Inteligencia artificial
AudioSep: Separa cualquier cosa que describas
LASS o Separación de fuentes de audio consultadas por lenguaje es el nuevo paradigma para CASA o Análisis de escena auditiva computacional que tiene como objetivo separar un sonido objetivo de una mezcla de audio determinada utilizando una consulta de lenguaje natural que proporciona una interfaz escalable y natural para tareas y aplicaciones de audio digital. Aunque los marcos de LASS han avanzado significativamente en los últimos años en términos de lograr el rendimiento deseado en fuentes de audio específicas como instrumentos musicales, no pueden separar el audio objetivo en el dominio abierto.
AudioSep, es un modelo fundamental que tiene como objetivo resolver las limitaciones actuales de los marcos de LASS al permitir la separación de audio objetivo utilizando consultas de lenguaje natural. Los desarrolladores del marco de AudioSep han entrenado el modelo extensivamente en una amplia variedad de conjuntos de datos multimodales a gran escala, y han evaluado el rendimiento del marco en una amplia variedad de tareas de audio, incluida la separación de instrumentos musicales, la separación de eventos de audio y el mejoramiento del habla entre muchos otros. El rendimiento inicial de AudioSep satisface los benchmarks, ya que demuestra impresionantes capacidades de aprendizaje zero-shot y entrega un fuerte rendimiento de separación de audio.
En este artículo, profundizaremos en el funcionamiento del marco de AudioSep, evaluaremos la arquitectura del modelo, los conjuntos de datos utilizados para el entrenamiento y la evaluación, y los conceptos esenciales involucrados en el funcionamiento del modelo de AudioSep. Así que comencemos con una introducción básica al marco de CASA.
CASA, USS, QSS, LASS: La base para AudioSep
El marco de CASA o Análisis de escena auditiva computacional es un marco utilizado por los desarrolladores para diseñar sistemas de escucha de máquina que tienen la capacidad de percibir entornos de sonido complejos de una manera similar a como los humanos perciben el sonido utilizando sus sistemas auditivos. La separación de sonido, con un enfoque especial en la separación de sonido objetivo, es un área fundamental de investigación dentro del marco de CASA, y tiene como objetivo resolver el “problema de la fiesta” o separar grabaciones de audio reales de grabaciones o archivos de fuentes de audio individuales. La importancia de la separación de sonido se puede atribuir principalmente a sus aplicaciones generalizadas, incluyendo la separación de fuentes de música, la separación de fuentes de audio, el mejoramiento del habla, la identificación de sonido objetivo y muchos más.
La mayoría del trabajo sobre separación de sonido realizado en el pasado se centra principalmente en la separación de una o más fuentes de audio, como la separación de música o la separación de habla. Un nuevo modelo llamado USS o Separación universal de sonido tiene como objetivo separar sonidos arbitrarios en grabaciones de audio reales. Sin embargo, es una tarea desafiante y restrictiva separar todas las fuentes de sonido de una mezcla de audio, principalmente debido a la amplia variedad de fuentes de sonido diferentes que existen en el mundo, lo que es la razón principal por la que el método USS no es factible para aplicaciones en tiempo real.
Una alternativa factible al método USS es el método QSS o Separación de sonido basada en consultas, que tiene como objetivo separar una fuente de sonido individual o objetivo de la mezcla de audio en función de un conjunto determinado de consultas. Gracias a esto, el marco de QSS permite a los desarrolladores y usuarios extraer las fuentes de audio deseables de la mezcla en función de sus requisitos, lo que hace que el método QSS sea una solución más práctica para aplicaciones digitales en tiempo real, como la edición de contenido multimedia o la edición de audio.
Además, los desarrolladores han propuesto recientemente una extensión del marco de QSS, el marco de LASS o Separación de fuentes de audio consultadas por lenguaje, que tiene como objetivo separar fuentes de sonido arbitrarias de una mezcla de audio utilizando descripciones de lenguaje natural de la fuente de sonido objetivo. Como el marco de LASS permite a los usuarios extraer las fuentes de audio objetivo utilizando un conjunto de instrucciones de lenguaje natural, puede convertirse en una herramienta poderosa con aplicaciones generalizadas en aplicaciones de audio digital. En comparación con los métodos tradicionales de consulta de audio o visión, el uso de instrucciones de lenguaje natural para la separación de audio ofrece un mayor grado de ventaja, ya que agrega flexibilidad y facilita la adquisición de información de consulta. Además, en comparación con los marcos de separación de audio basados en etiquetas que utilizan un conjunto predefinido de instrucciones o consultas, el marco de LASS no limita el número de consultas de entrada y tiene la flexibilidad de generalizarse suavemente al dominio abierto.
Originalmente, el marco de LASS se basa en el aprendizaje supervisado, en el que el modelo se entrena en un conjunto de datos de audio-texto emparejados etiquetados. Sin embargo, el principal problema con este enfoque es la disponibilidad limitada de datos de audio-texto etiquetados y anotados. Para reducir la dependencia del marco de LASS en datos de audio-texto etiquetados, los modelos se entrenan utilizando el enfoque de aprendizaje de supervisión multimodal. El objetivo principal detrás del uso de un enfoque de supervisión multimodal es utilizar modelos de preentrenamiento contrastivo multimodal como el modelo CLIP o Contrastive Language Image Pre Training como codificador de consulta para el marco. Dado que el marco de CLIP tiene la capacidad de alinear incrustaciones de texto con otras modalidades como audio o visión, permite a los desarrolladores entrenar los modelos de LASS utilizando modalidades ricas en datos y permite la interferencia con los datos textuales en un entorno de zero-shot. Los marcos de LASS actuales, sin embargo, utilizan conjuntos de datos a pequeña escala para el entrenamiento, y las aplicaciones del marco de LASS en cientos de dominios potenciales aún no se han explorado.
Para resolver las limitaciones actuales que enfrentan los marcos de LASS, los desarrolladores han introducido AudioSep, un modelo fundamental que tiene como objetivo separar el sonido de una mezcla de audio utilizando descripciones de lenguaje natural. El enfoque actual de AudioSep es desarrollar un modelo de separación de sonido preentrenado que aproveche los conjuntos de datos multimodales a gran escala existentes para permitir la generalización de los modelos de LASS en aplicaciones de dominio abierto. En resumen, el modelo de AudioSep es: ” Un modelo fundamental para la separación universal de sonido en dominio abierto utilizando consultas o descripciones de lenguaje natural entrenadas en conjuntos de datos de audio y multimodales a gran escala“.
AudioSep: Componentes clave y arquitectura
La arquitectura del marco de AudioSep comprende dos componentes clave: un codificador de texto y un modelo de separación.
El codificador de texto
El marco de AudioSep utiliza un codificador de texto del modelo CLIP o Contrastive Language Image Pre Training o el modelo CLAP o Contrastive Language Audio Pre Training para extraer incrustaciones de texto dentro de una consulta de lenguaje natural. La consulta de texto de entrada consiste en una secuencia de ” N” tokens que se procesa mediante el codificador de texto para extraer las incrustaciones de texto para la consulta de lenguaje de entrada dada. El codificador de texto utiliza una pila de bloques de transformador para codificar los tokens de texto de entrada, y las representaciones de salida se agregan después de pasar por las capas de transformador que dan como resultado el desarrollo de una representación vectorial de longitud fija con dimensiones D, donde D corresponde a las dimensiones de los modelos CLAP o CLIP, mientras que el codificador de texto se congela durante el período de entrenamiento.
El modelo CLIP se preentrena en un conjunto de datos a gran escala de pares de datos de imagen y texto utilizando aprendizaje contrastivo, lo que es la razón principal por la que el codificador de texto del modelo CLIP aprende a mapear descripciones textuales en el espacio semántico que también es compartido por las representaciones visuales. La ventaja que AudioSep obtiene al utilizar el codificador de texto de CLIP es que ahora puede escalar o entrenar el modelo de LASS desde datos de audio-visión no etiquetados, utilizando las incrustaciones visuales como alternativa, lo que permite el entrenamiento de los modelos de LASS sin la necesidad de datos de audio-texto etiquetados y anotados.
El modelo CLAP funciona de manera similar al modelo CLIP y utiliza un objetivo de aprendizaje contrastivo, ya que utiliza un codificador de texto y un codificador de audio para conectar el audio y el lenguaje, lo que lleva a las descripciones de texto y audio a un espacio latente de audio-texto unido.
Modelo de separación
El marco de AudioSep utiliza un modelo ResUNet en el dominio de frecuencia que se alimenta de una mezcla de clips de audio como la columna vertebral de separación para el marco. El marco funciona aplicando primero una transformada de Fourier de tiempo corto (STFT) en la onda para extraer un espectrograma complejo, el espectrograma de magnitud y la fase de X. El modelo sigue entonces la misma configuración y construye una red de codificador-decodificador para procesar el espectrograma de magnitud.
La red de codificador-decodificador ResUNet consiste en 6 bloques de codificador, 6 bloques de decodificador y 4 bloques de cuello de botella. El espectrograma en cada bloque de codificador utiliza 4 bloques convolucionales residuales para muestrear el espectrograma en una característica de cuello de botella, mientras que los bloques de decodificador utilizan 4 bloques deconvolucionales residuales para obtener los componentes de separación al muestrear las características. A continuación, cada uno de los bloques de codificador y sus bloques de decodificador correspondientes establecen una conexión de salto que opera a la misma tasa de muestreo o submuestreo. El bloque residual del marco consiste en 2 capas de activación Leaky-ReLU, 2 capas de normalización de lote y 2 capas de convolución, y además, el marco introduce un atajo residual adicional que conecta la entrada y la salida de cada bloque residual individual. El modelo ResUNet toma el espectrograma complejo X como entrada y produce la máscara de magnitud M como salida, con el residual de fase condicionado en las incrustaciones de texto que controla la magnitud de escalado y la rotación del ángulo del espectrograma. El espectrograma complejo separado se puede extraer multiplicando la máscara de magnitud predicha y el residual de fase con la transformada de Fourier de tiempo corto (STFT) de la mezcla.

En su marco, AudioSep utiliza una capa FiLm o capa modulada linealmente por características para conectar el modelo de separación y el codificador de texto después de la implementación de los bloques convolucionales en el ResUNet.
Entrenamiento y pérdida
Durante el entrenamiento del modelo de AudioSep, los desarrolladores utilizan el método de aumento de sonoridad y entrenan el marco de AudioSep de extremo a extremo utilizando una función de pérdida L1 entre las formas de onda reales y predichas.
Conjuntos de datos y benchmarks
Como se mencionó en las secciones anteriores, AudioSep es un modelo fundamental que tiene como objetivo resolver la dependencia actual de los modelos de LASS en conjuntos de datos de audio-texto emparejados etiquetados. El modelo de AudioSep se entrena en una amplia variedad de conjuntos de datos para equiparlo con capacidades de aprendizaje multimodal, y aquí se proporciona una descripción detallada del conjunto de datos y los benchmarks utilizados por los desarrolladores para entrenar el marco de AudioSep.
AudioSet
AudioSet es un conjunto de datos de audio grande y etiquetado débilmente que comprende más de 2 millones de fragmentos de audio de 10 segundos extraídos directamente de YouTube. Cada fragmento de audio en el conjunto de datos de AudioSet se categoriza por la ausencia o presencia de clases de sonido sin detalles de temporización específicos de los eventos de sonido. El conjunto de datos de AudioSet tiene más de 500 clases de audio distintas, incluyendo sonidos naturales, sonidos humanos, sonidos de vehículos y muchos más.
VGGSound
El conjunto de datos de VGGSound es un conjunto de datos de audio-visión a gran escala que, al igual que AudioSet, se ha obtenido directamente de YouTube, y contiene más de 200.000 clips de video, cada uno de ellos con una duración de 10 segundos. El conjunto de datos de VGGSound se categoriza en más de 300 clases de sonido, incluyendo sonidos humanos, sonidos naturales, sonidos de pájaros y más. El uso del conjunto de datos de VGGSound garantiza que el objeto responsable de producir el sonido objetivo también sea describible en el clip de video correspondiente.
AudioCaps
AudioCaps es el conjunto de datos de subtítulos de audio más grande disponible públicamente, y comprende más de 50.000 fragmentos de audio de 10 segundos que se extraen del conjunto de datos de AudioSet. Los datos en AudioCaps se dividen en tres categorías: datos de entrenamiento, datos de prueba y datos de validación, y los fragmentos de audio están anotados con descripciones de lenguaje natural utilizando la plataforma Amazon Mechanical Turk. Es importante destacar que cada fragmento de audio en el conjunto de datos de entrenamiento tiene una sola leyenda, mientras que los datos de prueba y validación tienen 5 leyendas de verdad fundamentada.
ClothoV2
ClothoV2 es un conjunto de datos de subtítulos de audio que consiste en clips obtenidos de la plataforma FreeSound, y al igual que AudioCaps, cada fragmento de audio está anotado con descripciones de lenguaje natural utilizando la plataforma Amazon Mechanical Turk.
WavCaps
Al igual que AudioSet, WavCaps es un conjunto de datos de audio grande y etiquetado débilmente que comprende más de 400.000 fragmentos de audio con subtítulos, y un tiempo de ejecución total que se aproxima a 7568 horas de datos de entrenamiento. Los fragmentos de audio en el conjunto de datos de WavCaps se obtienen de una amplia variedad de fuentes de audio, incluyendo BBC Sound Effects, AudioSet, FreeSound, SoundBible y más.

Detalles de entrenamiento
Durante la fase de entrenamiento, el modelo de AudioSep muestrea aleatoriamente dos segmentos de audio de dos fragmentos de audio diferentes del conjunto de datos de entrenamiento, y luego los mezcla para crear una mezcla de entrenamiento donde la longitud de cada segmento de audio es de aproximadamente 5 segundos. El modelo extrae entonces el espectrograma complejo de la señal de onda utilizando una ventana de Hann de tamaño 1024 con un tamaño de salto de 320.
El modelo utiliza entonces el codificador de texto de los modelos CLIP/CLAP para extraer las incrustaciones de texto con supervisión de texto como configuración predeterminada para AudioSep. Para el modelo de separación, el marco de AudioSep utiliza una capa ResUNet que consta de 30 capas, 6 bloques de codificador y 6 bloques de decodificador que se asemejan a la arquitectura seguida en el marco de separación de sonido universal. Además, cada bloque de codificador tiene dos capas de convolución con un tamaño de kernel de 3×3, con el número de mapas de características de salida de los bloques de codificador siendo 32, 64, 128, 256, 512 y 1024, respectivamente. Los bloques de decodificador comparten simetría con los bloques de codificador, y los desarrolladores aplican el optimizador Adam para entrenar el modelo de AudioSep con un tamaño de lote de 96.
Resultados de evaluación
En conjuntos de datos vistos
La siguiente figura compara el rendimiento del marco de AudioSep en conjuntos de datos vistos durante la fase de entrenamiento, incluyendo los conjuntos de datos de entrenamiento. La figura siguiente representa los resultados de evaluación de los benchmarks del marco de AudioSep en comparación con los sistemas de referencia, incluyendo modelos de mejoramiento del habla, LASS y CLIP. El modelo de AudioSep con codificador de texto de CLIP se representa como AudioSep-CLIP, mientras que el modelo de AudioSep con codificador de texto de CLAP se representa como AudioSep-CLAP.

Como se puede ver en la figura, el marco de AudioSep funciona bien cuando se utilizan subtítulos de audio o etiquetas de texto como consultas de entrada, y los resultados indican el rendimiento superior del marco de AudioSep en comparación con los modelos de separación de sonido de LASS y audio-consultados actuales.
En conjuntos de datos no vistos
Para evaluar el rendimiento de AudioSep en un entorno de zero-shot, los desarrolladores continuaron evaluando el rendimiento en conjuntos de datos no vistos, y el marco de AudioSep entrega un rendimiento de separación impresionante en un entorno de zero-shot, y los resultados se muestran en la figura siguiente.

Además, la imagen siguiente muestra los resultados de la evaluación del modelo de AudioSep contra el mejoramiento del habla de Voicebank-Demand.

La evaluación del marco de AudioSep indica un rendimiento fuerte y deseado en conjuntos de datos no vistos en un entorno de zero-shot, lo que permite realizar tareas de operación de sonido en nuevas distribuciones de datos.
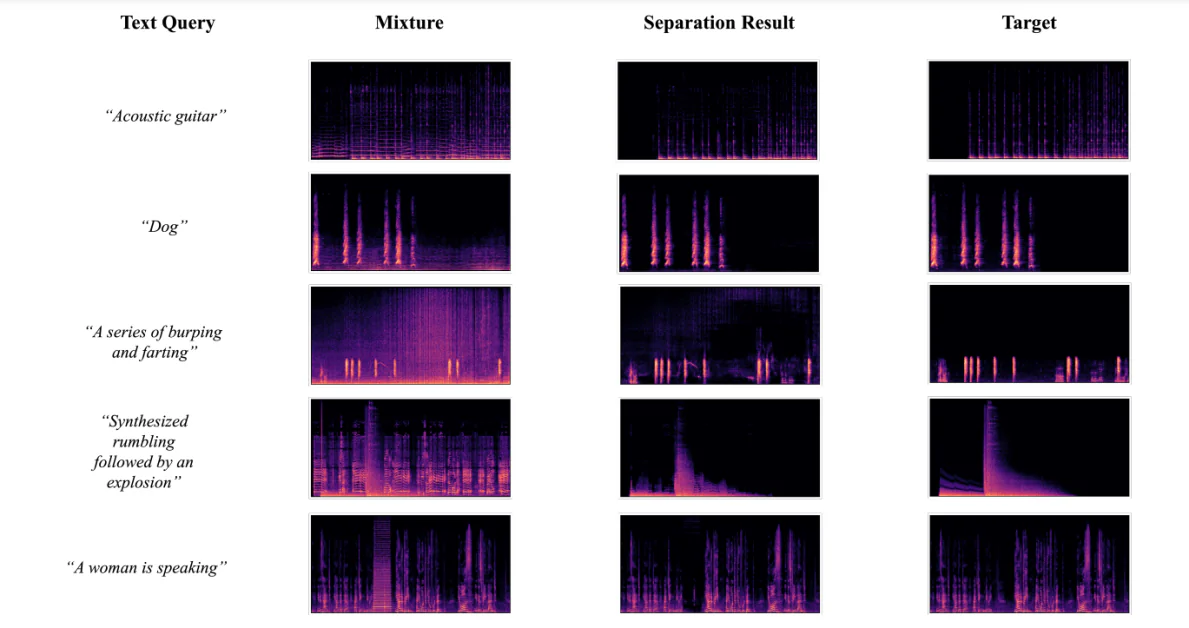
Visualización de resultados de separación
La figura siguiente muestra los resultados obtenidos cuando los desarrolladores utilizaron el marco de AudioSep-CLAP para realizar visualizaciones de espectrogramas para fuentes de audio objetivo reales, mezclas de audio y fuentes de audio separadas utilizando consultas de texto de audio diverso. Los resultados permitieron a los desarrolladores observar que el patrón de fuente separada del espectrograma está cerca de la fuente de la verdad fundamentada, lo que apoya aún más los resultados objetivos obtenidos durante los experimentos.
Comparación de consultas de texto
Los desarrolladores evalúan el rendimiento de AudioSep-CLAP y AudioSep-CLIP en AudioCaps Mini, y los desarrolladores utilizan las etiquetas de eventos de AudioSet, las leyendas de AudioCaps y las descripciones de lenguaje natural reanotadas para examinar los efectos de diferentes consultas, y la figura siguiente muestra un ejemplo de AudioCaps Mini en acción.

Conclusión
AudioSep es un modelo fundamental que se ha desarrollado con el objetivo de ser un marco de separación de sonido universal en dominio abierto que utiliza descripciones de lenguaje natural para la separación de audio. Como se observó durante la evaluación, el marco de AudioSep es capaz de realizar aprendizaje zero-shot y no supervisado de manera fluida al utilizar subtítulos de audio o etiquetas de texto como consultas de entrada, y los resultados indican un rendimiento superior que supera a los marcos de separación de sonido actuales como LASS, y puede ser capaz de resolver las limitaciones actuales de los marcos de separación de sonido populares.












