Inteligencia artificial
El techo del 75%: ¿Han alcanzado los modelos de IA su rendimiento máximo con los métodos actuales?

Anthropic y OpenAI presentaron modelos de IA de vanguardia con dos días de diferencia, logrando una precisión virtualmente idéntica del 74-75% en las pruebas de codificación de la industria, lo que indica un posible techo de rendimiento para las arquitecturas de IA actuales, mientras que adoptan enfoques dramáticamente diferentes para la distribución y la implementación.
Las lanzamientos casi simultáneos plantean preguntas fundamentales sobre si el desarrollo de IA ha alcanzado un punto muerto con los métodos de entrenamiento actuales, incluso mientras las empresas divergen agudamente en cómo entregar estas capacidades a los usuarios y desarrolladores de todo el mundo.
Puntos de convergencia de las pruebas que indican un hito técnico
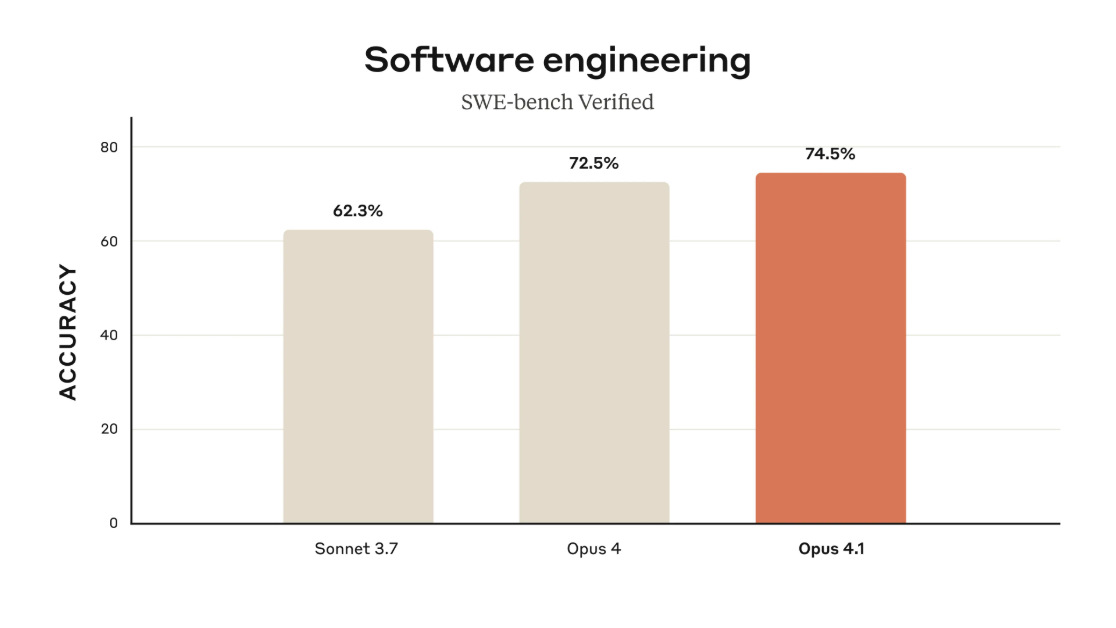
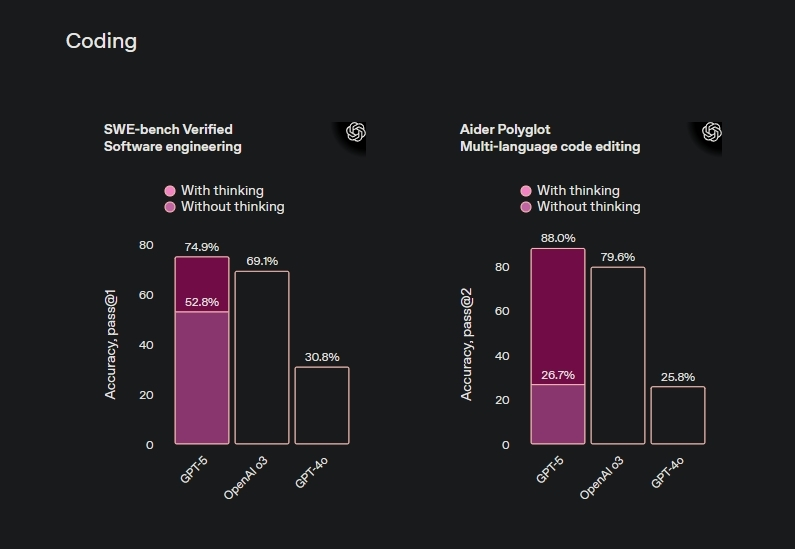
Claude Opus 4.1, lanzado el 5 de agosto por Anthropic, obtuvo un 74,5% en SWE-bench Verified, la prueba de codificación estándar de la industria. GPT-5 de OpenAI, anunciado el 7 de agosto, logró un 74,9% en la misma prueba, un empate estadístico que sugiere que ambas empresas han empujado las arquitecturas actuales a límites similares a pesar de trabajar de forma independiente.
La diferencia del 0,4% entre los modelos se encuentra dentro del margen de ruido estadístico para dichas pruebas.
Los enfoques arquitectónicos, sin embargo, divergen significativamente. OpenAI construyó GPT-5 como un sistema de multi-modelo con enrutamiento inteligente, las consultas se dirigen a respondedores rápidos para tareas simples, modelos de razonamiento para problemas complejos, o versiones miniatura cuando se alcanzan los límites de cómputo. Anthropic mantuvo un enfoque de modelo único con Opus 4.1, priorizando la coherencia sobre la optimización especializada.
Fuente: Anthropic
Estrategias de distribución que revelan filosofías en competencia
OpenAI hizo que GPT-5 estuviera disponible de inmediato para todos los usuarios de ChatGPT, incluidos aquellos en el nivel gratuito, alcanzando aproximadamente 700 millones de usuarios activos semanales sin costo. Microsoft integró simultáneamente el modelo en GitHub Copilot, Visual Studio Code, M365 Copilot y plataformas de Azure.
Anthropic mantiene restricciones de acceso más tradicionales, ofreciendo Opus 4.1 a usuarios pagos de Claude, a través de Claude Code para desarrolladores y mediante acceso a la API. La empresa parece centrarse en servir a desarrolladores y empresas que requieren un rendimiento confiable y coherente en lugar de maximizar el alcance de la distribución.
El precio de GPT-5 es agresivo, y los desarrolladores señalan una relación favorable entre costo y capacidad que podría presionar a los competidores para ajustar sus estrategias de precios.
Requisitos de infraestructura que reconfiguran la economía de la industria
Los requisitos computacionales revelan la escala masiva del desarrollo de IA de vanguardia. Según se informa, OpenAI mantiene un contrato anual de $30 mil millones con Oracle para capacidad, después de haber entrenado a GPT-5 en Microsoft Azure utilizando GPU NVIDIA H200. Meta anunció planes para gastar $72 mil millones en infraestructura de IA en 2025 solo.
Ambas empresas informan mejoras significativas en aplicaciones prácticas más allá de las pruebas crudas. OpenAI afirma que GPT-5 demuestra “aproximadamente un 45% menos de errores que GPT-4o” cuando se habilita la búsqueda en la web, con el modo de pensamiento que logra resultados similares al modelo o3 mientras utiliza un 50-80% menos de tokens, una ganancia de eficiencia sustancial.
GitHub informa que Opus 4.1 muestra “mejoras de rendimiento notables en la refactorización de código multi-archivo”, mientras que Cursor, un asistente de codificación de IA popular, describe a GPT-5 como “remarkablemente inteligente, fácil de dirigir”, según la documentación para desarrolladores de OpenAI.
Fuente: OpenAI
Techo técnico que sugiere un cambio de paradigma
La convergencia en métricas de rendimiento similares en varias empresas sugiere que los paradigmas de entrenamiento actuales pueden estar alcanzando sus límites. La agrupación de múltiples modelos alrededor del 74-75% de precisión en pruebas de codificación indica que las próximas mejoras importantes pueden requerir innovaciones fundamentales en lugar de escalado incremental.
Los compromisos arquitectónicos entre el sistema de enrutamiento complejo de OpenAI y el enfoque unificado de Anthropic reflejan filosofías diferentes sin un ganador claro. El sistema de multi-modelo de GPT-5 ofrece flexibilidad pero introduce posibles puntos de falla, mientras que la coherencia de Claude puede sacrificar el rendimiento especializado por la confiabilidad.
La democratización de las capacidades de IA de vanguardia, con características que costaban miles anualmente hace dos años y ahora están disponibles de forma gratuita, acelera la adopción en diversas industrias. Esta transición de IA como servicio premium a infraestructura de utilidad podría permitir categorías de aplicaciones completamente nuevas.
Implicaciones del mercado y próximos pasos
Los observadores de la industria esperan que Anthropic responda a la estrategia de precios de OpenAI, aunque probablemente no a través de un ajuste directo de precios. Google’s DeepMind y Meta, relativamente callados durante estos anuncios, se espera que hagan movimientos en los próximos meses.
La ventana de 48 horas entre los lanzamientos reveló la transición de la IA de tecnología experimental a infraestructura confiable. Cuando varias empresas logran puntuaciones de pruebas casi idénticas con diferencias porcentuales fraccionarias, la competencia se desplaza hacia la eficiencia de la implementación, la calidad de la integración y la confiabilidad del servicio.
Las mejoras prácticas son más importantes que la supremacía de las pruebas. SWE-bench Verified mide la capacidad de una IA para identificar y corregir errores reales en software de código abierto, y las puntuaciones de ambos modelos representan avances significativos en las capacidades de codificación autónoma.
A medida que los modelos de IA se vuelven cada vez más sofisticados en sus capacidades de razonamiento y codificación, la competencia se desplaza desde las métricas de rendimiento crudas hacia la implementación práctica y la confiabilidad en entornos de producción. La verdad sorprendente: esta estabilidad podría permitir un cambio más transformador que otro avance.












