Sundhedsvæsen
Populær COVIDx-datasæt kritiseret af britiske forskere
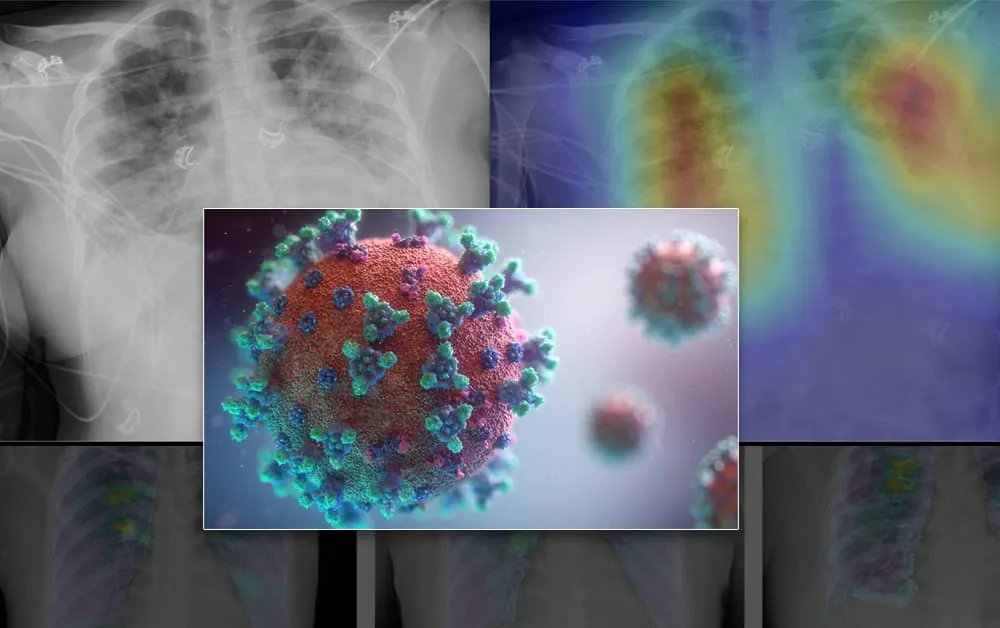
Et forskningskonsortium fra Storbritannien har rettet kritik mod omfanget af den videnskabelige tillid, der er placeret i open source-datasæt, der bruges til computerbaseret analyse af COVID-19-patienters bryst-røntgenbilleder, med fokus på det populære open source-datasæt COVIDx.
Forskerne, der har testet COVIDx i forskellige AI-træningsmodeller, hævder, at det ikke er “repræsentativt for den virkelige kliniske problemstilling”, at resultaterne, der opnås ved at bruge det, er “inflatede”, og at modellerne “ikke generaliserer godt” til virkelige data.
Forfatterne bemærker også inkonsistensen af de bidragne data, der udgør COVIDx, hvor originale billeder kommer i en variation af opløsninger, som automatisk omformates af den dybe læringsworkflow til de konsekvente størrelser, der er nødvendige for træning, og observerer, at denne proces kan introducere bedragende artefakter relateret til billed-genopladningsalgoritmen, snarere end den kliniske aspekt af dataene.
Den artikel hedder De fælder ved at bruge åbne data til at udvikle dybe læringsløsninger til COVID-19-detection i bryst-røntgenbilleder, og er et samarbejde mellem Center for Computational Imaging & Simulation in Biomedicine (CISTIB) på University of Leeds, sammen med forskere fra fem andre organisationer i samme by, herunder Leeds Teaching Hospitals NHS Trust.
Forskningen detaljerer, blandt andet, de negative praksisser, “misbrug af mærker” i COVIDx-datasættet, såvel som en “høj risiko for bias og konfoundering”. Forskerne egne eksperimenter med at sætte datasættet igennem tre livskraftige dybe læringsmodeller fik dem til at konkludere, at ‘den ekstraordinære præstation, der rapporteres bredt over problemområdet, er inflated, at modelpræstationsresultaterne er misrepræsenteret, og at modellerne ikke generaliserer godt til klinisk-realisticke data.’
Fem modsatrettede datasæt i ét
Rapporten* bemærker, at de fleste nuværende AI-baserede metoder i dette felt afhænger af en “heterogen” samling af data fra forskellige åbne kilde-repositorier, og observerer, at fem datasæt med bemærkelsesværdigt forskellige karakteristika er blevet samlet i COVIDx-datasættet, på trods af (ifølge forskerne) utilstrækkelig lighed i datakvalitet og type.
COVIDx-datasættet blev frigivet i maj 2020 som et konsortiumsindsats ledet af Department of Systems Design Engineering på University of Waterloo i Canada, med data gjort tilgængelig som en del af COVID-Net Open Source Initiative.
De fem samlinger, der udgør COVIDx, er: COVID-19 Image Data Collection (en åben kilde fra Montreal-forskere); COVID-19 Chest X-ray Dataset initiativ; Actualmed COVID-19 Chest X-ray datasæt; COVID-19 Radiography Database; og RSNA Pneumonia Detection Challenge datasæt, en af de mange præ-COVID-sæt, der er blevet presset i tjeneste for pandemikrisen.
(RICORD – se nedenfor – er siden blevet tilføjet til COVIDx, men da det blev inkluderet efter modellerne i studiet, blev det ekskluderet fra testdata, og i hvert fald vil det have tendens til at variere COVIDx endnu mere, hvilket er den centrale klage fra forfatterne af studiet.)
Forskerne hævder, at COVIDx er ‘det største og mest brugte’ datasæt af sin art inden for den videnskabelige fællesskab relateret til COVID-forskning, og at data, der importeres til COVIDx fra de bidragende datasæt, ikke tilstrækkeligt overensstemmer med den tredelte skema af COVIDx-datasættet (dvs. ‘normal’, ‘pneumoni’ og ‘COVID-19’).
… (resten af indholdet er oversat på samme måde)












