Τεχνητή νοημοσύνη
Συνθετικά Δεδομένα: Γέφυρα για το Χάσμα της Οκκλούσης με το Grand Theft Auto
Ερευνητές στο Πανεπιστήμιο του Ιλινόις έχουν δημιουργήσει ένα νέο σύνολο δεδομένων για την υπολογιστική όραση που χρησιμοποιεί συνθετική εικόνα που παράγεται από το μηχανισμό του παιχνιδιού Grand Theft Auto για να βοηθήσει στην επίλυση ενός από τα πιο δύσκολα εμπόδια στη σεμαντική τομείς – αναγνώριση αντικειμένων που είναι μόνο εν μέρει ορατά στις πηγαίες εικόνες και βίντεο.
Για αυτό, όπως περιγράφεται στο το έγγραφο, οι ερευνητές έχουν χρησιμοποιήσει το μηχανισμό του βίντεο παιχνιδιού GTA-V για να δημιουργήσουν ένα συνθετικό σύνολο δεδομένων που όχι μόνο διαθέτει ένα ρεκόρ αριθμού περιπτώσεων οκκλούσης, αλλά και διαθέτει τέλεια σεμαντική τομείς και ετικέτες, και λαμβάνει υπόψη τις χρονικές πληροφορίες με τρόπο που δεν αντιμετωπίζεται από παρόμοια ανοιχτά σύνολα δεδομένων.
Πλήρης Κατανόηση της Σκηνής
Το βίντεο παρακάτω, που δημοσιεύθηκε ως υλικό υποστήριξης για την έρευνα, δείχνει τα πλεονεκτήματα μιας πλήρους κατανόησης της σκηνής σε 3D, όπου τα κρυμμένα αντικείμενα είναι γνωστά και εκτίθενται στη σκηνή σε όλες τις περιπτώσεις, επιτρέποντας στο σύστημα αξιολόγησης να μάθει να συνδέει τις μερικά οκκλουσμένες απόψεις με το ολόκληρο (ετικεταρισμένο) αντικείμενο.
Πηγή: http://sailvos.web.illinois.edu/_site/index.html
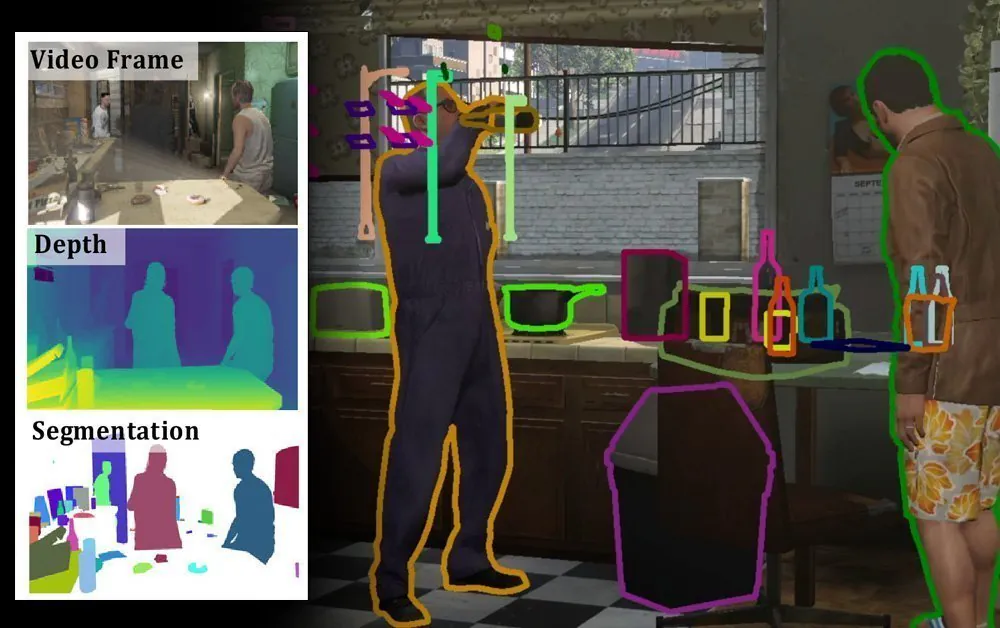
Το αποτέλεσμα σύνολο δεδομένων, που ονομάζεται SAIL-VOS 3D, ισχυρίζεται από τους συγγραφείς ότι είναι το πρώτο συνθετικό βίντεο σύνολο δεδομένων με πλαισιακή-προς-πλαισιακή ετικέτα, instance-επίπεδο τομείς, ground truth βάθος για προβολές σκηνής και 2D ετικέτες που περιγράφονται από ορθογώνιες περιοχές.

Πηγή (Κάντε κλικ για μεγέθυνση)
Οι ετικέτες του SAIL-VOS 3D περιλαμβάνουν βάθος, instance-επίπεδο modal και amodal τομείς, σεμαντικές ετικέτες και 3D mesh. Τα δεδομένα περιλαμβάνουν 484 βίντεο που αποτελούνται από 237.611 πλαισιά σε ανάλυση 1280×800, συμπεριλαμβανομένων μεταβάσεων shot.

Πάνω, τα αρχικά CGI πλαισιά, δεύτερη σειρά, instance-επίπεδο τομείς, τρίτη σειρά, amodal τομείς, που δείχνει το βάθος της κατανόησης της σκηνής και τη διαφάνεια που είναι διαθέσιμη στα δεδομένα. Πηγή (Κάντε κλικ για μεγέθυνση)
Το σύνολο δεδομένων διαθέτει 6.807 κλιπ με μέσο όρο 34,6 πλαισίων το καθένα, και τα δεδομένα ετικετώνονται με 3.460.213 αντικείμενα που προέρχονται από 3.576 μοντέλα mesh στο μηχανισμό του παιχνιδιού GTA-V. Αυτά αντιστοιχούν σε συνολικά 178 σεμαντικές κατηγορίες.
Ανακατασκευή Mesh και Αυτοματοποιημένη Ετικέτα
Καθώς η μελλοντική έρευνα για τα σύνολα δεδομένων είναι πιθανό να πραγματοποιηθεί σε πραγματικές εικόνες, τα mesh στο SAIL-VOS 3D παράγονται από το πλαίσιο της μηχανικής μάθησης, αντί να προέρχονται από το μηχανισμό του παιχνιδιού GTA-V.

Με ένα προγραμματιστικό και ουσιαστικά ‘ολογραφικό’ entendemento της ολόκληρης αναπαράστασης της σκηνής, η εικόνα SAIL-VOS 3D μπορεί να συνθέσει αναπαραστάσεις αντικειμένων που συνήθως κρύβονται από οκκλούσεις, όπως ο μακρινός βραχίονας του χαρακτήρα που γυρίζει εδώ, με τρόπο που θα εξαρτώταν αλλιώς από πολλά αντιπροσωπευτικά παραδείγματα σε πραγματικές εικόνες. (Κάντε κλικ για μεγέθυνση) Πηγή: https://arxiv.org/pdf/2105.08612.pdf
Καθώς κάθε αντικείμενο στο GTA-V περιέχει ένα μοναδικό ID, το SAIL-VOS ανακτά αυτά από το μηχανισμό απόδοσης χρησιμοποιώντας τη βιβλιοθήκη hook του GTA-V. Αυτό λύνει το πρόβλημα της ανακτησης του αντικειμένου εάν αυτό εξαφανιστεί προσωρινά από το πεδίο όρασης, поскольку η ετικέτα είναι σταθερή και αξιόπιστη. Υπάρχουν 162 αντικείμενα διαθέσιμα στο περιβάλλον, τα οποία οι ερευνητές χαρτογράφησαν σε αντίστοιχες κατηγορίες.
Μια Ποικιλία Σκηνών και Αντικειμένων
Πολλά από τα αντικείμενα στο μηχανισμό του GTA-V είναι κοινά στη φύση, και επομένως το SAIL-VOS περιέχει μια τυχερή 60% των κατηγοριών που υπάρχουν στο Microsoft’s MS-COCO dataset του 2014.

Το σύνολο δεδομένων SAIL-VOS περιλαμβάνει μια μεγάλη ποικιλία εσωτερικών και εξωτερικών σκηνών υπό διαφορετικές καιρικές συνθήκες, με χαρακτήρες που φορούν ποικίλα ενδύματα. (Κάντε κλικ για μεγέθυνση)
Εφαρμοσιμότητα
Για να διασφαλιστεί η συμβατότητα με την γενική τάση της έρευνας σε αυτόν τον τομέα, και να επιβεβαιωθεί ότι αυτή η συνθετική προσέγγιση μπορεί να ωφελήσει μη συνθετικά έργα, οι ερευνητές αξιολόγησαν το σύνολο δεδομένων χρησιμοποιώντας την προσεγγιστική ανίχνευσης πλαισίων που χρησιμοποιείται για το MS-COCO και το 2012 PASCAL Visual Object Classes (VOC) Challenge, με μέσο όρο ακρίβειας ως μετρικό.
Οι ερευνητές βρήκαν ότι η προ-εκπαίδευση στο σύνολο δεδομένων SAIL-VOS βελτιώνει την απόδοση του Intersection over Union (IoU) κατά 19%, με αντίστοιχη βελτίωση στην απόδοση του VideoMatch, από 55% σε 74% σε μη προηγουμένωςesehen δεδομένα.
Ωστόσο, σε περιπτώσεις ακραίας οκκλούσης, υπήρξαν περιπτώσεις όπου όλα τα παλαιότερα μέθοδοι παρέμειναν ανίκανα να αναγνωρίσουν ένα αντικείμενο ή πρόσωπο, αν και οι ερευνητές προβλέπουν ότι αυτό θα μπορούσε να επιλυθεί στο μέλλον εξετάζοντας γειτονικά πλαισιά για να καθορίσει τον λόγο για την amodal μάσκα.

Στις δύο δεξιές εικόνες, παραδοσιακές αλγόριθμοι τομείς έχουν αποτύχει να αναγνωρίσουν το θηλυκό πρόσωπο από το πολύ περιορισμένο μέρος του κεφαλιού που είναι ορατό. Μεταγενέστερες καινοτομίες με αξιολόγηση οπτικού ροή μπορεί να βελτιώσουν αυτά τα αποτελέσματα. (Κάντε κλικ για μεγέθυνση)













{kind=link}