Τεχνητή νοημοσύνη
Η Adobe Research Επεκτείνει τη Διαχωρισμένη Επεξεργασία Προσώπου GAN

Δεν είναι δύσκολο να κατανοήσετε γιατί η εντοπισμός είναι ένα πρόβλημα στη σύνθεση εικόνων, επειδή είναι συχνά ένα πρόβλημα σε άλλους τομείς της ζωής. Για παράδειγμα, είναι πολύ πιο δύσκολο να αφαιρέσετε το κούρκουμα από ένα καリー παρά να απορρίψετε το πίκλ στο μπέργκερ, και είναι σχεδόν αδύνατο να αφαιρέσετε τη γλυκύτητα από ένα ποτήρι καφέ. Κάποια πράγματα έρχονται σε πακέτο.
Ομοίως, ο εντοπισμός είναι ένα εμπόδιο για τις αρχιτεκτονικές σύνθεσης εικόνων που θα ήθελαν ιδανικά να分离 διαφορετικά χαρακτηριστικά και έννοιες όταν χρησιμοποιούν τη μηχανική μάθηση για να δημιουργήσουν ή να επεξεργαστούν πρόσωπα (ή σκύλους, πλοία, ή οποιοδήποτε άλλο τομέα).
Εάν μπορούσατε να分离 στοιχεία όπως ηλικία, φύλο, χρώμα μαλλιών, χρωματισμός δέρματος, σύνθεση, και così κατω, θα είχατε τις αρχές μιας πραγματικής οργανικότητας και ευελιξίας σε ένα πλαίσιο που θα μπορούσε να δημιουργήσει και να επεξεργαστεί εικόνες προσώπου σε ένα πραγματικά λεπτομερές επίπεδο, χωρίς να σέρνει ανεπιθύμητους “επιβατές” σε αυτές τις μετατροπές.

Στην μέγιστη εντοπισμού (πάνω αριστερά), όλα που μπορείτε να κάνετε είναι να αλλάξετε την εικόνα ενός学会 GAN δικτύου σε μια εικόνα ενός άλλου ανθρώπου.
Αυτό είναι αποτελεσματικά η χρήση της τελευταίας τεχνολογίας AI υπολογιστικής όρασης για να επιτύχει κάτι που είχε λυθεί με άλλα μέσα πάνω από τριάντα χρόνια πριν.
Με κάποιο βαθμό διαχωρισμού (‘Μέσο Διαχωρισμού’ στην προηγούμενη εικόνα), είναι δυνατό να thựcτούνται αλλαγές στυλ όπως το χρώμα μαλλιών, η έκφραση, η εφαρμογή κοσμητικών και η περιορισμένη περιστροφή κεφαλής, μεταξύ άλλων.

Source: FEAT: Face Editing with Attention, February 2022, https://arxiv.org/pdf/2202.02713.pdf
Υπήρχε ένας αριθμός απόπειρων τα τελευταία δύο χρόνια για να δημιουργηθούν διαδραστικά περιβάλλοντα επεξεργασίας προσώπου που επιτρέπουν στον χρήστη να αλλάξει χαρακτηριστικά προσώπου με 滑塾 και άλλες παραδοσιακές διασυνδέσεις, ενώ διατηρούνται τα βασικά χαρακτηριστικά του στόχου προσώπου όταν γίνονται προσθήκες ή αλλαγές. Ωστόσο, αυτό αποδείχθηκε một πρόκληση λόγω του υποκείμενου εντοπισμού χαρακτηριστικών/στυλ στον.latent χώρο του GAN.
Για παράδειγμα, το γυαλιά χαρακτηριστικό είναι συχνά συνυφασμένο με το ηλικία χαρακτηριστικό, που σημαίνει ότι η προσθήκη γυαλιών μπορεί να “γεράσει” το πρόσωπο, ενώ η αλλαγή της ηλικίας μπορεί να προσθέσει γυαλιά, ανάλογα με το βαθμό εφαρμογής διαχωρισμού υψηλού επιπέδου χαρακτηριστικών (δείτε ‘Δοκιμές’ παρακάτω για παραδείγματα).
Τα πιο αξιοσημείωτα, ήταν σχεδόν αδύνατο να αλλάξετε το χρώμα μαλλιών και άλλα χαρακτηριστικά μαλλιών χωρίς να ξαναυπολογιστούν τα μαλλιά και η διάθεσή τους, που δίνει μια ‘σφυρίγματα’, μεταβατική επίδραση.

Source: InterFaceGAN Demo (CVPR 2020), https://www.youtube.com/watch?v=uoftpl3Bj6w
Latent-to-Latent GAN Traversal
Μια νέα έρευνα της Adobe εισήχθη για WACV 2022 προσφέρει μια νέα προσέγγιση σε αυτά τα υποκείμενα προβλήματα σε ένα έγγραφο με τίτλο Latent to Latent: A Learned Mapper for Identity Preserving Editing of Multiple Face Attributes in StyleGAN-generated Images.

Supplemental material from the paper Latent to Latent: A Learned Mapper for Identity Preserving Editing of Multiple Face Attributes in StyleGAN-generated Images. Here we see that base characteristics in the learned face are not dragged into unrelated changes. See full video embed at end of article for better detail and resolution. Source: https://www.youtube.com/watch?v=rf_61llRH0Q
Το έγγραφο είναι υπό την ηγεσία του Siavash Khodadadeh, Επιστημονικού Ερευνητή της Adobe, μαζί με τέσσερις άλλους ερευνητές της Adobe και einen ερευνητή από το Τμήμα Πληροφορικής του Πανεπιστημίου της Κεντρικής Φλόριντα.
Το κομμάτι είναι ενδιαφέρον κυρίως επειδή η Adobe λειτουργεί σε αυτόν τον χώρο για κάποιο χρόνο, και είναι εύκολο να φανταστεί αυτή η λειτουργικότητα να εισέρχεται σε ένα έργο της Creative Suite τα επόμενα χρόνια. Ωστόσο, η αρχιτεκτονική που δημιουργήθηκε για το έργο ακολουθεί μια διαφορετική προσέγγιση για τη διατήρηση της οπτικής ακεραιότητας σε einen GAN επεξεργαστή προσώπου ενώ γίνονται αλλαγές.
Οι συγγραφείς δηλώνουν:
‘[Εμείς] εκπαιδεύουμε ένα νευρωνικό δίκτυο για να thựcτούν μια μετατροπή latent-to-latent που βρίσκει την κωδικοποίηση latent που αντιστοιχεί στην εικόνα με την αλλαγή χαρακτηριστικού. Καθώς η τεχνική είναι one-shot, δεν βασίζεται σε μια γραμμική ή μη γραμμική τροχιά της σταδιακής αλλαγής των χαρακτηριστικών.
‘Με την εκπαίδευση του δικτύου από το τέλος προς το άνω στο πλήρες πλήθος της γεννήτριας, το σύστημα μπορεί να προσαρμοστεί στους χώρους latent των αρχιτεκτονικών γεννητριών. Ιδιότητες, όπως η διατήρηση της ταυτότητας του προσώπου, μπορούν να κωδικοποιηθούν στη μορφή της εκπαίδευσης απωλειών.
‘Μόλις το δίκτυο latent-to-latent εκπαιδευτεί, μπορεί να ξαναχρησιμοποιηθεί για τυχαίες εικόνες χωρίς επανεκπαίδευση.’
Αυτό το τελευταίο σημαίνει ότι η προτεινόμενη αρχιτεκτονική φτάνει με τον τελικό χρήστη σε μια ολοκληρωμένη κατάσταση. Πρέπει ακόμα να τρέξει ένα νευρωνικό δίκτυο σε τοπικούς πόρους, αλλά νέες εικόνες μπορούν να “πεταχτούν” και να είναι έτοιμες για αλλαγή σχεδόν αμέσως,既然 το πλαίσιο είναι αποσυνδεμένο αρκετά για να μην χρειάζεται περαιτέρω εκπαίδευση ειδικά για την εικόνα.
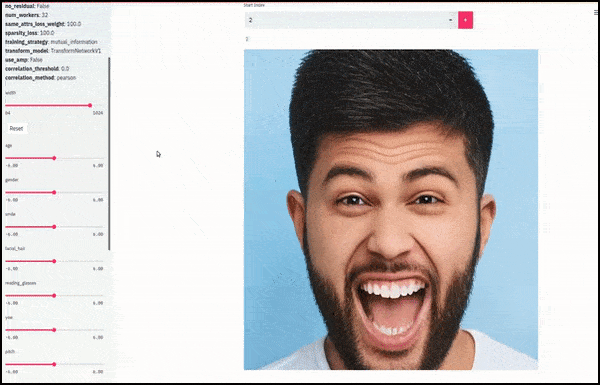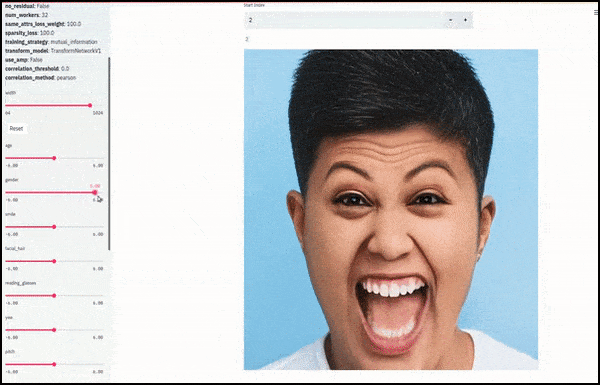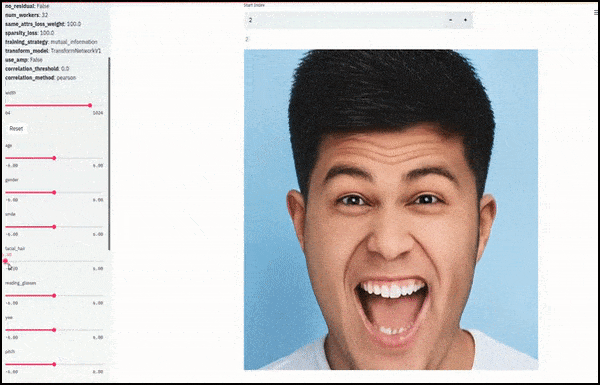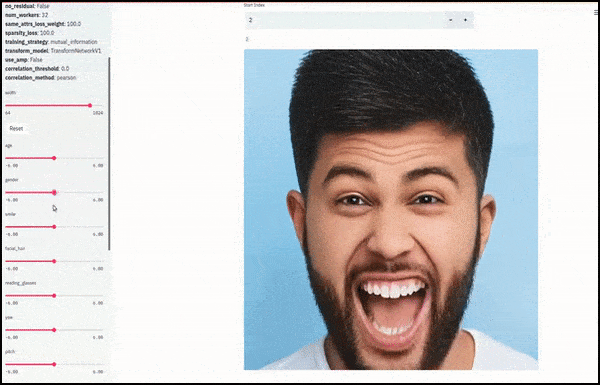
Γένος και γενειάδα αλλαγμένα ως 滑塾 που σχεδιάζουν τυχαίες και αυθαίρετες διαδρομές μέσω του χώρου latent, όχι μόνο ‘σκούπισμα μεταξύ τερματικών σημείων’. Δείτε το βίντεο στο τέλος του άρθρου για περισσότερες μετατροπές σε καλύτερη ανάλυση.
Μіж τους κύριους επιτεύγματα της εργασίας είναι η ικανότητα του δικτύου να ‘παγώσει’ ταυτότητες στον χώρο latent με την αλλαγή μόνο του χαρακτηριστικού σε ένα στόχο διανυσμάτων και να παρέχει ‘ορθωτικές όρους’ που διατηρούν τις ταυτότητες που μετατρέπονται.
Ουσιαστικά, το προτεινόμενο δίκτυο είναι ενσωματωμένο σε μια ευρύτερη αρχιτεκτονική που διευθύνει όλα τα επεξεργασμένα στοιχεία, τα οποία περνούν από προ-εκπαιδευμένα στοιχεία με παγωμένα βάρη που δεν θα παράγουν ανεπιθύμητες πλευρικές επιπτώσεις στις μετατροπές.
Καθώς η διαδικασία εκπαίδευσης βασίζεται σε τριάδες που μπορούν να παραχθούν είτε από μια αρχική εικόνα (υπό GAN inversion) είτε από μια υπάρχουσα αρχική κωδικοποίηση latent, η ολόκληρη διαδικασία εκπαίδευσης είναι ανεπίσημη, με τις σιωπηλές ενέργειες του συνηθισμένου εύρους συστημάτων ετικέτας και επιμέλειας σε τέτοια συστήματα αποτελούνται στην αρχιτεκτονική. Στην πραγματικότητα, το νέο σύστημα χρησιμοποιεί off-the-shelf αναγνωριστές χαρακτηριστικών:
‘[Το] πλήθος των χαρακτηριστικών που το δίκτυό μας μπορεί να ελέγξει ανεξάρτητα είναι μόνο περιορισμένο από τις ικανότητες του αναγνωριστικού(-ων) – εάν έχεις einen αναγνωριστικό για einen χαρακτηριστικό, podemos να προσθέσουμε το χαρακτηριστικό σε τυχαία πρόσωπα. Σε наших πειράματα, εκπαιδεύσαμε το δίκτυο latent-to-latent να επιτρέψει την προσαρμογή 35 διαφορετικών χαρακτηριστικών προσώπου, περισσότερα από οποιοδήποτε προηγούμενο προσεγγίσιμο.’
Το σύστημα ενσωματώνει έναν επιπλέον φραγμό κατά των ανεπιθύμητων ‘πλευρικών’ μετατροπών: στην απουσία μιας αίτησης για αλλαγή χαρακτηριστικού, το δίκτυο latent-to-latent θα χαρτογραφήσει einen διανυσματικό latent σε αυτόν, αυξάνοντας περαιτέρω τη σταθερή διατήρηση της ταυτότητας του στόχου.
Facial Recognition
Ένα επαναλαμβανόμενο πρόβλημα με GAN και encoder/decoder-βασισμένες επεξεργαστές προσώπου τα τελευταία χρόνια ήταν ότι οι εφαρμοζόμενες μετατροπές τείνουν να υποβαθμίσουν την ομοιότητα. Για να καταπολεμήσουν αυτό, το έργο της Adobe χρησιμοποιεί einen ενσωματωμένο δίκτυο αναγνώρισης προσώπου που ονομάζεται FaceNet ως δискριμινατέρ.

Project architecture, see lower mid-left for inclusion of FaceNet. Source: Latent to Latent: A Learned Mapper for Identity Preserving Editing of Multiple Face Attributes in StyleGAN-generated Images, OpenAccess.
(Σε προσωπικό σημείωμα, αυτό φαίνεται μια ενθαρρυντική κίνηση προς την ολοκλήρωση των τυπικών συστημάτων αναγνώρισης προσώπου και ακόμη και αναγνώρισης έκφρασης σε γεννητικά δίκτυα, ομολογουμένως ο καλύτερος τρόπος για να υπερβεί η τυφλή pixel>pixel mapping που κυριαρχεί στις τρέχουσες αρχιτεκτονικές deepfake με το κόστος της πιστότητας έκφρασης και άλλων σημαντικών τομέων στον τομέα της γεννήτριας προσώπου.)
Access All Areas in the Latent Space
Μια άλλη εντυπωσιακή λειτουργία του πλαισίου είναι η ικανότητά του να ταξιδεύει αυθαίρετα μεταξύ πιθανών μετατροπών στον χώρο latent, κατά τη θέληση του χρήστη. Πολλά προηγούμενα συστήματα που παρείχαν διερευνητικά διεπαφές άφηναν συχνά τον χρήστη να “σκουπίζει” μεταξύ σταθερών χρονοσειρών μετατροπής χαρακτηριστικών – εντυπωσιακό, αλλά συχνά μια γραμμική ή προscriptive εμπειρία.

From Improving GAN Equilibrium by Raising Spatial Awareness: here the user scrubs through a range of potential transition points between two latent space locations, but within the confines of pre-trained locations in the latent space. To apply other kinds of transformation based on the same material, reconfiguration and/or retraining is necessary. Source: https://genforce.github.io/eqgan/
Επιπλέον, ο χρήστης μπορεί επίσης να “παγώσει” στοιχεία που θέλει να διατηρηθούν κατά τη διάρκεια της διαδικασίας μετατροπής. Με αυτόν τον τρόπο, ο χρήστης μπορεί να διασφαλίσει ότι (για παράδειγμα) τα φόντα δεν θα μετακινηθούν, ή ότι τα μάτια θα παραμείνουν ανοιχτά ή κλειστά.
Data
Το δίκτυο αναγνώρισης χαρακτηριστικών εκπαιδεύτηκε σε τρία δίκτυα: FFHQ, CelebAMask-HQ, και ένα τοπικό, GAN-γεννημένο δίκτυο που λήφθηκε με δειγματοληψία 400.000 διανυσμάτων από τον χώρο Z του StyleGAN-V2.
Εξω-κατανομή (OOD) εικόνες φιλτράρονται, και τα χαρακτηριστικά εξάγονται χρησιμοποιώντας το Face API της Microsoft, με το αποτέλεσμα σύνολο να χωρίζεται 90/10, αφήνοντας 721.218 εικόνες εκπαίδευσης και 72.172 εικόνες δοκιμής για σύγκριση.
Testing
Αν και το πειραματικό δίκτυο ήταν αρχικά ρυθμισμένο για να διαχειριστεί 35 πιθανές μετατροπές, αυτές μειώθηκαν σε οκτώ για να πραγματοποιηθούν αναλογικές δοκιμές κατά των συγκρίσιμων πλαισίων InterFaceGAN, GANSpace, και StyleFlow.
Τα οκτώ επιλεγμένα χαρακτηριστικά ήταν Ηλικία, Φαλάκρα, Γενειάδα, Έκφραση, Φύλο, Γυαλιά, Πίτσα, και Yaw. Ήταν απαραίτητο να αναμορφωθούν τα ανταγωνιστικά πλαισια για κάποια από τα οκτώ χαρακτηριστικά που δεν είχαν προβλεφθεί στην αρχική διανομή, όπως η προσθήκη φαλάκρας και γενειάδας στο InterFaceGAN.
Όπως ήταν αναμενόμενο, ένα μεγαλύτερο επίπεδο εντοπισμού συνέβη στις ανταγωνιστικές αρχιτεκτονικές. Για παράδειγμα, σε ένα τεστ, το InterFaceGAN και το StyleFlow άλλαξαν το φύλο του υποκειμένου όταν ζητήθηκε να εφαρμοστεί ηλικία:

Two of the competing frameworks rolled a gender change into the ‘age’ transformation, also changing hair color without direct bidding of the user.
Επιπλέον, δύο από τους ανταγωνιστές βρήκαν ότι τα γυαλιά και η ηλικία είναι αδιαχώριστα χαρακτηριστικά:

Glasses and hair color change thrown in at no extra charge!
Δεν είναι μια ομοιόμορφη νίκη για την έρευνα: όπως μπορείτε να δείτε στο συνημμένο βίντεο στο τέλος του άρθρου, το πλαίσιο είναι το λιγότερο αποτελεσματικό όταν προσπαθεί να εξαγάγει διαφορετικές γωνίες (yaw), ενώ το GANSpace έχει ένα καλύτερο γενικό αποτέλεσμα για ηλικία και την εφαρμογή γυαλιών. Το πλαίσιο latent-to-latent έδεσε με το GANSpace και το StyleFlow όσον αφορά την προσθήκη πίτσας (γώνια κεφαλής).

Results calculated based on a calibration of the MTCNN face detector. Lower results are better.
Για περαιτέρω λεπτομέρειες και καλύτερη ανάλυση των παραδειγμάτων, δείτε το συνημμένο βίντεο στο τέλος του άρθρου.
https://www.youtube.com/watch?v=rf_61llRH0Q
Πρώτη δημοσίευση 16ης Φεβρουαρίου 2022.












