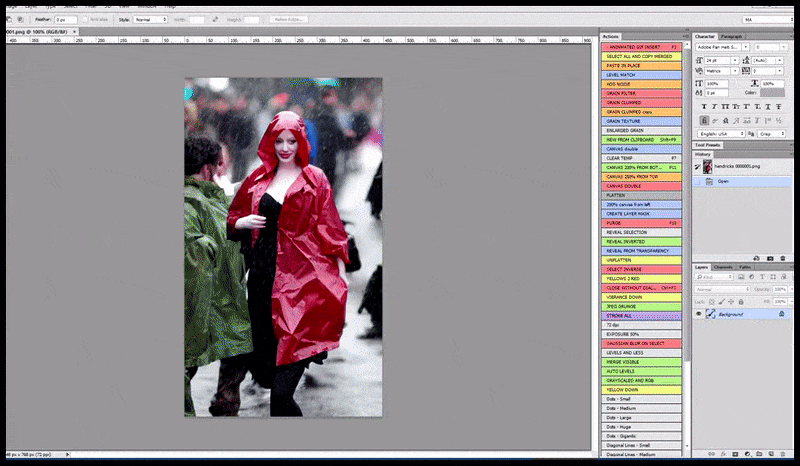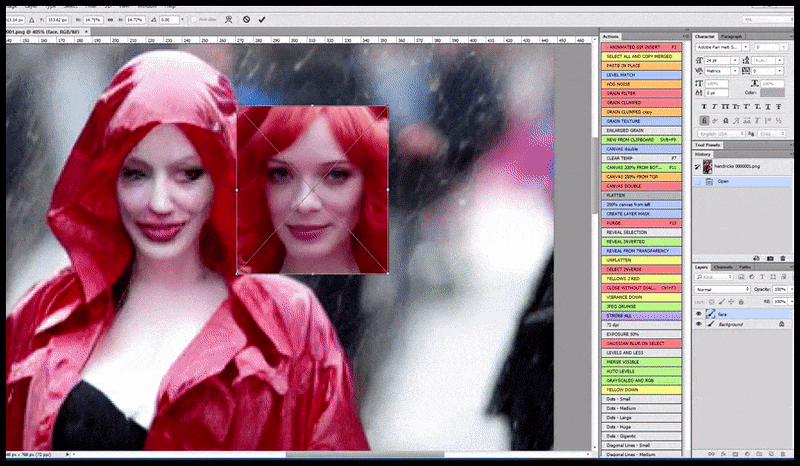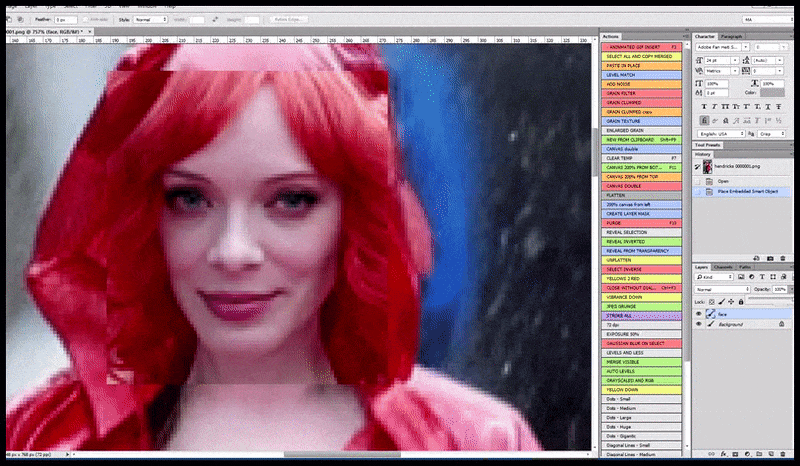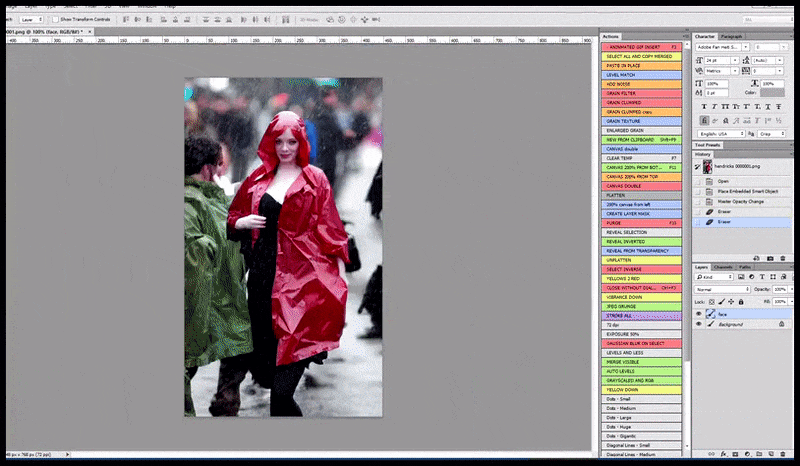
Recomponer la cara que llama la atención en el render original. Además de las caras, este proceso solo funciona con entidades que tengan una apariencia conocida, cohesiva e integral, como una parte de la foto original que contenga un objeto distintivo, como un reloj o un coche. Aumentar la escala de una sección de, por ejemplo, una pared dará como resultado una pared reensamblada de aspecto muy extraño, ya que los renders de mosaicos no tenían un contexto más amplio para esta pieza de rompecabezas durante el renderizado.
Algunas celebridades de la base de datos aparecen "precongeladas" en el tiempo, ya sea porque fallecieron prematuramente (como Marilyn Monroe) o porque alcanzaron una fama efímera, generando un gran volumen de imágenes en un período limitado. La difusión estable por sondeo (Stable Diffusion) podría proporcionar una especie de índice de popularidad "actual" para estrellas modernas y antiguas. Para algunas celebridades, tanto antiguas como actuales, no hay suficientes imágenes en los datos originales para obtener un buen parecido, mientras que la popularidad duradera de ciertas estrellas fallecidas hace tiempo o en decadencia garantiza que se pueda obtener un parecido razonable con el sistema.

Los renderizados de Stable Diffusion revelan rápidamente qué caras famosas están bien representadas en los datos de entrenamiento. A pesar de su enorme popularidad como adolescente mayor en el momento de escribir este artículo, Millie Bobby Brown era más joven y menos conocida cuando los conjuntos de datos de origen de LAION se extrajeron de la web, por lo que una similitud de alta calidad con Stable Diffusion era problemática en este momento.
Cuando los datos estén disponibles, las soluciones de resolución superior basadas en mosaicos en Stable Diffusion podrían ir más allá de centrarse en la cara: potencialmente podrían habilitar caras aún más precisas y detalladas al desglosar las características faciales y convertir toda la fuerza de la GPU local. recursos sobre características destacadas individualmente, antes del reensamblaje, un proceso que actualmente, nuevamente, es manual.

Esto no se limita a las caras, pero se limita a las partes de los objetos que están colocadas de manera predecible en el contexto más amplio del objeto anfitrión, y que se ajustan a las incrustaciones de alto nivel que uno podría esperar razonablemente encontrar en una hiperescala. conjunto de datos
El verdadero límite es la cantidad de datos de referencia disponibles en el conjunto de datos, porque, con el tiempo, los detalles profundamente iterados se volverán totalmente "alucinados" (es decir, ficticios) y menos auténticos.
Tales ampliaciones granulares de alto nivel funcionan en el caso de Jennifer Connelly, porque está bien representada en un rango de edades en LAION-estética (el subconjunto principal de LAION 5B que utiliza Stable Diffusion) y, en general, en LAION; en muchos otros casos, la precisión se vería afectada por la falta de datos, lo que requeriría un ajuste fino (capacitación adicional, consulte 'Personalización' a continuación) o una inversión textual (consulte a continuación).
Los mosaicos son una forma poderosa y relativamente económica de permitir que Stable Diffusion genere resultados de alta resolución, pero la ampliación algorítmica de mosaicos de este tipo, si carece de algún tipo de mecanismo de atención más amplio y de mayor nivel, puede no ser lo esperado. para estándares en una variedad de tipos de contenido.
2: Abordar problemas con las extremidades humanas
Stable Diffusion no hace honor a su nombre al representar la complejidad de las extremidades humanas. Las manos pueden multiplicarse aleatoriamente, los dedos se fusionan, aparecen terceras piernas sin ser invitadas y las extremidades existentes desaparecen sin dejar rastro. En su defensa, Stable Diffusion comparte el problema con sus compañeros de cuadra, y sin duda con DALL-E 2.

Resultados sin editar de DALL-E 2 y Difusión Estable (1.4) a finales de agosto de 2022, que muestran problemas en las extremidades. El mensaje es «Una mujer abrazando a un hombre».
Es probable que los fanáticos de Stable Diffusion que esperan que el próximo punto de control 1.5 (una versión más intensamente entrenada del modelo, con parámetros mejorados) resuelva la confusión de las extremidades se sientan decepcionados. El nuevo modelo, que será lanzado en aproximadamente dos semanas, actualmente se está estrenando en el portal comercial stable.ai DreamStudio, que usa 1.5 de manera predeterminada, y donde los usuarios pueden comparar la nueva salida con los renderizados de sus sistemas locales u otros sistemas 1.4:

Fuente: Prepack Local 1.4 y https://beta.dreamstudio.ai/

Fuente: Prepack Local 1.4 y https://beta.dreamstudio.ai/

Fuente: Prepack Local 1.4 y https://beta.dreamstudio.ai/
Como suele ser el caso, la calidad de los datos bien podría ser la principal causa contribuyente.
Las bases de datos de código abierto que alimentan los sistemas de síntesis de imágenes, como Stable Diffusion y DALL-E 2, pueden proporcionar muchas etiquetas tanto para humanos individuales como para acciones interhumanas. Estas etiquetas se entrenan simbióticamente con sus imágenes asociadas o segmentos de imágenes.

Los usuarios de Stable Diffusion pueden explorar los conceptos entrenados en el modelo consultando el conjunto de datos LAION-estética, un subconjunto del conjunto de datos LAION 5B, que alimenta el sistema. Las imágenes se ordenan no por etiquetas alfabéticas, sino por su puntuación estética. Fuente: https://rom1504.github.io/clip-retrieval/
A buena jerarquía de etiquetas y clases individuales que contribuyen a la representación de un brazo humano sería algo así como cuerpo>brazo>mano>dedos>[sub dígitos + pulgar]> [segmentos de dígitos]>uñas.

Segmentación semántica granular de las partes de una mano. Incluso esta deconstrucción inusualmente detallada deja cada dedo como una sola entidad, sin tener en cuenta las tres secciones de un dedo y las dos secciones del pulgar. Fuente: https://athitsos.utasites.cloud/publications/rezaei_petra2021.pdf
En realidad, es poco probable que las imágenes de origen se anoten de manera tan consistente en todo el conjunto de datos, y los algoritmos de etiquetado no supervisados probablemente se detengan en el higher nivel de, por ejemplo, "mano", y dejar los píxeles interiores (que técnicamente contienen información de "dedo") como una masa de píxeles sin etiquetar de la que se derivarán características arbitrariamente, y que pueden manifestarse en representaciones posteriores como un elemento discordante.

Cómo debería ser (arriba a la derecha, si no en la parte superior) y cómo tiende a ser (abajo a la derecha), debido a los recursos limitados para el etiquetado o la explotación arquitectónica de tales etiquetas si existen en el conjunto de datos.
Por lo tanto, si un modelo de difusión latente llega a representar un brazo, es casi seguro que al menos intentará representar una mano en el extremo de ese brazo, porque brazo>mano es la jerarquía mínima requerida, bastante alta en lo que la arquitectura sabe sobre "anatomía humana".
Después de eso, los "dedos" pueden ser el grupo más pequeño, a pesar de que hay 14 subpartes más de dedos/pulgares a tener en cuenta al representar manos humanas.
Si esta teoría se mantiene, no existe un remedio real, debido a la falta de presupuesto en todo el sector para la anotación manual y la falta de algoritmos adecuadamente efectivos que puedan automatizar el etiquetado y producir tasas de error bajas. En efecto, es posible que el modelo se base actualmente en la consistencia anatómica humana para ocultar las deficiencias del conjunto de datos en el que se entrenó.
Una posible razón por la que no se puede confiar en esto, recientemente propuesto en Stable Diffusion Discord, es que el modelo podría confundirse acerca de la cantidad correcta de dedos que debería tener una mano humana (realista) porque la base de datos derivada de LAION que la alimenta presenta personajes de dibujos animados que pueden tener menos dedos (lo cual es en sí mismo un atajo para ahorrar trabajo).

Dos de los posibles culpables del síndrome del dedo ausente en Difusión Estable y modelos similares. A continuación, se muestran ejemplos de manos de dibujos animados del conjunto de datos LAION-estética que sustenta Difusión Estable. Fuente: https://www.youtube.com/watch?v=0QZFQ3gbd6I
Si esto es cierto, entonces la única solución obvia es volver a entrenar el modelo, excluyendo el contenido basado en humanos no realista, asegurando que los casos genuinos de omisión (es decir, amputados) se etiqueten adecuadamente como excepciones. Solo desde el punto de vista de la curación de datos, esto sería todo un desafío, particularmente para los esfuerzos comunitarios hambrientos de recursos.
El segundo enfoque sería aplicar filtros que excluyan dicho contenido (es decir, "mano con tres o cinco dedos") para que no se manifieste en el momento de renderizado, de la misma manera que OpenAI lo ha hecho, hasta cierto punto. filtrado GPT-3 y DALL-E2, de modo que su salida podría regularse sin necesidad de volver a entrenar los modelos de origen.

Para Stable Diffusion, la distinción semántica entre dígitos e incluso extremidades puede volverse terriblemente borrosa, recordando la corriente de terror corporal de las películas de los años 1980 de autores como David Cronenberg. Fuente: https://old.reddit.com/r/StableDiffusion/comments/x6htf6/a_study_of_stable_diffusions_strange_relationship/
Sin embargo, nuevamente, esto requeriría etiquetas que pueden no existir en todas las imágenes afectadas, dejándonos con el mismo desafío logístico y presupuestario.
Se podría argumentar que quedan dos caminos por recorrer: arrojar más datos sobre el problema y aplicar sistemas interpretativos de terceros que puedan intervenir cuando se presentan al usuario final errores físicos del tipo descrito aquí (como mínimo, esto último le daría a OpenAI un método para proporcionar reembolsos por representaciones de "horror corporal", si la empresa estuviera motivada para hacerlo).
3: Personalización
Una de las posibilidades más emocionantes para el futuro de Stable Diffusion es la posibilidad de que los usuarios u organizaciones desarrollen sistemas revisados; modificaciones que permiten que el contenido fuera de la esfera LAION previamente entrenada se integre en el sistema, idealmente sin el gasto ingobernable de entrenar todo el modelo nuevamente, o el riesgo que implica entrenar en un gran volumen de imágenes novedosas a un sistema existente, maduro y capaz. modelo.
Por analogía: si dos estudiantes menos dotados se incorporan a una clase avanzada de treinta estudiantes, se integrarán y se pondrán al día, o bien suspenderán como alumnos atípicos; en cualquier caso, el rendimiento promedio de la clase probablemente no se verá afectado. Sin embargo, si se incorporan 15 estudiantes menos dotados, es probable que la curva de calificaciones de toda la clase se vea afectada.
Del mismo modo, la red de relaciones sinérgica y bastante delicada que se construye a través del entrenamiento sostenido y costoso del modelo puede verse comprometida, en algunos casos efectivamente destruida, por un exceso de datos nuevos, lo que reduce la calidad de salida del modelo en todos los ámbitos.
La razón para hacer esto es principalmente que su interés radica en secuestrar por completo la comprensión conceptual del modelo sobre las relaciones y las cosas, y apropiársela para la producción exclusiva de contenido que sea similar al material adicional que agregó.
Así, capacitando a 500,000 Simpson marcos en un punto de control de difusión estable existente es probable, eventualmente, para obtener una mejor Simpson simulador de lo que podría haber ofrecido la compilación original, suponiendo que suficientes relaciones semánticas amplias sobrevivan al proceso (es decir, Homer Simpson comiendo un perrito caliente, lo que puede requerir material sobre perritos calientes que no estaba en su material adicional, pero que ya existía en el punto de control), y suponiendo que no desea cambiar repentinamente de Simpson contenido para crear fabuloso paisaje de Greg Rutkowski – porque su modelo post-entrenado ha desviado enormemente su atención y no será tan bueno en hacer ese tipo de cosas como solía ser.
Un ejemplo notable de esto es waifu-difusión, que ha tenido éxito 56,000 imágenes de anime postentrenadas En un punto de control de Difusión Estable completado y entrenado. Sin embargo, es una tarea difícil para un aficionado, ya que el modelo requiere un mínimo desorbitado de 30 GB de VRAM, mucho más de lo que probablemente estará disponible para el consumidor en las próximas versiones de la serie 40XX de NVIDIA.

El entrenamiento de contenido personalizado en Stable Diffusion a través de waifu-diffusion: el modelo tomó dos semanas de entrenamiento posterior para generar este nivel de ilustración. Las seis imágenes de la izquierda muestran el progreso del modelo, a medida que avanzaba el entrenamiento, para generar resultados coherentes con el sujeto en función de los nuevos datos de entrenamiento. Fuente: https://gigazine.net/gsc_news/en/20220121-how-waifu-labs-create/
Se podría invertir mucho esfuerzo en estas "bifurcaciones" de los puntos de control de Difusión Estable, solo para verse obstaculizado por la deuda técnica. Los desarrolladores del Discord oficial ya han indicado que las versiones posteriores de los puntos de control no serán necesariamente compatibles con versiones anteriores, incluso con la lógica de indicaciones que pudo haber funcionado con una versión anterior, ya que su principal interés es obtener el mejor modelo posible, en lugar de dar soporte a aplicaciones y procesos heredados.
Por lo tanto, una empresa o individuo que decide convertir un punto de control en un producto comercial efectivamente no tiene vuelta atrás; su versión del modelo es, en ese punto, una "bifurcación dura" y no podrá obtener beneficios de versiones posteriores de stable.ai, lo que es un gran compromiso.
La esperanza actual y mayor para la personalización de Stable Diffusion es inversión textual, donde el usuario entrena en un pequeño puñado de CLIP-imágenes alineadas.

Una colaboración entre la Universidad de Tel Aviv y NVIDIA, la inversión textual permite el entrenamiento de entidades discretas y novedosas, sin destruir las capacidades del modelo fuente. Fuente: https://textual-inversion.github.io/
La principal limitación aparente de la inversión textual es que se recomienda un número muy bajo de imágenes, tan solo cinco. Esto produce efectivamente una entidad limitada que puede ser más útil para tareas de transferencia de estilo en lugar de la inserción de objetos fotorrealistas.
No obstante, actualmente se están realizando experimentos dentro de los diversos Discords de difusión estable que utilizan un número mucho mayor de imágenes de entrenamiento, y queda por ver qué tan productivo podría resultar el método. Nuevamente, la técnica requiere una gran cantidad de VRAM, tiempo y paciencia.
Debido a estos factores limitantes, es posible que tengamos que esperar un tiempo para ver algunos de los experimentos de inversión textual más sofisticados de los entusiastas de Stable Diffusion, y si este enfoque puede "colocarte en la imagen" de una manera que se vea mejor que un cortar y pegar de Photoshop, al tiempo que conserva la sorprendente funcionalidad de los puntos de control oficiales.
Publicado por primera vez el 6 de septiembre de 2022.












