Inteligencia Artificial
Optimización de preferencias directas: una guía completa

Alinear los grandes modelos lingüísticos (LLM) con los valores y preferencias humanos es un desafío. Los métodos tradicionales, como Aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF), han allanado el camino mediante la integración de aportaciones humanas para perfeccionar los resultados del modelo. Sin embargo, RLHF puede ser complejo y consumir muchos recursos, lo que requiere una potencia computacional y un procesamiento de datos sustanciales. Optimización de preferencias directas La optimización de datos (DPO) surge como un enfoque novedoso y más ágil, que ofrece una alternativa eficiente a estos métodos tradicionales. Al simplificar el proceso de optimización, la DPO no solo reduce la carga computacional, sino que también mejora la capacidad del modelo para adaptarse rápidamente a las preferencias humanas.
En esta guía profundizaremos en el DPO, explorando sus fundamentos, implementación y aplicaciones prácticas.
La necesidad de alinear las preferencias
Para comprender la DPO, es crucial comprender por qué es tan importante alinear los LLM con las preferencias humanas. A pesar de sus impresionantes capacidades, los LLM entrenados con grandes conjuntos de datos a veces pueden producir resultados inconsistentes, sesgados o desalineados con los valores humanos. Esta desalineación puede manifestarse de diversas maneras:
- Generar contenido inseguro o dañino
- Proporcionar información inexacta o engañosa.
- Exhibir sesgos presentes en los datos de entrenamiento.
Para abordar estos problemas, los investigadores han desarrollado técnicas para perfeccionar los LLM utilizando la retroalimentación humana. El más destacado de estos enfoques ha sido el RLHF.
Comprensión del RLHF: el precursor del DPO
El aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF) ha sido el método predilecto para alinear los LLM con las preferencias humanas. Analicemos el proceso de RLHF para comprender sus complejidades:
a) Ajuste Supervisado (SFT): El proceso comienza ajustando un LLM previamente capacitado en un conjunto de datos de respuestas de alta calidad. Este paso ayuda al modelo a generar resultados más relevantes y coherentes para la tarea objetivo.
b) Modelado de recompensas: Se entrena un modelo de recompensa independiente para predecir las preferencias humanas. Esto implica:
- Generar pares de respuestas para indicaciones dadas
- Hacer que los humanos califiquen qué respuesta prefieren
- Entrenando un modelo para predecir estas preferencias.
c) Aprendizaje reforzado: El LLM ajustado se optimiza aún más mediante el aprendizaje por refuerzo. El modelo de recompensa proporciona retroalimentación, guiando al LLM a generar respuestas que se alineen con las preferencias humanas.
Aquí hay un pseudocódigo de Python simplificado para ilustrar el proceso RLHF:
Si bien es eficaz, RLHF tiene varios inconvenientes:
- Requiere entrenar y mantener múltiples modelos (SFT, modelo de recompensa y modelo optimizado para RL)
- El proceso de RL puede ser inestable y sensible a hiperparámetros
- Es computacionalmente costoso y requiere muchos pasos hacia adelante y hacia atrás a través de los modelos.
Estas limitaciones han motivado la búsqueda de alternativas más sencillas y eficientes, dando lugar al desarrollo del DPO.
Optimización de preferencias directas: conceptos básicos

Optimización de preferencias directas https://arxiv.org/abs/2305.18290
Esta imagen contrasta dos enfoques distintos para alinear los resultados del LLM con las preferencias humanas: el Aprendizaje por Refuerzo a partir de la Retroalimentación Humana (RLHF) y la Optimización Directa de Preferencias (DPO). El RLHF se basa en un modelo de recompensa para guiar la política del modelo de lenguaje mediante ciclos de retroalimentación iterativos, mientras que la DPO optimiza directamente los resultados del modelo para que coincidan con las respuestas preferidas por los humanos utilizando datos de preferencias. Esta comparación destaca las fortalezas y las posibles aplicaciones de cada método, ofreciendo información sobre cómo se podrían entrenar futuros LLM para alinearse mejor con las expectativas humanas.
Ideas clave detrás del DPO:
a) Modelado de recompensa implícita: DPO elimina la necesidad de un modelo de recompensa separado al tratar el modelo de lenguaje en sí como una función de recompensa implícita.
b) Formulación basada en políticas: En lugar de optimizar una función de recompensa, DPO optimiza directamente la política (modelo de lenguaje) para maximizar la probabilidad de respuestas preferidas.
c) Solución de formato cerrado: DPO aprovecha una visión matemática que permite una solución de formato cerrado para la política óptima, evitando la necesidad de actualizaciones iterativas de RL.
Implementación de DPO: un tutorial práctico sobre el código
La siguiente imagen muestra un fragmento de código que implementa la función de pérdida de DPO con PyTorch. Esta función desempeña un papel crucial en el perfeccionamiento de la forma en que los modelos de lenguaje priorizan los resultados según las preferencias humanas. A continuación, se detallan los componentes clave:
- Firma de función: Los
dpo_lossLa función toma varios parámetros, incluidas las probabilidades de registro de políticas (pi_logps), probabilidades logarítmicas del modelo de referencia (ref_logps), e índices que representan terminaciones preferidas y no preferidas (yw_idxs,yl_idxs). Además, unbetaEl parámetro controla la fuerza de la penalización KL. - Extracción de probabilidad de registro: El código extrae las probabilidades de registro de finalizaciones preferidas y no preferidas tanto de la política como de los modelos de referencia.
- Cálculo de la relación logarítmica: La diferencia entre las probabilidades logarítmicas de terminaciones preferidas y no preferidas se calcula tanto para el modelo de política como para el de referencia. Esta relación es crítica para determinar la dirección y magnitud de la optimización.
- Cálculo de pérdidas y recompensas: La pérdida se calcula utilizando el
logsigmoidfunción, mientras que las recompensas se determinan escalando la diferencia entre las probabilidades de la política y del registro de referencia porbeta.

Función de pérdida de DPO usando PyTorch
Profundicemos en las matemáticas detrás del DPO para entender cómo logra estos objetivos.
Las matemáticas de DPO
DPO es una reformulación inteligente del problema de aprendizaje de preferencias. A continuación, se detalla paso a paso:
a) Punto de partida: Maximización de recompensas restringida por KL
El objetivo original del RLHF se puede expresar como:
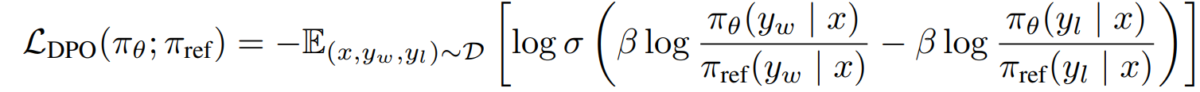
- πθ es la política (modelo de lenguaje) que estamos optimizando
- r(x,y) es la función de recompensa
- πref es una política de referencia (normalmente el modelo SFT inicial)
- β controla la fuerza de la restricción de divergencia de KL
b) Formulario de póliza óptima: Se puede demostrar que la política óptima para este objetivo toma la forma:
π_r(y|x) = 1/Z(x) * πref(y|x) * exp(1/β * r(x,y))Donde Z(x) es una constante de normalización.
c) Dualidad política-recompensa: La idea clave del DPO es expresar la función de recompensa en términos de la política óptima:
r(x,y) = β * log(π_r(y|x) / πref(y|x)) + β * log(Z(x))d) Modelo de preferencia Suponiendo que las preferencias siguen el modelo de Bradley-Terry, podemos expresar la probabilidad de preferir y1 sobre y2 como:
p*(y1 ≻ y2 | x) = σ(r*(x,y1) - r*(x,y2))Donde σ es la función logística.
e) Objetivo del DPO Sustituyendo nuestra dualidad política de recompensa en el modelo de preferencia, llegamos al objetivo del DPO:
L_DPO(πθ; πref) = -E_(x,y_w,y_l)~D [log σ(β * log(πθ(y_w|x) / πref(y_w|x)) - β * log(πθ(y_l|x) / πref(y_l|x)))]Este objetivo se puede optimizar utilizando técnicas estándar de descenso de gradiente, sin necesidad de algoritmos RL.
Implementación de DPO
Ahora que entendemos la teoría detrás de la OPD, veamos cómo implementarla en la práctica. Usaremos... Python y PyTorch para este ejemplo:
import torch
import torch.nn.functional as F
class DPOTrainer:
def __init__(self, model, ref_model, beta=0.1, lr=1e-5):
self.model = model
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
"""
pi_logps: policy logprobs, shape (B,)
ref_logps: reference model logprobs, shape (B,)
yw_idxs: preferred completion indices in [0, B-1], shape (T,)
yl_idxs: dispreferred completion indices in [0, B-1], shape (T,)
beta: temperature controlling strength of KL penalty
Each pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single preference pair.
"""
# Extract log probabilities for the preferred and dispreferred completions
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
# Calculate log-ratios
pi_logratios = pi_yw_logps - pi_yl_logps
ref_logratios = ref_yw_logps - ref_yl_logps
# Compute DPO loss
losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios))
rewards = self.beta * (pi_logps - ref_logps).detach()
return losses.mean(), rewards
def train_step(self, batch):
x, yw_idxs, yl_idxs = batch
self.optimizer.zero_grad()
# Compute log probabilities for the model and the reference model
pi_logps = self.model(x).log_softmax(-1)
ref_logps = self.ref_model(x).log_softmax(-1)
# Compute the loss
loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
loss.backward()
self.optimizer.step()
return loss.item()
# Usage
model = YourLanguageModel() # Initialize your model
ref_model = YourLanguageModel() # Load pre-trained reference model
trainer = DPOTrainer(model, ref_model)
for batch in dataloader:
loss = trainer.train_step(batch)
print(f"Loss: {loss}")
Desafíos y direcciones futuras
Si bien el DPO ofrece ventajas significativas sobre los enfoques tradicionales de RLHF, todavía existen desafíos y áreas para futuras investigaciones:
a) Escalabilidad a modelos más grandes:
A medida que los modelos de lenguaje continúan creciendo en tamaño, aplicar DPO de manera eficiente a modelos con cientos de miles de millones de parámetros sigue siendo un desafío abierto. Los investigadores están explorando técnicas como:
- Métodos eficientes de ajuste fino (p. ej., LoRA, ajuste de prefijo)
- Optimizaciones de entrenamiento distribuido
- Puntos de control de gradiente y entrenamiento de precisión mixta
Ejemplo de uso de LoRA con DPO:
from peft import LoraConfig, get_peft_model
class DPOTrainerWithLoRA(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
self.model = get_peft_model(model, lora_config)
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
# Usage
base_model = YourLargeLanguageModel()
dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
b) Adaptación multitarea y de pocos disparos:
El desarrollo de técnicas de DPO que puedan adaptarse eficientemente a nuevas tareas o dominios con datos de preferencia limitados es un área activa de investigación. Los enfoques que se están explorando incluyen:
- Marcos de metaaprendizaje para una rápida adaptación
- Ajuste fino basado en indicaciones para DPO
- Transferir el aprendizaje de modelos de preferencias generales a dominios específicos
c) Manejo de preferencias ambiguas o conflictivas:
Los datos de preferencias del mundo real suelen contener ambigüedades o conflictos. Mejorar la robustez de la OPD ante estos datos es crucial. Entre las posibles soluciones se incluyen:
- Modelado de preferencias probabilísticas
- Aprendizaje activo para resolver ambigüedades.
- Agregación de preferencias de múltiples agentes
Ejemplo de modelado de preferencias probabilísticas:
class ProbabilisticDPOTrainer(DPOTrainer):
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob):
# Compute log ratios
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1)
loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) +
(1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff))
return loss.mean()
# Usage
trainer = ProbabilisticDPOTrainer(model, ref_model)
loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% confidence in preference
d) Combinación de DPO con otras técnicas de alineación:
La integración de DPO con otros enfoques de alineación podría conducir a sistemas más sólidos y capaces:
- Principios constitucionales de IA para la satisfacción de restricciones explícitas
- Debate y modelado de recompensa recursivo para la obtención de preferencias complejas
- Aprendizaje por refuerzo inverso para inferir funciones de recompensa subyacentes
Ejemplo de combinación de DPO con IA constitucional:
class ConstitutionalDPOTrainer(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None):
super().__init__(model, ref_model, beta, lr)
self.constraints = constraints or []
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
constraint_loss = 0
for constraint in self.constraints:
constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs)
return base_loss + constraint_loss
# Usage
def safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs):
# Implement safety checking logic
unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps)
return torch.relu(unsafe_score - 0.5) # Penalize if unsafe score > 0.5
constraints = [safety_constraint]
trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)
Consideraciones prácticas y mejores prácticas
Al implementar DPO para aplicaciones del mundo real, considere los siguientes consejos:
a) Calidad de los Datos: La calidad de los datos de sus preferencias es crucial. Asegúrese de que su conjunto de datos:
- Cubre una amplia gama de entradas y comportamientos deseados.
- Tiene anotaciones de preferencias consistentes y confiables.
- Equilibra diferentes tipos de preferencias (p. ej., factibilidad, seguridad, estilo)
b) Ajuste de hiperparámetros: Si bien DPO tiene menos hiperparámetros que RLHF, el ajuste sigue siendo importante:
- β (beta): controla el equilibrio entre satisfacción de preferencias y divergencia con respecto al modelo de referencia. Comience con valores alrededor 0.1 - 0.5.
- Tasa de aprendizaje: utilice una tasa de aprendizaje más baja que el ajuste fino estándar, generalmente en el rango de 1e-6 a 1e-5.
- Tamaño de lote: tamaños de lote más grandes (32 - 128) a menudo funcionan bien para el aprendizaje de preferencias.
c) Refinamiento iterativo: DPO se puede aplicar de forma iterativa:
- Entrene un modelo inicial usando DPO
- Genere nuevas respuestas utilizando el modelo entrenado.
- Recopilar nuevos datos de preferencia sobre estas respuestas.
- Volver a entrenar utilizando el conjunto de datos ampliado

Rendimiento de optimización de preferencias directas
Esta imagen muestra el rendimiento de LLM como GPT-4 en comparación con las evaluaciones humanas mediante diversas técnicas de entrenamiento, como la Optimización de Preferencias Directas (DPO), el Ajuste Fino Supervisado (SFT) y la Optimización de Políticas Proximales (PPO). La tabla revela que los resultados de GPT-4 se ajustan cada vez más a las preferencias humanas, especialmente en tareas de resumen. El nivel de concordancia entre GPT-4 y los revisores humanos demuestra la capacidad del modelo para generar contenido que conecta con los evaluadores humanos, casi con la misma fidelidad que el contenido generado por ellos.
Estudios de casos y aplicaciones
Para ilustrar la eficacia del DPO, veamos algunas aplicaciones del mundo real y algunas de sus variantes:
- DPO iterativo: Desarrollada por Snorkel (2023), esta variante combina el muestreo de rechazo con DPO, lo que permite un proceso de selección más refinado para los datos de entrenamiento. Al iterar sobre múltiples rondas de muestreo de preferencias, el modelo puede generalizar mejor y evitar el sobreajuste a preferencias ruidosas o sesgadas.
- OPI (Optimización iterativa de preferencias): Introducido por Azar et al. (2023), IPO agrega un término de regularización para evitar el sobreajuste, que es un problema común en la optimización basada en preferencias. Esta extensión permite que los modelos mantengan un equilibrio entre adherirse a las preferencias y preservar las capacidades de generalización.
- KTO (Optimización de la transferencia de conocimientos): Una variante más reciente de Ethayarajh et al. (2023), la KTO prescinde por completo de las preferencias binarias. En cambio, se centra en transferir conocimiento de un modelo de referencia al modelo de políticas, optimizándolo para lograr una alineación más fluida y consistente con los valores humanos.
- DPO multimodal para el aprendizaje entre dominios por Xu et al. (2024): Un enfoque en el que DPO se aplica en diferentes modalidades (texto, imagen y audio), lo que demuestra su versatilidad a la hora de alinear modelos con las preferencias humanas en diversos tipos de datos. Esta investigación destaca el potencial de DPO en la creación de sistemas de IA más completos capaces de manejar tareas complejas y multimodales.












