
Τεχνητή νοημοσύνη
Το ανώτατο όριο του 75%: Έχουν φτάσει τα μοντέλα τεχνητής νοημοσύνης στην κορυφή της απόδοσης με τις τρέχουσες μεθόδους;

Ανθρωπικός και OpenAI αποκάλυψε πρωτοποριακά μοντέλα τεχνητής νοημοσύνης με διαφορά δύο ημερών, με τα δύο να επιτυγχάνουν σχεδόν πανομοιότυπη ακρίβεια 74-75% σε benchmarks κωδικοποίησης του κλάδου, σηματοδοτώντας ένα πιθανό ανώτατο όριο απόδοσης για τις τρέχουσες αρχιτεκτονικές τεχνητής νοημοσύνης, ενώ παράλληλα υιοθετούν δραματικά διαφορετικές προσεγγίσεις στη διανομή και την εφαρμογή.
Οι σχεδόν ταυτόχρονες κυκλοφορίες εγείρουν θεμελιώδη ερωτήματα σχετικά με το εάν η ανάπτυξη της Τεχνητής Νοημοσύνης έχει φτάσει σε ένα οροπέδιο με τις τρέχουσες μεθόδους εκπαίδευσης, ακόμη και καθώς οι εταιρείες αποκλίνουν έντονα ως προς τον τρόπο παροχής αυτών των δυνατοτήτων σε χρήστες και προγραμματιστές παγκοσμίως.
Η Σύγκλιση Δεικτών Αναφοράς Υποδεικνύει Τεχνικό Ορόσημο
Κλοντ Έπους 4.1, που κυκλοφόρησε στις 5 Αυγούστου από την Anthropic, σημείωσε βαθμολογία 74.5% στο SWE-bench Verified, το πρότυπο συγκριτικής αξιολόγησης κωδικοποίησης του κλάδου. Το GPT-5 του OpenAI, που ανακοινώθηκε στις 7 Αυγούστου, πέτυχε 74.9% στην ίδια δοκιμή—μια στατιστική ισοβαθμία που υποδηλώνει ότι και οι δύο εταιρείες έχουν ωθήσει τις τρέχουσες αρχιτεκτονικές σε παρόμοια όρια, παρά το γεγονός ότι εργάζονται ανεξάρτητα.
Η διαφορά του 0.4% μεταξύ των μοντέλων εμπίπτει στο περιθώριο του στατιστικού θορύβου για τέτοια σημεία αναφοράς.
Ωστόσο, οι αρχιτεκτονικές προσεγγίσεις διαφέρουν σημαντικά. Το OpenAI δημιούργησε το GPT-5 ως ένα σύστημα πολλαπλών μοντέλων με έξυπνη δρομολόγηση—τα ερωτήματα κατευθύνονται σε ταχύτατους ανταποκριτές για απλές εργασίες, σε μοντέλα συλλογισμού για σύνθετα προβλήματα ή σε μίνι εκδόσεις όταν επιτευχθούν τα όρια υπολογισμού. Η Anthropic διατήρησε μια προσέγγιση ενός μοντέλου με το Opus 4.1, δίνοντας προτεραιότητα στη συνέπεια έναντι της εξειδικευμένης βελτιστοποίησης.
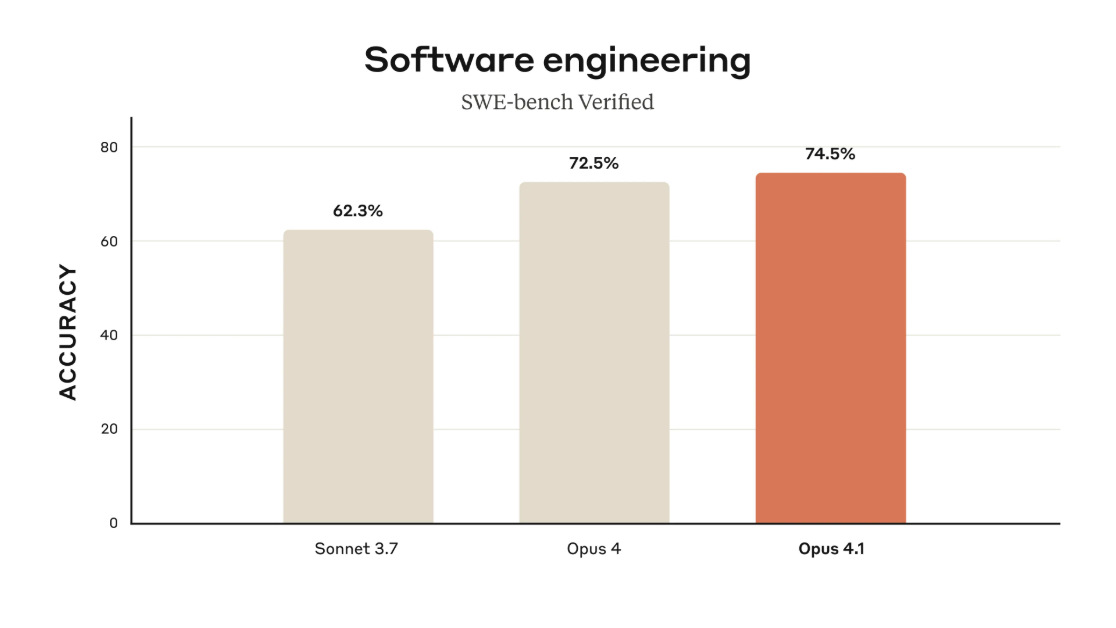
Πηγή: Anthropic
Οι στρατηγικές διανομής αποκαλύπτουν ανταγωνιστικές φιλοσοφίες
Το OpenAI έκανε το GPT-5 άμεσα διαθέσιμο σε όλους τους χρήστες του ChatGPT, συμπεριλαμβανομένων εκείνων που βρίσκονταν στην δωρεάν έκδοση, φτάνοντας περίπου τα 700 εκατομμύρια εβδομαδιαίως ενεργούς χρήστες χωρίς κόστος. Η Microsoft ενσωμάτωσε ταυτόχρονα το μοντέλο στις πλατφόρμες GitHub Copilot, Visual Studio Code, M365 Copilot και Azure.
Η Anthropic διατηρεί πιο παραδοσιακούς περιορισμούς πρόσβασης, προσφέροντας Opus 4.1 για χρήστες επί πληρωμή του Claude, μέσω του Claude Code για προγραμματιστές και μέσω πρόσβασης API. Η εταιρεία φαίνεται να επικεντρώνεται στην εξυπηρέτηση προγραμματιστών και επιχειρήσεων που απαιτούν αξιόπιστη και συνεπή απόδοση αντί για τη μεγιστοποίηση της εμβέλειας διανομής.
Η τιμολόγηση του GPT-5 είναι επιθετική, με τους προγραμματιστές να σημειώνουν ευνοϊκούς λόγους κόστους προς δυνατότητες που θα μπορούσαν να πιέσουν τους ανταγωνιστές να προσαρμόσουν τις στρατηγικές τιμολόγησης.
Οι απαιτήσεις υποδομών αναδιαμορφώνουν την οικονομία του κλάδου
Οι υπολογιστικές απαιτήσεις αποκαλύπτουν την τεράστια κλίμακα ανάπτυξης της πρωτοποριακής Τεχνητής Νοημοσύνης. Η OpenAI φέρεται να διατηρεί ένα Ετήσιο συμβόλαιο 30 δισεκατομμυρίων δολαρίων με την Oracle για χωρητικότητα, έχοντας εκπαιδευτεί στο GPT-5 στο Microsoft Azure χρησιμοποιώντας GPU NVIDIA H200. Ο Meta ανακοίνωσε σχέδια για δαπάνη 72 δισεκατομμυρίων δολαρίων σε υποδομές τεχνητής νοημοσύνης μόνο το 2025.
Και οι δύο εταιρείες αναφέρουν σημαντικές βελτιώσεις σε πρακτικές εφαρμογές πέρα από τα ακατέργαστα benchmarks. Η OpenAI δηλώνει ότι το GPT-5 επιδεικνύει «περίπου 45% λιγότερα σφάλματα από το GPT-4o» όταν είναι ενεργοποιημένη η αναζήτηση στο web, με τη λειτουργία σκέψης να επιτυγχάνει παρόμοια αποτελέσματα με το μοντέλο o3, χρησιμοποιώντας 50-80% λιγότερα tokens - ένα σημαντικό κέρδος στην αποδοτικότητα.
Αναφορές GitHub Παραστάσεις Opus 4.1 «αξιοσημείωτα κέρδη στην απόδοση στην αναδιαμόρφωση κώδικα πολλαπλών αρχείων», ενώ το Cursor, ένας δημοφιλής βοηθός κωδικοποίησης τεχνητής νοημοσύνης, περιγράφει το GPT-5 ως «εξαιρετικά έξυπνο, εύκολο στη διαχείριση», σύμφωνα με την τεκμηρίωση προγραμματιστών του OpenAI.
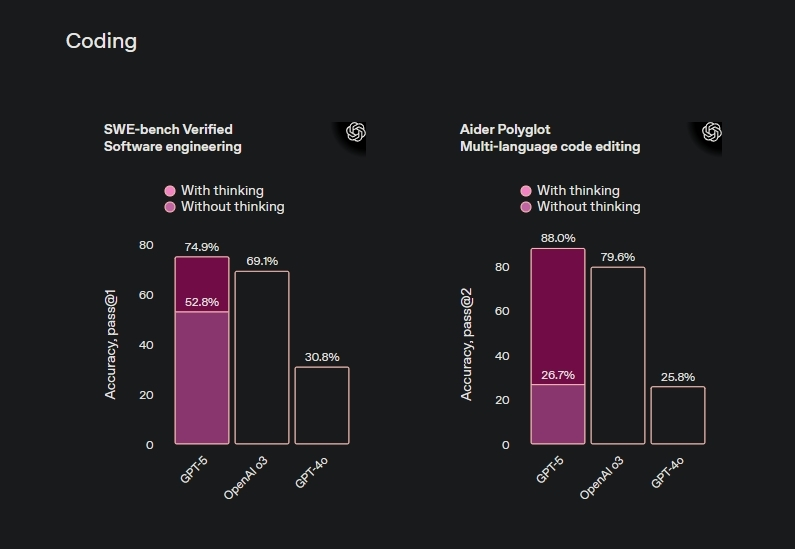
Πηγή: OpenAI
Το τεχνικό ανώτατο όριο υποδηλώνει μετατόπιση παραδείγματος προς τα εμπρός
Η σύγκλιση σε παρόμοιες μετρήσεις απόδοσης μεταξύ των εταιρειών υποδηλώνει ότι τα τρέχοντα πρότυπα εκπαίδευσης ενδέχεται να πλησιάζουν τα όριά τους. Πολλαπλά μοντέλα ομαδοποιούνται με ακρίβεια περίπου 74-75% σε σημεία αναφοράς κωδικοποίησης δείχνει ότι οι επόμενες σημαντικές βελτιώσεις ενδέχεται να απαιτούν θεμελιώδεις καινοτομίες αντί για σταδιακή κλιμάκωση.
Οι αρχιτεκτονικοί συμβιβασμοί μεταξύ του πολύπλοκου συστήματος δρομολόγησης του OpenAI και Η ενοποιημένη προσέγγιση του Anthropic αντικατοπτρίζουν διαφορετικές φιλοσοφίες χωρίς σαφή νικητή. Το σύστημα πολλαπλών μοντέλων του GPT-5 προσφέρει ευελιξία αλλά εισάγει πιθανά σημεία αποτυχίας, ενώ η συνέπεια του Claude μπορεί να θυσιάσει την εξειδικευμένη απόδοση για την αξιοπιστία.
Ο εκδημοκρατισμός των πρωτοποριακών δυνατοτήτων της Τεχνητής Νοημοσύνης —με χαρακτηριστικά που κόστιζαν χιλιάδες ετησίως πριν από δύο χρόνια και τώρα διαθέσιμα δωρεάν— επιταχύνει την υιοθέτησή τους σε όλους τους κλάδους. Αυτή η μετάβαση από την Τεχνητή Νοημοσύνη ως υπηρεσία υψηλής ποιότητας σε υποδομές κοινής ωφέλειας θα μπορούσε να επιτρέψει εντελώς νέες κατηγορίες εφαρμογών.
Επιπτώσεις στην αγορά και επόμενα βήματα
Οι παρατηρητές του κλάδου αναμένουν ότι η Anthropic θα ανταποκριθεί στην τιμολογιακή στρατηγική της OpenAI, αν και πιθανότατα όχι μέσω άμεσης αντιστοίχισης τιμών. Το DeepMind της Google και η Meta, που ήταν σχετικά σιωπηλοί κατά τη διάρκεια αυτών των ανακοινώσεων, αναμένεται να κάνουν κινήσεις τους επόμενους μήνες.
Το χρονικό διάστημα των 48 ωρών μεταξύ των κυκλοφοριών αποκάλυψε τη μετάβαση της Τεχνητής Νοημοσύνης από την πειραματική τεχνολογία στην αξιόπιστη υποδομή. Όταν πολλές εταιρείες επιτυγχάνουν σχεδόν πανομοιότυπες βαθμολογίες αναφοράς με κλασματικές ποσοστιαίες διαφορές, ο ανταγωνισμός μετατοπίζεται προς την αποτελεσματικότητα της ανάπτυξης, την ποιότητα ενσωμάτωσης και την αξιοπιστία των υπηρεσιών.
Οι πρακτικές βελτιώσεις έχουν μεγαλύτερη σημασία από την υπεροχή σε συγκριτικά αποτελέσματα. Το SWE-bench Verified μετρά την ικανότητα μιας τεχνητής νοημοσύνης να εντοπίζει και να διορθώνει πραγματικά σφάλματα σε λογισμικό ανοιχτού κώδικα και οι βαθμολογίες και των δύο μοντέλων αντιπροσωπεύουν σημαντικές προόδους στις δυνατότητες αυτόνομης κωδικοποίησης.
Καθώς τα μοντέλα τεχνητής νοημοσύνης γίνονται ολοένα και πιο εξελιγμένα στις ικανότητες συλλογισμού και κωδικοποίησης, ο ανταγωνισμός μετατοπίζεται από τις ακατέργαστες μετρήσεις απόδοσης στην πρακτική εφαρμογή και αξιοπιστία σε περιβάλλοντα παραγωγής. Η εκπληκτική αλήθεια; Αυτή η σταθερότητα θα μπορούσε να επιτρέψει περισσότερες μετασχηματιστικές αλλαγές από ό,τι θα έκανε μια άλλη σημαντική ανακάλυψη.











