Τεχνητή νοημοσύνη
Είναι το DALL-E 2 Απλά “Κόλλα Πράγματα Μαζί” Χωρίς Κατανόηση των Σχέσεων τους;

Một νέα έρευνα από το Πανεπιστήμιο του Χάρβαρντ υποδηλώνει ότι το DALL-E 2 της OpenAI, ένα πλαίσιο text-to-image που έχει κάνει θόρυβο, έχει σημαντικές δυσκολίες στην αναπαραγωγή ακόμη και των σχέσεων επιπέδου βρέφους μεταξύ των στοιχείων που συνθέτει σε συνθετικές φωτογραφίες, παρά την εντυπωσιακή σοφιστικέ του σε πολλά από τα αποτελέσματά του.
Οι ερευνητές πραγματοποίησαν μια μελέτη χρηστών που συμμετείχαν 169 συμμετέχοντες, οι οποίοι τους παρουσιάστηκαν εικόνες DALL-E 2 με βάση τις βασικές ανθρώπινες αρχές της σεμασιολογίας των σχέσεων, μαζί με τις κειμενικές προτροπές που τις είχαν δημιουργήσει. Όταν τους ζητήθηκε να δηλώσουν εάν οι προτροπές και οι εικόνες ήταν σχετικές, λιγότερο από το 22% των εικόνων θεωρήθηκαν ότι ήταν σχετικές με τις αντίστοιχες προτροπές, όσον αφορά τις πολύ απλές σχέσεις που το DALL-E 2 ζητήθηκε να οπτικοποιήσει.

Μια στιγμιότυπη οθόνη από τις δοκιμές που διεξήχθησαν για το νέο έγγραφο. Οι συμμετέχοντες ζητήθηκαν να επιλέξουν όλες τις εικόνες που ταιριάζουν με την προτροπή. Source: https://arxiv.org/pdf/2208.00005.pdf
Τα αποτελέσματα δείχνουν επίσης ότι η φαινομενική ικανότητα του DALL-E να συνδέει διαφορετικά στοιχεία μπορεί να μειωθεί καθώς αυτά τα στοιχεία γίνονται λιγότερο πιθανό να έχουν συμβεί στο πραγματικό training dataset που τροφοδοτεί το σύστημα.
Για παράδειγμα, εικόνες για την προτροπή ‘παιδί αγγίζει ένα μπολ’ έλαβαν ποσοστό συμφωνίας 87% (δηλαδή οι συμμετέχοντες κλικάρουν στις περισσότερες εικόνες ως σχετικές με την προτροπή), ενώ παρόμοιες φωτορεαλιστικές αναπαραγωγές του ‘ένα πίθηκος αγγίζει ένα ιγκουάνα’ έλαβαν μόνο 11% συμφωνίας:


Το DALL-E δυσκολεύεται να απεικονίσει το απίθανο γεγονός του ‘ένα πίθηκος αγγίζει ένα ιγκουάνα’, πιθανώς επειδή είναι ασυνήθιστο, πιο πιθανό μη υπάρχον, στη training set.
Στο δεύτερο παράδειγμα, το DALL-E 2 συχνά λαμβάνει λάθος το μέγεθος και ακόμη και το είδος, πιθανώς λόγω της έλλειψης πραγματικών εικόνων που απεικονίζουν这一 γεγονός. Από την άλλη πλευρά, είναι εύλογο να περιμένουμε ένα μεγάλο αριθμό training φωτογραφιών που σχετίζονται με παιδιά και φαγητό, και ότι αυτή η υπο-κατηγορία/κλάση είναι καλά αναπτυγμένη.
Η δυσκολία του DALL-E στην τοποθέτηση άκρως αντιθετικών στοιχείων εικόνας υποδηλώνει ότι το κοινό είναι目前 τόσο εκπληκτικό από τις φωτορεαλιστικές και ευρέως ερμηνευτικές ικανότητες του συστήματος, ώστε να μην έχει αναπτύξει ένα κριτικό μάτι για τις περιπτώσεις όπου το σύστημα έχει αποτελεσματικά μόνο ‘κολλήσει’ ένα στοιχείο δραματικά σε ένα άλλο, όπως σε αυτά τα παραδείγματα από τον επίσημο ιστότοπο του DALL-E 2:

Σύνθεση κολλήματος, από τα επίσημα παραδείγματα για DALL-E 2. Source: https://openai.com/dall-e-2/
Το νέο έγγραφο αναφέρει*:
‘Η σχεσιακή κατανόηση είναι ένα θεμελιώδες συστατικό της ανθρώπινης νοημοσύνης, το οποίο εκδηλώνεται νωρίς στην ανάπτυξη, και υπολογίζεται γρήγορα και αυτόματα στην ανίχνευση.
‘Η δυσκολία του DALL-E 2 με ακόμη και τις βασικές χωρικές σχέσεις (όπως in, on, under) υποδηλώνει ότι ό,τι έχει μάθει, δεν έχει ακόμη μάθει τους τύπους αναπαραστάσεων που επιτρέπουν στους ανθρώπους να δομήσουν τόσο ευέλικτα και ανθεκτικά τον κόσμο.
‘Μια άμεση ερμηνεία αυτής της δυσκολίας είναι ότι συστήματα όπως το DALL-E 2 δεν έχουν ακόμη σχεσιακή σύνθεση.’
Οι συγγραφείς προτείνουν ότι συστήματα κειμενο-οδηγούμενης γεννήτριας εικόνας όπως η σειρά DALL-E θα μπορούσαν να επωφεληθούν από την αξιοποίηση αλγορίθμων κοινούς στην ρομποτική, οι οποίοι μοντελοποιούν ταυτότητες και σχέσεις ταυτόχρονα, λόγω της ανάγκης του πράκτορα να αλληλεπιδρά πραγματικά με το περιβάλλον αντί να φτιάχνει απλώς μια σύνθεση διαφορετικών στοιχείων.
Μια τέτοια προσέγγιση, με τίτλο CLIPort, χρησιμοποιεί τον ίδιο CLIP μηχανισμό που χρησιμεύει ως στοιχείο αξιολόγησης ποιότητας στο DALL-E 2:
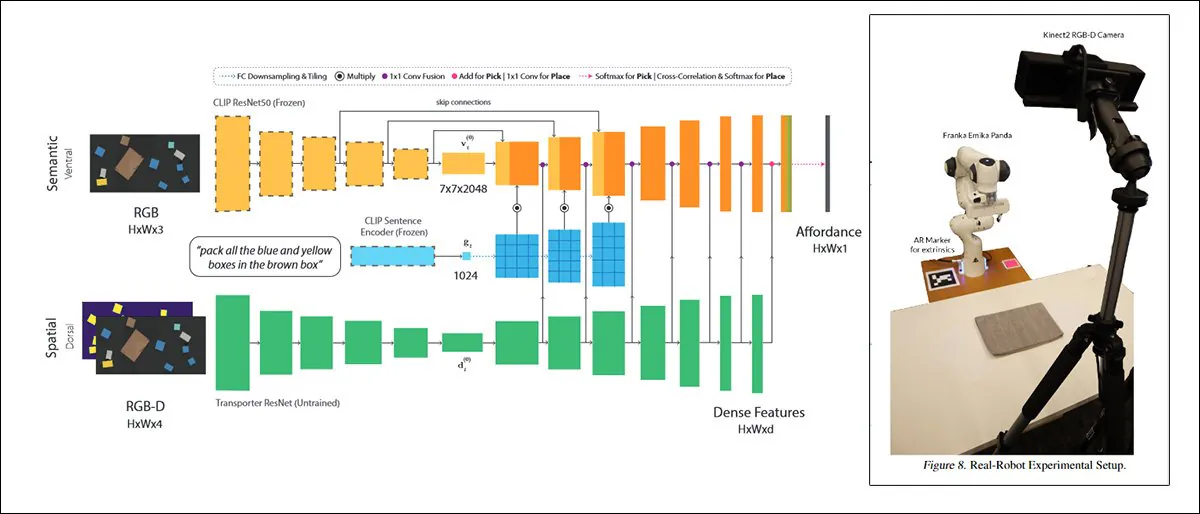
CLIPort, μια συνεργασία του 2021 μεταξύ του Πανεπιστημίου του Ουάσιγκτον και της NVIDIA, χρησιμοποιεί CLIP σε ένα контекστό τόσο πρακτικό που τα συστήματα που εκπαιδεύονται σε αυτό πρέπει αναγκαστικά να αναπτύξουν μια κατανόηση των φυσικών σχέσεων, μια мотιβασία που λείπει στο DALL-E 2 και σε παρόμοια ‘φανταστικά’ πλαίσια σύνθεσης εικόνας. Source: https://arxiv.org/pdf/2109.12098.pdf
Οι συγγραφείς προτείνουν επίσης ότι ‘ένα άλλο πιθανό βελτίωση’ μπορεί να είναι για την αρχιτεκτονική των συστημάτων σύνθεσης εικόνας όπως το DALL-E να ενσωματώσει πολλαπλασιαστικές επιδράσεις σε ένα μόνο επίπεδο υπολογισμού, επιτρέποντας τον υπολογισμό των σχέσεων με τρόπο που εμπνέεται από τις ικανότητες επεξεργασίας πληροφοριών βιολογικών συστημάτων.
Το νέο έγγραφο έχει τίτλο Δοκιμή της Σχεσιακής Κατανόησης στη Κειμενο-οδηγούμενη Γεννήτρια Εικόνας, και προέρχεται από τους Colin Conwell και Tomer D. Ullman στο Τμήμα Ψυχολογίας του Χάρβαρντ.
Πέρα από την Πρώιμη Κριτική
Σχολιάζοντας το ‘θάμβος’ πίσω από τον ρεαλισμό και την ακεραιότητα της έξοδου του DALL-E 2, οι συγγραφείς σημειώνουν προηγούμενα έργα που έχουν βρει ελαττώματα στα γεννητικά συστήματα εικόνας τύπου DALL-E.
Τον Ιούνιο του έτους, το Πανεπιστήμιο Μπέρκλεϊ της Καλιφόρνιας σημείωσε τη δυσκολία του DALL-E στην αντιμετώπιση των ανακλάσεων και των σκιών· το ίδιο μήνα, μια μελέτη από την Κορέα ερεύνησε την ‘μοναδικότητα’ και την πρωτοτυπία της έξοδου του DALL-E 2 με κριτικό μάτι· μια προκαταρκτική ανάλυση των εικόνων DALL-E 2, λίγο μετά την εκκίνηση, από το NYU και το Πανεπιστήμιο του Τέξας, βρήκε διάφορα προβλήματα με τη σύνθεση και άλλα βασικά στοιχεία στις εικόνες DALL-E 2· και τον προηγούμενο μήνα, μια κοινή εργασία μεταξύ του Πανεπιστημίου του Ιλινόις και του MIT πρότεινε προτάσεις για αρχιτεκτονικές βελτιώσεις σε τέτοια συστήματα όσον αφορά τη σύνθεση.
Οι ερευνητές σημειώνουν επίσης ότι οι λουμινάρες του DALL-E όπως ο Aditya Ramesh έχουν παραδεχθεί τα προβλήματα του πλαισίου με τη δέσμευση, το σχετικό μέγεθος, το κείμενο και άλλες προκλήσεις.
Οι dévelopπεurs πίσω από το σύστημα σύνθεσης εικόνας Imagen της Google έχουν επίσης προτείνει DrawBench, ένα νέο σύστημα σύγκρισης που αξιολογεί την ακρίβεια εικόνας σε διάφορα πλαίσια με διαφορετικά μετρικά.
Αντίθετα, οι συγγραφείς του νέου εγγράφου προτείνουν ότι ένα καλύτερο αποτέλεσμα μπορεί να επιτευχθεί με την τοποθέτηση της ανθρώπινης εκτίμησης – αντί για αλγοριθμικές μετρικές – ενάντια στις εικόνες, για να καθορίσει πού βρίσκονται τα弱ά σημεία και τι μπορεί να γίνει για να τα μετριάσει.
Η Μελέτη
Για αυτόν τον σκοπό, το νέο έργο βασίζεται σε ψυχολογικές αρχές και επιδιώκει να απομακρύνει την τρέχουσα έξαρση του ενδιαφέροντος στη μηχανική προτροπής (η οποία, στην πραγματικότητα, είναι μια παραίτηση από τα ελαττώματα του DALL-E 2, ή οποιοδήποτε συγκρίσιμο σύστημα), για να ερευνήσει και πιθανώς να αντιμετωπίσει τις περιορισμούς που κάνουν τέτοιες ‘γύρους’ απαραίτητους.
Το έγγραφο αναφέρει:
‘Η παρούσα εργασία επικεντρώνεται σε ένα σύνολο 15 βασικών σχέσεων που περιγράφηκαν προηγουμένως, εξετάστηκαν ή προτάθηκαν στη γνωστική, αναπτυξιακή ή γλωσσική βιβλιογραφία. Το σύνολο περιλαμβάνει τόσο εδαφικές χωρικές σχέσεις (π.χ. ’X πάνω σε Y’), όσο και πιο αφηρημένες αγεντικές σχέσεις (π.χ. ’X βοηθά Y’).
‘Οι προτροπές είναι σκόπιμα απλές, χωρίς复雑ότητα ή πλούτο. Δηλαδή, αντί για μια προτροπή όπως ‘ένα γαϊδούρι και ένα πιθήκος παίζουν ένα παιχνίδι. Το γαϊδούρι κρατάει μια σχοινί σε ένα άκρο, το πιθήκος κρατάει στο άλλο. Το γαϊδούρι κρατάει το σχοινί στο στόμα του. Ένα γάτο τρέχει πάνω από το σχοινί’, χρησιμοποιούμε ‘ένα μποξ πάνω σε ένα μαχαίρι’.
‘Η απλότητα εξακολουθεί να καταλαμβάνει ένα ευρύ φάσμα σχέσεων από διάφορες υπο-κατηγορίες της ανθρώπινης ψυχολογίας, και κάνει τις πιθανές αποτυχίες του μοντέλου πιο εντυπωσιακές και συγκεκριμένες.’
Για τη μελέτη τους, οι συγγραφείς προσέλαβαν 169 συμμετέχοντες από το Prolific, όλοι τους τοποθετημένοι στις Ηνωμένες Πολιτείες, με μέσο όρο ηλικίας 33 ετών, και 59% γυναίκες.
Οι συμμετέχοντες τους παρουσιάστηκαν 18 εικόνες οργανωμένες σε ένα πλέγμα 3×6 με την προτροπή στην κορυφή, και μια προειδοποίηση στο κάτω μέρος που αναφέρει ότι όλες, κάποιες ή καμία από τις εικόνες μπορεί να έχουν δημιουργηθεί από την προεβλεπόμενη προτροπή, και τους ζητήθηκε να επιλέξουν τις εικόνες που πιστεύουν ότι σχετίζονται με αυτόν τον τρόπο.
Οι εικόνες που παρουσιάστηκαν στους συμμετέχοντες βασίζονταν στη γλωσσική, αναπτυξιακή και γνωστική βιβλιογραφία, αποτελούμενη από ένα σύνολο οκτώ φυσικών και επτά ‘αγεντικών’ σχέσεων (αυτό θα γίνει σαφές σε λίγο).
Φυσικές Σχέσεις
σε, πάνω, κάτω, καλύπτοντας, κοντά, αποκρύπτονται από, κρέμονται πάνω, και δένεται σε.
Αγεντικές Σχέσεις
πوش, ρίχνει, αγγίζει, χτυπά, κλωτσά, βοηθά, και εμποδίζει.
Όλες αυτές οι σχέσεις προέρχονται από τις προηγούμενες μη-CS περιοχές μελέτης.
Δώδεκα οντότητες αποκτήθηκαν έτσι για χρήση στις προτροπές, με έξι αντικείμενα και έξι πράκτορες:
Αντικείμενα
μποξ, κύλινδρος, μαξιλάρι, μπολ, φλιτζάνι, και μαχαίρι.
Πράκτορες
άνθρωπος, γυναίκα, παιδί, ρομπότ, πίθηκος, και ιγκουάνα.
(Οι ερευνητές παραδέχονται ότι η συμπερίληψη του ιγκουάνα, όχι ένα κύριο σημείο της ξηράς κοινωνιολογικής ή ψυχολογικής έρευνας, ήταν ‘ένα δώρο’)
Για κάθε σχέση, πέντε διαφορετικές προτροπές δημιουργήθηκαν με τυχαία δειγματοληψία δύο οντοτήτων πέντε φορές, με αποτέλεσμα 75 συνολικά προτροπές, από τις οποίες το DALL-E 2 και για τις οποίες οι αρχικές 18 εικόνες που παρουσιάστηκαν, χωρίς να επιτρέπεται καμία παραλλαγή ή δεύτερη ευκαιρία.
Αποτελέσματα
Το έγγραφο αναφέρει*:
‘Οι συμμετέχοντες σε μέσο όρο ανέφεραν ένα χαμηλό ποσοστό συμφωνίας μεταξύ των εικόνων του DALL-E 2 και των προτροπών που χρησιμοποιήθηκαν για τη δημιουργία τους, με μέσο όρο 22,2% [18,3, 26,6] σε 75 διαφορετικές προτροπές.
‘Αγεντικές προτροπές, με μέσο όρο 28,4% [22,8, 34,2] σε 35 προτροπές, παρήγαγαν υψηλότερη συμφωνία από τις φυσικές προτροπές, με μέσο όρο 16,9% [11,9, 23,0] σε 40 προτροπές.’

Αποτελέσματα από τη μελέτη. Οι σημείες σε μαύρο υποδηλώνουν όλες τις προτροπές, με κάθε σημείο να αντιστοιχεί σε μια μεμονωμένη προτροπή, και το χρώμα διαχωρίζει ανάλογα με το αν το αντικείμενο της προτροπής ήταν αγεντικό ή φυσικό (δηλαδή ένα αντικείμενο).
Για να συγκρίνουν τη διαφορά μεταξύ της ανθρώπινης και αλγοριθμικής αντίληψης των εικόνων, οι ερευνητές έτρεξαν τις αναπαραγωγές τους μέσω του ανοιχτού κώδικα ViT-L/14 του CLIP. Με τη μέση των βαθμολογιών, βρήκαν μια ‘μετριάσταση σχέση’ μεταξύ των δύο συνόλων αποτελεσμάτων, το οποίο είναι ίσως εκπληκτικό,考虑οντας το βαθμό στον οποίο το CLIP συμβάλλει στη δημιουργία των εικόνων.

Αποτελέσματα της σύγκρισης CLIP (ViT-L/14) με τις ανθρώπινες απαντήσεις.
Οι ερευνητές προτείνουν ότι άλλοι μηχανισμοί στην αρχιτεκτονική, ίσως σε συνδυασμό με μια τυχαία πλεονεξία (ή έλλειψη) δεδομένων στη training set, μπορεί να εξηγήσουν τον τρόπο με τον οποίο το CLIP μπορεί να αναγνωρίσει τις αδυναμίες του DALL-E χωρίς να μπορεί, σε όλες τις περιπτώσεις, να κάνει κάτι σημαντικό για το πρόβλημα.
Οι συγγραφείς καταλήγουν στο συμπέρασμα ότι το DALL-E 2 έχει μόνο μια ονομαστική ικανότητα, αν υπάρχει, να αναπαράγει εικόνες που ενσωματώνουν σχεσιακή κατανόηση, ένα θεμελιώδες στοιχείο της ανθρώπινης νοημοσύνης που αναπτύσσεται σε μας πολύ sớmο.
‘Η ιδέα ότι συστήματα όπως το DALL-E 2 δεν έχουν σύνθεση μπορεί να φανεί ως έκπληξη σε οποιονδήποτε που έχει δει τις εντυπωσιακές και λογικές απαντήσεις του DALL-E 2 σε προτροπές όπως ‘μια καρτούν ενός μωρού νταϊκόν ραδίκι σε ένα τούτο γυαλί περπατώντας ένα πούδι’. Προτροπές όπως αυτές συχνά παράγουν μια λογική προσέγγιση μιας συνθετικής концепції, με όλα τα μέρη της προτροπής παρόντα, και παρόντα στη σωστή θέση.
‘Η σύνθεση, ωστόσο, δεν είναι μόνο η ικανότητα να κολλήσετε πράγματα μαζί – ακόμη και πράγματα που μπορεί να μην έχετε παρατηρήσει μαζί πριν. Η σύνθεση απαιτεί μια κατανόηση των κανόνων που δένουν τα πράγματα μαζί. Οι σχέσεις είναι τέτοιες κανόνες.’
Ο Άνθρωπος Δαγκώνει τον Τ-Ρεξ
Γνώμη Όπως η OpenAI ενσωματώνει ένα μεγαλύτερο αριθμό χρηστών μετά τη πρόσφατη βητα-μονοποίηση του DALL-E 2, και από τότε πρέπει να πληρώσετε για τις περισσότερες γεννήσεις, οι αδυναμίες του DALL-E 2 στη σχεσιακή κατανόηση μπορεί να γίνουν πιο εμφανείς καθώς κάθε ‘αποτυχημένη’ προσπάθεια έχει ένα οικονομικό βάρος, και δεν υπάρχουν επιστροφές.
Εκείνοι που έλαβαν μια πρόσκληση λίγο νωρίτερα είχαν χρόνο (και, μέχρι πρόσφατα, μεγαλύτερη ευχέρεια να παίξουν με το σύστημα) να παρατηρήσουν κάποια από τα ‘σχεσιακά σφάλματα’ που μπορεί να εκπέμψει το DALL-E 2.
Για παράδειγμα, για einen φαν του Γιουράσικ Παρκ, είναι πολύ δύσκολο να πάρει έναν δεινόσαυρο να κυνηγάει ένα άτομο στο DALL-E 2, ακόμη και αν η έννοια του ‘κυνηγιού’ δεν φαίνεται να είναι στο σύστημα λογοκρισίας του DALL-E 2, και ακόμη και αν η μακρά ιστορία των δεινοσαύρων στις ταινίες πρέπει να παρέχει άφθονες training παραδείγματα (τουλάχιστον στη μορφή τρέιλερ και φωτογραφιών δημοσιότητας) για αυτή τη διαδικασία.

Μια τυπική απάντηση του DALL-E 2 στην προτροπή ‘Μια χρωματική φωτογραφία ενός T-Rex που κυνηγάει ένα άτομο σε ένα δρόμο’. Source: DALL-E 2
Έχω βρει ότι οι εικόνες είναι τυπικές για παραλλαγές της προτροπής ‘[δεινόσαυρος] κυνηγάει [ένα άτομο]’ , και ότι καμία επέκταση της προτροπής δεν μπορεί να κάνει τον T-Rex να συμμορφωθεί.
Ίσως το μόνο training δεδομένων που το DALL-E 2 θα μπορούσε να έχει πρόσβαση ήταν στη γραμμή του ‘άνθρωπος πολεμάει δεινόσαυρο’, από φωτογραφίες δημοσιότητας για παλαιότερες ταινίες όπως Ένα Εκατομμύριο Χρόνια Πρίν (1966), και ότι η φήμη πτήσης του Jeff Goldblum από τον βασιλιά των θηρίων είναι απλώς ένα outlier σε αυτό το μικρό τμήμα δεδομένων.
* Η μετατροπή των εσωτερικών αναφορών των συγγραφέων σε υπερσύνδεσμους.
Πρώτη δημοσίευση 4η Αυγούστου 2022.












