Inteligencia artificial
Edición de objetos asistida por IA con Imagic de Google y ‘Borrar y reemplazar’ de Runway

Esta semana, dos nuevos algoritmos gráficos impulsados por IA, aunque contrastantes, ofrecen formas novedosas para que los usuarios finales realicen cambios muy granulares y efectivos en objetos de las fotos.
El primero es Imagic, de Google Research, en asociación con el Instituto de Tecnología de Israel y el Instituto de Ciencia Weizmann. Imagic ofrece edición de objetos condicionada por texto, con edición fina mediante el ajuste fino de modelos de difusión.

Cambia lo que quieras, y deja el resto – Imagic promete edición granular de solo las partes que deseas cambiar. Fuente: https://arxiv.org/pdf/2210.09276.pdf
Cualquiera que haya intentado cambiar solo un elemento en una re-renderización de Stable Diffusion sabrá muy bien que, por cada edición exitosa, el sistema cambiará cinco cosas que te gustaban tal como estaban. Es una limitación que actualmente tiene a muchos de los entusiastas más talentosos de SD constantemente cambiando entre Stable Diffusion y Photoshop, para arreglar este tipo de ‘daño colateral’. Desde este punto de vista, los logros de Imagic parecen notables.
En el momento de escribir, Imagic carece incluso de un video promocional, y, dado la actitud circunspecta de Google hacia la liberación de herramientas de síntesis de imágenes sin restricciones, es incierto hasta qué punto, si es que lo hace, tendremos la oportunidad de probar el sistema.
La segunda oferta es la facilidad Borrar y reemplazar de Runway ML, una nueva característica en la sección ‘Herramientas mágicas de IA’ de su suite en línea exclusiva de utilidades de efectos visuales basados en aprendizaje automático.
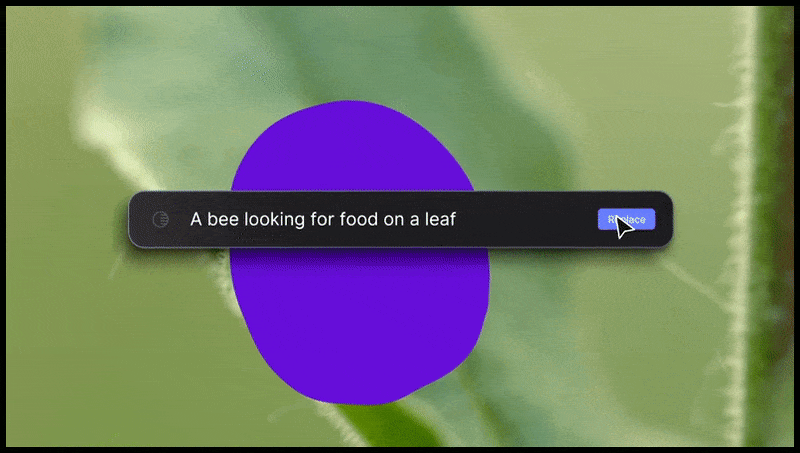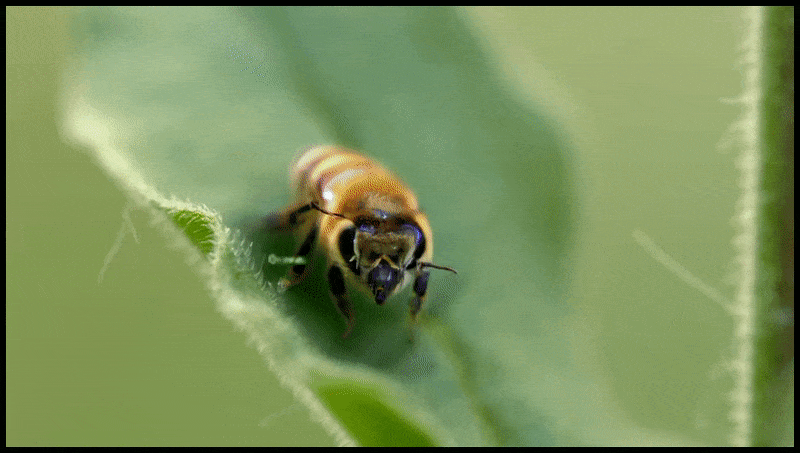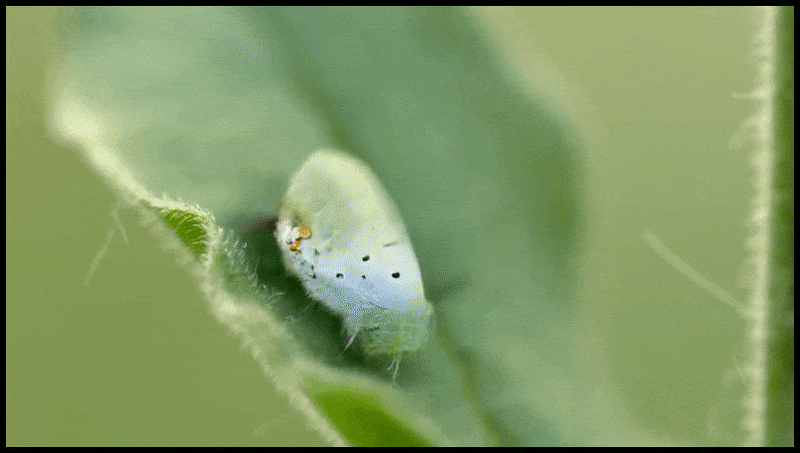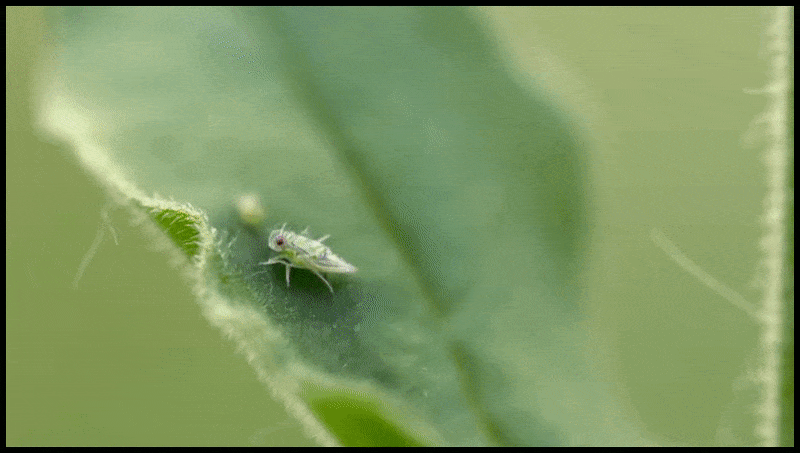
La característica Borrar y reemplazar de Runway ML, ya vista en una vista previa para un sistema de edición de video a texto. Fuente: https://www.youtube.com/watch?v=41Qb58ZPO60
Vamos a ver la salida de Runway primero.
Borrar y reemplazar
Al igual que Imagic, Borrar y reemplazar se ocupa exclusivamente de imágenes fijas, aunque Runway ha visto en una vista previa la misma funcionalidad en una solución de edición de video a texto que aún no se ha lanzado:

Aunque cualquiera puede probar la nueva característica Borrar y reemplazar en imágenes, la versión de video aún no está disponible públicamente. Fuente: https://twitter.com/runwayml/status/1568220303808991232
Aunque Runway ML no ha lanzado detalles de las tecnologías detrás de Borrar y reemplazar, la velocidad a la que puedes sustituir una planta de interior por un busto razonablemente convincente de Ronald Reagan sugiere que un modelo de difusión como Stable Diffusion (o, mucho menos probable, un DALL-E 2 con licencia) es el motor que está reinventando el objeto de tu elección en Borrar y reemplazar.

Reemplazar una planta de interior con un busto de The Gipper no es tan rápido como esto, pero es bastante rápido. Fuente: https://app.runwayml.com/
El sistema tiene algunas restricciones del tipo DALL-E 2: imágenes o texto que activan los filtros Borrar y reemplazar desencadenarán una advertencia sobre la posible suspensión de la cuenta en caso de más infracciones – prácticamente un clon de caldera de las políticas de OpenAI para DALL-E 2.
Muchos de los resultados carecen de los bordes rugosos típicos de Stable Diffusion. Runway ML son inversores y socios de investigación en SD, y es posible que hayan entrenado un modelo propietario que es superior a los pesos de punto de referencia de código abierto 1.4 que el resto de nosotros está luchando actualmente (como muchos otros grupos de desarrollo, aficionados y profesionales, están entrenando o ajustando modelos de Stable Diffusion).
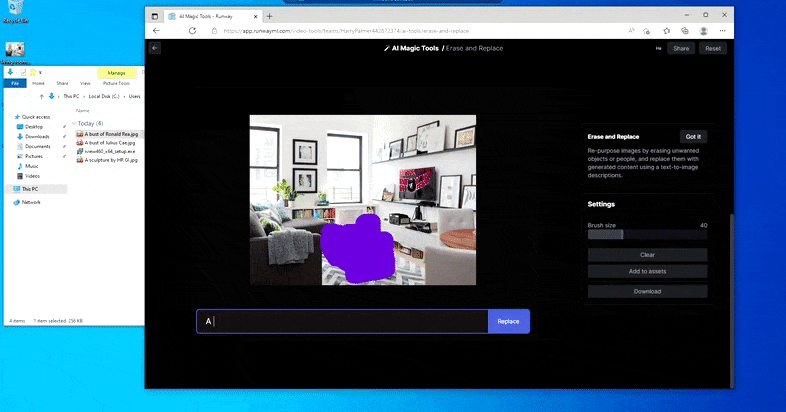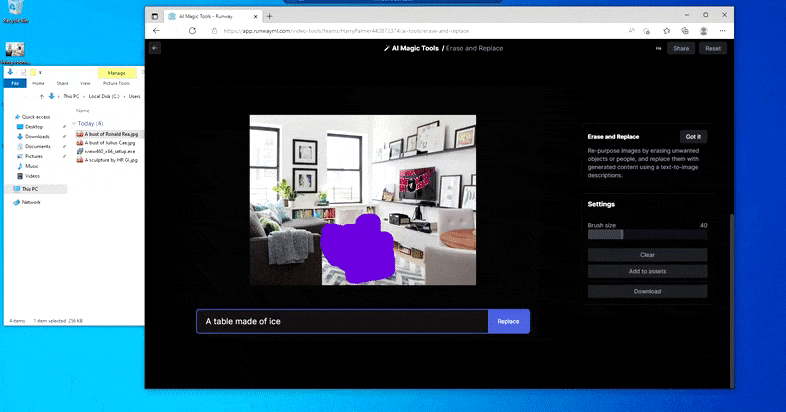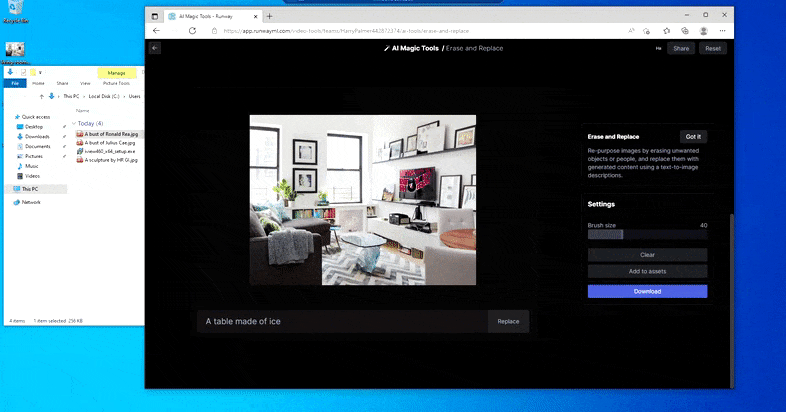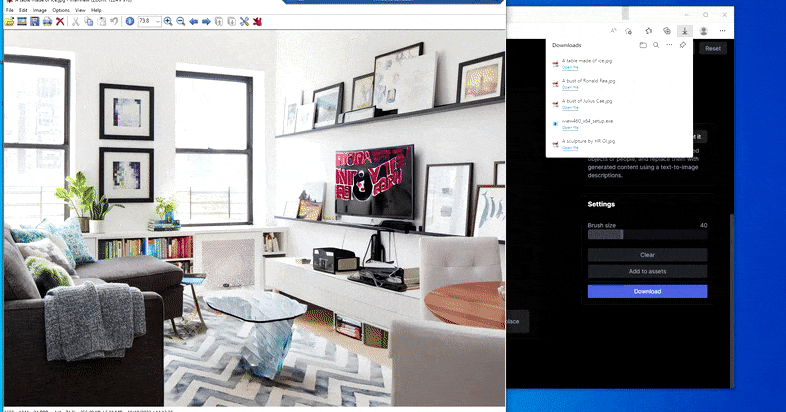
Sustituir una mesa doméstica por una ‘mesa de hielo’ en Borrar y reemplazar de Runway ML.
Al igual que Imagic (ver más abajo), Borrar y reemplazar es ‘orientado a objetos’, por así decirlo: no puedes simplemente borrar una ‘parte vacía’ de la imagen e inpintarla con el resultado de tu texto; en ese escenario, el sistema simplemente trazará el objeto más cercano aparente a lo largo de la línea de visión de la máscara (como una pared o un televisor) y aplicará la transformación allí.
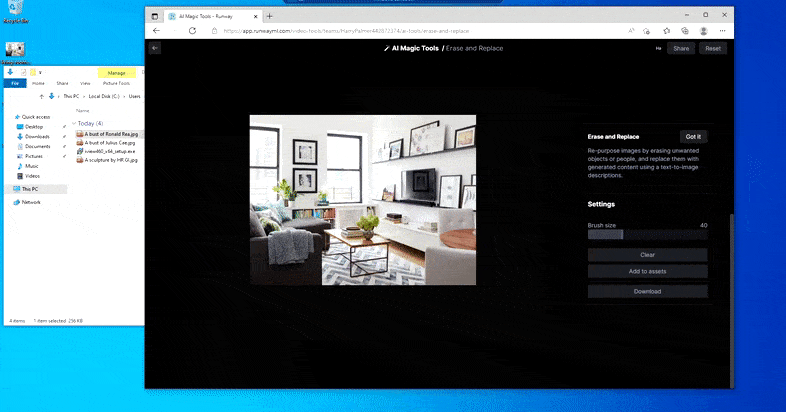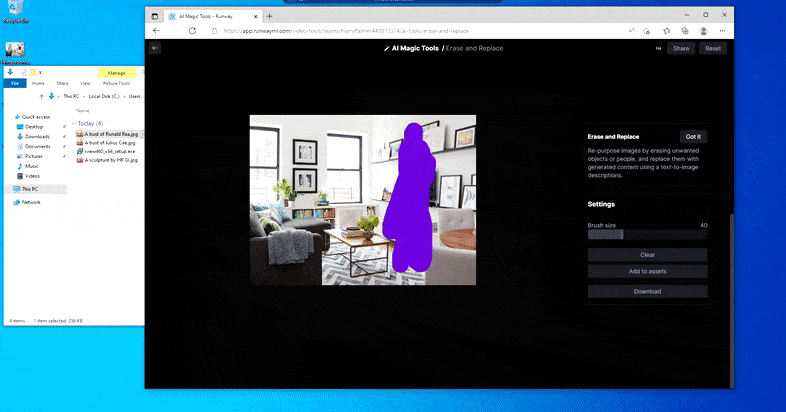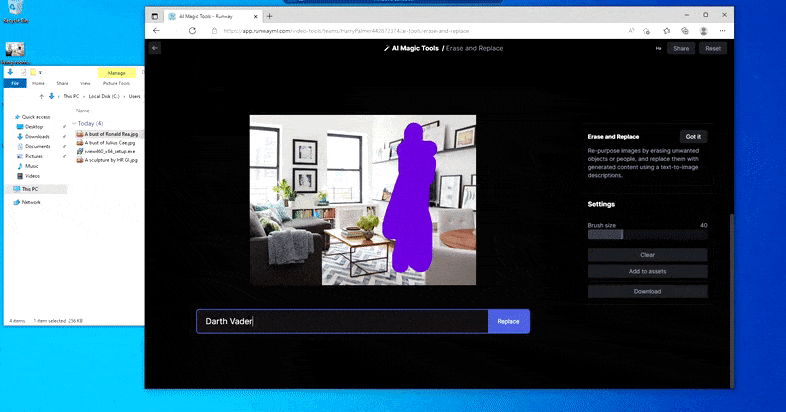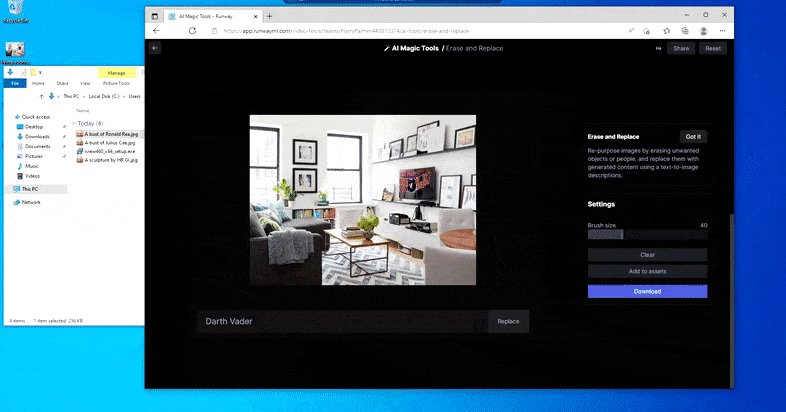
Como indica el nombre, no puedes inyectar objetos en el espacio vacío en Borrar y reemplazar. Aquí, un esfuerzo por invocar al señor de los Sith más famoso resulta en un mural extraño relacionado con Vader en la TV, aproximadamente donde se dibujó el área de ‘reemplazo’.
Es difícil decir si Borrar y reemplazar está siendo evasivo con respecto al uso de imágenes con derechos de autor (que aún están obstaculizadas, aunque con éxito variable, en DALL-E 2), o si el modelo utilizado en el motor de renderizado de backend no está optimizado para ese tipo de cosas.

El ‘Mural de Nicole Kidman’ ligeramente NSFW indica que el modelo de difusión presunto que se utiliza carece de la rechazada sistemática de DALL-E 2 para renderizar caras realistas o contenido subido de tono, mientras que los resultados de los intentos de evocar obras con derechos de autor van desde lo ambiguo (‘xenomorph’) hasta lo absurdo (‘el trono de hierro’). Inset inferior derecho, la imagen de origen.
Sería interesante saber qué métodos utiliza Borrar y reemplazar para aislar los objetos que puede reemplazar. Presumiblemente, la imagen se ejecuta a través de alguna derivación de CLIP, con los elementos discretos individuados por reconocimiento de objetos y segmentación semántica posterior. Ninguna de estas operaciones funciona casi tan bien en una instalación común de Stable Diffusion.
Pero nada es perfecto: a veces el sistema parece borrar y no reemplazar, incluso cuando (como hemos visto en la imagen de arriba), el mecanismo de renderizado subyacente definitivamente sabe lo que significa una texto de prompt. En este caso, resulta imposible convertir una mesa de café en un xenomorph: en su lugar, la mesa simplemente desaparece.
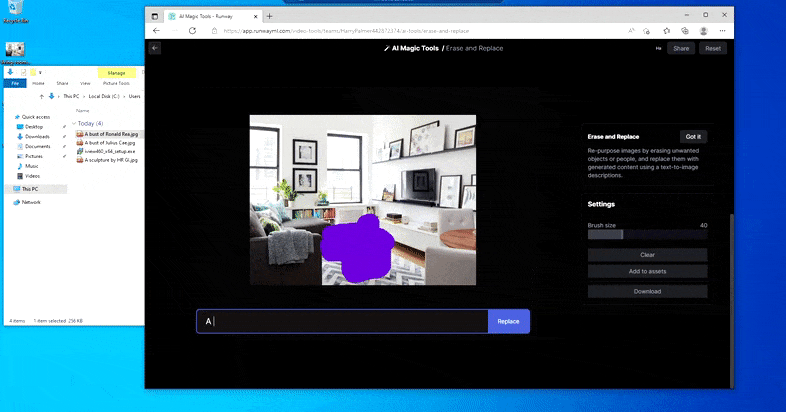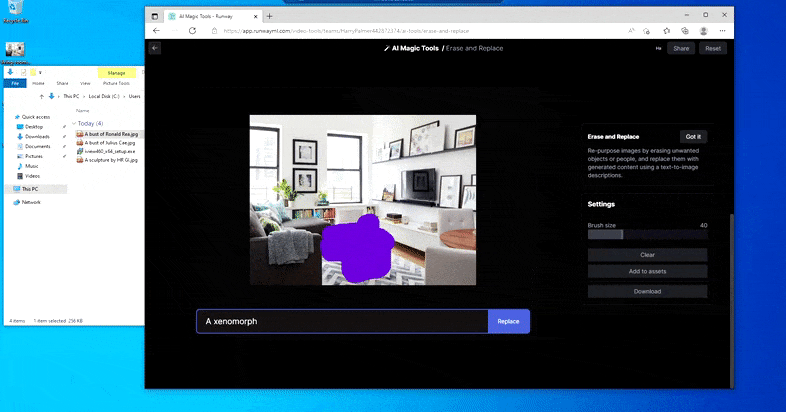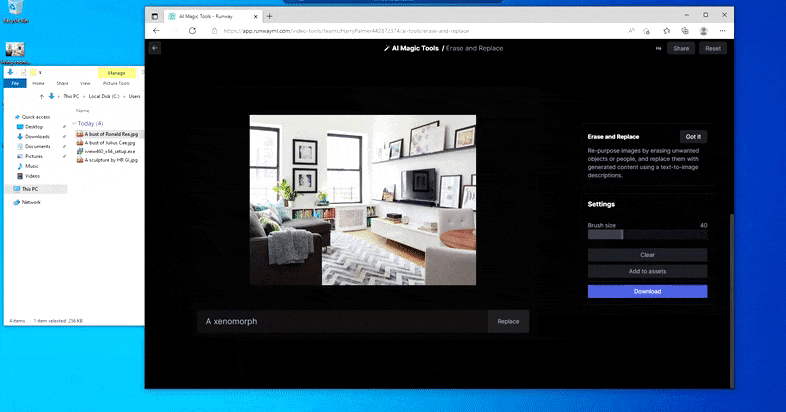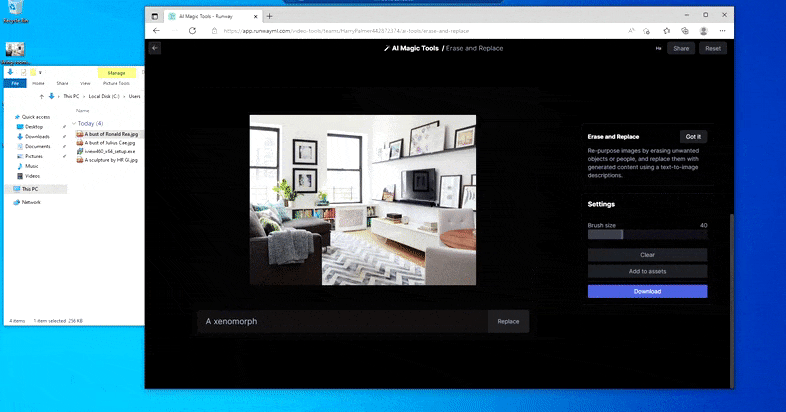
Una iteración más aterradora de ‘¿Dónde está Waldo?’, ya que Borrar y reemplazar no logra producir un alienígena.
Borrar y reemplazar parece ser un sistema de sustitución de objetos efectivo, con un excelente inpainting. Sin embargo, no puede editar objetos existentes percibidos, sino solo reemplazarlos. En realidad, alterar el contenido de la imagen existente sin comprometer el material ambiental es una tarea mucho más difícil, ligada a la lucha del sector de la visión por computadora hacia la desvinculación en los diversos espacios latentes de los marcos populares.
Imagic
Es una tarea que Imagic aborda. El nuevo documento ofrece numerosos ejemplos de ediciones que modifican con éxito facetas individuales de una foto mientras dejan el resto de la imagen intacta.

En Imagic, las imágenes modificadas no sufren del estiramiento, distorsión y ‘adivinanza de occlusión’ característicos de la marioneta de deepfake, que utiliza priores limitados derivados de una sola imagen.
El sistema emplea un proceso de tres etapas: optimización de incrustación de texto; ajuste fino del modelo; y, finalmente, la generación de la imagen modificada.

Imagic codifica el texto de prompt de destino para recuperar la incrustación de texto inicial, y luego optimiza el resultado para obtener la imagen de entrada. Después de eso, el modelo generativo se ajusta a la imagen de origen, agregando una serie de parámetros, antes de ser sometido a la interpolación solicitada.
Inesperadamente, el marco se basa en la arquitectura de texto a video de Imagen de Google, aunque los investigadores afirman que los principios del sistema son ampliamente aplicables a modelos de difusión latentes.
Imagen utiliza una arquitectura de tres niveles, en lugar del array de siete niveles utilizado para la iteración más reciente de texto a video del software. Los tres módulos distintos comprenden un modelo de difusión generativo que opera a una resolución de 64x64px; un modelo de super-resolución que escala esta salida a 256x256px; y un modelo de super-resolución adicional para llevar la salida hasta una resolución de 1024×1024.
Imagic interviene en la etapa más temprana de este proceso, optimizando la incrustación de texto solicitada en la etapa de 64px en un optimizador Adam con una tasa de aprendizaje estática de 0,0001.

Una clase magistral en desvinculación: aquellos que han intentado cambiar algo tan simple como el color de un objeto renderizado en un modelo de difusión, GAN o NeRF sabrán lo significativo que es que Imagic pueda realizar tales transformaciones sin ‘desgarrar’ la coherencia del resto de la imagen.
El ajuste fino tiene lugar en el modelo base de Imagen, durante 1500 pasos por imagen de entrada, condicionado en la incrustación revisada. Al mismo tiempo, la capa secundaria 64px>256px se optimiza en paralelo en la imagen condicionada. Los investigadores observan que una optimización similar para la capa final 256px>1024px tiene ‘poco o ningún efecto’ en los resultados finales, y por lo tanto no lo han implementado.
El documento establece que el proceso de optimización tarda aproximadamente ocho minutos por imagen en chips TPUV4 gemelos. La renderización final tiene lugar en Imagen core bajo el esquema de muestreo DDIM.
Al igual que en procesos de ajuste fino similares para el DreamBooth de Google, las incrustaciones resultantes también se pueden utilizar para alimentar la estilización, así como ediciones fotorealistas que contienen información extraída de la base de datos subyacente más amplia que alimenta a Imagen (ya que, como muestra la primera columna a continuación, las imágenes de origen no tienen el contenido necesario para efectuar estas transformaciones).

Movimiento y ediciones fotorealistas flexibles se pueden obtener mediante Imagic, mientras que los códigos derivados y desvinculados obtenidos en el proceso se pueden utilizar tan fácilmente para la salida estilizada.
Los investigadores compararon Imagic con trabajos anteriores SDEdit, un enfoque basado en GAN de 2021, una colaboración entre la Universidad de Stanford y la Universidad de Carnegie Mellon; y Text2Live, una colaboración, de abril de 2022, entre el Instituto de Ciencia Weizmann y NVIDIA.

Una comparación visual entre Imagic, SDEdit y Text2Live.
Es claro que los enfoques anteriores están luchando, pero en la fila inferior, que implica interjectar un cambio masivo de pose, los incumbentes fallan por completo para refigurar el material de origen, en comparación con un éxito notable de Imagic.
Los requisitos de recursos y el tiempo de entrenamiento por imagen de Imagic, aunque cortos por los estándares de tales empresas, lo hacen una inclusión poco probable en una aplicación de edición de imágenes local en computadoras personales: y no está claro hasta qué punto el proceso de ajuste fino podría reducirse a niveles de consumidor.
Como está, Imagic es una oferta impresionante que es más adecuada para las API: un entorno en el que Google Research, cauto de la crítica con respecto a facilitar el deepfaking, puede estar más cómodo.
Publicado por primera vez el 18 de octubre de 2022.












