Inteligencia artificial
Cómo Stable Diffusion podría desarrollarse como un producto de consumo mainstream

Irónicamente, Stable Diffusion, el nuevo marco de síntesis de imágenes de IA que ha conquistado el mundo, no es ni estable ni realmente “difundido” – al menos, no todavía.
La gama completa de capacidades del sistema se extiende a través de una variedad de ofertas que mutan constantemente de un puñado de desarrolladores que intercambian frenéticamente la información y las teorías más recientes en coloquios diversos en Discord – y la gran mayoría de los procedimientos de instalación de los paquetes que están creando o modificando están muy lejos de ser “plug and play”.
En su lugar, tienden a requerir instalación a través de línea de comandos o BAT a través de GIT, Conda, Python, Miniconda y otros marcos de desarrollo de vanguardia – paquetes de software tan raros entre el público en general que su instalación es frecuentemente marcada por proveedores de antivirus y anti-malware como evidencia de un sistema comprometido.

Solo una pequeña selección de etapas en el desafío que actualmente requiere la instalación estándar de Stable Diffusion. Muchas de las distribuciones también requieren versiones específicas de Python, que pueden entrar en conflicto con las versiones existentes instaladas en la máquina del usuario – aunque esto se puede evitar con instalaciones basadas en Docker y, en cierta medida, a través del uso de entornos Conda.
Los hilos de mensaje en las comunidades de Stable Diffusion SFW y NSFW están inundados de consejos y trucos relacionados con la modificación de scripts de Python y la instalación estándar, con el fin de habilitar una funcionalidad mejorada o resolver errores de dependencia frecuentes y una serie de otros problemas.
Esto deja al consumidor promedio, interesado en crear imágenes increíbles a partir de textos, prácticamente a merced del creciente número de interfaces web de API monetizadas, la mayoría de las cuales ofrecen un número mínimo de generaciones de imágenes gratuitas antes de requerir la compra de tokens.
Además, casi todas estas ofertas web se niegan a generar contenido NSFW (mucho del cual puede relacionarse con temas de interés general que no son pornografía, como “guerra”).
‘Photoshop para Stable Diffusion’
Lo que el mundo en general está esperando con ansias es ‘Photoshop para Stable Diffusion’ – una aplicación instalable multiplataforma que combine la mejor y más poderosa funcionalidad de la arquitectura de Stability.ai, así como las diversas innovaciones ingeniosas de la comunidad de desarrollo de SD en surgimiento, sin ventanas de línea de comandos flotantes, rutinas de instalación y actualización oscuras y cambiantes, o características que faltan.
Lo que tenemos actualmente, en la mayoría de las instalaciones más capaces, es una página web elegante con una ventana de línea de comandos desencarnada, y cuya URL es un puerto localhost:

Similar a aplicaciones de síntesis de CLI como FaceSwap y DeepFaceLab, la instalación ‘prepack’ de Stable Diffusion muestra sus raíces de línea de comandos, con la interfaz accesible a través de un puerto localhost (ver parte superior de la imagen de arriba) que se comunica con la funcionalidad de Stable Diffusion basada en CLI.
Sin duda, una aplicación más fluida está en camino. Ya hay varias aplicaciones integrales basadas en Patreon que se pueden descargar, como GRisk y NMKD (ver imagen a continuación) – pero ninguna que, hasta ahora, integre el conjunto completo de características que algunas de las implementaciones más avanzadas y menos accesibles de Stable Diffusion pueden ofrecer.

Paquetes iniciales de Stable Diffusion, ligeramente ‘aplicacionizados’. La de NMKD es la primera en integrar la salida de CLI directamente en la GUI.
Veamos cómo podría ser una implementación más pulida y integral de esta asombrosa maravilla de código abierto – y qué desafíos podría enfrentar.
Consideraciones legales para una aplicación de Stable Diffusion comercial completamente financiada
El factor NSFW
El código fuente de Stable Diffusion se ha lanzado bajo una licencia extremadamente permissiva que no prohíbe reimplementaciones comerciales y obras derivadas que se basen ampliamente en el código fuente.
Además de las mencionadas y crecientes aplicaciones basadas en Patreon, así como el gran número de complementos de aplicación que se están desarrollando para Figma, Krita, Photoshop, GIMP y Blender (entre otros), no hay razón práctica por la que una casa de desarrollo de software bien financiada no pudiera desarrollar una aplicación de Stable Diffusion mucho más sofisticada y capaz. Desde una perspectiva de mercado, hay toda la razón para creer que varias de estas iniciativas ya están en marcha.
Aquí, tales esfuerzos enfrentan inmediatamente el dilema de si la aplicación permitirá o no que el filtro NSFW nativo de Stable Diffusion (un fragmento de código) se desactive.
‘Enterrar’ el interruptor NSFW
Aunque la licencia de código abierto de Stability.ai para Stable Diffusion incluye una lista ampliamente interpretable de aplicaciones para las que no se puede utilizar (que incluye, posiblemente, contenido pornográfico y deepfakes), la única forma en que un proveedor podría prohibir efectivamente dicho uso sería compilar el filtro NSFW en un ejecutable opaco en lugar de un parámetro en un archivo Python, o bien hacer cumplir una comparación de suma de comprobación en el archivo Python o DLL que contiene la directiva NSFW, para que no se puedan producir renderizados si los usuarios alteran esta configuración.
Esto dejaría a la aplicación putativa ‘castrada’ de la misma manera que DALL-E 2 actualmente lo está, disminuyendo su atractivo comercial. Además, inevitablemente, las versiones ‘manipuladas’ de estos componentes (ya sean elementos de tiempo de ejecución de Python originales o archivos DLL compilados, como los que se utilizan en la línea de herramientas de mejora de imágenes de IA de Topaz) probablemente surgirían en la comunidad de piratería/torrent para desbloquear tales restricciones, simplemente reemplazando los elementos obstructivos y anulando cualquier requisito de suma de comprobación.
Al final, el proveedor puede optar por simplemente repetir la advertencia de Stability.ai contra el mal uso que caracteriza la primera ejecución de muchas distribuciones actuales de Stable Diffusion.
Sin embargo, los pequeños desarrolladores de código abierto que actualmente utilizan descargos casuales de esta manera tienen poco que perder en comparación con una empresa de software que ha invertido cantidades significativas de tiempo y dinero en hacer que Stable Diffusion sea completo y accesible – lo que invita a una consideración más profunda.
Responsabilidad por deepfakes
Como hemos señalado recientemente, la base de datos LAION-aesthetics, parte de las 4.200 millones de imágenes en las que se entrenaron los modelos actuales de Stable Diffusion, contiene un gran número de imágenes de celebridades, lo que permite a los usuarios crear efectivamente deepfakes, incluidos deepfakes de celebridades pornográficas.

De nuestro artículo reciente, cuatro etapas de Jennifer Connelly a lo largo de cuatro décadas de su carrera, inferidas a partir de Stable Diffusion.
Esto es un problema separado y más controvertido que la generación de (generalmente) pornografía “abstracta” legal, que no representa a “personas reales” (aunque tales imágenes se infieren de múltiples fotos reales en el material de entrenamiento).
Dado que un número creciente de estados de EE. UU. y países están desarrollando o han instituido leyes contra la pornografía de deepfakes, la capacidad de Stable Diffusion para crear pornografía de celebridades podría significar que una aplicación comercial que no esté completamente censurada (es decir, que pueda generar material pornográfico) podría necesitar algún tipo de filtro para reconocer caras de celebridades.
Un método sería proporcionar una lista negra integrada de términos que no se aceptarán en una llamada de usuario, relacionados con nombres de celebridades y personajes ficticios con los que pueden estar asociados. Presumiblemente, tales configuraciones necesitarían instituirse en más idiomas que solo el inglés, ya que los datos originales presentan otros idiomas. Otro enfoque podría ser incorporar sistemas de reconocimiento de celebridades como los desarrollados por Clarifai.
Puede ser necesario que los productores de software incorporen dichos métodos, quizás inicialmente desactivados, como podría ayudar a prevenir que una aplicación de Stable Diffusion autónoma genere caras de celebridades, pendiente de nueva legislación que podría hacer que dicha funcionalidad sea ilegal.
Una vez más, sin embargo, dicha funcionalidad podría ser inevitablemente descompilada y revertida por partes interesadas; sin embargo, el productor de software podría, en ese caso, afirmar que este es efectivamente un vandalismo no autorizado – siempre y cuando este tipo de ingeniería inversa no se haga excesivamente fácil.
Características que podrían incluirse
La funcionalidad principal en cualquier distribución de Stable Diffusion se esperaría de cualquier aplicación comercial bien financiada. Estas incluyen la capacidad de utilizar textos para generar imágenes apropiadas (texto-imagen); la capacidad de utilizar bocetos o otras imágenes como guías para nuevas imágenes generadas (imagen-imagen); los medios para ajustar cuán “imaginativa” se instruye al sistema para que sea; una forma de equilibrar el tiempo de renderizado con la calidad; y otros “básicos”, como la archivación automática opcional de imágenes y llamadas, y el escalado rutinario opcional a través de RealESRGAN, y al menos la corrección básica de “rostros” con GFPGAN o CodeFormer.
Esa es una instalación “vanilla” bastante estándar. Veamos algunas de las características más avanzadas que actualmente se están desarrollando o extendiendo, que podrían incorporarse en una aplicación completa de Stable Diffusion.
Congelación estocástica
Incluso si vuelves a utilizar una semilla de un renderizado exitoso anterior, es terriblemente difícil lograr que Stable Diffusion repita con precisión una transformación si cualquier parte del texto o la imagen de origen (o ambos) se cambia para un renderizado posterior.
Este es un problema si deseas utilizar EbSynth para imponer las transformaciones de Stable Diffusion en video real de manera temporalmente coherente – aunque la técnica puede ser muy efectiva para tomas simples de cabeza y hombros:

Un movimiento limitado puede hacer que EbSynth sea un medio efectivo para convertir las transformaciones de Stable Diffusion en video realista. Fuente: https://streamable.com/u0pgzd
EbSynth funciona extrapolando una pequeña selección de ‘alteradas’ claves en un video que se ha renderizado en una serie de archivos de imagen (y que luego se puede volver a ensamblar en un video).

En este ejemplo del sitio web de EbSynth, un puñado de cuadros de un video se han pintado de manera artística. EbSynth utiliza estos cuadros como guías de estilo para alterar todo el video para que coincida con el estilo pintado. Fuente: https://www.youtube.com/embed/eghGQtQhY38
En el ejemplo a continuación, que presenta casi ningún movimiento en absoluto desde la (real) instructora de yoga rubia de la izquierda, Stable Diffusion todavía tiene dificultades para mantener una cara coherente, porque las tres imágenes que se transforman como ‘claves’ no son completamente idénticas, aunque todas comparten la misma semilla numérica.

Aquí, incluso con el mismo texto y semilla en todas las tres transformaciones, y muy pocos cambios entre los cuadros de origen, los músculos del cuerpo varían en tamaño y forma, pero lo más importante es que la cara es inconsistente, lo que obstaculiza la coherencia temporal en un posible renderizado de EbSynth.
Aunque el video de SD/EbSynth a continuación es muy inventivo, donde los dedos del usuario se han transformado en (respectivamente) una pareja de piernas de pantalones caminando y un pato, la inconsistencia de los pantalones tipifica el problema que tiene Stable Diffusion para mantener la coherencia en diferentes claves, incluso cuando los cuadros de origen son similares entre sí y la semilla es coherente.

Los dedos de un hombre se convierten en un hombre caminando y un pato, a través de Stable Diffusion y EbSynth. Fuente: https://old.reddit.com/r/StableDiffusion/comments/x92itm/proof_of_concept_using_img2img_ebsynth_to_animate/
El usuario que creó este video comentó que la transformación del pato, que es posiblemente la más efectiva de las dos, si no la más impactante y original, solo requirió una clave transformada, mientras que fue necesario renderizar 50 imágenes de Stable Diffusion para crear los pantalones caminando, que exhiben más inconsistencia temporal. El usuario también señaló que tomó cinco intentos lograr la coherencia para cada una de las 50 claves.
Por lo tanto, sería un gran beneficio para una aplicación de Stable Diffusion verdaderamente integral proporcionar funcionalidad que preserve las características al máximo a lo largo de las claves.
Una posibilidad es que la aplicación permita al usuario ‘congelar’ la codificación estocástica para la transformación en cada cuadro, lo que actualmente solo se puede lograr modificando el código fuente manualmente. Como muestra el ejemplo a continuación, esto ayuda a la coherencia temporal, aunque ciertamente no la resuelve:

Un usuario de Reddit se transformó en diferentes personas famosas al no solo persistir la semilla (que cualquier implementación de Stable Diffusion puede hacer), sino al asegurarse de que el parámetro stochastic_encode() fuera idéntico en cada transformación. Esto se logró modificando el código, pero podría convertirse fácilmente en un interruptor accesible para el usuario. Claramente, sin embargo, no resuelve todos los problemas temporales. Fuente: https://old.reddit.com/r/StableDiffusion/comments/wyeoqq/turning_img2img_into_vid2vid/
Inversión textual en la nube
Una mejor solución para obtener personajes y objetos temporalmente coherentes es “hornear”los en una Inversión textual – un archivo de 5KB que se puede entrenar en unas pocas horas basándose en solo cinco imágenes anotadas, que luego se pueden invocar mediante un texto especial ‘*’, lo que permite, por ejemplo, una apariencia persistente de personajes nuevos para incluir en una narrativa.

Las imágenes asociadas con etiquetas apropiadas se pueden convertir en entidades discretas a través de la Inversión textual, y se pueden invocar sin ambigüedad, y en el contexto y estilo correctos, mediante palabras especiales de token. Fuente: https://huggingface.co/docs/diffusers/training/text_inversion
Las Inversiones textuales son archivos adjuntos al modelo grande y completamente entrenado que utiliza Stable Diffusion, y se “deslizan” en el proceso de invocación/prompt, para que puedan participar en escenas derivadas del modelo, y beneficiarse del enorme banco de datos de conocimiento del modelo sobre objetos, estilos, entornos e interacciones.
Sin embargo, aunque una Inversión textual no lleva mucho tiempo en entrenarse, requiere una gran cantidad de VRAM; según varios tutoriales actuales, en algún lugar entre 12, 20 y hasta 40GB.
Dado que la mayoría de los usuarios casuales es poco probable que tengan ese tipo de potencia de GPU a su disposición, ya están surgiendo servicios en la nube que manejarán la operación, incluida una versión de Hugging Face. Aunque hay implementaciones de Google Colab que pueden crear inversiones textuales para Stable Diffusion, los requisitos de VRAM y tiempo pueden hacer que esto sea un desafío para los usuarios de Colab de nivel gratuito.
Para una aplicación de Stable Diffusion potencialmente completa e instalada, pasar esta tarea pesada a los servidores en la nube de la empresa parece una estrategia de monetización obvia (suponiendo que una aplicación de Stable Diffusion de bajo costo o sin costo esté permeada por dicha funcionalidad no gratuita, lo que parece probable en muchas aplicaciones posibles que surgirán de esta tecnología en los próximos 6-9 meses).
Además, el proceso bastante complicado de anotar y dar formato a las imágenes y texto presentadas podría beneficiarse de la automatización en un entorno integrado. El potencial “factor adictivo” de crear elementos únicos que pueden explorar y interactuar con los vastos mundos de Stable Diffusion parecería potencialmente compulsivo, tanto para entusiastas generales como para usuarios más jóvenes.
Ponderación de texto versátil
Hay muchas implementaciones actuales que permiten al usuario asignar un énfasis mayor a una sección de un texto largo, pero el instrumentalidad varía bastante entre estas, y es frecuentemente torpe o poco intuitiva.
La bifurcación de Stable Diffusion muy popular por AUTOMATIC1111, por ejemplo, puede disminuir o aumentar el valor de una palabra de texto al encerrarla en corchetes simples o múltiples (para desenfatizar) o corchetes cuadrados para enfatizar.

Los corchetes cuadrados y/o los paréntesis pueden transformar su desayuno en esta versión de los pesos de texto de Stable Diffusion, pero es una pesadilla del colesterol de todos modos.
Otras iteraciones de Stable Diffusion utilizan signos de exclamación para enfatizar, mientras que las más versátiles permiten a los usuarios asignar pesos a cada palabra en el texto a través de la GUI.
El sistema también debería permitir pesos de texto negativos – no solo para fanáticos del horror, sino porque puede haber misterios menos alarmantes y más edificantes en el espacio latente de Stable Diffusion que nuestro uso limitado del lenguaje puede invocar.
Pintura exterior
Poco después de la espectacular apertura del código de Stable Diffusion, OpenAI intentó – en gran medida en vano – recuperar algo de su trueno de DALL-E 2 anunciando ‘pintura exterior’, que permite a un usuario extender una imagen más allá de sus límites con lógica semántica y coherencia visual.
Naturalmente, esto ya se ha implementado en varias formas para Stable Diffusion, así como en Krita, y debería incluirse en una versión completa y estilo Photoshop de Stable Diffusion.
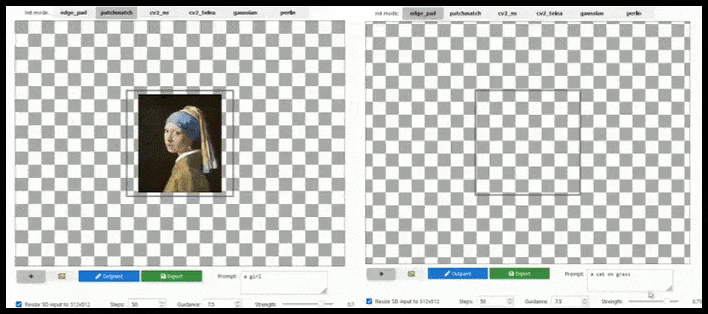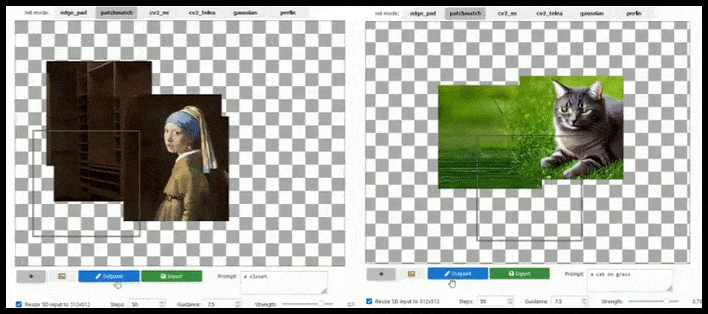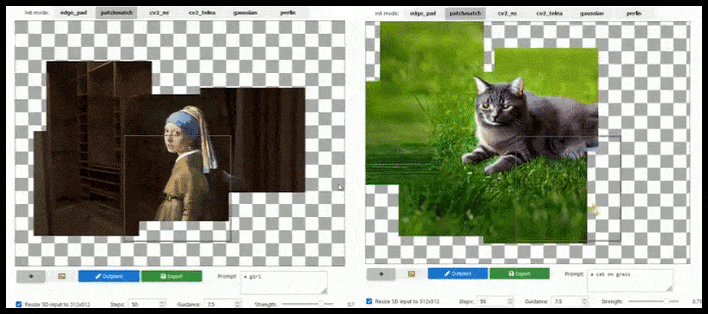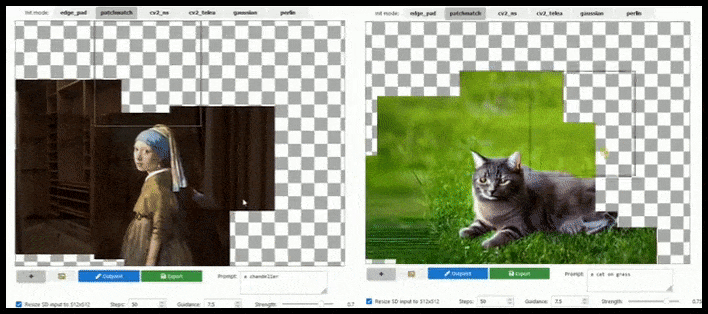
La ampliación basada en mosaicos puede extender un renderizado estándar de 512×512 casi infinitamente, siempre y cuando los textos, la imagen existente y la lógica semántica lo permitan. Fuente: https://github.com/lkwq007/stablediffusion-infinity
Dado que Stable Diffusion se entrena en imágenes de 512x512px (y por una variedad de otras razones), a menudo corta las cabezas (o otras partes esenciales del cuerpo) de los sujetos humanos, incluso cuando el texto claramente indicó ‘énfasis en la cabeza’, etc.

Ejemplos típicos de ‘decapitación’ de Stable Diffusion; pero la pintura exterior podría poner a George de vuelta en la imagen.
Cualquier implementación de pintura exterior del tipo ilustrado en la imagen animada de arriba (que se basa exclusivamente en bibliotecas de Unix, pero que debería ser capaz de replicarse en Windows) también debería estar herramientada como un remedio de un solo clic/prompt para este problema.
Actualmente, muchos usuarios extienden el lienzo de las representaciones ‘decapitadas’ hacia arriba, llenan aproximadamente el área de la cabeza y utilizan img2img para completar el renderizado defectuoso.
Enmascaramiento efectivo que comprende el contexto
El enmascaramiento puede ser un asunto terriblemente de golpe y error en Stable Diffusion, dependiendo de la bifurcación o versión en cuestión. Con frecuencia, donde es posible dibujar una máscara coherente en absoluto, el área especificada termina siendo repintada con contenido que no tiene en cuenta el contexto completo de la imagen.
En una ocasión, enmascaré los corneas de una imagen de una cara y proporcioné el texto ‘ojos azules’ como una máscara para repintar – solo para descubrir que parecía estar mirando a través de dos ojos humanos cortados a una imagen distante de un lobo inquietante. Supongo que tengo suerte de que no fuera Frank Sinatra.
La edición semántica también es posible identificando el ruido que construyó la imagen en primer lugar, lo que permite al usuario abordar elementos estructurales específicos en un renderizado sin interferir con el resto de la imagen:

Cambiar un elemento en una imagen sin enmascaramiento tradicional y sin alterar el contenido adyacente, identificando el ruido que originó la imagen y abordando las partes de él que contribuyeron al área objetivo. Fuente: https://old.reddit.com/r/StableDiffusion/comments/xboy90/a_better_way_of_doing_img2img_by_finding_the/
Este método se basa en el muestreador K-Diffusion.
Filtros semánticos para errores fisiológicos
Como mencionamos anteriormente, Stable Diffusion puede agregar o eliminar extremidades con frecuencia, en gran parte debido a problemas de datos y limitaciones en las anotaciones que acompañan las imágenes que lo entrenaron.

Al igual que el niño travieso que sacó la lengua en la foto de grupo de la escuela, los errores biológicos de Stable Diffusion no siempre son inmediatamente obvios, y es posible que hayas subido a Instagram tu última obra maestra de IA antes de darte cuenta de las manos extra o las extremidades derretidas.
Sería útil que una aplicación de Stable Diffusion completa contuviera algún tipo de sistema de reconocimiento anatómico que empleara la segmentación semántica para calcular si la imagen entrante presenta deficiencias anatómicas graves (como en la imagen de arriba), y la descarta a favor de un nuevo renderizado antes de presentarla al usuario.

Por supuesto, es posible que desees renderizar a la diosa Kali, o al Doctor Octopus, o incluso rescatar una parte no afectada de una imagen con extremidades afectadas, por lo que esta función debería ser un interruptor opcional.
Si los usuarios pueden tolerar el aspecto de telemetría, tales fallos incluso podrían transmitirse de forma anónima en un esfuerzo colectivo de aprendizaje federado que podría ayudar a que los modelos futuros mejoren su comprensión de la lógica anatómica.
Mejora automática de caras basada en LAION
Como mencioné en mi anterior mirada a tres cosas que Stable Diffusion podría abordar en el futuro, no debería dejarse únicamente a ninguna versión de GFPGAN intentar “mejorar” las caras renderizadas en los renderizados iniciales.
Las “mejoras” de GFPGAN son terriblemente genéricas, frecuentemente socavan la identidad del individuo representado, y operan únicamente en una cara que ha recibido no más tiempo de procesamiento o atención que cualquier otra parte de la imagen.
Por lo tanto, un programa profesional para Stable Diffusion debería ser capaz de reconocer una cara (con una biblioteca estándar y relativamente ligera como YOLO), aplicar el peso completo de la potencia de GPU disponible para volver a renderizarla, y ya sea fusionar la cara mejorada en el renderizado original de contexto completo, o guardarla por separado para una recomposición manual. Actualmente, esto es una operación bastante “manual”.
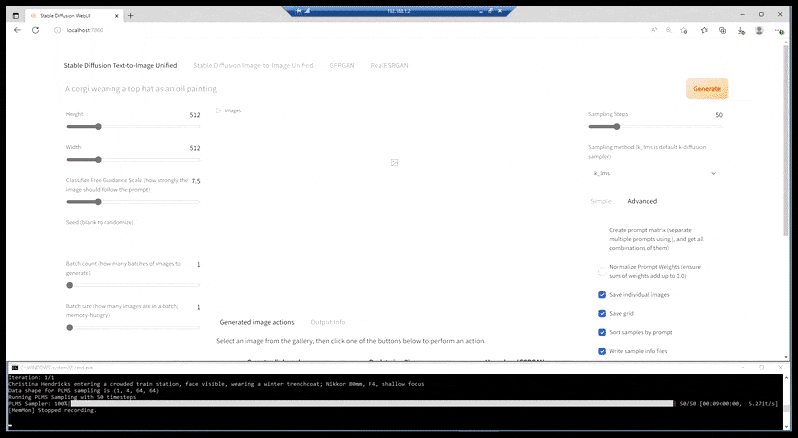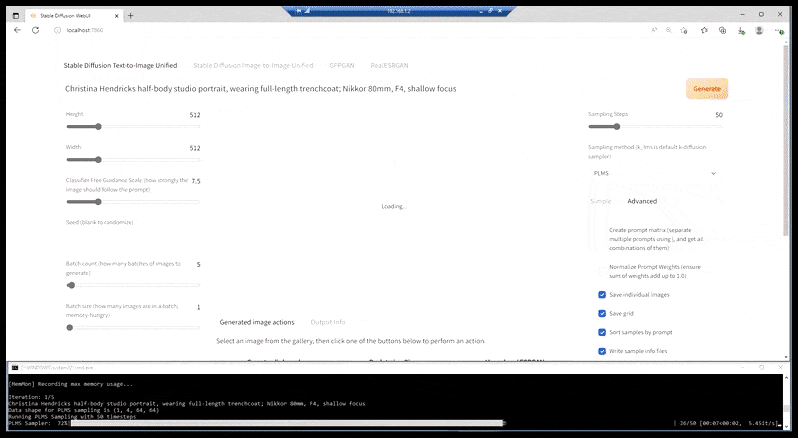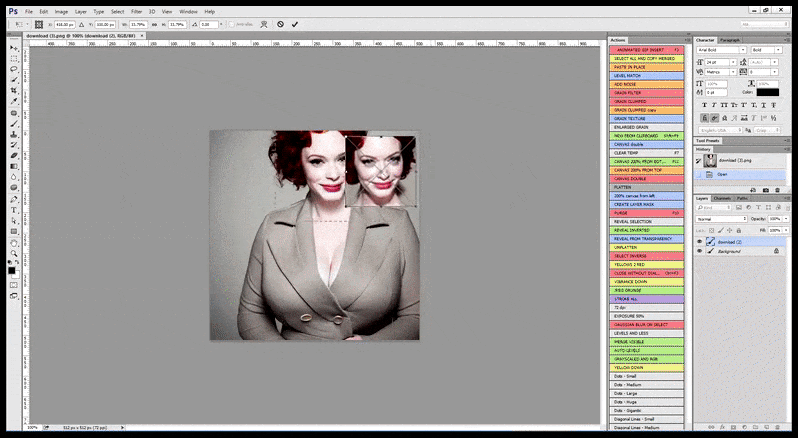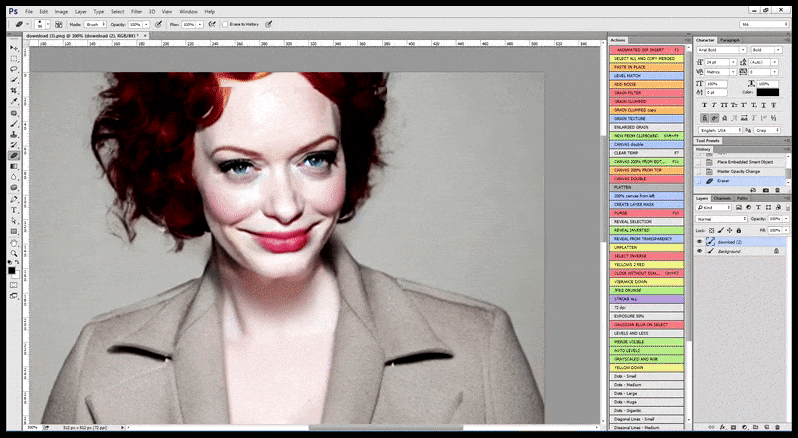
En casos donde Stable Diffusion se ha entrenado en un número adecuado de imágenes de una celebridad, es posible centrar la capacidad completa de la GPU en un renderizado posterior solo de la cara de la imagen renderizada, lo cual es generalmente una mejora notable – y, a diferencia de GFPGAN, se basa en información de los datos entrenados de LAION, en lugar de simplemente ajustar los píxeles renderizados.
Búsqueda en LAION dentro de la aplicación
Desde que los usuarios comenzaron a darse cuenta de que buscar en la base de datos de LAION para conceptos, personas y temas podría ser una ayuda para un mejor uso de Stable Diffusion, se han creado varios exploradores de LAION en línea, incluido haveibeentrained.com.

La función de búsqueda en haveibeentrained.com permite a los usuarios explorar las imágenes que alimentan a Stable Diffusion, y descubrir si los objetos, personas o ideas que podrían gustarles invocar en el sistema probablemente se hayan entrenado en él. Tales sistemas también son útiles para descubrir entidades adyacentes, como la forma en que se agrupan las celebridades, o la ‘próxima idea’ que conduce a la actual. Fuente: https://haveibeentrained.com/?search_text=bowl%20of%20fruit
Aunque tales bases de datos web a menudo revelan algunas de las etiquetas que acompañan a las imágenes, el proceso de generalización que tiene lugar durante el entrenamiento del modelo significa que es poco probable que una imagen particular pueda ser invocada mediante el uso de su etiqueta como un texto.
Además, la eliminación de ‘palabras de parada’ y la práctica de stemming y lemmatization en Procesamiento de Lenguaje Natural significa que muchas de las frases en pantalla se dividieron o se omitieron antes de ser entrenadas en Stable Diffusion.
Sin embargo, la forma en que los grupos estéticos se unen en estas interfaces puede enseñar al usuario final mucho sobre la lógica (o, posiblemente, la ‘personalidad’) de Stable Diffusion, y puede ser una ayuda para una mejor producción de imágenes.
Conclusión
Hay muchas otras características que me gustaría ver en una implementación de escritorio nativa de Stable Diffusion, como el análisis de imágenes basado en CLIP nativo, que invierte el proceso estándar de Stable Diffusion y permite al usuario invocar frases y palabras que el sistema naturalmente asociaría con la imagen de origen, o el renderizado.
Además, la escalabilidad basada en mosaicos real sería una adición bienvenida, ya que ESRGAN es casi tan brusco como GFPGAN. Afortunadamente, los planes para integrar la implementación de txt2imghd de GOBIG están haciendo que esto sea una realidad en las distribuciones, y parece una elección obvia para una iteración de escritorio.
Algunas otras solicitudes populares de las comunidades de Discord me interesan menos, como diccionarios de texto integrados y listas de artistas y estilos aplicables, aunque un cuaderno en la aplicación o un léxico personalizable de frases parecería una adición lógica.
Asimismo, las limitaciones actuales de la animación humana en Stable Diffusion, aunque iniciadas por CogVideo y varios otros proyectos, siguen siendo increíblemente incipientes, y a merced de la investigación upstream en primores temporales relacionados con el movimiento humano auténtico.
Por ahora, el video de Stable Diffusion es estrictamente psicodélico, aunque puede tener un futuro más brillante en la marioneta de deepfakes, a través de EbSynth y otras iniciativas de texto a video relativamente incipientes (y vale la pena señalarizar la falta de personas sintetizadas o ‘alteradas’ en el video promocional más reciente de Runway).
Otra funcionalidad valiosa sería el pase transparente de Photoshop, establecido desde hace tiempo en el editor de texturas de Cinema4D, entre otras implementaciones similares. Con esto, uno puede pasar imágenes fácilmente entre aplicaciones y usar cada aplicación para realizar las transformaciones que excelan.
Finalmente, y quizás lo más importante, un programa de escritorio de Stable Diffusion completo debería poder no solo cambiar fácilmente entre puntos de control (es decir, versiones del modelo subyacente que impulsa el sistema), sino también actualizar Inversiones textuales personalizadas que funcionaron con versiones anteriores del modelo oficial, pero que de otro modo podrían estar rotas por versiones posteriores del modelo (como han indicado los desarrolladores en el Discord oficial).
Irónicamente, la organización en la mejor posición para crear una matriz de herramientas tan poderosa e integrada para Stable Diffusion, Adobe, se ha aliado tan fuertemente con la Iniciativa de autenticidad de contenido que podría parecer un paso de relaciones públicas en retroceso – a menos que estuviera dispuesta a limitar las capacidades generativas de Stable Diffusion tan a fondo como OpenAI ha hecho con DALL-E 2, y a posicionarlo en su lugar como una evolución natural de sus considerables participaciones en fotografía de stock.
Publicado por primera vez el 15 de septiembre de 2022.












