Τεχνητή νοημοσύνη
Πώς Λειτουργεί η Γεννήτρια Text-to-3D AI: Meta 3D Gen, OpenAI Shap-E και άλλα
By
Aayush Mittal Mittal
Η ικανότητα να παράγει ψηφιακά τρισδιάστατα περιουσιακά στοιχεία από κείμενα προτύπων αντιπροσωπεύει μια από τις πιο ενθουσιώδεις πρόσφατες εξελίξεις στην τεχνητή νοημοσύνη και την υπολογιστική γραφική. Καθώς η αγορά των τρισδιάστατων ψηφιακών περιουσιακών στοιχείων προβλέπεται να αυξηθεί από $28.3 δισεκατομμύρια το 2024 σε $51.8 δισεκατομμύρια το 2029, τα μοντέλα text-to-3D είναι έτοιμα να παίξουν σημαντικό ρόλο στην επανάσταση της δημιουργίας περιεχομένου σε βιομηχανίες όπως τα βιντεοπαιχνίδια, η κινηματογραφική βιομηχανία, ο ηλεκτρονικός εμπορισμός και πολλά άλλα. Αλλά πώς ακριβώς λειτουργούν αυτά τα συστήματα τεχνητής νοημοσύνης; Σε αυτό το άρθρο, θα κάνουμε μια βαθιά εμβάθυνση στις τεχνικές λεπτομέρειες πίσω από τη γεννήτρια text-to-3D.

Η Πρόκληση της Γεννήτριας 3D
Η γεννήτρια ψηφιακών τρισδιάστατων περιουσιακών στοιχείων από κείμενα είναι μια σημαντικά πιο σύνθετη εργασία από τη γεννήτρια εικόνων 2D. Ενώ οι εικόνες 2D είναι ουσιαστικά πίνακες εικονοστοιχείων, τα τρισδιάστατα περιουσιακά στοιχεία απαιτούν την αναπαράσταση γεωμετρίας, υφών, υλικών και συχνά κινούμενων αντικειμένων στο τρισδιάστατο χώρο. Αυτή η πρόσθετη διαστατικότητα και σύνθετη πολυπλοκότητα καθιστά την εργασία της γεννήτριας πολύ πιο απαιτητική.
Ορισμένες βασικές προκλήσεις στη γεννήτρια text-to-3D περιλαμβάνουν:
- Αναπαράσταση τρισδιάστατης γεωμετρίας και δομής
- Γεννήτρια συνεπών υφών και υλικών σε ολόκληρη την τρισδιάστατη επιφάνεια
- Εγγύηση φυσικής πιθανοφάνειας και συνεχείας από πολλαπλά σημεία θέασης
- Καταγραφή λεπτομερειών και γлобικής δομής ταυτόχρονα
- Γεννήτρια περιουσιακών στοιχείων που μπορούν να αποδοθούν ή να εκτυπωθούν εύκολα
Για να αντιμετωπιστούν αυτές οι προκλήσεις, τα μοντέλα text-to-3D αξιοποιούν几 βασικές τεχνολογίες και τεχνικές.
Κύρια Στοιχεία των Συστημάτων Text-to-3D
Τα περισσότερα μοντέλα γεννήτριας text-to-3D μοιράζονται ορισμένα βασικά στοιχεία:
- Κωδικοποίηση κειμένου: Μετατροπή του εισαγώμενου κειμένου σε αριθμητική αναπαράσταση
- Τρισδιάστατη αναπαράσταση: Μέθοδος για την αναπαράσταση τρισδιάστατης γεωμετρίας και εμφάνισης
- Γεννήτρια μοντέλου: Το βασικό μοντέλο τεχνητής νοημοσύνης για τη γεννήτρια του τρισδιάστατου περιουσιακού στοιχείου
- Απόδοση: Μετατροπή της τρισδιάστατης αναπαράστασης σε εικόνες 2D για οπτικοποίηση
Ας εξετάσουμε κάθε ένα από αυτά σε περισσότερες λεπτομέρειες.
Κωδικοποίηση Κειμένου
Το πρώτο βήμα είναι να μετατρέψουμε το εισαγώμενο κείμενο σε αριθμητική αναπαράσταση που το μοντέλο τεχνητής νοημοσύνης μπορεί να εργαστεί. Αυτό συνήθως γίνεται χρησιμοποιώντας μεγάλους μοντέλους γλωσσών όπως BERT ή GPT.
Τρισδιάστατη Αναπαράσταση
Υπάρχουν beberapa κοινές μεθόδους για την αναπαράσταση τρισδιάστατης γεωμετρίας στα μοντέλα τεχνητής νοημοσύνης:
- Πλέγματα voxel: Τρισδιάστατοι πίνακες τιμών που αντιπροσωπεύουν κατοχή ή χαρακτηριστικά
- Συνόλου σημείων: Συνολά σημείων 3D
- Ιστών: Κορυφές και πρόσωπα που ορίζουν μια επιφάνεια
- Συνεχείς συναρτήσεις: Συνεχείς συναρτήσεις που ορίζουν μια επιφάνεια (π.χ. συνάρτηση υπογεγραμμένης απόστασης)
- Νευρωνικές ακτίνες (NeRFs): Νευρωνικά δίκτυα που αντιπροσωπεύουν πυκνότητα και χρώμα στο τρισδιάστατο χώρο
Κάθε μια από αυτές έχει ανταλλαγές όσον αφορά την ανάλυση, τη χρήση μνήμης και την ευκολία της γεννήτριας. Πολλά πρόσφατα μοντέλα χρησιμοποιούν συνεχείς συναρτήσεις ή NeRFs καθώς επιτρέπουν υψηλής ποιότητας αποτελέσματα με λογικές απαιτήσεις υπολογισμού.
Για παράδειγμα, μπορούμε να αναπαραστήσουμε μια απλή σφαίρα ως συνάρτηση υπογεγραμμένης απόστασης:
import numpy as np
def sphere_sdf(x, y, z, radius=1.0):
return np.sqrt(x**2 + y**2 + z**2) - radius
# Αξιολόγηση SDF σε ένα τρισδιάστατο σημείο
point = [0.5, 0.5, 0.5]
distance = sphere_sdf(*point)
print(f"Απόσταση στην επιφάνεια της σφαίρας: {distance}")
Γεννήτρια Μοντέλου
Το κεντρικό μέρος ενός συστήματος text-to-3D είναι το γεννήτρια μοντέλο που παράγει την τρισδιάστατη αναπαράσταση από την εμφωλευμένη αναπαράσταση κειμένου. Τα περισσότερα μοντέλα χρησιμοποιούν κάποια παραλλαγή ενός μοντέλου διάχυσης, παρόμοια με αυτά που χρησιμοποιούνται στη γεννήτρια εικόνων 2D.
Τα μοντέλα διάχυσης λειτουργούν προσθέτοντας逐渐 θόρυβο στα δεδομένα και στη συνέχεια μαθαίνοντας να αντιστρέφουν αυτή τη διαδικασία. Για τη γεννήτρια 3D, αυτή η διαδικασία συμβαίνει στο χώρο της επιλεγμένης τρισδιάστατης αναπαράστασης.
Ένα απλοποιημένο ψευδοκώδικα για ένα βήμα εκπαίδευσης μοντέλου διάχυσης μπορεί να φαίνεται così:
def diffusion_training_step(model, x_0, text_embedding): # Δειγματίζουμε ένα τυχαίο βήμα t = torch.randint(0, num_timesteps, (1,)) # Προσθέτουμε θόρυβο στην είσοδο noise = torch.randn_like(x_0) x_t = add_noise(x_0, noise, t) # Προβλέπουμε τον θόρυβο predicted_noise = model(x_t, t, text_embedding) # Υπολογίζουμε την απώλεια loss = F.mse_loss(noise, predicted_noise) return loss # Βρόχος εκπαίδευσης for batch in dataloader: x_0, text = batch text_embedding = encode_text(text) loss = diffusion_training_step(model, x_0, text_embedding) loss.backward() optimizer.step()
Κατά τη διάρκεια της γεννήτριας, ξεκινάμε από καθαρό θόρυβο και επαναλαμβανόμενα αποθορυβοποιούμε, υπό την επιρροή της εμφωλευμένης αναπαράστασης κειμένου.
Απόδοση
Για να οπτικοποιήσουμε τα αποτελέσματα και να υπολογίσουμε απώλειες κατά την εκπαίδευση, χρειαζόμαστε να αποδώσουμε την τρισδιάστατη αναπαράσταση σε εικόνες 2D. Αυτό συνήθως γίνεται χρησιμοποιώντας διαφορίσιμες τεχνικές απόδοσης που επιτρέπουν τη ροή των gradient στο πίσω μέρος της διαδικασίας απόδοσης.
Για αναπαραστάσεις με βάση τον ιστό, μπορεί να χρησιμοποιηθεί ένας αποδοτής με βάση την αποτύπωση:
import torch import torch.nn.functional as F import pytorch3d.renderer as pr def render_mesh(vertices, faces, image_size=256): # Δημιουργούμε einen αποδοτή renderer = pr.MeshRenderer( rasterizer=pr.MeshRasterizer(), shader=pr.SoftPhongShader() ) # Ρυθμίζουμε την κάμερα cameras = pr.FoVPerspectiveCameras() # Αποδίδουμε images = renderer(vertices, faces, cameras=cameras) return images # Παράδειγμα χρήσης vertices = torch.rand(1, 100, 3) # Τυχαίες κορυφές faces = torch.randint(0, 100, (1, 200, 3)) # Τυχαίες πρόσωπα rendered_images = render_mesh(vertices, faces)
Για αναπαραστάσεις με βάση τις συνεχείς συναρτήσεις όπως οι NeRFs, συνήθως χρησιμοποιούνται τεχνικές march του ακτίνα για την απόδοση.
Συγκεντρώνοντας τα Πάντα: Η Διαδικασία Text-to-3D
Τώρα που έχουμε καλύψει τα βασικά στοιχεία, ας περάσουμε από τη διαδικασία που συνδυάζει αυτά τα στοιχεία σε μια τυπική διαδικασία γεννήτριας text-to-3D:
- Κωδικοποίηση κειμένου: Η εισαγώμενη πρόταση κειμένου κωδικοποιείται σε μια πυκνή διανυσματική αναπαράσταση χρησιμοποιώντας ένα μοντέλο γλωσσών.
- Αρχική γεννήτρια: Ένα μοντέλο διάχυσης, υπό την επιρροή της εμφωλευμένης αναπαράστασης κειμένου, γεννήτρια μιας αρχικής τρισδιάστατης αναπαράστασης (π.χ. NeRF ή συνεχής συνάρτηση).
- Συνέπεια πολλαπλών προοπτικών: Το μοντέλο αποδίδει πολλαπλές προοπτικές του γεννημένου τρισδιάστατου περιουσιακού στοιχείου και εξασφαλίζει συνέπεια μεταξύ των προοπτικών.
- Βελτίωση: Επιπλέον δίκτυα μπορεί να βελτιώσουν τη γεωμετρία, να προσθέσουν υφές ή να ενισχύσουν λεπτομέρειες.
- Τελικό αποτέλεσμα: Η τρισδιάστατη αναπαράσταση μετατρέπεται σε μια επιθυμητή μορφή (π.χ. υφασμένο ιστό) για χρήση σε εφαρμογές.
Εδώ είναι ένα απλοποιημένο παράδειγμα του πώς αυτό μπορεί να φαίνεται σε κώδικα:
class TextTo3D(nn.Module):
def __init__(self):
super().__init__()
self.text_encoder = BertModel.from_pretrained(‘bert-base-uncased’)
self.diffusion_model = DiffusionModel()
self.refiner = RefinerNetwork()
self.renderer = DifferentiableRenderer()
def forward(self, text_prompt):
# Κωδικοποίηση κειμένου
text_embedding = self.text_encoder(text_prompt).last_hidden_state.mean(dim=1)
# Αρχική γεννήτρια τρισδιάστατης αναπαράστασης
initial_3d = self.diffusion_model(text_embedding)
# Απόδοση πολλαπλών προοπτικών
views = self.renderer(initial_3d, num_views=4)
# Βελτίωση με βάση την συνέπεια πολλαπλών προοπτικών
refined_3d = self.refiner(initial_3d, views)
return refined_3d
# Χρήση
model = TextTo3D()
text_prompt = “Μια κόκκινη σπορ αυτοκίνητο”
generated_3d = model(text_prompt)
Κορυφαία Μοντέλα Περιουσιακών Στοιχείων Text-to-3D Διαθέσιμα
3DGen – Meta
3DGen σχεδιάστηκε για να αντιμετωπίσει το πρόβλημα της γεννήτριας περιεχομένου 3D – όπως χαρακτήρες, αντικείμενα και σκηνές – από περιγραφές κειμένου.
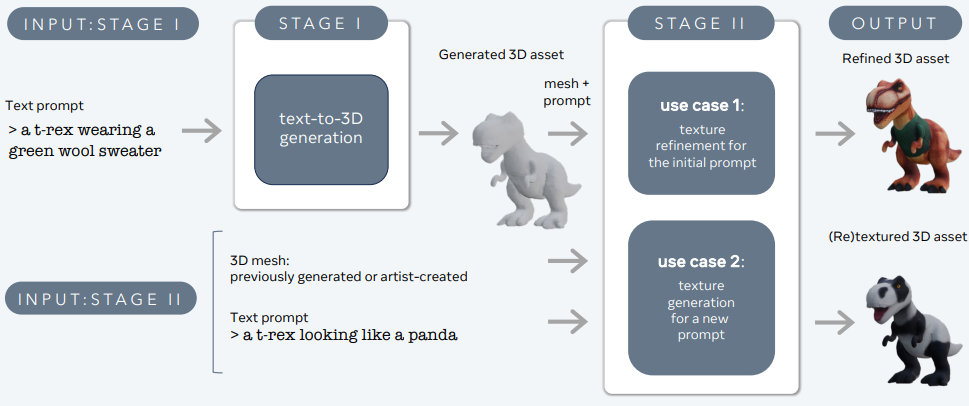
Μεγάλες Γλώσσες και Μοντέλα Text-to-3D – 3d-gen
3DGen υποστηρίζει φυσικά βασισμένη απόδοση (PBR), απαραίτητη για την πραγματική απόδοση τρισδιάστατων περιουσιακών στοιχείων σε πραγματικές εφαρμογές. Επίσης, επιτρέπει τη γεννήτρια υφών σε προηγουμένως γεννημένα ή δημιουργημένα από καλλιτέχνη τρισδιάστατα σχήματα χρησιμοποιώντας νέες περιγραφές κειμένου. Η διαδικασία ενσωματώνει δύο βασικά στοιχεία: Meta 3D AssetGen και Meta 3D TextureGen, τα οποία χειρίζονται τη γεννήτρια κειμένου σε 3D και τη γεννήτρια κειμένου σε υφή, αντίστοιχα.
Meta 3D AssetGen
Meta 3D AssetGen (Siddiqui et al., 2024) είναι υπεύθυνο για την αρχική γεννήτρια τρισδιάστατων περιουσιακών στοιχείων από περιγραφές κειμένου. Αυτό το στοιχείο παράγει einen ιστό με υφές και χάρτες υλικών PBR σε περίπου 30 δευτερόλεπτα.
Meta 3D TextureGen
Meta 3D TextureGen (Bensadoun et al., 2024) βελτιώνει τις υφές που παράγονται από το AssetGen. Μπορεί επίσης να χρησιμοποιηθεί για τη γεννήτρια νέων υφών για υπάρχοντα τρισδιάστατα σχήματα με βάση πρόσθετες περιγραφές κειμένου. Αυτό το στάδιο διαρκεί περίπου 20 δευτερόλεπτα.
Point-E (OpenAI)
Point-E, αναπτυγμένο από την OpenAI, είναι ένα άλλο αξιοσημείωτο μοντέλο γεννήτριας text-to-3D. Σε αντίθεση με το DreamFusion, το οποίο παράγει αναπαραστάσεις NeRF, το Point-E γεννήτρια τρισδιάστατα σημεία.
Κύρια χαρακτηριστικά του Point-E:
α) Διπλή διαδικασία: Το Point-E πρώτα γεννήτρια μιας συνθετικής προοπτικής 2D χρησιμοποιώντας ένα μοντέλο διάχυσης κειμένου-εικόνας, και στη συνέχεια χρησιμοποιεί αυτή την εικόνα για να προϋποθέσει ένα δεύτερο μοντέλο διάχυσης που παράγει το τρισδιάστατο σημείο.
β) Αποδοτικότητα: Το Point-E σχεδιάστηκε για να είναι υπολογιστικά αποδοτικό, ικανό να γεννήτρια τρισδιάστατα σημεία σε δευτερόλεπτα σε μια seule GPU.
γ) Χρωματική πληροφορία: Το μοντέλο μπορεί να γεννήτρια χρωματισμένα σημεία, διατηρώντας τόσο γεωμετρική όσο και εμφανισιακή πληροφορία.
Περιορισμοί:
- Χαμηλότερη πιστότητα σε σύγκριση με προσεγγίσεις με βάση τον ιστό ή NeRF
- Τα σημεία απαιτούν πρόσθετη επεξεργασία για πολλές εφαρμογές
Shap-E (OpenAI):
Βασισμένο στο Point-E, η OpenAI εισήγαγε το Shap-E, το οποίο γεννήτρια τρισδιάστατους ιστούς αντί σημείων. Αυτό αντιμετωπίζει ορισμένα από τα προβλήματα του Point-E ενώ διατηρεί την υπολογιστική αποδοτικότητα.
Κύρια χαρακτηριστικά του Shap-E:
α) Συνεχής αναπαράσταση: Το Shap-E μαθαίνει να γεννήτρια συνεχείς αναπαραστάσεις (συναρτήσεις υπογεγραμμένης απόστασης) τρισδιάστατων αντικειμένων.
β) Εξαγωγή ιστών: Το μοντέλο χρησιμοποιεί μια διαφορίσιμη υλοποίηση του αλγορίθμου marching cubes για τη μετατροπή της συνεχούς αναπαράστασης σε πολυγωνικό ιστό.
γ) Γεννήτρια υφής: Το Shap-E μπορεί επίσης να γεννήτρια υφές για τους τρισδιάστατους ιστούς, οδηγώντας σε πιο οπτικά ελκυστικά αποτελέσματα.
Πλεονεκτήματα:
- Γρήγορες χρόνοι γεννήτριας (δευτερόλεπτα έως λεπτά)
- Απευθείας έξοδος ιστών κατάλληλη για απόδοση και εφαρμογές
- Ικανότητα γεννήτριας και γεωμετρίας και υφής
GET3D (NVIDIA):
GET3D, αναπτυγμένο από ερευνητές της NVIDIA, είναι ένα άλλο ισχυρό μοντέλο γεννήτριας text-to-3D που επικεντρώνεται στην παραγωγή υψηλής ποιότητας υφασμένων τρισδιάστατων ιστών.
Κύρια χαρακτηριστικά του GET3D:
α) Εξπlicit αναπαράσταση επιφάνειας: Σε αντίθεση με το DreamFusion ή το Shap-E, το GET3D γεννήτρια εξπlicit αναπαραστάσεων επιφάνειας (ιστών) χωρίς μεσολαβικές συνεχείς αναπαραστάσεις.
β) Γεννήτρια υφής: Το μοντέλο περιλαμβάνει μια διαφορίσιμη τεχνική απόδοσης για να μάθει και να γεννήτρια υψηλής ποιότητας υφών για τους τρισδιάστατους ιστούς.
γ) Αρχιτεκτονική GAN: Το GET3D χρησιμοποιεί μια αρχιτεκτονική GAN, η οποία επιτρέπει γρήγορη γεννήτρια μιας φοράς που το μοντέλο έχει εκπαιδευτεί.
Πλεονεκτήματα:
- Υψηλής ποιότητας γεωμετρία και υφές
- Γρήγορες χρόνοι εκπαίδευσης
- Άμεση ολοκλήρωση με μηχανές απόδοσης 3D
Περιορισμοί:
- Απαιτεί τρισδιάστατα δεδομένα εκπαίδευσης, τα οποία μπορούν να είναι σπάνια για ορισμένες κατηγορίες αντικειμένων
Συμπέρασμα
Η γεννήτρια text-to-3D AI αντιπροσωπεύει μια θεμελιώδη αλλαγή στη δημιουργία και την αλληλεπίδραση με τρισδιάστατο περιεχόμενο. Χρησιμοποιώντας προηγμένα τεχνάσματα βαθιάς μάθησης, αυτά τα μοντέλα μπορούν να παράγουν σύνθετα, υψηλής ποιότητας τρισδιάστατα περιουσιακά στοιχεία από απλές περιγραφές κειμένου. Καθώς η τεχνολογία συνεχίζει να εξελίσσεται, μπορούμε να περιμένουμε να δούμε ολοένα και πιο σύνθετα και ικανά συστήματα text-to-3D που θα επαναφέρουν βιομηχανίες από τα βιντεοπαιχνίδια και τον κινηματογράφο στο σχεδιασμό προϊόντων και την αρχιτεκτονική.
Έχω περάσει τα τελευταία πέντε χρόνια βυθισμένος στον fascinující κόσμο της Μηχανικής Μάθησης και της Βαθιάς Μάθησης. Η αγάπη και η εξειδίκευσή μου έχουν οδηγήσει στην συμβολή μου σε πάνω από 50 διαφορετικά projects μηχανικής λογισμικού, με ιδιαίτερη έμφαση στο AI/ML. Η συνεχής περιέργεια μου έχει επίσης τραβήξει την προσοχή μου προς την Επεξεργασία Φυσικής Γλώσσας, ένα πεδίο που είμαι πρόθυμος να εξερευνήσω περαιτέρω.

You may like


Η Αγώνας των Όπλων της Τεχνητής Νοημοσύνης Εντείνεται: Η Στρατηγική Συνεργασία της AMD με την OpenAI


OpenAI Secures Seven-Year, $38 Billion AWS Cloud Partnership


Βελτιστοποίηση Νευρωνικών Πεδίων Ραδιάντσας (NeRF) για Εchtzeit 3D Απόδοση σε Πλατφόρμες Ηλεκτρονικού Εμπορίου


Το Πρωτόκολλο Πλαισίου Μοντέλου του Claude (MCP): Ένας Οδηγός για τους Ανάπτυκτες


Σχεδιαστικά Πρότυπα σε Python για Μηχανικούς AI και LLM: Ένας Πρακτικός Οδηγός


Microsoft AutoGen: Πολυ-Εージεντ AI Ροές Εργασιών με Προηγμένη Αυτοματοποίηση







